
Article Promotion
The Importance of Knowledge Graphs in Natural Language Processing
Author Affiliation:
Feng Zhiwei, Research Center for Russian Language, Literature and Culture, Heilongjiang University / Hangzhou Normal University
Abstract:
The term “knowledge graph” first appeared in literature in 1972. In May 2012, Google explicitly proposed the concept of a knowledge graph and constructed a large-scale knowledge graph, pioneering research in this area. Knowledge graphs represent semantic symbols as nodes and the semantic relationships between symbols as edges, forming a generic formal description of semantic knowledge, becoming an important resource for natural language processing. This article introduces the development history and basic principles of knowledge graphs, formalizes the description of the triples (head entity, relation, tail entity), analyzes the significant role of knowledge graphs in natural language processing research, and introduces various large-scale knowledge graphs such as Wikipedia, DBpedia, TAGO, Freebase, Wikidata, NELL, Knowledge Vault, as well as Chinese-focused knowledge graphs and the COKG-19 knowledge graph. Since the triples in knowledge graphs are based on predicate logic, their representation has certain limitations. This article suggests combining word vectors from deep learning with knowledge graphs, integrating intuitive “System 1” knowledge with rational analysis “System 2” knowledge, to improve the current deficiencies of knowledge graphs and advance them into cognitive graphs.
Keywords:
Knowledge Graph; Word Vector; Triple; Head Entity; Relation; Tail Entity
DOI Code:
10.16263/j.cnki.23-1071/h.2021.05.001
Publication Information:
Feng Zhiwei. The Importance of Knowledge Graphs in Natural Language Processing [J]. Foreign Language Research, 2021(5).
1. Development History
In 1956, the Dartmouth Conference held at Dartmouth College in the USA proposed the concept of “Artificial Intelligence (AI)”. Since then, AI has rapidly developed. Natural Language Processing (NLP) is a significant research area within AI. In NLP research, scholars began to construct automatic reasoning models for problem-solving, proposing a series of theories and methods for knowledge description such as semantic networks, frames, and scripts (Feng Zhiwei, 2011). For example, Sowa et al. proposed the “Concept Net” for knowledge description in 1983. Scholars limited the relationships between entities based on symbolic principles to specific basic relations such as “has, causes, belongs to,” and defined some reasoning rules on the graph, hoping to achieve AI through logical reasoning (Sowa et al., 1983). Based on these knowledge description theories and methods, domain experts began to manually compile instance data and establish knowledge bases, achieving success in some limited domains. Scholars began to focus on the study of knowledge resources.
With the emergence of the internet, people created large-scale data through interactions with nature and society, entering the era of big data. This data exists in various modalities such as text, images, audio, and video. How to enable computers to automatically recognize, read, analyze, and understand this vast and complex data, mining valuable information to provide accurate information services for users, has become one of the core goals of the next generation of information services. In 2001, Tim Berners Lee proposed the concept of the semantic web, defining a conceptual standard for describing the objective world, using a unified metadata framework to semantically annotate the content of the internet, thereby endowing the internet with meaning and transforming the World Wide Web (WWW) into a semantically connected web. Influenced by the idea of the semantic web, billions of internet users collaboratively built “Wikipedia,” promoting rapid growth in knowledge resources, achieving unprecedented levels in knowledge types, coverage, and data scale (Tim Berners Lee et al., 2001). The term “knowledge graph” appeared in literature in 1972. In May 2012, Google explicitly proposed the concept of a knowledge graph and constructed a large-scale knowledge graph, opening up research in knowledge graphs. Since then, knowledge graphs have become popular in NLP research, becoming an important content of NLP research.
Knowledge graphs use nodes to represent semantic symbols and edges to represent the semantic relationships between symbols, thus forming a generic formal description framework for semantic knowledge. In computers, symbols such as nodes and edges can represent objects in the physical and cognitive worlds through “symbol grounding” and serve as a bridge for different individuals to describe and exchange information and knowledge in the cognitive world. The use of a unified formal framework for knowledge description in knowledge graphs facilitates knowledge sharing and learning, making knowledge graphs widely welcomed by NLP researchers. After Google constructed its knowledge graph, it released a large-scale knowledge graph containing 50.7 billion entities in 2012, prompting many internet companies to quickly follow suit and build their own knowledge graphs. For example, Microsoft established Probase, Baidu created “Zhixin,” and Sogou built “Zhili Fang.” Various industries, including finance, healthcare, justice, education, and publishing, have established their vertical knowledge graphs, significantly improving the intelligence level of these industries. Companies such as Amazon, eBay, Facebook, IBM, LinkedIn, and Uber have successively announced the development of knowledge graphs. At the same time, academia began to research the theories and methods for constructing knowledge graphs. An increasing number of scientific papers have been published on the topic of knowledge graphs, including books, papers, new technologies, and surveys related to knowledge graphs.
The development of knowledge graph technology has deep historical roots, originating from the study of semantic knowledge representation in natural language within AI and undergoing the baptism of the ever-deepening demands of internet information services. It has now developed into a core tool for internet knowledge services. The theoretical research of knowledge representation represented by semantic networks, the practical application of intelligent information processing on the internet, and the collaborative construction of knowledge resources represented by Wikipedia have collectively driven the further development of knowledge graphs (Zhao Jun et al., 2019).
2. Knowledge Graph Triples
The triples in knowledge graphs are represented as (h, r, t), where h represents the “head entity,” r represents the “relation,” and t represents the “tail entity.” The structure of knowledge graph triples is very simple and can be represented as: (head, relation, tail)
Using initials, it can be represented as: (h, r, t)
For example, we have the following triples:
(Max Planck, nationality, Germany)
(Max Planck, born, Kiel, Denmark)
(Max Planck, awarded, Nobel Prize)
(Max Planck, profession, physicist)
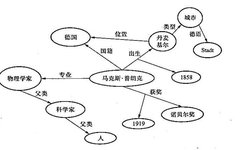
In the triple (Max Planck, nationality, Germany), h=Max Planck, r=nationality, t=Germany. Through these different triples, we can obtain a relatively comprehensive understanding of Max Planck. Clearly, such a knowledge graph is a straightforward means of describing knowledge. Through this knowledge graph, we know that Max Planck is a German, born in Kiel, Denmark (now part of Germany’s Holstein), his profession is physicist, and he has received the Nobel Prize. Based on this, if we associate it with other structured data, we can further learn more about Max Planck. For instance, through the type of “Kiel, Denmark,” we can learn that “Kiel” is a “city,” and through the language description of “city,” we can further learn that the German term for “city” is Stadt, and so on. Through the parent node of “physicist,” we can know that its parent attribute is “scientist,” and that the parent attribute of “scientist” is “human.” When the “relation” r in the triple is unclear, the knowledge graph allows for the addition of other information as “additional resources” to supplement the lack of information. For example, we can introduce “birth date” as an “additional resource” for birth information, thus knowing that “Max Planck was born in Kiel, Denmark in 1858.” We can also introduce “award date” as an “additional resource” for award information, thus knowing that “Max Planck received the Nobel Prize in 1919.”
In this way, we can obtain more triples:
(Kiel, Denmark, type, city)
(Kiel, Denmark, location, Germany)
(city, German, Stadt)
(physicist, parent, scientist)
(scientist, parent, human)
(birth date, additional resource, 1858)
(award date, additional resource, 1919)
Based on the above triples, we can construct a knowledge graph about the German physicist Max Planck. As shown in Figure 1.
This knowledge graph describes the nationality, birth, awards, profession, and other information of the renowned German physicist Max Planck in a triple format, which is very useful. It is evident that the structured description of data according to the agreed framework, combined with existing structured data, forms a knowledge graph that can describe relatively complete knowledge. In practical applications, knowledge graphs often need to map their framework structure to a framework supported by a specific database, and if necessary, the database can be specially extended. This way, the functionality of knowledge graphs becomes even more powerful. In knowledge graphs, knowledge is cognition, the graph is the carrier, and the database is the implementation. Knowledge graphs represent cognitive content using the abstract carrier of graphs on database systems.
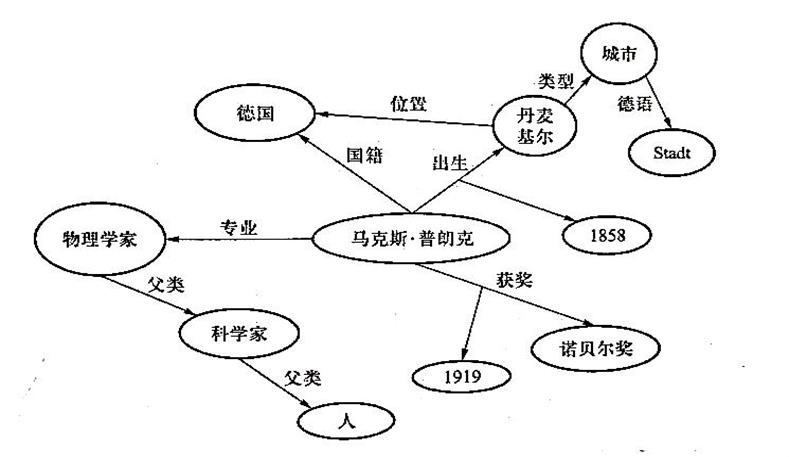
Figure 1 Example of a Knowledge Graph
3. Several Large-scale Knowledge Graphs
Currently, large-scale knowledge graphs include Wikipedia, DBpedia, YAGO, Freebase, Wikidata, NELL, Knowledge Vault, and others. These large-scale knowledge graphs use rich semantic representation capabilities and flexible structures to describe information and knowledge in the cognitive and physical worlds, becoming effective carriers of knowledge (Feng Zhiwei, Zhan Hongwei, 2018).
Figure 2 shows the major large-scale knowledge graphs: Wikipedia, DBpedia, YAGO, Freebase, NELL, Knowledge Vault, etc. Below, we will introduce them respectively.
(1) Wikipedia: In 2001, the global multilingual encyclopedia collaboration project Wikipedia was initiated with the aim of providing a free encyclopedia for all humanity. Within a few years, through the collaborative efforts of global users, Wikipedia completed the writing of hundreds of thousands of entries, and has now developed into a large-scale knowledge graph with millions of entries. The emergence of Wikipedia has promoted the construction of many structured knowledge bases based on encyclopedias.
(2) DBpedia: In 2006, Tim Berners Lee proposed the concept of “linked data” based on the World Wide Web he founded, encouraging everyone to publish data publicly and follow certain principles to publish it on the Semantic Web. The purpose of linked data is not only to publish data on the Semantic Web but also to establish links between data, forming a vast network of linked data. The most representative linked data network is DBpedia, which began operating in 2007 and is currently known as the first large-scale open-domain linked data network. This system was initially developed by scholars from the Free University of Berlin and Leipzig University, aiming to alleviate the difficulties faced by the semantic web at that time. DBpedia released its first public dataset in 2007, allowing others to use it through open licensing. The developers of DBpedia believe that in the context of massive network information, it is impractical to use a traditional “top-down” approach to design knowledge ontologies before data. Instead, data and its metadata should be continuously improved as information increases. This increase and improvement of data can be achieved through community collaboration, thus knowledge ontologies should be designed “bottom-up” based on data. However, this bottom-up approach involves many issues such as data consistency, uncertainty, and unified representation of implicit knowledge. They believe that the most efficient way to explore these issues is to provide a content-rich multi-source data corpus, which can greatly promote the development of knowledge reasoning and data uncertainty management technologies, and develop operational systems for the Semantic Web.
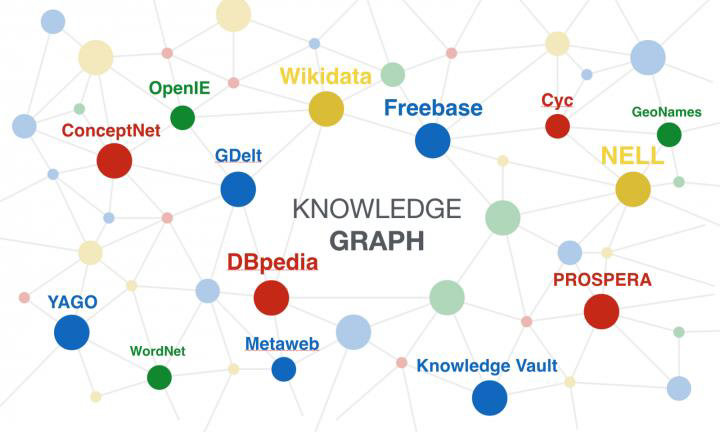
Figure 2 Major Large-scale Knowledge Graphs
Based on the concept of “linked data,” the DBpedia knowledge base utilizes semantic web technologies, using the Resource Description Framework (RDF) in the semantic web to establish linking relationships with numerous knowledge bases such as WordNet and Cyc, building a massive network of linked data. As shown in Figure 3.
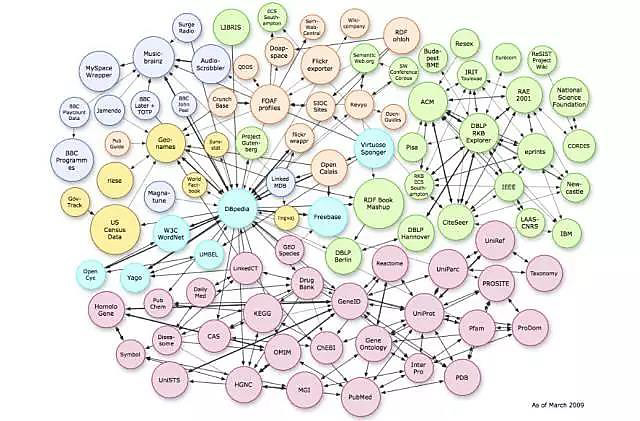
Figure 3 Linked Data Network Centered on DBpedia
DBpedia primarily relies on community members to define and write accurate extraction templates to extract structured information from Wikipedia to build a large-scale knowledge base. Additionally, the construction of the DBpedia ontology is also completed through community collaboration.
DBpedia can support 127 languages and describes 17.31 million entities. DBpedia has extracted 9.5 billion triples, of which 1.3 billion triples are extracted from the English version of Wikipedia, 5 billion triples from other language versions of Wikipedia, and another 3.2 billion triples from Wikipedia, thus DBpedia has a large amount of cross-language knowledge.
(3) YAGO: This system is a project initiated by the Max Planck Institute in Germany in 2007. To address the shortcomings of using only a single source of background knowledge, YAGO established a high-quality, high-coverage knowledge base based on multiple sources of background knowledge. WordNet is a highly accurate ontology knowledge base, but the knowledge it contains only covers some common concepts or entities in everyday language; while Wikipedia contains richer entity knowledge than WordNet, the conceptual hierarchy provided by Wikipedia is similar to a tagging structure, which is not precise enough for direct use in building ontologies. YAGO combines WordNet and Wikipedia, leveraging the ontological information from WordNet to supplement the hypernym knowledge of entities in Wikipedia, thus constructing a large-scale, high-quality, and high-coverage knowledge base. As of now, YAGO has over 10 million entities and 120 million factual knowledge.
(4) Freebase: This system is a structured knowledge resource built using a crowdsourcing approach based on Wikipedia, containing 58.13 million entities and 3.2 billion triples of structured knowledge, making it a publicly accessible large-scale knowledge graph. Freebase was acquired by Google on July 16, 2010, and was integrated into Google’s knowledge graph. In 2015, Google shut down Freebase and transferred its data to Wikipedia.
(5) NELL: This system is a machine learning system developed by Carnegie Mellon University based on the Read the Web project. NELL stands for Never-Ending Language Learning. NELL continuously performs automatic reading and automatic learning tasks. The automatic reading task involves acquiring knowledge from web text and adding the acquired knowledge to NELL’s internal knowledge base, while the automatic learning task uses machine learning algorithms to acquire new knowledge, consolidating and expanding its understanding of knowledge. NELL can extract a large number of triples and label the extracted iteration rounds, time, and confidence, and can also undergo manual verification. The NELL system has been automatically learning since 2010, and after half a year of learning, it extracted a total of 350,000 entity-relation triples, achieving a correctness rate of 87% after manual labeling and correction.
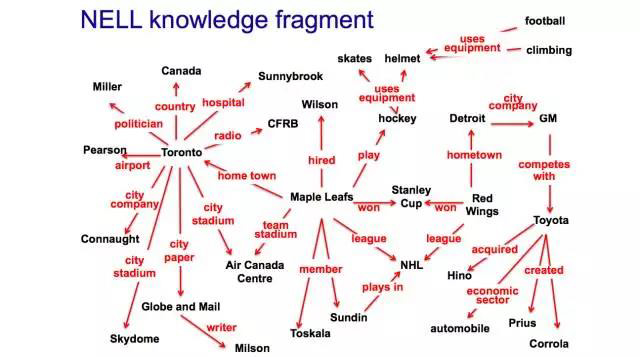
Figure 4 Knowledge Segments Extracted by NELL
Figure 4 shows knowledge segments extracted by NELL regarding the Maple Leafs team, consisting of many triples. For example:
(Maple Leafs, play, hockey)
(Maple Leafs, won, Stanley Cup)
(Maple Leafs, hired, Wilson)
(Maple Leafs, member, Toskals)
(Maple Leafs, member, Sundin)
(Maple Leafs, hometown, Toronto)
(Toronto, country, Canada)
From these triples, we can know that the Maple Leafs team plays hockey, has won the Stanley Cup, has hired Wilson, has members Toskals and Sundin, and is located in Toronto, which is in Canada. This knowledge forms a very complex knowledge system.
(6) Knowledge Vault: This system is a large-scale knowledge graph developed by Google in 2014. Compared to the Freebase knowledge graph, Knowledge Vault no longer adopts the crowdsourcing approach to build knowledge but instead uses algorithms to automatically search for information on the web, employing machine learning methods to integrate and fuse existing structured data (such as structured data from YAGO or Freebase) and automatically convert them into usable knowledge. Currently, Knowledge Vault has collected 1.6 billion factual data, of which 271 million factual data have high confidence, with an accuracy rate of around 90%.
The knowledge graphs introduced above are primarily based on English, even multilingual knowledge graphs are centered around the English language, with knowledge in other languages obtained through cross-language knowledge linking.
In recent years, a large number of knowledge graphs primarily in Chinese have been launched in China, mainly constructed based on the structured information from Baidu Encyclopedia and Wikipedia. For instance, Shanghai Jiao Tong University’s zhishi.me and Fudan University’s CN-pedia. In 2017, multiple universities in China initiated the cnSchema.org project, which aims to utilize community power to maintain the Schema standards of open-domain knowledge graphs.
To combat the novel coronavirus (COVID-19), researchers, medical personnel, government officials, and the public worldwide are eager for open and comprehensive knowledge about the virus. To meet this urgent need, Tsinghua University initiated the ArnetMiner knowledge graph project. ArnetMiner collects and organizes existing open knowledge graphs related to COVID-19, further integrating them to construct a large-scale, structured COVID-19 knowledge graph called COKG-19, as shown in Figure 5.
Figure 5 COKG-19 Knowledge Graph
Currently, COKG-19 includes 505 concepts, 393 attributes, 26,282 instances, and 32,352 knowledge triples, covering medical, health, material, prevention, research, and personnel information. The goal of COKG-19 is to help publishers and researchers identify and link semantic knowledge in texts and provide more intelligent services and applications. People can gain comprehensive knowledge about COVID-19 through COKG-19. COKG-19 is a bilingual knowledge graph in Chinese and English, allowing for bilingual queries, thus serving international users. Therefore, the structured information accumulated in the triples of knowledge graphs has become the most valuable knowledge asset in the era of artificial intelligence.
4. Improvements to Knowledge Graphs
If we have billions of such triple knowledge, we can also use them for logical reasoning to obtain richer knowledge. For instance, if we have the triples regarding the birth years of Feng Zhiwei and Noam Chomsky (N. Chomsky):
(Feng Zhiwei, birth year, 1939)
(Noam Chomsky, birth year, 1928)
In an intelligent dialogue system, when a user asks: “How old was Chomsky when Feng Zhiwei was born?” This type of question cannot be answered solely by directly querying the triples in the knowledge graph; it must rely on logical reasoning provided by the knowledge graph. If the knowledge graph contains the above triples, we can deduce that Chomsky’s age at the time of Feng Zhiwei’s birth equals Feng Zhiwei’s birth year minus Chomsky’s birth year. Since 1939 – 1928 = 11, we can infer from the knowledge graph that Chomsky was 11 years old when Feng Zhiwei was born. Thus, the structured information in the triples of knowledge graphs not only stores knowledge but also enables knowledge reasoning, generating new knowledge, making it a treasure trove of human knowledge and very valuable.
We can also combine knowledge graphs with word vectors in neural network deep learning to enhance the interpretability of neural networks (Feng Zhiwei, 2019). In recent years, scholars have transformed discrete language symbols into real values of word vectors through mathematical methods to process natural language, elevating natural language processing to a new level. However, word vectors are not symbols of natural language but real values, making it difficult to discern the linguistic patterns they represent, lacking interpretability. If we have a knowledge graph, we can use the linguistic facts represented by the knowledge graph to organize the word vector representations obtained through deep learning. For example, if the neural network obtains the following word vector data through deep learning:
Beijing: [270]
Capital: [319]
City: [327]
Hamburg: [348]
Port City: [300]
Stockholm: [368]
These word vector data are real values, and it is challenging to determine their relationships solely based on these word vectors, leading to a lack of interpretability. However, if our knowledge graph contains the following triples:
(Beijing, is, capital)
(Stockholm, is, capital)
(Hamburg, is, port)
(Stockholm, is, port)
(capital, is a type of, city)
(port, is a type of, city)
Then we can elevate the word vectors from the neural network into circular regions based on the linguistic facts represented in the knowledge graph, maintaining the vector characteristics of the neural network while learning the knowledge structure driven by the knowledge graph through the topological relationships between different areas in the domain representation. This method allows us to spatially represent knowledge by integrating the numerical values of word vectors and the symbols of knowledge graphs, significantly enhancing the interpretability of word vectors (Li Juanzi et al., 2020). As shown in Figure 6.
Figure 6 on the left shows the numerical representation of word vectors obtained through deep learning, while the right side represents the linguistic symbol representation of the knowledge graph. The circular region with radius r=88 represents “capital,” and the circular region with radius r=100 represents “port city.” Based on the symbol information in the knowledge graph, we can determine that Beijing is a “capital,” Hamburg is a “port city,” and Stockholm possesses both “capital” and “port city” characteristics, which is encompassed within the circular region with radius r=178. In this way, we obtain a knowledge graph with cognitive functions that merges the numerical values of word vectors with the symbols of knowledge graphs through domain representation, achieving spatialization of symbols through vector regionalization and symbol projection, significantly enhancing the interpretability of word vectors.
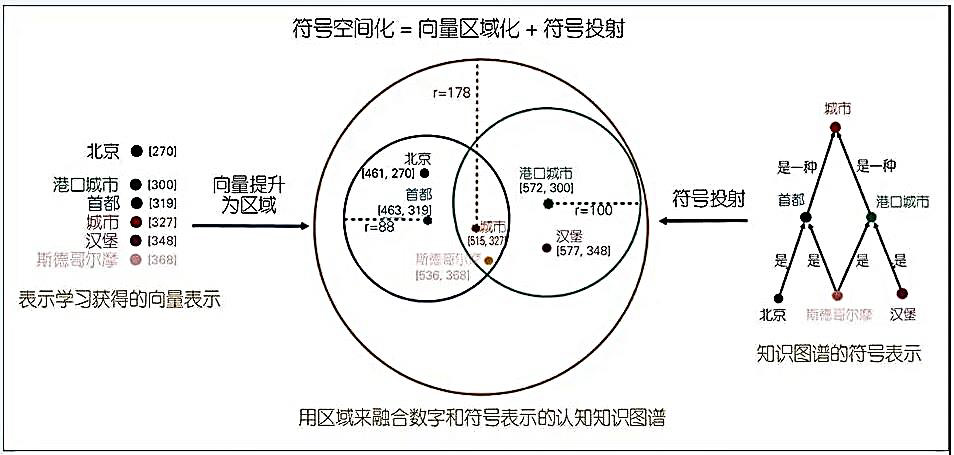
Figure 6 Knowledge Representation and Reasoning Merging Word Vector Values and Knowledge Graph Symbols
5. From Knowledge Graphs to Cognitive Graphs
However, the triples in knowledge graphs are based on first-order predicate logic of two events or entities, and such a representation of triples has limitations. For a long time, researchers in knowledge graphs have tirelessly pursued the exploration of issues relying solely on triples composed of head entities, relations, and tail entities (h, r, t). Although these can represent most simple events or properties of entities, they struggle with complex knowledge. In the era of artificial intelligence, where the granularity of knowledge understanding is increasingly refined, such shortcomings become the Achilles’ heel of knowledge graphs. For instance, for the fact that “Li Zhengdao and Yang Zhenning jointly proposed the theory of parity violation,” if we want to include it in the knowledge graph, we must record it in the format: (Li Zhengdao and Yang Zhenning, jointly proposed, theory of parity violation). However, this means that the head entity “Li Zhengdao and Yang Zhenning” cannot independently express the other activities conducted by these two scientists. If we separate the head entity into “Li Zhengdao” and “Yang Zhenning,” it contradicts the fact of “jointly proposed” in the triple relation. Therefore, such facts cannot be directly represented in knowledge graphs. Similarly, the proposition “The attributes of the cloned sheep are the same as those of the body” is also difficult to represent with knowledge graphs. Such propositions are usually referred to as “rules” in broader knowledge base theories, requiring extensive enumeration operations to explain the specific content of each attribute, thus deducing the attributes of cloned sheep, which involves a vast number of entities related to cloned sheep, making it challenging for knowledge graphs to express. To improve these shortcomings of knowledge graphs, scholars have proposed “cognitive graphs.”
In cognitive science, there is a well-known “dual-process theory,” which posits that human cognition can be divided into two systems: “System 1” and “System 2.” System 1 is intuitive-based, while System 2 is analytic-based. System 1 engages in “fast thinking,” relying on intuition and is a thought system based on experience and associations, where its basic function is to activate emotions, memories, and experiences related to objects, all of which are unconscious and can be quickly activated. This activated information forms a harmonious story, leading System 1 to easily make misjudgments. As long as the related objects are harmonious, System 1 believes it is correct. Therefore, System 1 can automatically, easily, and quickly believe anything and is easily deceived, leading to misjudgments. In contrast, System 2 engages in “slow thinking,” which utilizes knowledge in the working system for slow and reliable logical reasoning, requiring conscious control and representing advanced human intelligence. Its basic functions are mathematical calculations and logical reasoning, engaging in conscious reasoning and deliberation, akin to a “slow Zhuge Liang” (a meticulous strategist). System 2 can alter the functioning of System 1, coordinating between them to correct System 1’s misjudgments, as illustrated in Figure 7.

Figure 7 Coordination of System 1 and System 2 in the “Dual-process Theory”
Current neural networks and deep learning primarily operate on the basis of System 1, relying mainly on large-scale data for support. In the future, research in natural language processing needs to evolve from System 1 deep learning to System 2 deep learning, achieving the logical reasoning capabilities of System 2. This will require not only support from big data but also rich knowledge. It is evident that in the transition from System 1 deep learning to System 2 deep learning, knowledge graphs, which carry rich human knowledge, will play a crucial role.
The Foreign Language Research Journal is a core journal in Chinese, a top 100 social science journal in China, a core academic journal in the RCCSE Chinese Core Academic Journal, a core journal in the comprehensive evaluation of humanities and social sciences in China (A journal), and a source journal in the Chinese Social Sciences Citation Index (CSSCI expanded version).
This WeChat public account publishes articles from the Foreign Language Research Journal unless otherwise specified. All rights reserved. Reprinting is welcome, but please indicate the source.
