

Last week, the “Huxiu Research” column under Huxiu updated its episode titled “Is Chinese Bound to Fall Behind in the AI Wave?” After the episode aired, we received discussions and doubts from various parties. The questions mainly fell into two categories:
One category included many AI practitioners pointing out that our understanding of the principles of ChatGPT was not thorough and accurate enough. The other category was the lingering doubts about whether “is it really that difficult to make AI speak Chinese?”
 For example, this friend feels that the actual situation is not as difficult as stated in the video.
For example, this friend feels that the actual situation is not as difficult as stated in the video.
Therefore, the production team engaged in mutual critique and conducted deeper learning and discussions on these issues, resulting in the following questions and answers, which we hope will be helpful to you in front of the screen.
In this AI wave, we hope we can all maintain our thinking and progress.
If you haven’t watched the video yet, you can click on the video card at the end of the article to watch it.
What language does a large language model like ChatGPT understand?
To explain this question, it may be necessary to understand how ChatGPT actually “speaks”. This can be answered by the full name of the three letters GPT, which stands for Generative Pre-trained Transformer.
Generative means predicting the next words based on the previous context. Pre-trained Transformer means it uses the Transformer architecture, which learns the relationships between words by mimicking the human “attention mechanism” and predicts the next word. For ChatGPT, it uses an autoregressive generation model, meaning that every time the model generates a word, it is added to the previous context for the next prediction, significantly enhancing the model’s learning ability and accuracy.
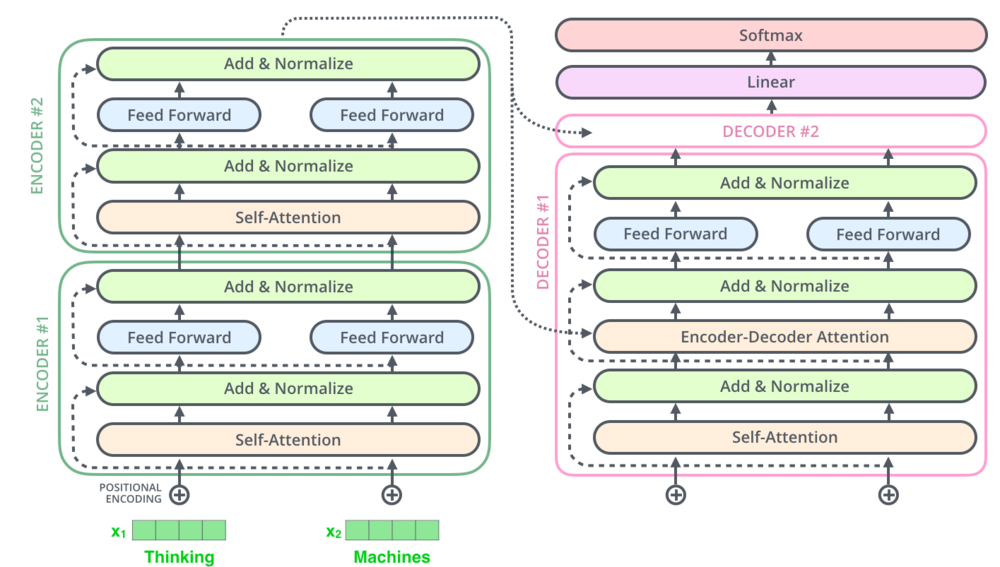 An example of a Transformer architecture, image: jalammar
An example of a Transformer architecture, image: jalammar
From the results, ChatGPT can converse with us using “language”. From a theoretical perspective, ChatGPT is a model that can predict and complete the task of “continuing the sentence” through mathematical operations. We can say that ChatGPT does not know the underlying meaning of the “answers” it outputs, but it can provide correct answers from a linguistic perspective.
How does GPT-4 achieve good Chinese understanding?
After GPT-4 was released, netizens tested several examples mentioned in our video, such as “I spent three days reading this book,” and found that GPT-4 could fully understand it, which is impressive. After testing it ourselves, we also found that GPT-4 has already shown strong capabilities in understanding and outputting Chinese.
So how does it do it? The paper on GPT-3 actually explains part of ChatGPT’s “few-shot learning” mechanism. In simple terms, this means “giving examples”.
For instance, if I want the AI to translate “上山打老虎” (Go up the mountain to hunt tigers), I will provide several examples of Chinese to English translations when inputting the question, like this:
Prompt: 上山打老虎
example1: 天王盖地虎 —- sky king gay ground tiger
example2: 上阵父子兵 —- go to battlefield together
Then I let the AI output based on this context, which is called in-context learning, a specific method used by OpenAI to train models. The specific principles may take some time to explain clearly, but from the title of GPT-3’s paper, “Language Models are Few-Shot Learners,” we can see the outcome is evident: it is effective.
With GPT-4, its multilingual understanding abilities have improved, but the technical details disclosed in this paper are limited. From certain perspectives, the capabilities of ChatGPT and the content that can be explained by everyone are gradually diverging. We hope to take this opportunity to discuss this issue with more professionals.
What impact does insufficient Chinese corpus have?
In the original video, we pointed out that the lack of Chinese corpus has led to many difficulties for language models when learning Chinese expressions. However, some friends in the comments section used examples of GPT-4 to say that with the previously mentioned in-context learning mechanism, current large language models do not necessarily require a massive corpus to master a new language.
After chatting with some practitioners, some friends also expressed that different languages are just data for AI, and under the influence of large computing power and deep learning, there is not much difference between them.
However, we can understand how ChatGPT itself selects its corpus. According to the paper, the GPT-3 model used a staggering 499 billion tokens (a unit of words in NLP research). As for how much foreign corpus GPT-4 has used, OpenAI has not disclosed that yet.
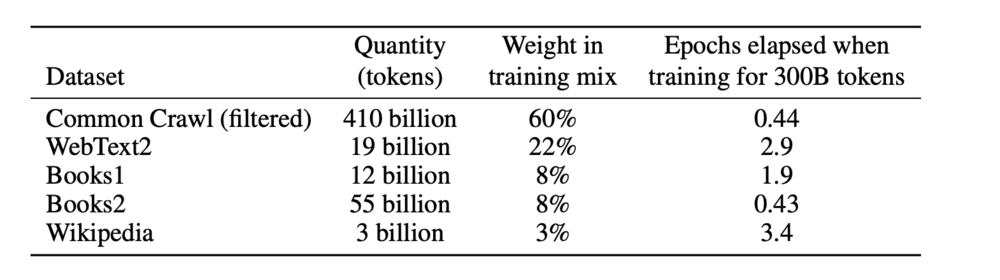 Data regarding the training set in the GPT-3 paper
Data regarding the training set in the GPT-3 paper
Although it is said that great teachers produce outstanding students, a sufficient number of ordinary craftsmen, combined with the right learning methods, can still produce high achievers.
What if we train with classical Chinese?
Many people in the comments section of the video raised this interesting question! Some even asked, “Is classical Chinese the last fortress of humanity?” What about Martian language?
If you understand the previous introduction to the principles and training process of ChatGPT, you will know that classical Chinese may just be a matter of “whether to practice and how to practice” for data models.
If we want an AI that can speak classical Chinese, we may need to provide it with enough classical Chinese corpus, which brings more work, such as digitizing literature, categorizing, and extracting…
Artificial intelligence is a costly business, and perhaps we do not currently need an AI that can speak classical Chinese?
Who knows.
How can we make AI speak good Chinese?
As we just mentioned, currently, the only publicly available large language model in China is Wenxin Yiyan, and Wenxin Yiyan has not disclosed specific training and parameter details. However, from the publicly available information, we know that Wenxin Yiyan also uses the Transformer architecture, but it leans more towards Google’s BERT technical approach rather than ChatGPT’s approach (if this is incorrect, please privately message me via Baidu).
Given this, perhaps we can emulate the approaches of ChatGPT and BERT based on their public information to create a “work sheet”—what exactly needs to be done to make AI speak good Chinese.
First is the corpus, which is like soil; good soil naturally leads to a good foundation. We may need some Chinese corpus sets for training that are not just Wikipedia, and perhaps we can also follow OpenAI’s approach of using English corpus first and then teaching it to translate.
Next is the training methods. Each company has its own technical route, but the specific techniques used will directly affect the final performance of the product.
Finally, there is money and time. Time is straightforward; who doesn’t spend time learning to speak? Secondly, there is money. It is estimated that the cost of training GPT-3 once is 5 million dollars, and the overall cost exceeds hundreds of millions.
These are all significant amounts of money.
What is the impact of training AI in English on multiculturalism?
This seems to be a topic that is not widely discussed at the moment, but just like Hollywood’s impact on global culture, if AI really sweeps the globe as some expect, then will the training data based on English affect cultural diversity?
In the papers released by OpenAI, we can see that during the RLHF (Reinforcement Learning from Human Feedback) process, ChatGPT sought 40 contractors for “labeling”. We do not currently know the backgrounds of these contractors.
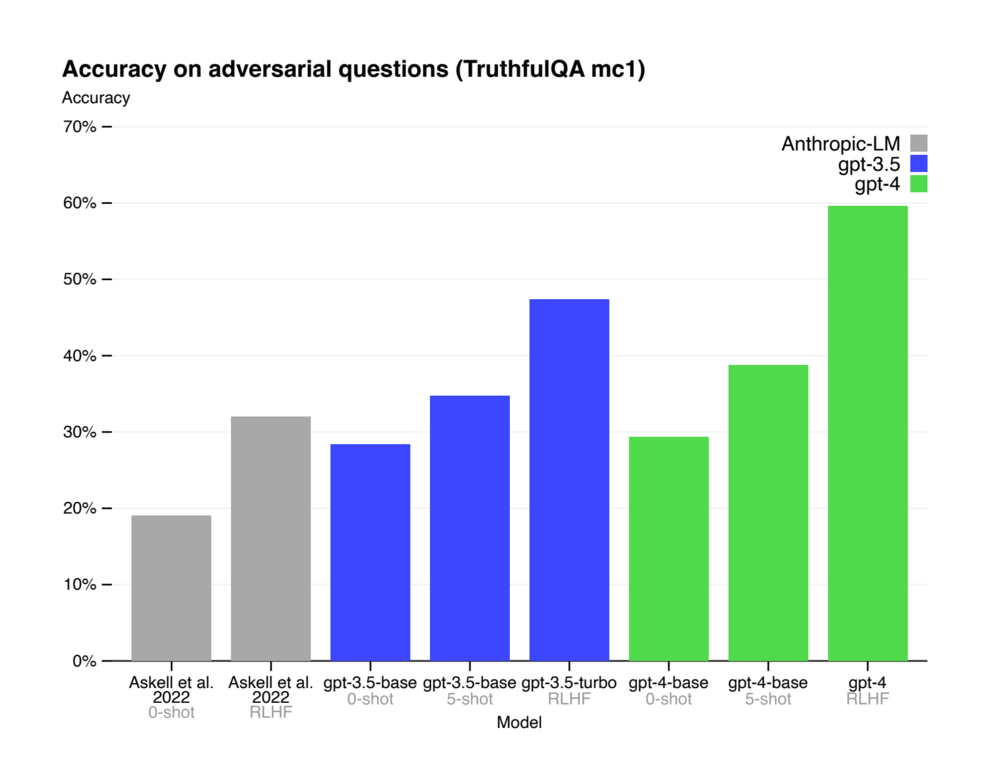 The GPT-4 paper shows significant score increases after RLHF
The GPT-4 paper shows significant score increases after RLHF
Considering the black box nature of Transformers and neural networks, it is currently unclear what impact these human interventions will have on the final model. However, from past instances of artificial intelligence, bias is prevalent, and resolving this bias through parameter adjustments remains a challenge.
Will large language models affect the language itself?
I saw a joke this morning:
Some companies are training conscious AI;
Some companies are training unconscious workers.
(via 夏之空)
Now, various “AI usage guidelines” are emerging like bamboo shoots after a spring rain. From the actual effects, it can be confirmed that using ChatGPT to learn foreign languages is definitely feasible, such as translation, polishing, and understanding, all of which are strengths of large language models.
However, some are concerned that if we rely too much on large language models, will we transition from training AI to being trained by AI? If there are underlying issues with AI, will we be affected?
What does the future hold?
While I was writing this article, the renowned safety organization Future of Life Institute (FLI) released an open letter calling for all institutions worldwide to pause training AI that is stronger than GPT-4 for at least six months and to use this time to establish AI safety protocols.
As of now, this open letter has been signed by 1,125 notable individuals, including Elon Musk and Steve Wozniak.
 As of the time of publication, this open letter has been signed by 1,377 notable individuals
As of the time of publication, this open letter has been signed by 1,377 notable individuals
Because the speed is just too fast… it’s as if everyone at the AI table is holding high cards.
As the open letter states, AI systems have already demonstrated capabilities to compete with humans in general tasks, so the next question is whether they will replace humans?
I will quote the conclusion of the open letter: welcome everyone to leave comments and discuss:
Let’s enjoy a long AI summer, not rush unprepared into a fall.
Let us enjoy a long AI summer rather than rush unprepared into a deep autumn. (Translated manually, not using AI)
Final Thoughts
Just before publication, we contacted Professor Chen Huajun from the School of Computer Science and Technology at Zhejiang University, an expert in knowledge graphs, big data, and natural language processing.
Q: Does the lack of Chinese corpus have an impact on training large AI models?
A: Not necessarily a significant impact; after all, for AI, text, images, and videos are all treated as data, regardless of language. Chinese and English are just data for AI.
Q: What approach do you think should be taken to develop a large Chinese language model?
A: The base model can be trained with English corpus, then enhanced training with Chinese corpus, and conduct Chinese prompt engineering and instruction fine-tuning. I believe this is the technical route most domestic teams are taking to develop large models.
Q: Wouldn’t this lead to semantic differences causing understanding deviations?
A: I think this is not solely a problem of processing Chinese (like idioms such as “车水马龙”). A solution could be to use a knowledge graph to constrain the generative model, which can help reduce the generation of incorrect knowledge. Our own experiments have confirmed this.
Q: What do you think will happen next?
A: AI is still a revolution in productivity; there are pros and cons, but I believe the benefits outweigh the drawbacks. After a significant boost in human productivity, people will find more new jobs and new ways of living.
If you have any objections or complaints about this article, please contact [email protected]
End
Want to gain knowledge? Follow Huxiu’s video account!