In the past three years, the emergence of foundational models represented by OpenAI’s ChatGPT has significantly accelerated the development of LLM applications. However, relying solely on LLMs to answer questions based on their “inherent” knowledge often leads to issues such as hallucinations or outdated knowledge. Against this backdrop, the idea of using multiple LLMs, each optimized for different types of questions, has emerged. However, this can also lead to certain limitations, making the overall system complex and difficult to scale.
So how can we solve this problem?
The answer is the Composite Artificial Intelligence System (CAIS). Next, we will focus on interpreting the historical evolution of CAIS and its construction process.
01.
The Historical Evolution of CAIS, from RAG to Agent
This concept was first mentioned in a blog titled “Transition from Models to Composite Artificial Intelligence Systems” on the website of the AI research lab at the University of California, Berkeley, in early 2024. It emphasizes achieving more efficient, reliable, and interpretable intelligent systems by integrating multiple AI technologies and modules.
For example, we can enhance system performance by adding additional components to the LLM pipeline. A common example is RAG, which generates more accurate and relevant answers by storing a “knowledge base” or “context” in a vector database (such as Milvus or Zilliz Cloud) and combining it with the LLM as context.
Generally, the basic steps for building a RAG system are as follows:
-
Chunking: Splitting documents into smaller parts to improve the relevance of semantic searches in the vector database, which is a core feature of vector databases like Zilliz Cloud and Milvus.
-
Embedding: Vectorizing the chunks (creating vector numerical representations) and storing them in the vector database.
-
Prompt: Providing instructions to the LLM to retrieve answers based on queries from the vector database.
-
Query: The question posed to the LLM.
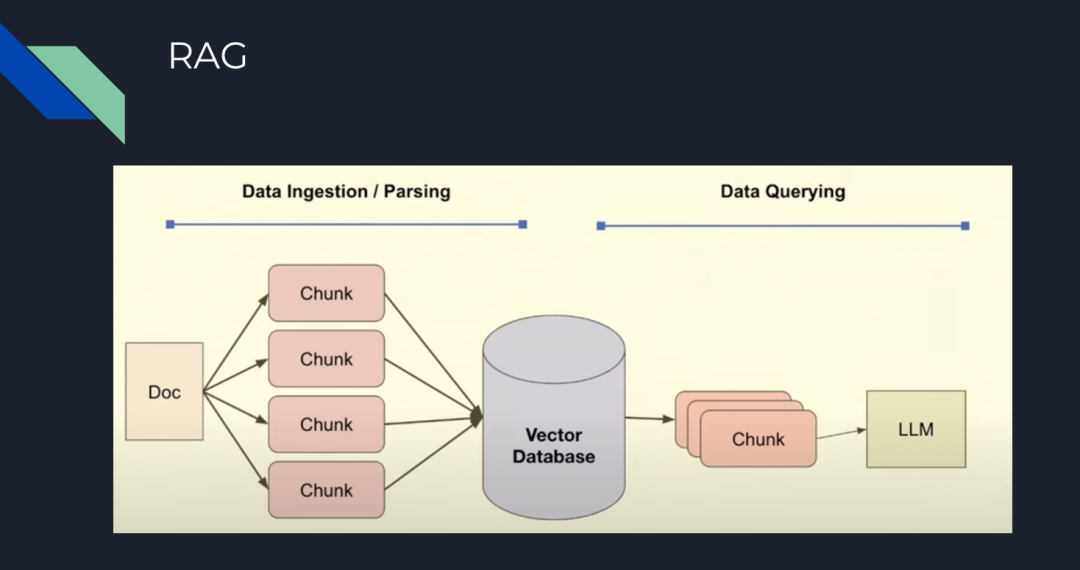
Figure 1: Basic Steps of RAG
It is not difficult to see that each of the above steps mainly relies on vector similarity to complete retrieval and content generation. However, if the chunking is not precise enough, or the content of the chunks is not highly relevant to the answers, the final generated answers may also be unsatisfactory.
Meanwhile, another major limitation of RAG is its excessive dependence on specific models. For example, if we are doing a comparison task, the model may be trained for inductive tasks.
On this basis, Agents have emerged.
LLM Agents are complex systems that can perform various complex operations by adding “human-like” steps in the pipeline, such as reasoning, tool usage, or planning.
For instance, in the following diagram, the LLM Agent includes multiple components that can interact during the iterative process. They can not only perform similarity retrieval but also complete various functions such as planning, reasoning, tool usage, and memory.
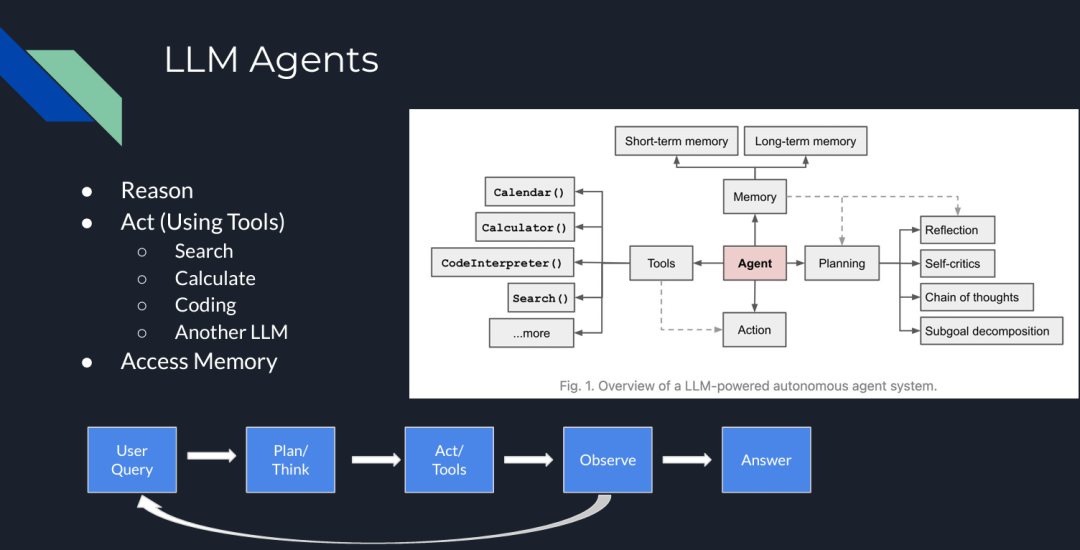
Figure 2: LLM Agents
Currently, the most popular architecture and framework for various Agents is ReAct (Reasoning/Action). This concept originated from the paper “ReAct: Synergizing Reasoning and Acting in Language Models”.
In ReAct, there are four main steps: Planning/Thinking, Acting (tools), Observing, and Answer Generation.
Notably, in the evaluation phase, if the model does not find an answer, it will return to the reasoning step or ask the user for more hints to continue generating the answer.
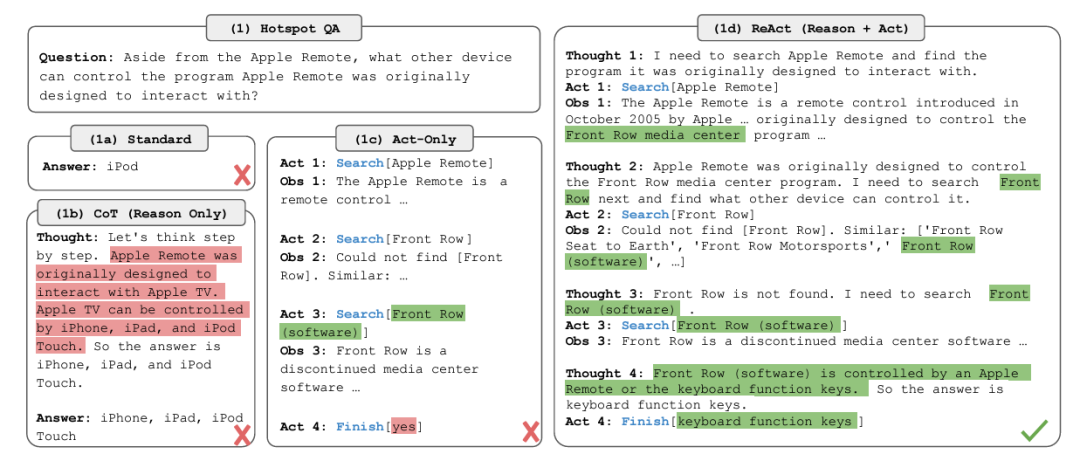
Figure 3: ReAct Framework
So how do we use these Agents in the RAG pipeline? Here are five common ways to construct agents in the RAG pipeline:
-
Routing: Redirecting user queries to specific knowledge bases related to the queries.
-
Example: If a user asks for recommendations for a specific type of book, the query can be routed to a knowledge base containing information about those types of books.
-
Query Planning: Splitting the query into sub-queries, with each sub-query directed to the relevant RAG pipeline.
-
Example: If you want to know a company’s financial results over the past three years, the Agent will create sub-queries for each year and direct each sub-query to the appropriate knowledge base.
-
Tool Use: LLM interacts with external APIs or tools to determine the parameters needed for the interaction.
-
Example: If a user requests a weather forecast, the LLM calls a weather API, determines parameters such as location and date, and processes the API response to provide an answer.
-
ReAct: An iterative process that combines reasoning and action, including planning, tool use, and observation steps.
-
Example: To generate a detailed travel itinerary, the system infers user needs, uses APIs to gather information about attractions, dining, and accommodation, observes the accuracy and relevance of the results, and then provides a comprehensive travel plan.
-
Dynamic Query Planning: The Agent executes multiple tasks or sub-queries in parallel instead of sequentially and aggregates the results.
-
Example: If you want to compare the financial results of two companies and calculate the differences in specific metrics, the Agent will process data for both companies in parallel and then combine the results to provide a comparison. LLMCompiler is a framework that supports efficient and effective orchestration of parallel function calls.
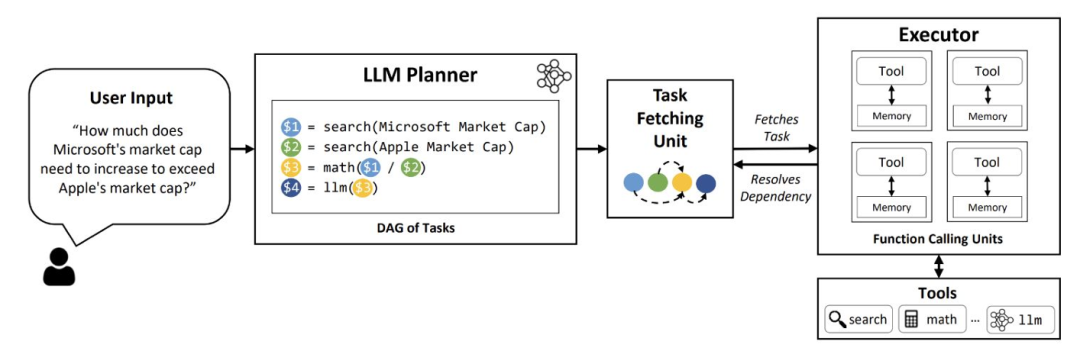
Figure 4: LLM Compiler
Now, let’s build a simple Agentic pipeline using the Milvus vector database.
02.
Building Agentic RAG with Claude 3.5 Sonnet, LlamaIndex, and Milvus
The following content is an example of an Agentic RAG pipeline using LlamaIndex as the Agent framework, Milvus as the vector database, and Claude 3.5 Sonnet as the LLM. We will use it to build an Agentic RAG.
Step 1: Data Loading
We use the FAQ page of Milvus documentation 2.4.x as the private knowledge base for RAG.
!pip install -qq llama-index pymilvus llama-index-vector-stores-milvus llama-index-llms-anthropic
!wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
!unzip -q /content/milvus_docs_2.4.x_en.zip -d /content/milvus_docs
from llama_index.core import SimpleDirectoryReader
# load documents
documents = SimpleDirectoryReader(
input_files=["/content/milvus_docs/en/faq/operational_faq.md"]
).load_data()
print("Document ID:", documents[0].doc_id)
Step 2: Environment Variables
We need to import two API keys: Anthropic and OpenAI.
import os
from google.colab import userdata
os.environ["ANTHROPIC_API_KEY"] = userdata.get('ANTHROPIC_API_KEY')
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
Step 3: Data Indexing
Create a document index using the Milvus vector database as our knowledge base. Since OpenAI is the default embedding model in LlamaIndex (which can be changed), we need to define the same dimensions (dim = 1536) in MilvusVectorStore. After running the following code, a local database will be created containing our knowledge base.
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
vector_store = MilvusVectorStore(dim=1536)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
Step 4: Simple Query Engine
First, test the query engine without an Agent. It is powered by Claude 3.5 Sonnet and searches for relevant content in our index.
llm = Anthropic(model="claude-3-5-sonnet-20240620")
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)
res = query_engine.query("What is the maximum vector dimension supported in Milvus?")
print(res)
"""
Output:
Milvus supports vectors with up to 32,768 dimensions by default. However, if you need to work with vectors of even higher dimensionality, you have the option to increase the value of the 'Proxy.maxDimension' parameter. This allows Milvus to accommodate vectors with dimensions exceeding the default limit.
"""
Step 5: Agent Query Engine
Now, we add QueryEngineTool, which will serve as a wrapper tool for the query engine for the Agent to use.
from llama_index.core import VectorStoreIndex
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.llms.anthropic import Anthropic
llm = Anthropic(model="claude-3-5-sonnet-20240620")
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)
query_engine_tool = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="knowledge_base",
description=("Provides information about Milvus FAQ. Use a detailed plain text question as input to the tool."
),
),
)
Step 6: AI Agent Creation
The Agent used in this example is the FunctionCallingAgentWorker from LlamaIndex, which deploys critic reflection on query replies and utilizes the query engine tool to generate improved answers.
from llama_index.core.agent import FunctionCallingAgentWorker
agent_worker = FunctionCallingAgentWorker.from_tools(
[query_engine_tool], llm=llm, verbose=True
)
agent = agent_worker.as_agent()
response = agent.chat("What is the maximum vector dimension supported in Milvus?")
print(str(response))
"""
Output:
Added user message to memory: What is the maximum vector dimension supported in Milvus?
=== LLM Response ===
To answer your question about the maximum vector dimension supported in Milvus, I'll need to consult the Milvus FAQ knowledge base. Let me do that for you.
=== Calling Function ===
Calling function: knowledge_base with args: {"input": "What is the maximum vector dimension supported in Milvus?"}
=== Function Output ===
Milvus supports vectors with up to 32,768 dimensions by default. However, if you need to work with vectors of even higher dimensionality, you have the option to increase the value of the 'Proxy.maxDimension' parameter. This allows Milvus to accommodate vectors with dimensions exceeding the default limit.
=== LLM Response ===
Based on the information from the Milvus FAQ knowledge base, I can provide you with the following answer:
The maximum vector dimension supported in Milvus is 32,768 by default. This means that out of the box, Milvus can handle vectors with up to 32,768 dimensions, which is suitable for most applications.
However, it's important to note that Milvus offers flexibility for cases where you might need to work with even higher-dimensional vectors. If your use case requires vectors with dimensions exceeding 32,768, you have the option to increase this limit. This can be done by adjusting the 'Proxy.maxDimension' parameter in Milvus configuration.
So, to summarize:
1. Default maximum dimension: 32,768
2. Can be increased: Yes, by modifying the 'Proxy.maxDimension' parameter
This flexibility allows Milvus to accommodate a wide range of use cases, from typical machine learning and AI applications to more specialized scenarios that might require extremely high-dimensional vectors.
"""
The output of the Agent provides a more detailed answer, including the source of the information, the reasoning behind the answer, and some additional suggestions related to the topic. This helps us better understand the answers given by the LLM model.
03.
Agentic RAG Architecture
The complete architecture of the Agentic RAG we just built is shown below.
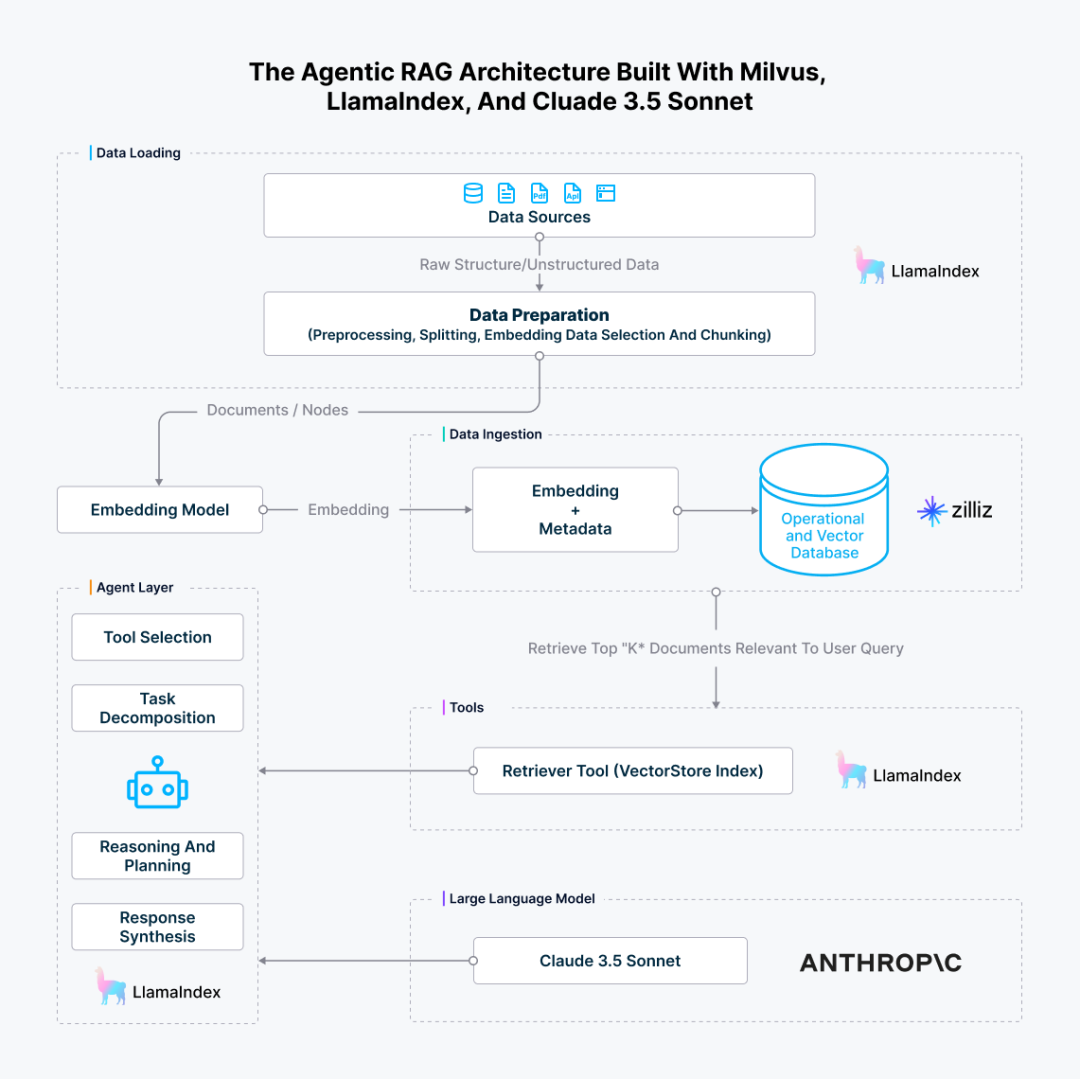
Figure 5: Agentic RAG Architecture Built with Milvus, LlamaIndex, and Claude 3.5 Sonnet
04.
Conclusion
The concept of Compound AI breaks down complex AI systems into multiple independent modules, resulting in greater flexibility, scalability, reusability, and reduced system coupling, greatly enhancing the overall efficiency of the pipeline. Following this concept, the evolution of LLM systems has transitioned from standalone models to more complex architectures that combine RAG and Agents.
In this process, vector database technologies represented by Milvus have significantly improved the efficiency, accuracy, and reliability of systems by providing powerful data management, retrieval, and fusion capabilities. It not only optimizes the performance of modules such as RAG and Agents but also supports multimodal data processing and real-time decision-making, greatly enhancing the flexibility and scalability of systems.
If you are interested in the above case or want to learn more about Milvus, feel free to scan the QR code at the end of the article for further communication.
Author: Benito Martin
Recommended Reading