

Introduction by AliMei: With the rapid development of deep learning technologies, especially CNN and RNN, OCR technology has seen significant advancements in recent years. Meanwhile, under the trend of intelligent terminals, localized intelligent recognition has gained attention and favor due to its efficient and fast experience, high privacy protection, and zero traffic consumption. More and more application algorithms are starting to favor terminal completion, and OCR is no exception. Next, Ant Financial’s algorithm expert Yi Xian will analyze this lightweight and precise mobile OCR engine – xNN-OCR.
Background and Overview
Advantages of Mobile OCR
Due to the limitations of algorithm efficiency and model size, most OCR applications currently upload images to the server for recognition and then return the results to the client. While this meets some business needs, it results in a significant loss in user experience, especially in scenarios requiring high responsiveness, particularly in weak network environments. Additionally, during high-demand business events with excessive concurrent requests, the server often has to adopt downgrade strategies. If the terminal also possesses recognition capabilities, it can greatly reduce the server’s load. Moreover, when it comes to sensitive personal documents like ID cards and bank cards, using OCR for information extraction with an ‘instant destruction’ approach on the terminal provides a natural fortress for data protection. Therefore, having terminal OCR recognition capabilities holds extremely important business value and significance.
Challenges of Mobile OCR
While deep learning technology ensures a certain level of recognition accuracy in specific scenarios, issues regarding model size and speed remain significant challenges on the terminal. Currently, most backend OCR models are typically tens or hundreds of megabytes, which can exceed the size of the entire app installation package, making it impossible to deploy directly on mobile devices. Furthermore, if real-time downloading is employed, large models can lead to high failure rates, long wait times, large app sizes, and high data consumption. Additionally, many OCR algorithms running on cloud GPUs still require tens to hundreds of milliseconds, making it a huge challenge to maintain high operational efficiency on mobile CPUs.
What Did We Do? – xNN-OCR
xNN-OCR is a high-precision, high-efficiency, lightweight text recognition engine specifically developed for local recognition on mobile devices. It currently supports the recognition of scene digits, English, Chinese characters, and special symbols. xNN-OCR has developed and optimized a set of deep learning-based text detection and recognition algorithms tailored for mobile devices. By leveraging xNN’s network compression and acceleration capabilities, the detection and recognition models can be compressed to several hundred kilobytes, achieving real-time performance (up to 15 FPS) on mid-range and higher mobile CPUs, allowing for a ‘what you see is what you get’ experience in video streams combined with the ‘scan’ mode.
Mobile OCR Recognition Technology
Mobile OCR technology mainly consists of two aspects: one is the research and optimization of the OCR algorithm framework, with the primary goal of exploring high-precision and lightweight detection and recognition frameworks, ensuring that the model size and speed are within an appropriate range before compression; the second is to utilize xNN for pruning and quantization of the model to the size required for practical applications. The following diagram showcases the entire compression process of the bank card detection and recognition model, demonstrating the changes in accuracy and model size, with similar processes for other OCR scene recognitions.
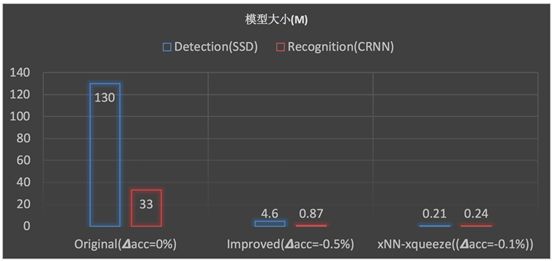
Bank Card Detection/Recognition Model Compression
Exploration of Lightweight OCR Algorithm Framework
Currently, most mobile OCR technologies primarily rely on traditional algorithms, which have relatively low recognition rates in complex natural scenes. In contrast, deep learning-based solutions can effectively address these issues, achieving recognition rates and stability far superior to traditional algorithms. The mainstream deep learning OCR can be divided into two main components: text line detection and line recognition, which we will introduce separately below:
★ Text Line Detection
In detection, we combined the Region-CNN framework of object detection with the FCN image segmentation framework, retaining the simplicity of the FCN framework to meet the model size and prediction time requirements on the terminal. We also added a location regression module for target detection within the model, enabling the detection of text in arbitrary shapes. Within the overall FCN framework, various model simplification structures (such as Separable Convolution, Group Convolution + Channel Shuffle, etc., as shown below) were employed to ensure that while the model size continuously decreases, the accuracy does not decline. This approach achieved good detection results while meeting the stringent requirements of the terminal.

Separable Convolution
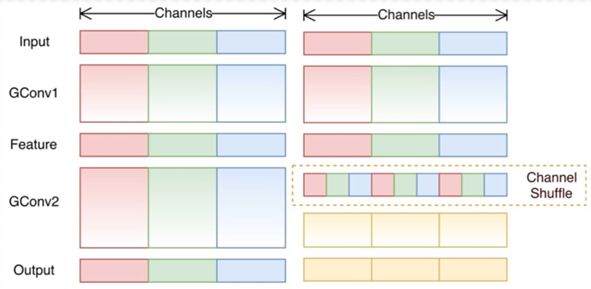
Group Convolution + Channel Shuffle
★ Text Line Recognition
In recognition, we optimized the CRNN (CNN+LSTM+CTC) framework, designing a lightweight CNN network specifically for mobile text line recognition by combining Densenet with Multiscale Feature and Channel-wise Attention techniques. Additionally, we employed projection techniques for LSTM internal parameters and dimensionality reduction techniques like SVD and BTD for the fully connected layers to further reduce the number of parameters (as shown below). On the ICDAR2013 dataset (NOFINETUNE), the model size decreased by approximately 50%, while the recognition rate improved by nearly 4 points compared to CRNN, establishing a strong foundation for the upper end.
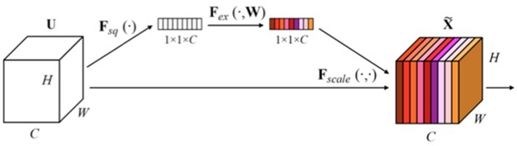
Channel-wise Attention
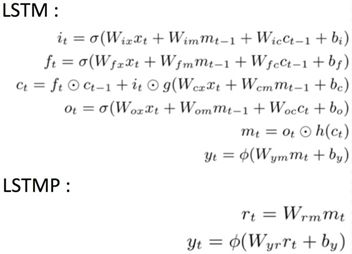
LSTM Projection
★ xNN Model Compression
Currently, our OCR algorithm models are developed based on TensorFlow, and xNN has added support for TFLite models, significantly outperforming TFLite in terms of performance. The compression ratio of xNN for our OCR algorithm models ranges from 10 to 20 times, varying slightly between different scenarios. Meanwhile, the accuracy of the compressed models remains largely unchanged. Since OCR is a complex recognition task, the algorithm models are usually very large, and most backend OCR algorithms run on GPUs. To run on the terminal, extensive optimizations at the algorithm level are required, along with xNN’s powerful model compression and acceleration capabilities.
Applications of Mobile OCR
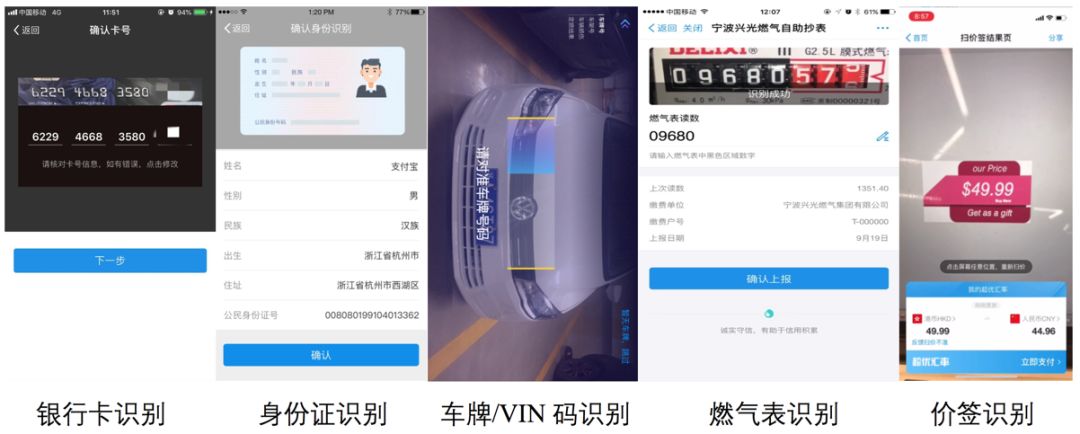
OCR technology is one of the most important technical means for information extraction and scene understanding, with a wide range of applications. Currently, mobile local OCR applications can be divided into two major categories from a technical perspective: one category is printed text recognition, mainly targeting scenes with little font variation and simple backgrounds, such as ID card recognition, business card recognition, and license plate recognition; the other category is scene text recognition, primarily addressing scenarios with significant font variation and complex backgrounds, such as bank card recognition, gas meter/water meter recognition, storefront name recognition, and scene English recognition (AR translation). The latter category presents greater challenges in terms of recognition difficulty. We have applied xNN-OCR to these scenarios and optimized it based on the characteristics of each scene, achieving a series of results, particularly maintaining efficiency and accuracy in complex environments. The specific data is summarized in the table below. Here are some important and common application scenarios.
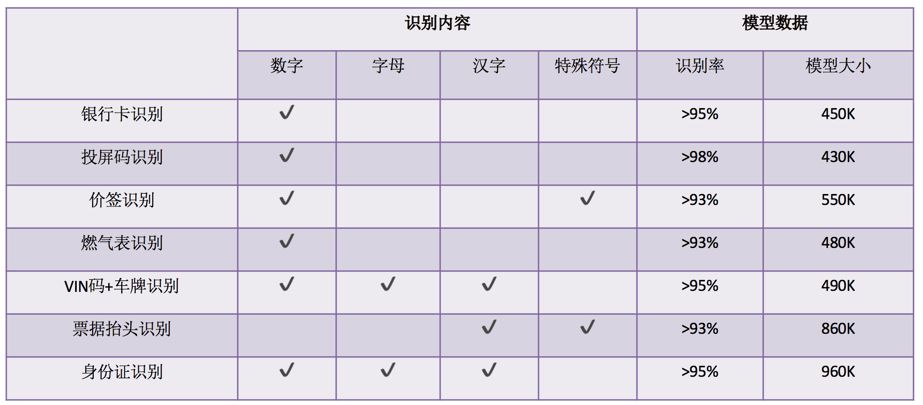
OCR Business Scenario Data Metrics
-
Bank Card Recognition: Bank card recognition is a crucial technology in the financial industry and a typical representative of scene digit recognition. Currently, most bank card recognition solutions use terminal recognition, which not only provides a better and faster experience but also protects user privacy since data upload is unnecessary. The bank card recognition developed based on xNN-OCR takes <300ms on mid-range phones, with most bank cards recognized in seconds. Furthermore, xNN-OCR demonstrates significant advantages in speed and accuracy when dealing with complex backgrounds and environmental interferences.
-
Gas Meter Recognition: OCR for gas meter reading is a key technology in current self-service gas meter reading. Compared to traditional on-site readings, it saves significant manpower and resources, avoiding the inconveniences of on-site reading. Additionally, it reduces issues like missed or incorrect readings. Many gas companies have started applying this technology, but in practical applications, gas meters are sometimes positioned in concealed locations, making it difficult to control shooting angles and lighting. Typically, the quality of images uploaded by general users for backend recognition is poor, leading to low recognition rates. xNN-OCR completes the entire recognition process on the terminal and guides users in capturing images through feedback, significantly improving the recognition rate. In collaboration with a gas company, we tested a recognition rate of over 93%, keeping the model size under 500k, with successful recognition taking <1s.
-
License Plate/VIN Code Recognition: License plate/VIN code recognition is a classic scenario for traditional printed text applications, playing a crucial role in daily scenes like mobile policing and vehicle repair assessments. Since license plate/VIN code recognition may require simultaneous processing in practical applications, xNN-OCR combines the recognition of both scenarios into one, maintaining a model size of <500k, with successful recognition on mid-range phones taking <1s. It is also insensitive to interferences such as lighting, blurriness, and shooting angles. Moreover, since the terminal can repeatedly recognize to seek the highest confidence result as the final output, it achieves higher recognition accuracy compared to backend recognition, which is a one-time deal.
-
ID Card Recognition: ID card recognition is also a very important technology in the financial industry, playing a crucial role in real-name verification and security audits. However, due to the large Chinese character library, the model size tends to be large. Currently, most ID card recognition solutions rely on server-side recognition, but controlling the quality on the terminal can be challenging, often leading to difficulties in balancing experience and accuracy. xNN-OCR has made breakthroughs in recognizing large character libraries, with an overall model size of less than 1M. It controls recognition accuracy through single character recognition confidence, avoiding reliance on image quality judgments, and enhances recognition efficiency through multi-frame fusion, achieving recognition times of <600ms on mid-range phones, with successful recognition in <2s.
Outlook
xNN-OCR can currently recognize scene digits, English, and some Chinese characters on the terminal, achieving industrial application levels in terms of model size, speed, and accuracy, and fully surpassing traditional algorithm-based OCR applications on the terminal, validated in multiple practical application projects. Additionally, we have made achievements in recognizing over 7000 types of Chinese characters on the terminal, which we will share in the near future. We welcome interested individuals to research and discuss together.
We firmly believe that as the mobile deployment of deep learning gradually strengthens and mobile hardware devices continue to upgrade, there will be an increasing number of intelligent applications and businesses on the terminal. In the future, xNN-OCR will undoubtedly bring deeper impacts and higher value to OCR-related businesses.
Technical Salon Registration
The ICDE 2019 (35th International Conference on Data Engineering) will be held from April 8 to April 11 in Macau, China. We will host a technical session themed “Databases in the Cloud Era” at the Parisian Macau on April 9, featuring exciting talks on the latest products and technological innovations, including the next-generation self-developed cloud-native database POLARDB and the OLAP database AnalyticDB. We look forward to your participation!
For detailed agenda and registration, please click on “Read the Original” at the end of this article.

You May Also Like
Click the image below to read

Today, only happy mathematics is discussed in Alibaba’s report hall

Alibaba Open Source OpenJDK Long-term Support Version Alibaba Dragonwell

Alibaba’s 2019 Internship Recruitment Has Officially Started!