
Background
After the “14th Five-Year Plan” elevated digital government to a national strategic priority, this year’s Two Sessions once again highlighted the digital economy and smart cities as focal points of interest. On March 5, the “Government Work Report” emphasized strengthening the construction of digital government and promoting the sharing of government data. Smart governance aims to assist in governmental decision-making, optimize business processes, and enhance the service experience for enterprises and citizens, making it a key initiative for improving government regulatory efficiency and public service capabilities, particularly within smart cities.
Government governance mainly refers to scenarios related to government affairs in smart cities, including: information collection, review, and services. A good level of government governance can provide convenient and efficient handling experiences for people’s livelihoods, increase civil communication and interaction, and facilitate the digital construction of government information for easier querying and retrieval.
As the pace of digital transformation accelerates across various industries in China, more citizens are experiencing the convenience brought by digitalization. The demand for digital transformation in government governance, which is closely related to the public, is becoming increasingly urgent, such as:
-
Scenario 1: During epidemic prevention, population census, and passenger flow sampling surveys, various functional departments need to collect and manage citizens’ ID card or household registration information in bulk offline. The traditional method of manually registering each entry requires significant manpower, is time-consuming, and cannot meet the urgent needs of these matters;
-
Scenario 2: When citizens handle government services online, they often need to verify identity information, but the cumbersome manual input process can slow down the handling speed and affect the user experience;
-
Scenario 3: In the past, government systems primarily used paper documents to convey announcements and documents. As the accumulation of documents increases, the process of finding certain important documents becomes cumbersome. Although electronic government systems are continually upgrading, the systems are not yet fully interconnected, and the transmission of paper documents is sometimes unavoidable.
PaddleOCR’s PP-OCRv2 and PP-Structure solutions support intelligent urban governance.
Paddle’s Intelligent Governance Solutions
Government governance mainly refers to scenarios related to government affairs in smart cities, including: information collection, review, and services, with the main business scenarios and corresponding Paddle solutions illustrated below:

Government Governance Overview
Government governance can be divided into five sub-scenarios based on the information collection and processing workflow: on-site data collection, online government services, electronic documentation, government information review, and government Q&A systems.
Depending on the objects being collected, the above scenarios can be categorized into:
-
Information collection scenarios for ID cards, household registration books, and driver’s licenses;
-
Document digitization scenarios for densely formatted documents such as files and announcements;
-
Natural language processing scenarios for text information classification, generation, review, and Q&A.
The first two scenarios primarily involve computer vision tasks focused on image processing, while the last scenario mainly addresses natural language processing tasks related to textual information. This article focuses on visual-related scenarios and AI technologies.
Using PP-OCRv2 for Automatic Collection of Document Information
During epidemics, population censuses, and passenger flow sampling surveys, government personnel need to quickly collect citizens’ document information. Based on deep learning text recognition technology, it can quickly and accurately extract text information such as names and ID numbers from documents, with low sensitivity to image quality, significantly reducing information collection costs and effectively addressing the limitations of traditional technologies in natural scenes, which struggle to handle issues like slant, blur, and shadow.

PP-OCRv2 Key Information Extraction Illustration
The PaddleOCR text recognition development kit has open-sourced an industry-grade SOTA text recognition solution called PP-OCRv2, which includes detection, orientation classification, and recognition models, capable of recognizing Chinese, English, numbers, and vertical text, with a size of only 13M. In some scenarios, fine-tuning with a small amount of real data can achieve effective results. It is now widely used in various document recognition scenarios.

Online experience address: https://www.paddlepaddle.org.cn/hub/scene/ocr
Using PP-Structure for Structuring Government Documents
Due to various limitations, government systems inevitably still use paper documents to convey announcements and files, leading to difficulties in retrieval and lack of structured information management.
Document information collection is a natural scene-oriented task in government governance, where text form features are diverse. Ensuring universal recognition capability is key for AI technology, while document digitization is an important application scenario for document objects in government governance. For document scenarios primarily involving documents, tables, and receipts, text information is often dense, and besides obtaining text information, there is also a desire to automatically delineate document areas and structurally extract tables.
PaddleOCR has open-sourced a solution for document structuring called PP-Structure, which supports layout analysis and table recognition, key information extraction, and visual Q&A tasks to meet the needs of government document digitization.
-
Supports layout analysis of document images, dividing them into five categories: text, titles, tables, images, and lists;
-
Supports structural extraction of table areas, with final results output as Excel files;
-
Supports visual document Q&A and key information extraction tasks, capable of extracting key information from images.
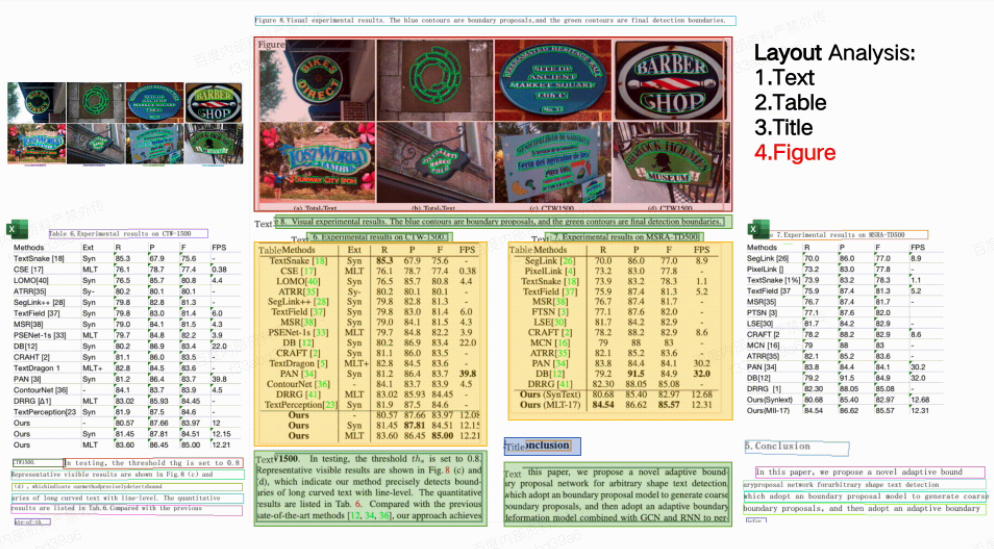
PP-Structure Layout Analysis Illustration
PaddleOCR Text Recognition Development Kit
PP-Structure and PP-OCRv2 are solutions designed by PaddleOCR for different business scenarios. In industrial implementation, PaddleOCR provides a comprehensive solution covering data generation, semi-automatic labeling, integrated training and deployment, and multi-end multi-platform deployment, enabling rapid model training and deployment, as illustrated below. In terms of the richness of the model library, PaddleOCR offers 4 text detection algorithms, 8 text recognition algorithms, 1 end-to-end algorithm, and 80 multilingual models, facilitating developers’ secondary development based on business needs.
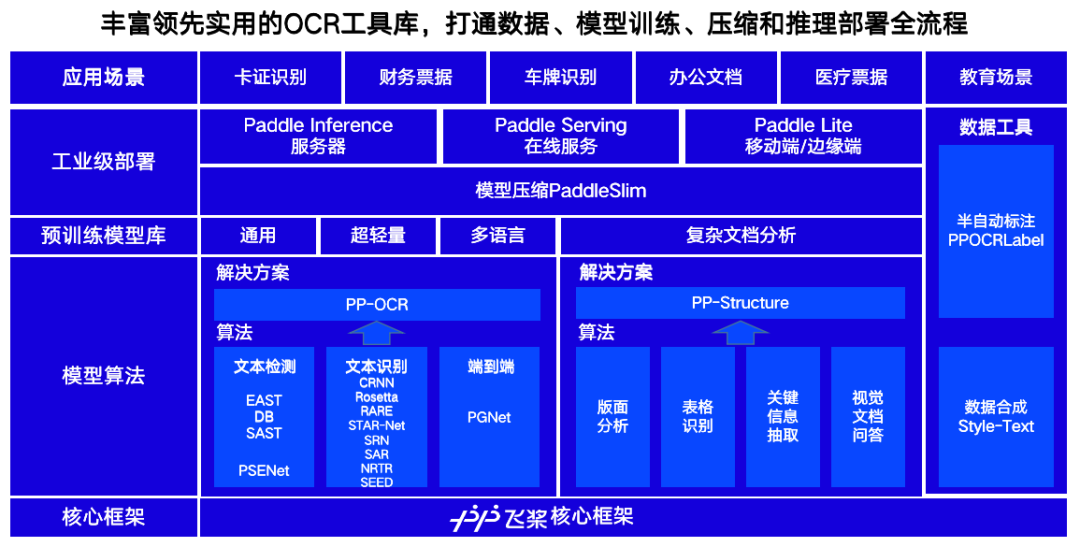
PaddleOCR Overview
Industry Application Case: Honglian Company’s Intelligent Electronic Evidence Analysis Case
Honglian Network Technology Company is an electronic evidence company that often needs to browse a large number of images to find key information that plays a crucial role in determining cases. Traditional methods are time-consuming and labor-intensive, while utilizing AI capabilities to classify image information and extract text content enables rapid localization and analysis of key information.

In the design of the solution, Honglian Company classifies massive images into three categories: people, documents, and certificates using image classification technology, and then utilizes text recognition capabilities to extract text information from images, achieving image text retrieval. For images of people, face detection, segmentation, and matching technologies are used to achieve rapid identification of individuals.
During the implementation process, Honglian Company adopted staged integrated learning, automated training, and other technologies, using the PP-OCRv2 model and PP-YOLOv2 model to complete text recognition and object detection tasks, achieving a good balance between recognition effectiveness and parsing speed.
Paddle official website: https://www.paddlepaddle.org.cn
PaddleOCR project address: https://github.com/PaddlePaddle/PaddleOCR
Course Live Broadcast Announcement
Paddle has thoughtfully prepared a live broadcast course for everyone, starting with core technical theories, combined with enterprise users personally explaining application cases and insights, thoroughly analyzing the technical difficulties, pain points, and solutions in smart governance business scenarios, making it understandable, learnable, and usable. The live broadcast will be held on March 25th from 20:00 to 21:30, and industry partners interested are welcome to participate and exchange ideas.
Scan to register for the live course and join the technical exchange group

More Exciting Content to Look Forward To
