Introduction
Currently, there are many OCR models in open source projects, but there is no unified benchmark to measure which one is better. Faced with so many models, we are somewhat at a loss. Therefore, I have been wanting to build such a benchmark for some time, and it seems to have taken shape.
To better evaluate the performance of various models, I have collected two annotated open-source test sets:
-
text_det_test_dataset[1] -
text_rec_test_dataset[2]
To facilitate the calculation of various model metrics, I have organized two libraries for commonly used metrics:
-
TextDetMetric[3] -
TextRecMetric[4]
The following results are based on the above four libraries, and the metric results only represent the performance on the specified test sets; they do not imply that the results on other test sets will be the same, and are for reference only.
The inference times in the following tables are based on runs on a MacBook Pro M2, and different machines may yield different results. Please focus on the comparisons between them.
The metric calculations are derived under the same parameters, with differences only in the model files.
For the download links of the corresponding models, please refer to: link[5].
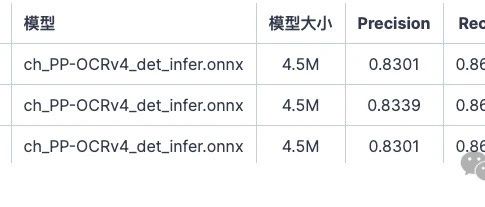
Text Detection Models
Evaluation dependencies:
-
rapidocr_onnxruntime==1.3.16: link[6] -
Metric calculation library TextDetMetric: link[7] -
Test set text_det_test_dataset: link[8]
For more details, you can check AI Studio[9].
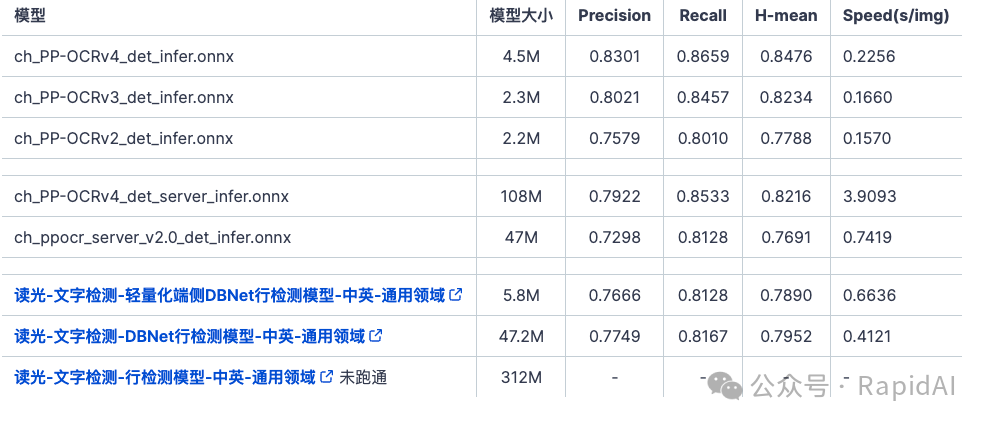
Comparison of results under different inference engines:
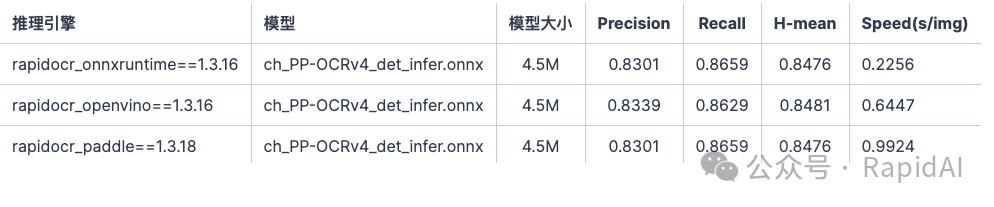
Text Recognition Models
Evaluation dependencies:
-
rapidocr_onnxruntime==1.3.16: link[10] -
Metric calculation library TextRecMetric: link[11] -
Test set text_rec_test_dataset: link[12]
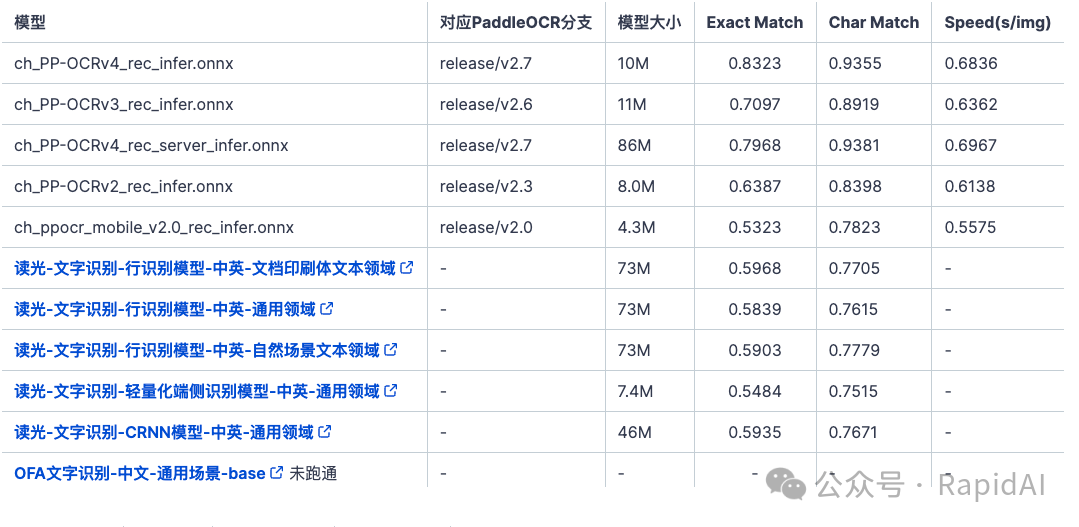
Comparison of results under different inference engines:

-
Input Shape:
-
v2: [3, 32, 320] -
v3~v4: [3, 48, 320] -
Different models, instantiation examples are as follows:
from rapidocr_onnxruntime import RapidOCR # v3 or v4 engine = RapidOCR( rec_model_path="models/ch_PP-OCRv3_rec_infer.onnx", ) # v2 engine = RapidOCR( rec_model_path="models/ch_ppocr_mobile_v2.0_rec_infer.onnx", rec_img_shape=[3, 32, 320], )
References
text_det_test_dataset: https://huggingface.co/datasets/SWHL/text_det_test_dataset
[2]text_rec_test_dataset: https://huggingface.co/datasets/SWHL/text_rec_test_dataset
[3]TextDetMetric: https://github.com/SWHL/TextDetMetric
[4]TextRecMetric: https://github.com/SWHL/TextRecMetric
[5]link: https://rapidai.github.io/RapidOCRDocs/docs/about_model/download_onnx/
[6]link: https://github.com/RapidAI/RapidOCR
[7]link: https://github.com/SWHL/TextDetMetric
[8]link: https://huggingface.co/datasets/SWHL/text_det_test_dataset
[9]AI Studio: https://aistudio.baidu.com/projectdetail/6679889?sUid=57084&shared=1&ts=1693054678460
[10]link: https://github.com/RapidAI/RapidOCR
[11]link: https://github.com/SWHL/TextRecMetric
[12]link: https://huggingface.co/datasets/SWHL/text_rec_test_dataset
For further updates, please click Read Original to obtain.