Can AI completely edit images according to client requirements? With the help of GPT-3 and Stable Diffusion, models can instantly become proficient in Photoshop, allowing for seamless image modifications.
After the rise of diffusion models, many people have focused on how to effectively use prompts to generate the desired images. Through continuous experimentation with various AI drawing models, researchers have even summarized key phrases that lead to better image outputs:

In other words, mastering the correct AI communication can significantly enhance the quality of generated images (see: “How to Draw ‘Llama Playing Basketball’? Someone Paid $13 to Challenge DALL·E 2 to Show Its True Skills”).
Additionally, some researchers are working in another direction: how to verbally modify an image to achieve the desired outcome.
Recently, we reported on research from Google Research and other institutions. By simply stating how you want an image to change, it can essentially meet your requirements and generate photo-realistic images, such as making a dog sit:

The input description given to the model is “a dog sitting”, but the most natural description in everyday conversation would be “make this dog sit”. Some researchers believe this is an issue that should be optimized, and the model should align more closely with human language habits.
Recently, a research team from UC Berkeley proposed a new method for image editing based on human instructions called InstructPix2Pix: given an input image and a textual description of what the model is supposed to do, the model can follow the instructions to edit the image.

Paper link: https://arxiv.org/pdf/2211.09800.pdf
For example, to replace a sunflower with a rose in an image, you simply need to tell the model, “replace the sunflower with a rose”:

To obtain training data, the research combined two large pre-trained models—language model (GPT-3) and text-to-image generation model (Stable Diffusion)—to create a large paired training dataset of image editing examples. Researchers trained the new model InstructPix2Pix on this extensive dataset and generalized it to real images and user-written instructions during inference.
InstructPix2Pix is a conditional diffusion model that generates edited images given an input image and a textual instruction for editing. The model performs image editing directly during the forward pass without requiring any additional example images, complete input/output image descriptions, or fine-tuning for each example, allowing for rapid image editing in just a few seconds.
Although InstructPix2Pix was trained entirely on synthetic examples (i.e., text descriptions generated by GPT-3 and images generated by Stable Diffusion), the model achieved zero-shot generalization to arbitrary real images and human-written text. The model supports intuitive image editing, including object replacement, style changes, and more.

Method Overview
Researchers treat instruction-based image editing as a supervised learning problem: first, they generated a paired training dataset containing text editing instructions and images before and after editing (Figure 2a-c), and then trained a diffusion model for image editing on this generated dataset (Figure 2d). Although the generated images and editing instructions were used during training, the model can still edit real images using any human-written instructions. Below is an overview of the method shown in Figure 2.

Generating a Multimodal Training Dataset
During the dataset generation phase, researchers combined the capabilities of a large language model (GPT-3) and a text-to-image model (Stable Diffusion) to create a multimodal training dataset containing text editing instructions and corresponding images before and after editing. This process involves the following steps:
-
Fine-tuning GPT-3 to generate a collection of text editing content: given a prompt describing an image, generate a text instruction describing the changes to be made and a prompt describing the image after the changes (Figure 2a);
-
Using the text-to-image model to convert the two text prompts (i.e., before and after editing) into a pair of corresponding images (Figure 2b).
InstructPix2Pix
Researchers used the generated training data to train a conditional diffusion model based on the Stable Diffusion model, capable of editing images according to written instructions.
The diffusion model learns to generate data samples through a denoising autoencoder that estimates data distribution scores (pointing towards high-density data). Latent diffusion operates in the latent space of a pre-trained variational autoencoder with an encoder and decoder
and decoder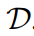 to enhance the efficiency and quality of the diffusion model.
to enhance the efficiency and quality of the diffusion model.
For an image x, the diffusion process adds noise to the encoded latent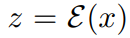 to produce a noisy latent z_t, where the noise level increases with time step t∈T. The researchers learn a network
to produce a noisy latent z_t, where the noise level increases with time step t∈T. The researchers learn a network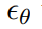 that predicts the noise added to the noisy latent z_t, given image adjustment C_I and text instruction adjustment C_T. The researchers minimize the following latent diffusion objective:
that predicts the noise added to the noisy latent z_t, given image adjustment C_I and text instruction adjustment C_T. The researchers minimize the following latent diffusion objective:
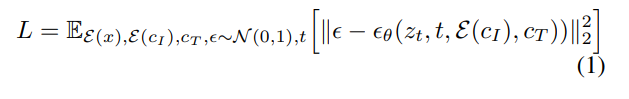
Previous studies (Wang et al.) have shown that for image translation tasks, especially when paired training data is limited, fine-tuning a large image diffusion model outperforms training from scratch. Therefore, in the new study, the authors initialized the model’s weights using a pre-trained Stable Diffusion checkpoint, leveraging its powerful text-to-image generation capabilities.
To support image adjustments, the researchers added extra input channels to the first convolutional layer, connecting z_t and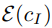 . All available weights of the diffusion model were initialized from the pre-trained checkpoint, while the weights running on the newly added input channels were initialized to zero. The authors reused the same text adjustment mechanism initially used for captions without treating text editing instructions c_T as input.
. All available weights of the diffusion model were initialized from the pre-trained checkpoint, while the weights running on the newly added input channels were initialized to zero. The authors reused the same text adjustment mechanism initially used for captions without treating text editing instructions c_T as input.
Experimental Results
In the images below, the authors showcase the image editing results of their new model. These results target a variety of real photos and artworks. The new model successfully performed many challenging edits, including object replacement, changing seasons and weather, replacing backgrounds, modifying material properties, converting art mediums, and more.




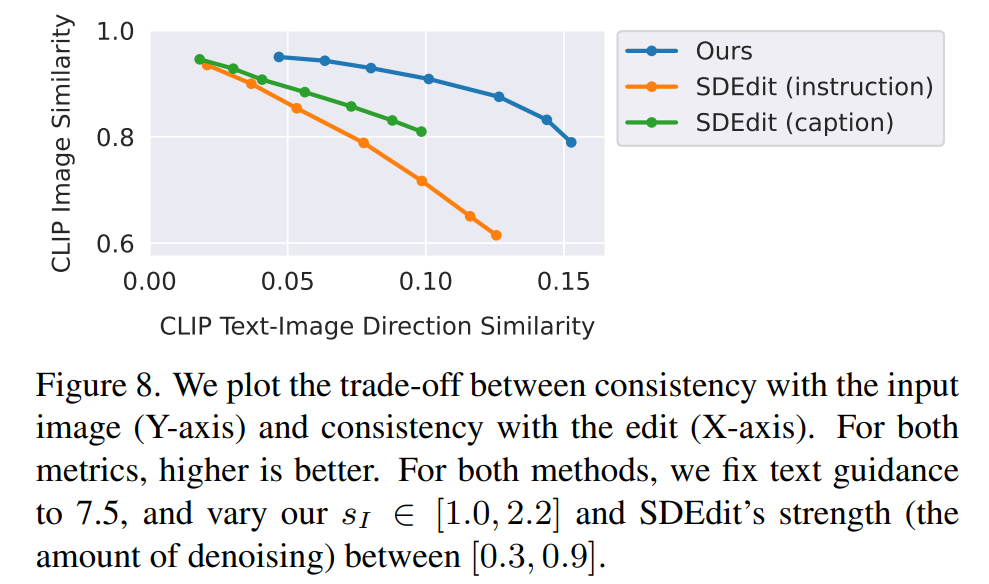
The researchers compared their new method with some recent techniques, such as SDEdit and Text2Live. The new model follows the instructions to edit images, while other methods (including baseline methods) require descriptions of the image or editing layers. Therefore, in the comparison, the authors provided “after editing” text annotations instead of editing instructions for the latter. The authors also quantitatively compared the new method with SDEdit, using two metrics to measure image consistency and editing quality. Finally, the authors presented ablation results showing how the size and quality of the generated training data affect model performance.