
Source: Machine Learning Grocery Store
This article is approximately 1800 words long and suggests a reading time of 10 minutes.
One of the most challenging parts of the ML workflow is finding the best hyperparameters for the model. The performance of ML models is directly related to hyperparameters.
Introduction
Wikipedia states, “Hyperparameter optimization or tuning is the problem of choosing a set of optimal hyperparameters for a learning algorithm.”
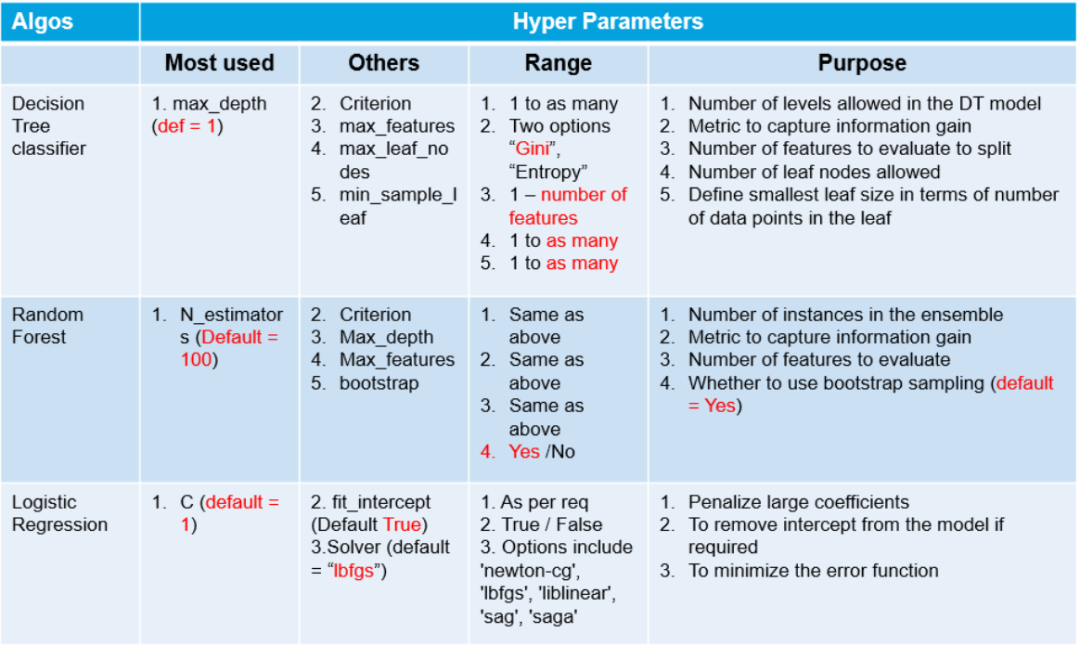
Hyperparameters
Contents
-
Traditional Manual Tuning
-
Grid Search
-
Random Search
-
Bayesian Search
1. Traditional Manual Search
# importing required libraries
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold, cross_val_score
from sklearn.datasets import load_wine
wine = load_wine()
X = wine.data
y = wine.target
# splitting the data into train and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=14)
# declaring parameters grid
k_value = list(range(2, 11))
algorithm = ['auto', 'ball_tree', 'kd_tree', 'brute']
scores = []
best_comb = []
kfold = KFold(n_splits=5)
# hyperparameter tuning
for algo in algorithm:
for k in k_value:
knn = KNeighborsClassifier(n_neighbors=k, algorithm=algo)
results = cross_val_score(knn, X_train, y_train, cv=kfold)
print(f'Score: {round(results.mean(), 4)} with algo = {algo}, K = {k}')
scores.append(results.mean())
best_comb.append((k, algo))
best_param = best_comb[scores.index(max(scores))]
print(f'\nThe Best Score : {max(scores)}')
print(f"['algorithm': {best_param[1]}, 'n_neighbors': {best_param[0]}]")
# Disadvantages:
-
There is no way to ensure the best parameter combination is obtained.
-
This is a trial-and-error process, which is very time-consuming.
2. Grid Search
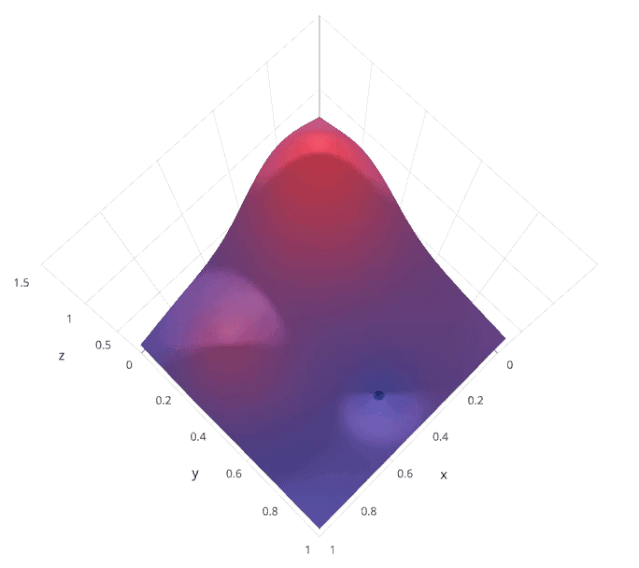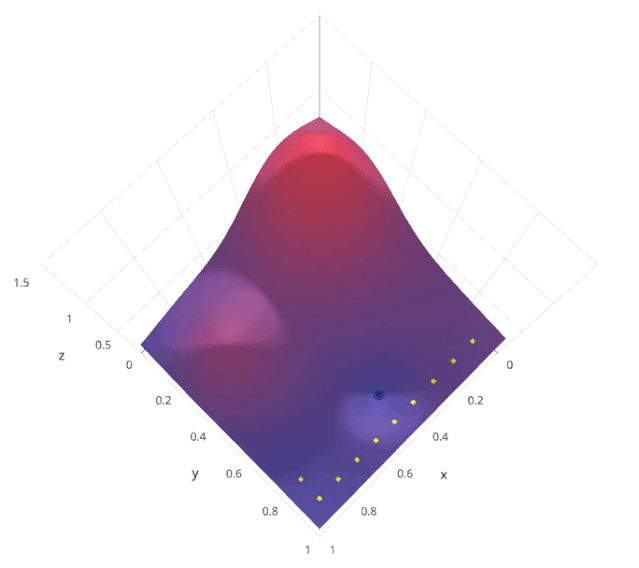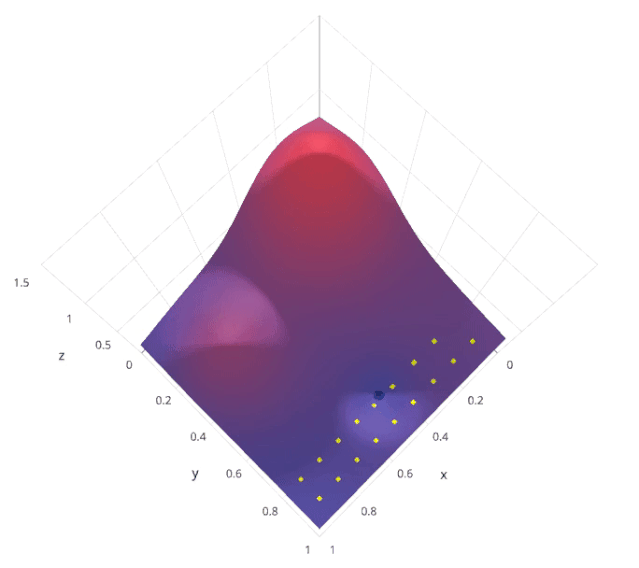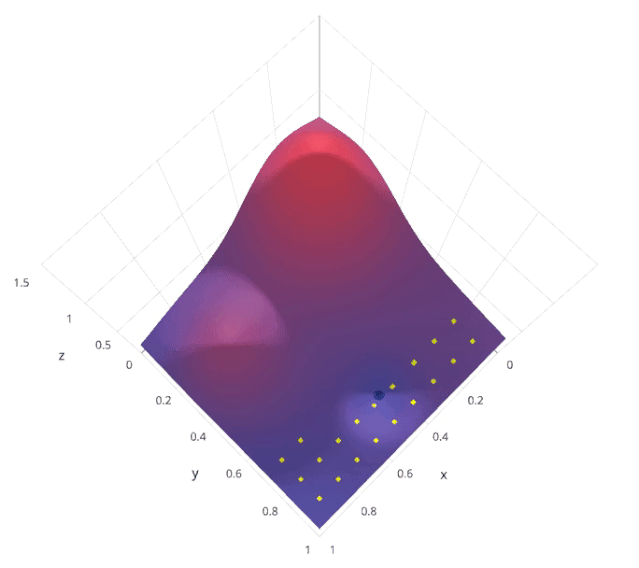
from sklearn.model_selection import GridSearchCV
knn = KNeighborsClassifier()
grid_param = { 'n_neighbors': list(range(2, 11)), 'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'] }
grid = GridSearchCV(knn, grid_param, cv=5)
grid.fit(X_train, y_train)
# best parameter combination
grid.best_params_
# Score achieved with best parameter combination
grid.best_score_
# all combinations of hyperparameters
grid.cv_results_['params']
# average scores of cross-validation
grid.cv_results_['mean_test_score']
# Disadvantages:
3. Random Search
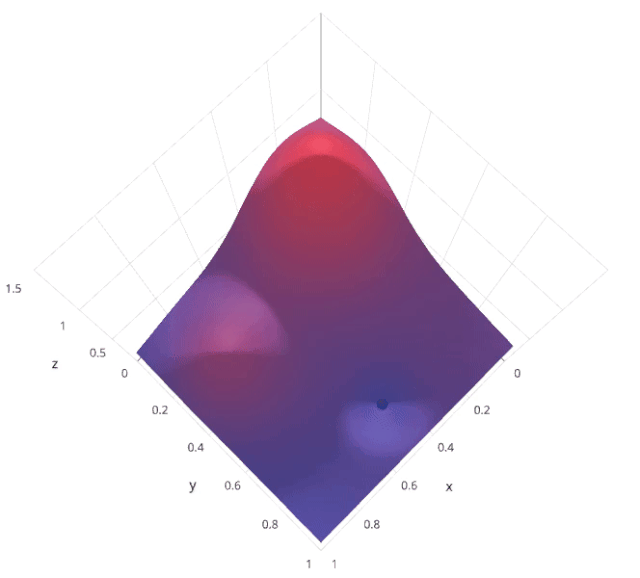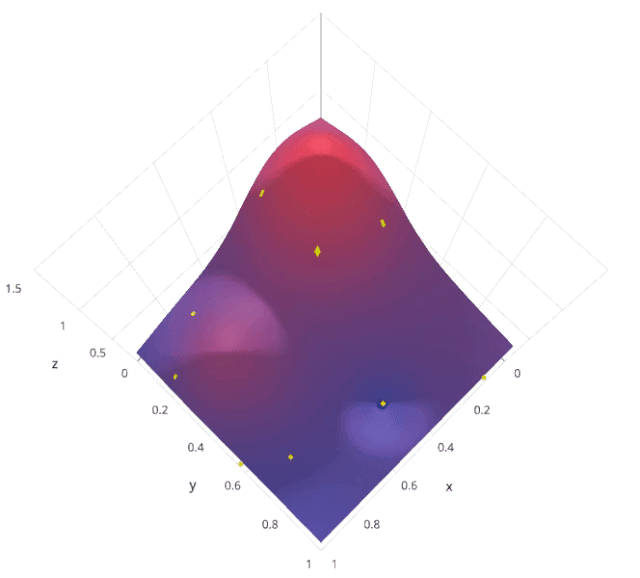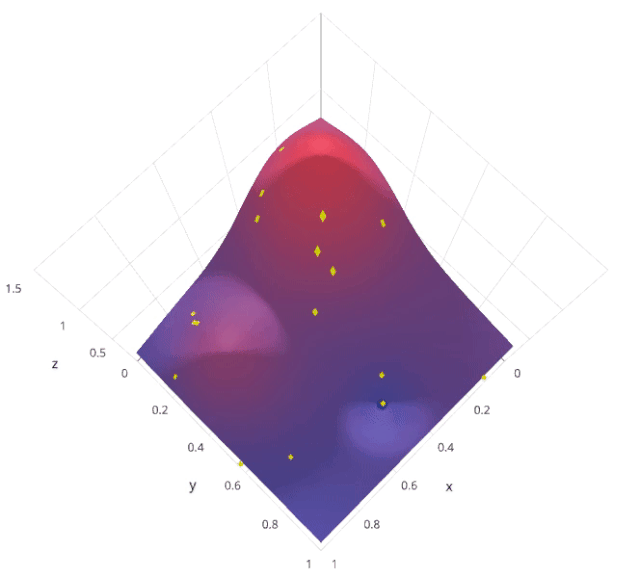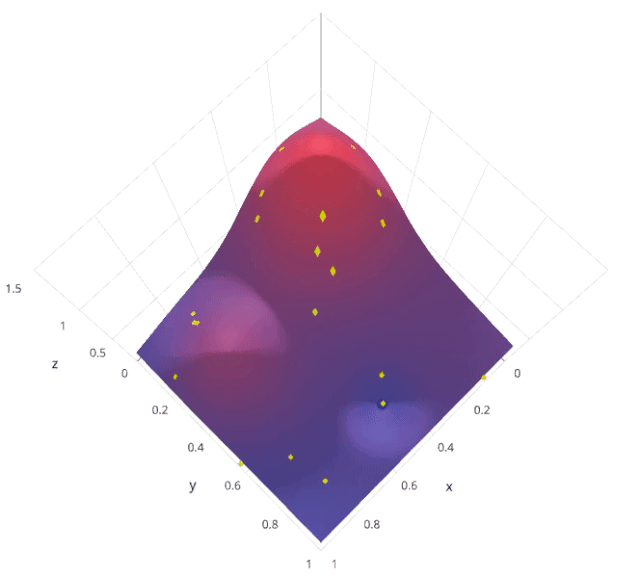
from sklearn.model_selection import RandomizedSearchCV
knn = KNeighborsClassifier()
grid_param = { 'n_neighbors': list(range(2, 11)), 'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'] }
rand_ser = RandomizedSearchCV(knn, grid_param, n_iter=10)
rand_ser.fit(X_train, y_train)
# best parameter combination
rand_ser.best_params_
# score achieved with best parameter combination
rand_ser.best_score_
# all combinations of hyperparameters
rand_ser.cv_results_['params']
# average scores of cross-validation
rand_ser.cv_results_['mean_test_score']
4. Bayesian Search
-
Calculate the posterior expectation of the loss f using previously evaluated points X1*:n*.
-
Sample the loss f at new points X, thereby maximizing some method of the expectation of f. This method specifies which regions of the f domain are best suited for sampling.
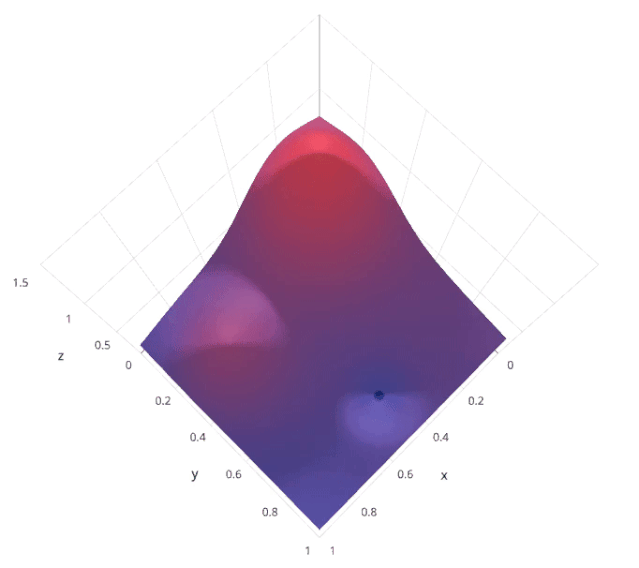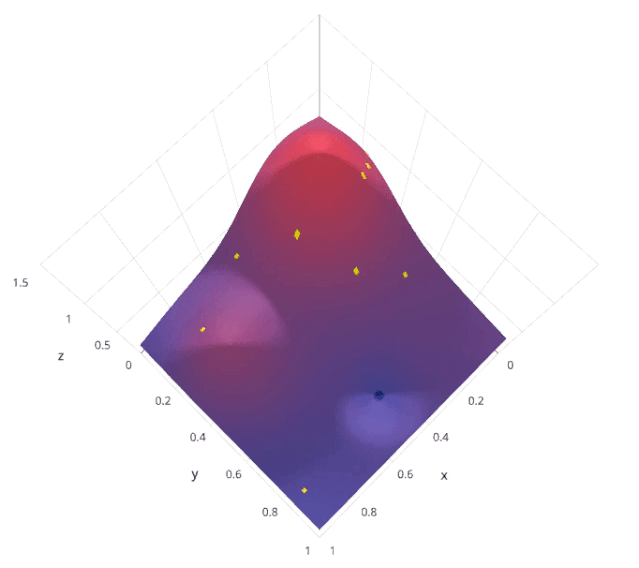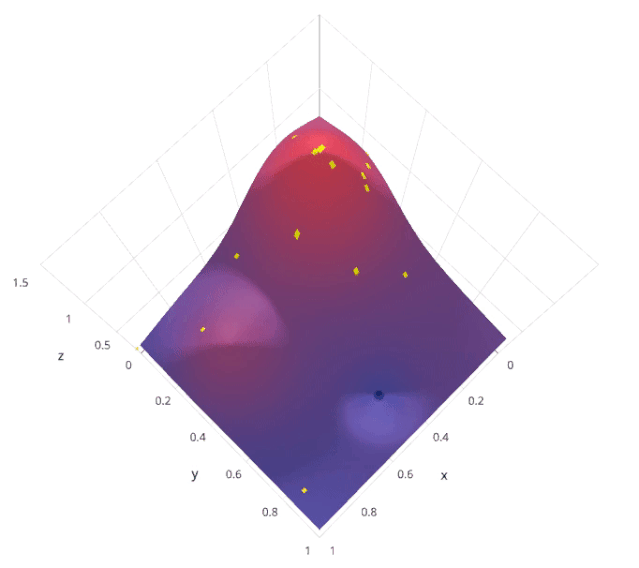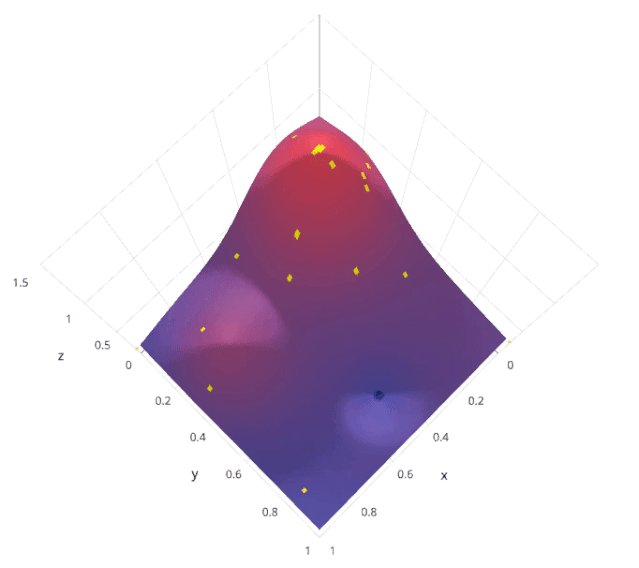
Installation: pip install scikit-optimize
from skopt import BayesSearchCV
import warnings
warnings.filterwarnings("ignore")
# parameter ranges are specified by one of below
from skopt.space import Real, Categorical, Integer
knn = KNeighborsClassifier()
# defining hyper-parameter grid
grid_param = { 'n_neighbors': list(range(2, 11)), 'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'] }
# initializing Bayesian Search
Bayes = BayesSearchCV(knn, grid_param, n_iter=30, random_state=14)
Bayes.fit(X_train, y_train)
# best parameter combination
Bayes.best_params_
# score achieved with best parameter combination
Bayes.best_score_
# all combinations of hyperparameters
Bayes.cv_results_['params']
# average scores of cross-validation
Bayes.cv_results_['mean_test_score']
# Another library to implement Bayesian search is bayesian-optimization.
Installation: pip install bayesian-optimization
Conclusion
Editor: Huang Jiyan