Click the above “Beginner’s Guide to Vision“, select to add “Star” or “Top“
Heavyweight content delivered first time
Author: Savaram Ravindra
Source: mindmajix.com
Image recognition is a fascinating and challenging research field. This article elaborates on the concepts, applications, and techniques of convolutional neural networks for image recognition.
What is Image Recognition and Why Use It?
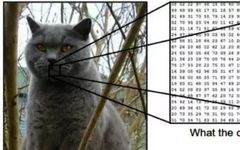
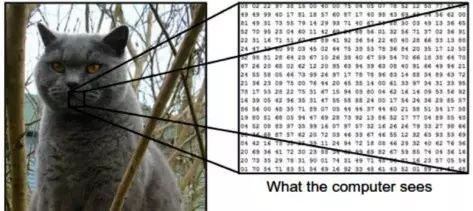
In the field of machine vision, image recognition refers to the ability of software to recognize people, scenes, objects, actions, and the content of images. To achieve image recognition, computers can combine artificial intelligence software with cameras using machine vision technology.
While human and animal brains easily recognize objects, computers struggle with the same task. When we look at things like trees, cars, or friends, we typically do not need to consciously learn to judge what they are. However, for computers, recognizing anything (be it a clock, chair, human, or animal) is a very difficult problem, and the risks associated with finding solutions to this problem are very high.
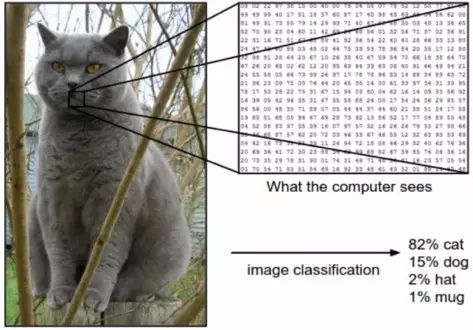
Image: CS231.github
Image recognition is a machine learning method designed to mimic the functions of the human brain. Through this method, computers can recognize visual elements in images. By relying on large databases and emerging patterns, computers can understand images and formulate relevant labels and categories.
Popular Applications of Image Recognition
Image recognition has various applications. The most common and popular is personal photo management. The user experience of photo management applications is improving through image recognition. In addition to providing photo storage, applications also offer better discovery and search functionalities. They can achieve this through automatic image organization provided by machine learning. The image recognition API integrated into the application classifies images based on recognized patterns and groups them by themes.
Other applications of image recognition include panoramic photo galleries and video sites, interactive marketing and creative campaigns, facial and image recognition on social networks, and image classification for websites with large visual databases.
Image Recognition is a Daunting Task
Image recognition is not an easy task. One effective way to achieve it is to apply metadata to unstructured data. Hiring human experts to manually label music and movie libraries can be a daunting task, but when it comes to challenges like distinguishing pedestrians from various other vehicles in the navigation systems of self-driving cars or filtering, classifying, or tagging the millions of user-uploaded videos and photos displayed daily on social media, it becomes almost unattainable.
One solution to this problem is to leverage neural networks. We can theoretically analyze images using traditional neural networks, but in practice, from a computational perspective, the costs can be very high. For example, a typical neural network attempting to process small images (making them 30 * 30 pixels) still requires 500,000 parameters and 900 inputs. A powerful machine can handle this, but once the images become larger (e.g., reaching 500 * 500 pixels), the number of required parameters and inputs increases to very high levels.
Another issue related to the application of image recognition neural networks is overfitting. Simply put, overfitting occurs when a model is too closely aligned with the data it has already been trained on. Generally, this leads to additional parameters (further increasing computational costs) and the model’s exposure to new data results in a decline in general performance.
Convolutional Neural Networks
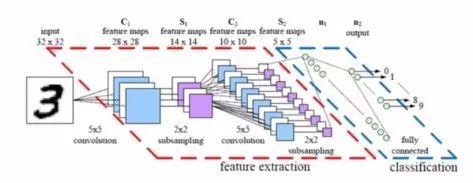
Convolutional Neural Network architecture model
In terms of the structure of neural networks, a relatively simple variation can make larger images more manageable. The result is what we call CNN or ConvNets (Convolutional Neural Networks).
The general applicability of neural networks is one of their advantages, but this advantage becomes a hindrance when processing images. Convolutional neural networks make interesting trade-offs: if a network is specifically designed for processing images, then some generality must be sacrificed for a more feasible solution.
If you consider any image, proximity has a strong correlation with similarity, and convolutional neural networks explicitly exploit this fact. This means that in a given image, two pixels that are closer to each other are more likely to be related than two pixels that are further apart. However, in a general neural network, each pixel is connected to every single neuron. The increased computational load makes the network less accurate in this case.
By stopping many of these less important connections, convolutional networks solve this problem. In technical terms, convolutional neural networks manage image processing by filtering connections based on proximity. In a given layer, convolutional neural networks do not connect every input to every neuron; instead, they intentionally limit the connections so that any single neuron only receives input from a small portion of the previous layer (e.g., 5 * 5 or 3 * 3 pixels). Thus, each neuron is responsible for processing only a part of the image (by the way, this is almost how individual cortical neurons function in the brain, where each neuron only responds to a small portion of the entire visual field).
How Convolutional Neural Networks Work
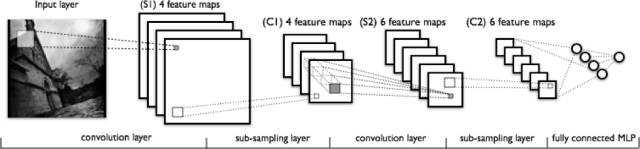
Image: deeplearning4j
In the above image, from left to right, you can observe:
· The actual input image being scanned for features. The filter is a light rectangle.
· Activation maps are arranged on top of a stack, one for each filter you use. The larger rectangle is a patch to be downsampled.
· The activation map is compressed through downsampling.
· A new set of activation maps generated by downsampling the filters through the stack.
· A second downsampling—compressing the second set of activation maps.
· A fully connected layer, where each node specifies the output of one label.
CNNs filter connections by proximity. The secret lies in adding two new layers: pooling and convolution layers. We will break down this process as follows: using one for a specific purpose, for example, to determine whether an image contains a grandfather.
The first step of the process is the convolution layer, which itself contains several steps.
· First, we will break down the grandfather’s image into a series of overlapping 3 * 3 pixel puzzles.
· Next, we will run these puzzles through a simple single-layer neural network, keeping the weights constant. The tiles are arranged so that while we keep each image size small (in this case, 3 * 3), the neural network can handle them, ensuring manageable size.
· Then, an array representing the content of each area in the photo will be output, where the axes represent color, width, and height. So, for each puzzle, in this case, we will have a 3 * 3 * 3 representation. (If we talk about a video of the grandfather, we would throw in a fourth dimension—time).
· The next step is the pooling layer. It takes these 3 or 4-dimensional arrays and applies downsampling functions along with spatial dimensions. The result is a pool array that contains only the important parts of the image while discarding the rest, minimizing the amount of computation needed while also avoiding overfitting issues.
The downsampled array is used as input for a regular fully connected neural network. Since the input size has been greatly reduced due to pooling and convolution, we now have something that the regular network can process while retaining the most important parts of the data. The final output will represent the system’s confidence in the grandfather’s image.
In real life, the working process of CNNs is intricate, involving many hidden, pooling, and convolution layers. Additionally, real CNNs usually involve hundreds or thousands of labels, rather than just a single label.
How to Build a Convolutional Neural Network?
Building a CNN from scratch can be an expensive and time-consuming task. That said, several APIs have recently been developed to enable different organizations to gather various insights without having to research machine learning or computer vision expertise themselves.
Google Cloud Vision
Google Cloud Vision is Google’s visual recognition API and uses REST API. It is based on the open-source TensorFlow framework. It detects individual faces and objects and includes a fairly comprehensive set of labels.
IBM Watson Visual Recognition
IBM Watson Visual Recognition is part of the Watson Developer Cloud and comes with a large set of built-in categories, but is actually built to train custom tailored classes based on the images you provide. It also supports some great features, including NSFW and OCR detection, similar to Google Cloud Vision.
Clarif.ai
Clarif.ai is an emerging image recognition service that also uses REST API. One interesting aspect of Clarif.ai is that it comes with some modules that help customize its algorithms to specific topics like food, travel, and weddings.
Although the above APIs are suitable for a few general applications, you may still need to develop custom solutions for specific tasks. Fortunately, many libraries can make life easier for developers and data scientists by handling optimization and computational aspects, allowing them to focus on training models. Many libraries, including Theano, Torch, DeepLearning4J, and TensorFlow, have been successfully applied to various applications.
Interesting Applications of Convolutional Neural Networks
Automatically Adding Sound to Silent Films
To match silent videos, the system must synthesize sound for this task. The system is trained on thousands of video examples where drumsticks hit different surfaces to produce different sounds. The deep learning model associates video frames with a pre-recorded database to select sounds that perfectly match what is occurring in the scene. The system is then evaluated using a setup similar to the Turing test, where people must determine which video has fake (synthesized) or real sound. This is a very cool application of convolutional neural networks and LSTM recurrent neural networks.
Disclaimer: Some content is sourced from the internet for the purpose of learning and communication only. The copyright of the article belongs to the original author. If there are any discrepancies, please contact us for removal.
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply with: Extension Module Chinese Tutorial on the "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply with: Python Vision Practical Project on the "Beginner's Guide to Vision" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eye line addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply with: OpenCV Practical Project 20 Lectures on the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will be gradually subdivided). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, it will not be approved. After successful addition, you will be invited to join relevant WeChat groups based on your research direction. Please do not send advertisements in the group, or you will be removed from the group. Thank you for your understanding~