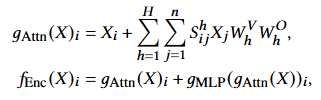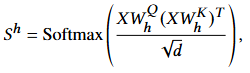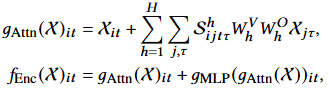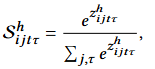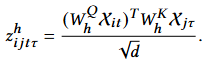Source: Time Series Research
This article is approximately 2800 words long and is recommended for a 5-minute read.
This article proposes a higher-order Transformer architecture specifically designed to handle multimodal stock data for predicting stock movements.
For investors and traders, predicting stock movements in the financial market is crucial as it enables them to make informed decisions and enhance profitability. However, this task is inherently challenging due to the randomness of market dynamics, the non-stationarity of stock prices, and the influence of numerous factors beyond historical prices.
Researchers from abroad have addressed the challenges of predicting stock movements in the financial market by introducing a higher-order Transformer, a new architecture designed for handling multivariate time series data. By extending the self-attention mechanism and Transformer architecture to a higher order, it effectively captures the complex market dynamics between time and variables. To manage computational complexity, the researchers proposed using tensor decomposition to perform low-rank approximations on potentially large attention tensors and employed kernel attention, thereby reducing complexity to a linear relationship with the amount of data. Additionally, an encoder-decoder model that integrates technical analysis and fundamental analysis was proposed, utilizing multimodal signals from historical prices and relevant tweets. Experiments conducted on the Stocknet dataset demonstrated the effectiveness of this approach, highlighting its potential in enhancing stock movement prediction in the financial market. This work has been accepted by KDD 2024.

【Paper Title】
Higher Order Transformers: Enhancing Stock Movement Prediction On Multimodal Time-Series Data
【Paper Address】
https://arxiv.org/abs/2412.10540
Traditional stock prediction methods primarily focus on technical analysis (TA) and fundamental analysis (FA), utilizing historical price data and key financial indicators, respectively. Although these methods provide valuable insights, they often fail to capture the complex interdependencies and high-dimensional structure of financial data.
Recent advancements in machine learning, particularly in natural language processing and graph neural networks, have begun to address these limitations by integrating multimodal data sources such as news articles and social media sentiment, thereby gaining a more detailed understanding of market dynamics. Despite these advancements, existing models still struggle to cope with the vast quantity and variability of financial data when dealing with high-dimensional, multivariate time series data, resulting in often unsatisfactory prediction performance.
To tackle these challenges, the researchers introduced a new architecture called the higher-order Transformer. This architecture extends traditional Transformer models by incorporating higher-order data structures into the self-attention mechanism, enabling it to capture more complex interrelationships across time and variables.
The researchers first explained how to tokenize the input multivariate time series data. They constructed a price vector for each stock daily, including the adjusted closing price, highest price, and lowest price. Additionally, they added date features such as the day of the month, month of the year, and year. The combination of these price and date features formed a six-dimensional vector for each stock on a daily basis.
Inspired by previous work, the researchers added stock-specific learnable tokens at the beginning of each time series, using them as common CLS tokens in the Transformer encoder. Similar to BERT and ViT, the hidden state of this special token is used as the representation of the stock over the entire time window for classification tasks.
02 Higher-Order Transformer
First, the self-attention mechanism in the Transformer layer was reviewed, and then it was extended to a higher order through tensorizing queries, keys, and values, forming the higher-order Transformer layer. Given the high cost of computing attention on tensors, the researchers proposed using low-rank approximations with Kronecker decomposition and combined it with attention kernel techniques to significantly reduce computational complexity.
-
Standard Transformer Layer
The Transformer encoding layer consists of two main parts: the self-attention layer and the element-wise feedforward layer. For a set of input vectors, the Transformer layer computes specific formulas, including self-attention and feedforward network calculations.
-
Higher-Order Transformer Layer
To generalize the scaled dot-product attention formula to higher-order input data, the researchers extended the concept of attention to tensors. They not only defined the Transformer encoding layer as a function that includes self-attention and feedforward network calculations but also extended the computation of attention scores accordingly.
-
Low-Rank Approximation and Kronecker Decomposition
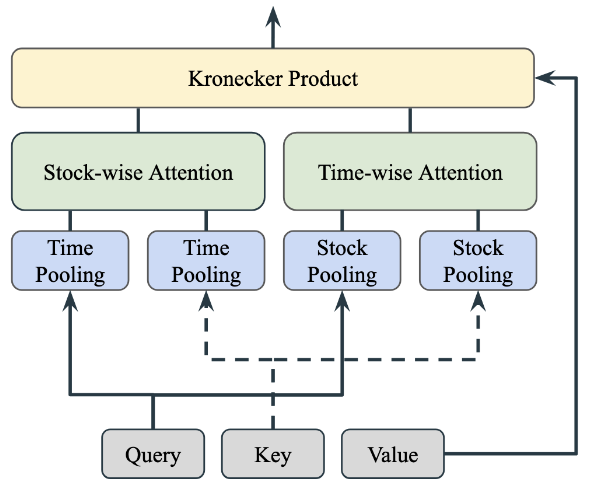
Considering the attention matrix as a flattened result that reshapes the tensor into variable and time dimensions. The attention matrix is parameterized using Kronecker decomposition, demonstrating how to approximate the original attention tensor through Kronecker decomposition.
Figure 1: Higher-Order Attention Mechanism Using Kronecker Decomposition
-
Linear Attention and Kernel Techniques
Using kernelized linear attention, the attention matrix is approximated through suitable kernel functions, achieving linear computational complexity.
The model architecture consists of a multi-layer Transformer network. The input tensor is transformed through a linear projection layer to align features with the hidden dimensions required by the model and its attention modules. The pre-normalization technique, specifically RMSNorm, is applied in each layer following the method proposed by Touvron et al. For computing temporal attention, rotational position embeddings are applied, while stock-level attention does not involve position embeddings, as the order in this dimension is meaningless.
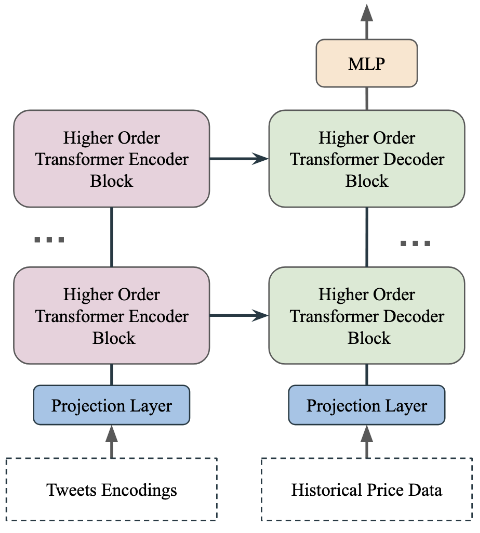
As shown in Figure 2, tweet encodings are input into the Transformer encoder, while historical price data is input into the Transformer decoder. The multimodal model proposed in this paper follows an encoder-decoder architecture, where the data modalities of the encoder and decoder differ. Specifically, text encodings are processed by the Transformer encoder, while price time series data is processed by the Transformer decoder. The cross-attention layer in the network facilitates the fusion of information between these two modalities.
Figure 2: Multimodal Transformer Architecture
The researchers used the Stocknet dataset to demonstrate the capabilities of the higher-order Transformer in classifying stock market movements. This dataset contains historical data of 88 stocks extracted from Yahoo Finance, along with related news scraped from Twitter, covering a span of two years.
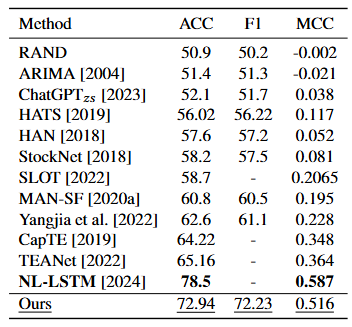
The experiments analyzed the benchmark performance of the proposed model against various baseline models on the StockNet dataset. As shown in Table 1, the proposed model outperformed most existing baseline models across all evaluation metrics, second only to the NL-LSTM model, which reported the highest accuracy in binary stock movement predictions.
Table 1: Classification Performance Comparison
The researchers further investigated the impact of different aspects of the model through ablation studies, focusing on the types of attention mechanisms used, data modalities, and attention methods. The results are provided in Tables 2 and 3.
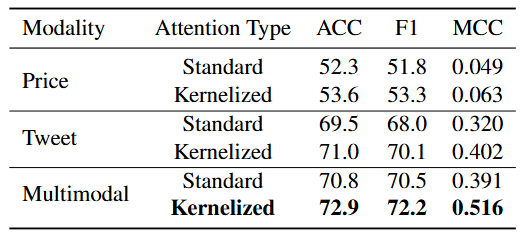
Table 2 shows the impact of data modalities on performance. The multimodal approach that integrates price data and Twitter news significantly outperformed the unimodal approach, emphasizing the benefits of utilizing multiple data sources. Moreover, text-based models performed better than time series-based models, indicating the rich context present in news data scraped from Twitter significantly aids stock movement prediction tasks. Table 2 also explored the effects of using linear versus standard attention mechanisms across different modalities. The results highlighted the advantages of linear attention in terms of efficiency and effectiveness, particularly in multimodal settings.
Table 3 shows that applying attention in any single dimension (stock-level or time-level) improves performance metrics compared to not using attention, but the performance boost is most significant when attention is applied in both dimensions simultaneously.
Table 2: Ablation Study on Data Modalities and Attention Mechanisms Demonstrating that using multimodal data is more effective than unimodal data, and that using kernelized attention mechanisms is more effective than standard attention mechanisms.
Table 3: Ablation Study on Attention Dimensions Demonstrating that applying attention mechanisms in both dimensions is effective.
This article proposes a higher-order Transformer architecture specifically designed to handle multimodal stock data for predicting stock movements. By extending the self-attention mechanism and Transformer architecture to incorporate higher-order interactions, this model adeptly captures the complex dynamics of the financial market across both stock and time dimensions. To address computational constraints, the researchers achieved low-rank approximations through tensor decomposition and integrated kernel attention to achieve linear computational complexity. Extensive testing on the Stocknet dataset indicates that the proposed method significantly outperforms most existing models in predicting stock movements. Ablation studies further validate the effectiveness of specific architectural components, highlighting their contributions to model performance. Future researchers plan to train the model on other multimodal stock datasets and analyze profitability on real-world stock data to further test the practical applicability and financial feasibility of the proposed methods.
Data派THU, as a public account on data science, is backed by Tsinghua University’s Big Data Research Center, sharing cutting-edge research dynamics in data science and big data technology innovation, continuously disseminating data science knowledge, striving to build a talent gathering platform in data, and creating China’s strongest big data group.

Sina Weibo: @Data派THU
WeChat Video Account: Data派THU
Today’s Headline: Data派THU