The Analyst Network of Machine Heart
Author:Wang Zijia
Editor: H4O
This article introduces the Transformer family.
Recently, the arms race of large language models has dominated much of the discussions among friends, with many articles exploring what these models can do and their commercial value. However, as a small researcher immersed in the field of artificial intelligence for many years, I am more concerned with the technical principles behind this arms race and how these models are engineered to benefit humanity. Rather than focusing on how these models can make money and be engineered to benefit more people, I want to explore the reasons behind this phenomenon and what we researchers can do to achieve “a glorious retirement after being replaced by AI” before that happens.
Three years ago, when GPT-3 stirred up a storm in the tech world, I attempted to analyze the vast family behind GPT in a historical manner. I chronologically sorted the technical lineage behind GPT (Figure 1) and tried to explain the technical principles behind GPT’s success. This year, ChatGPT, the younger sibling of GPT-3, seems even smarter, able to converse with people, allowing more to understand the latest developments in the field of natural language processing. At this historic moment, as the historians of AI, we should perhaps take some time to review what has happened in recent years. The first article starts with GPT-3, so this series is actually a record of the post-GPT era (the Post-GPT Book), and while exploring the changes in the GPT family, I realized that most stories are related to the Transformer, hence the title of this article is the Transformer Family.
Figure 1. The Old Genealogy of GPT
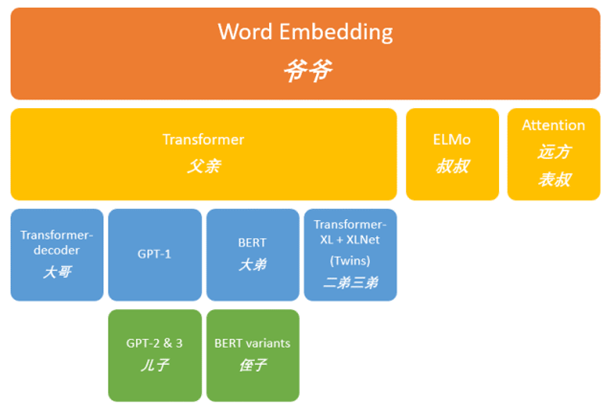
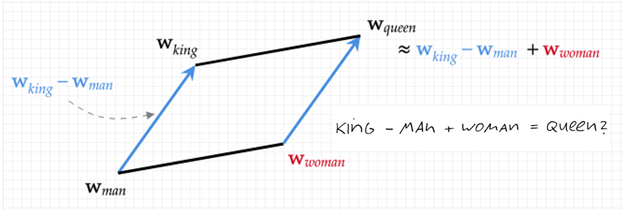
Before officially introducing the Transformer family, let us first revisit what has happened in the past according to Figure 1. Starting from Word Embedding [1,2], vectors (a series of numbers) encapsulated the semantics of words in a peculiar yet effective way. Figure 2 illustrates this representation: using numbers to represent (King – Man + Woman = Queen). Based on this, a vast NLP (Natural Language Processing) family was established.
Figure 2. Word2Vec Illustration (King – Man + Woman = Queen)
After that, its eldest son ELMo [3] discovered the importance of context, as exemplified in the following two sentences:
“Oh! You bought my favorite pizza, I love you!”
“Ah, I really love you! You dropped my favorite pizza on the ground?”
The meaning of “I love you” is evidently different. ELMo successfully solved this problem by “given a sequence of words to a model, predicting the next and previous words (contextual context).”
Meanwhile, a distant cousin of Word Embedding discovered another issue – when people understand a sentence, they focus on certain words. A clear phenomenon is that many typos are easily overlooked when reading one’s mother tongue because our attention is not on them while understanding the text. Thus, he proposed the Attention mechanism [4], but at this time, the Attention mechanism was still in its infancy and could not work independently, thus it could only rely on sequential models like RNN and LSTM. Figure 3 shows the process of combining the attention mechanism with RNN, illustrating why Attention cannot work independently. Here, let me briefly explain the working process of NLP models. First, we have a sentence, for example, “I love you China,” which consists of five characters, represented as x_1-x_5 in Figure 3. Each character transforms into what was just mentioned – word embedding (a series of numbers), represented as h_1-h_5 in Figure 3. They then finally convert into outputs, such as “I love China” (translation task), represented as x_1’-x_3’ in Figure 3. The remaining part not mentioned in Figure 3 is the attention mechanism, denoted as A in Figure 3, which assigns a weight to each h, allowing us to identify which words are important when converting the current word. For specific details, please refer to my initial article (starting from word2vec, discussing the vast genealogy of GPT). It can be seen that the numerical representation is the foundation of the entire task, which is why the Attention mechanism cannot work independently.
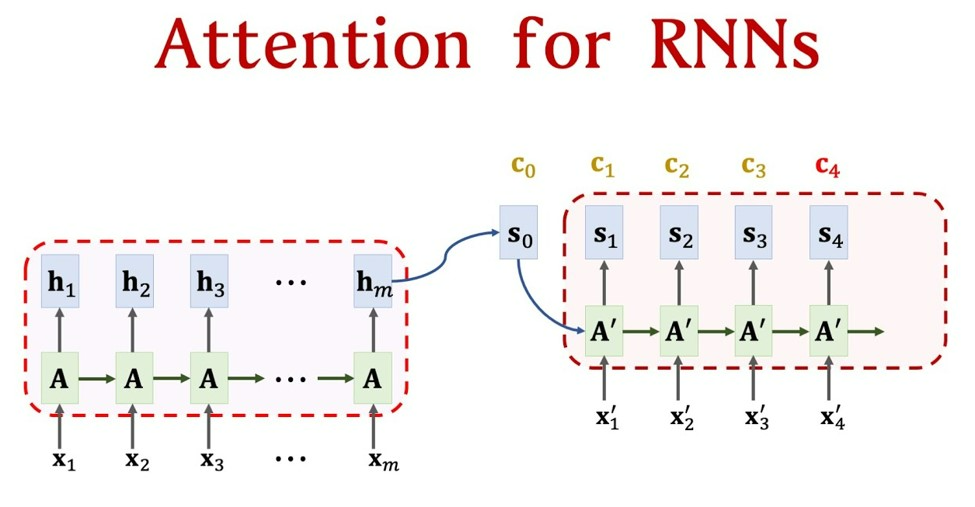 Figure 3. Early Photo – Attention and RNN Combine (source: Attention for RNN Seq2Seq Models (1.25x speed recommended) – YouTube)
At this point, as a proud direct descendant of the royal family, the Transformer did not recognize this dependent way of working. In the paper “Attention is All You Need” [5], it proposed its independent method, transforming the “Attention mechanism” into “Self-Attention mechanism,” allowing it to generate that string of numbers using only the attention mechanism. We can illustrate this change using a Chinese medicine prescription analogy. Initially, the Attention mechanism can be seen as the dosage of each ingredient, but when picking up the medicine, the medicine exists in the hands of the RNN or LSTM (the herbalist). The prescription we write must also be based on what medicines are available in the pharmacy (RNN, LSTM). What the Transformer did was reclaim the picking rights (by adding the value matrix) and change the way of prescribing (by adding the key and query matrices). At this point, Source can be viewed as a storage box in a Chinese medicine shop, where the medicines inside are composed of address Key (medicine names) and Value (medicines). Currently, there is a Key=Query (prescription) inquiry, aiming to extract the corresponding Value (medicine) from the storage box, that is, the Attention value. By comparing the similarity between the Query and the Key addresses in the storage box for addressing, it is said to be soft addressing, meaning we do not just find one type of medicine from the storage box but may extract content from each Key address. The importance of the extracted content (the quantity) is determined by the similarity between the Query and the Key, and then the Value is weighted and summed to obtain the final Value (a prescription), which is also the Attention value. Therefore, many researchers regard the Attention mechanism as a special case of soft addressing, which is very reasonable [6].
From then on, the Transformer officially began to lead the family towards prosperity.
In fact, as can be seen from Figure 1, the transformer is the most prolific descendant of the grandfather’s family, confirming that the title “Attention is All You Need” indeed has its reason. Although we just discussed what the self-attention mechanism is, the evolution of the transformer has been detailed in the previous article (starting from word2vec, discussing the vast genealogy of GPT), I will still quickly review what the Transformer architecture is for newcomers.
In simple terms, we can see the Transformer as an “actor.” For this “actor,” the encoder acts like the actor’s memory, responsible for converting lines into an intermediate representation (abstracted into something we do not know in the actor’s mind, which is the actor’s understanding), while the decoder acts like the actor’s performance, responsible for converting the understanding in the mind into a display on the screen. The most important self-attention mechanism serves as the actor’s focus, automatically adjusting the actor’s attention at different positions, thus better understanding all lines and allowing for a more natural and smooth performance in different contexts.
More specifically, we can see the Transformer as a large “language processing factory.” In this factory, each worker (encoder) is responsible for processing one position in the input sequence (for example, a character), processing and transforming it, and then passing it to the next worker (encoder). Each worker has a detailed instruction manual (self-attention mechanism), which describes how to process the input at the current position and how to relate it to previous positions. In this factory, every worker can process their tasks simultaneously, allowing the entire factory to efficiently handle large amounts of input data.
As soon as the Transformer appeared, it undoubtedly seized the throne due to its powerful capabilities and its two promising sons (BERT and GPT). BERT (Bidirectional Encoder Representations from Transformers) [1] inherited the encoder part of the Transformer, winning the first half of the race, but due to its limitations, it lost to GPT in terms of versatility. The honest GPT (Generative Pre-trained Transformer) [7-10] inherited the decoder part, learning the way humans communicate from scratch, ultimately achieving a comeback in the second half of the race.
Of course, the ambition of the Transformer is clearly not limited to this; “Attention is All You Need” does not only refer to the NLP field. Before introducing the entanglement between GPT and BERT, let’s first see what their venerable father has accomplished.
New Genealogy – A Multitude of Lords
Figure 3. Early Photo – Attention and RNN Combine (source: Attention for RNN Seq2Seq Models (1.25x speed recommended) – YouTube)
At this point, as a proud direct descendant of the royal family, the Transformer did not recognize this dependent way of working. In the paper “Attention is All You Need” [5], it proposed its independent method, transforming the “Attention mechanism” into “Self-Attention mechanism,” allowing it to generate that string of numbers using only the attention mechanism. We can illustrate this change using a Chinese medicine prescription analogy. Initially, the Attention mechanism can be seen as the dosage of each ingredient, but when picking up the medicine, the medicine exists in the hands of the RNN or LSTM (the herbalist). The prescription we write must also be based on what medicines are available in the pharmacy (RNN, LSTM). What the Transformer did was reclaim the picking rights (by adding the value matrix) and change the way of prescribing (by adding the key and query matrices). At this point, Source can be viewed as a storage box in a Chinese medicine shop, where the medicines inside are composed of address Key (medicine names) and Value (medicines). Currently, there is a Key=Query (prescription) inquiry, aiming to extract the corresponding Value (medicine) from the storage box, that is, the Attention value. By comparing the similarity between the Query and the Key addresses in the storage box for addressing, it is said to be soft addressing, meaning we do not just find one type of medicine from the storage box but may extract content from each Key address. The importance of the extracted content (the quantity) is determined by the similarity between the Query and the Key, and then the Value is weighted and summed to obtain the final Value (a prescription), which is also the Attention value. Therefore, many researchers regard the Attention mechanism as a special case of soft addressing, which is very reasonable [6].
From then on, the Transformer officially began to lead the family towards prosperity.
In fact, as can be seen from Figure 1, the transformer is the most prolific descendant of the grandfather’s family, confirming that the title “Attention is All You Need” indeed has its reason. Although we just discussed what the self-attention mechanism is, the evolution of the transformer has been detailed in the previous article (starting from word2vec, discussing the vast genealogy of GPT), I will still quickly review what the Transformer architecture is for newcomers.
In simple terms, we can see the Transformer as an “actor.” For this “actor,” the encoder acts like the actor’s memory, responsible for converting lines into an intermediate representation (abstracted into something we do not know in the actor’s mind, which is the actor’s understanding), while the decoder acts like the actor’s performance, responsible for converting the understanding in the mind into a display on the screen. The most important self-attention mechanism serves as the actor’s focus, automatically adjusting the actor’s attention at different positions, thus better understanding all lines and allowing for a more natural and smooth performance in different contexts.
More specifically, we can see the Transformer as a large “language processing factory.” In this factory, each worker (encoder) is responsible for processing one position in the input sequence (for example, a character), processing and transforming it, and then passing it to the next worker (encoder). Each worker has a detailed instruction manual (self-attention mechanism), which describes how to process the input at the current position and how to relate it to previous positions. In this factory, every worker can process their tasks simultaneously, allowing the entire factory to efficiently handle large amounts of input data.
As soon as the Transformer appeared, it undoubtedly seized the throne due to its powerful capabilities and its two promising sons (BERT and GPT). BERT (Bidirectional Encoder Representations from Transformers) [1] inherited the encoder part of the Transformer, winning the first half of the race, but due to its limitations, it lost to GPT in terms of versatility. The honest GPT (Generative Pre-trained Transformer) [7-10] inherited the decoder part, learning the way humans communicate from scratch, ultimately achieving a comeback in the second half of the race.
Of course, the ambition of the Transformer is clearly not limited to this; “Attention is All You Need” does not only refer to the NLP field. Before introducing the entanglement between GPT and BERT, let’s first see what their venerable father has accomplished.
New Genealogy – A Multitude of Lords
“Father, times have changed. Our family will achieve true glory through my efforts.”
After understanding the mechanism of the Transformer, we can look at what level the Transformer family has developed under its powerful growth (the new genealogy). From the earlier “actor” example, it can be seen that the Transformer represents a learning approach that aligns with human logic, thus it can process not only text but also images. Figure 2 summarizes the powerful background of the Transformer family. In addition to allowing GPT and BERT to continue to expand in the initial NLP field, the Transformer has also begun to venture into the field of computer vision. Its younger son (Google’s proposed ViT, etc.) has also shone in this field. In 2021, the Vision Transformer experienced a major explosion, with a large number of works based on Vision Transformer sweeping through computer vision tasks. Naturally, as a family, the Transformer family will always share resources, leading to the emergence of CLIP, which connects text and images (AI painting). At the end of 2022, Stable Diffusion was in the spotlight before ChatGPT. Moreover, CLIP also opened new doors for the Transformer family in multimodal applications. Besides text and images, can text also be used for music or drawing? Multimodal and multitask Transformers also emerged. In summary, each field is a lord, and a Transformer that started from scratch in the NLP field has become a “Zhou king” capable of granting fiefs to lords.
A multitude of lords, indeed a prosperous era.
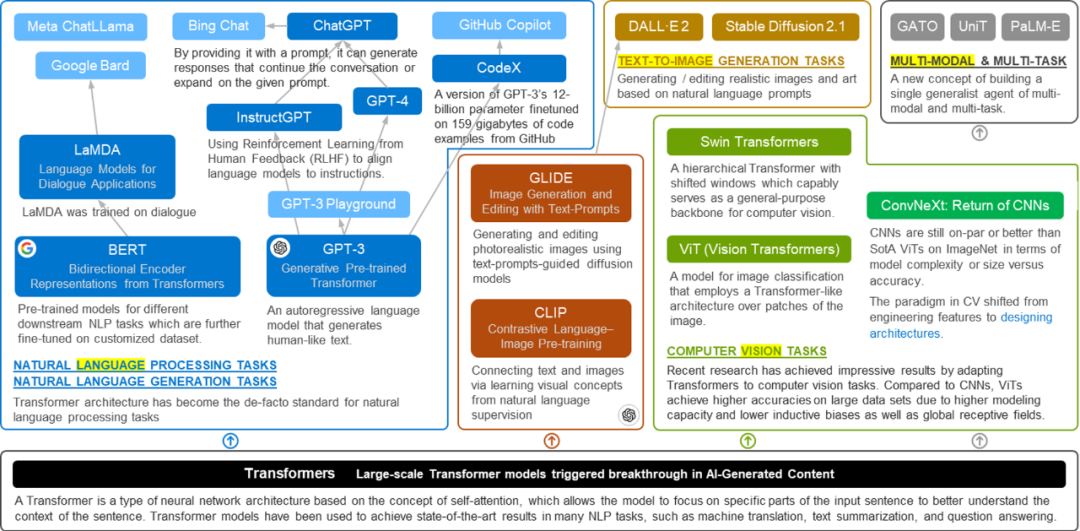
Figure 4. The Increasingly Prosperous Family Tree of the Transformer Family
First Trial – Vision Transformer [12]
Before discussing GPT, we must first mention the first bold attempt made by the Transformer – that is, letting the younger son dabble in the CV field. Let’s take a look at the younger son’s background:
-
Its father, the Transformer, was born in a paper called Attention is All You Need in 2017.
-
In 2019, Google proposed a Vision Transformer (ViT) architecture that can directly process images without using convolutional layers (CNN). The paper title is straightforward: “An image is worth 16×16 words.” As shown in Figure 5, its basic idea is to divide the input image into a series of small patches, each of which can be understood as a word processed in the past, and then convert these patches into vectors, just as words are processed in a standard Transformer. If we say that in the natural language processing (NLP) field, the attention mechanism of the Transformer attempts to capture the relationships between different words in the text, then in the computer vision (CV) field, ViT attempts to capture the relationships between different parts of an image.
 Figure 5. How ViT Processes Images (source: Are Transformers better than CNN’s at Image Recognition? | by Arjun Sarkar | Towards Data Science)
Since then, various models based on the Transformer have emerged, achieving results that surpass CNNs in corresponding tasks. So what is the advantage of the Transformer? Let’s return to the movie example and see the difference between the Transformer and CNN:
Imagine you are a director needing to arrange positions for the actors and place different elements appropriately, such as positioning actors against suitable backgrounds, using appropriate lighting to create a harmonious and aesthetically pleasing scene. For CNN, it acts like a professional photographer, capturing each frame pixel by pixel and extracting low-level features like edges and textures. It then combines these features to form higher-level features, such as faces and actions, ultimately producing a frame. As the movie progresses, CNN continually repeats this process until the entire film is completed.
In contrast, ViT acts like an art director, viewing the entire scene as a whole, considering background, lighting, color, and other factors, assigning suitable positions and angles to each actor to create a perfect scene. Then, ViT summarizes this information into a vector and processes it using a multi-layer perceptron, ultimately producing a frame. As the movie progresses, ViT continues this process until the entire film is created.
Returning to image processing tasks, suppose we have a 224×224 pixel image of a cat, and we want to classify it using a neural network. If we use a traditional convolutional neural network, it might employ multiple convolutional and pooling layers to gradually reduce the image size, ultimately obtaining a smaller feature vector that is classified through a fully connected layer. The issue with this method is that during convolution and pooling, we gradually lose information in the image because we cannot consider the relationships between all pixel points simultaneously. Additionally, due to the sequential limitations of convolution and pooling layers, we are unable to achieve global information interaction. In contrast, if we use the Transformer and self-attention mechanism to process this image, we can directly view the entire image as a sequence and perform self-attention calculations. This method does not lose any relationships between pixel points and allows for global information interaction.
Furthermore, because self-attention calculations are parallelizable, we can process the entire image simultaneously, greatly accelerating computation speed. For example, suppose we have a sentence: “I like to eat ice cream,” which contains six words. Now, if we are using a self-attention-based model to understand this sentence, the Transformer can:
Figure 5. How ViT Processes Images (source: Are Transformers better than CNN’s at Image Recognition? | by Arjun Sarkar | Towards Data Science)
Since then, various models based on the Transformer have emerged, achieving results that surpass CNNs in corresponding tasks. So what is the advantage of the Transformer? Let’s return to the movie example and see the difference between the Transformer and CNN:
Imagine you are a director needing to arrange positions for the actors and place different elements appropriately, such as positioning actors against suitable backgrounds, using appropriate lighting to create a harmonious and aesthetically pleasing scene. For CNN, it acts like a professional photographer, capturing each frame pixel by pixel and extracting low-level features like edges and textures. It then combines these features to form higher-level features, such as faces and actions, ultimately producing a frame. As the movie progresses, CNN continually repeats this process until the entire film is completed.
In contrast, ViT acts like an art director, viewing the entire scene as a whole, considering background, lighting, color, and other factors, assigning suitable positions and angles to each actor to create a perfect scene. Then, ViT summarizes this information into a vector and processes it using a multi-layer perceptron, ultimately producing a frame. As the movie progresses, ViT continues this process until the entire film is created.
Returning to image processing tasks, suppose we have a 224×224 pixel image of a cat, and we want to classify it using a neural network. If we use a traditional convolutional neural network, it might employ multiple convolutional and pooling layers to gradually reduce the image size, ultimately obtaining a smaller feature vector that is classified through a fully connected layer. The issue with this method is that during convolution and pooling, we gradually lose information in the image because we cannot consider the relationships between all pixel points simultaneously. Additionally, due to the sequential limitations of convolution and pooling layers, we are unable to achieve global information interaction. In contrast, if we use the Transformer and self-attention mechanism to process this image, we can directly view the entire image as a sequence and perform self-attention calculations. This method does not lose any relationships between pixel points and allows for global information interaction.
Furthermore, because self-attention calculations are parallelizable, we can process the entire image simultaneously, greatly accelerating computation speed. For example, suppose we have a sentence: “I like to eat ice cream,” which contains six words. Now, if we are using a self-attention-based model to understand this sentence, the Transformer can:
-
Minimize the total computational complexity per layer: In a self-attention-based model, we only need to calculate the attention weights between each word and all other words, meaning each layer’s computation depends only on the input length, not the size of the hidden layers. In this example, the input length is six words, so the computational complexity of each layer only depends on these six words.
-
Maximize the amount of parallelizable computation: The self-attention-based model can simultaneously compute the attention weights between each word and all other words, allowing for high parallelization of computation, thereby accelerating model training and inference.
However, ViT requires large-scale datasets and high-resolution images to unleash its full potential. Therefore, while Vision Transformers perform excellently in the CV domain, CNNs still have broader applications and research in computer vision, particularly in tasks like object detection and segmentation.
But that’s okay; you’ve done well enough. Your father’s venture into CV was not to replace CNN but to pursue grander goals.
The foundation of this goal is what I mentioned earlier, “Furthermore.”
Emerging Strength – CLIP [13]
As I mentioned earlier, the Transformer has even grander ambitions, which is “large models,” super, super large models. In addition to what I discussed in the previous article about how transformers can better acquire global information, the smaller computational complexity and better parallelization have become the foundations supporting large models.
In 2021, besides the significant progress of Vision Transformer, the GPT branch was also busy preparing for GPT3.5. The diligent Transformer led to a new climax – connecting text and images. This climax also marked the first shot for the “large model” plan outside the NLP field. At this point, the shortcomings of the Transformer in visual tasks became advantages. “ViT requires large-scale datasets and high-resolution images to unleash its full potential” can be rephrased as “ViT can handle large-scale datasets and high-resolution images.”
Let’s first discuss what CLIP is.
CLIP stands for Contrastive Language-Image Pre-Training, and its basic idea is clearly traditional CV’s contrastive learning. When we learn new knowledge, we read various books and articles to gather a wealth of information. However, we do not merely memorize every word and sentence in each book or article. Instead, we try to find similarities and differences between this information. For example, we may notice that the way a theme is described and the key concepts are expressed may differ across different books, but the concepts described are essentially the same. This method of seeking similarities and differences is one of the fundamental ideas of contrastive learning. We can view each book or article as different samples, while books or articles on the same theme can be seen as different instances from the same category. In contrastive learning, we train the model to learn how to differentiate between different categories of samples, thereby learning their similarities and differences.
Next, let’s get a bit more academic. Suppose you want to train a model to recognize car brands. You can have a set of labeled car images, each with a brand label such as “Mercedes,” “BMW,” “Audi,” etc. In traditional supervised learning, you would input the images and brand labels into the model and let it learn how to predict the correct brand label.
But in contrastive learning, you can train the model using unlabeled images. Assume you have a set of unlabeled car images, and you can divide these images into two groups: positive samples and negative samples. Positive samples are images of the same brand from different angles, while negative samples are images of different brands. Next, you can use contrastive learning to train the model to bring positive samples of the same brand closer together while pushing negative samples of different brands further apart. In this way, the model can learn to extract brand-specific features from images without explicitly telling it the brand label for each image.
Clearly, this is a self-supervised learning model, and CLIP is a similar self-supervised learning model, but its goal is to connect language and images, enabling computers to understand the relationship between text and images.
Imagine you are learning a vocabulary set, where each word has its definition and corresponding image. For each word and its corresponding image, you can view them as a pair. Your task is to identify the relationships between these words and images, namely which words match which images and which do not.
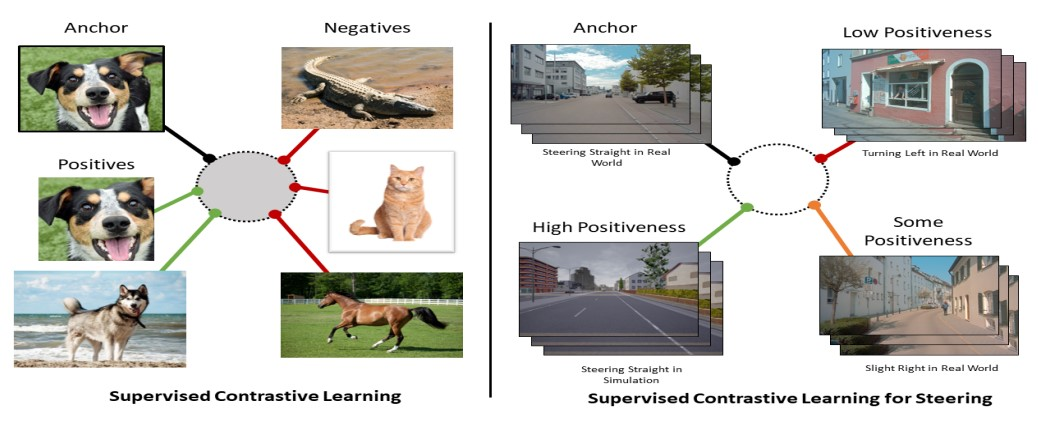
As illustrated in Figure 6, for contrastive learning algorithms, these word-image pairs are referred to as “anchors” and “positives.” “Anchor” refers to the object we want to learn about, while “positive” refers to the samples that match the “anchor.” In contrast, “negative” refers to samples that do not match the “anchor.”
In contrastive learning, we pair “anchor” and “positive” and attempt to distinguish them. Meanwhile, we also pair “anchor” and “negative” and try to differentiate them. This process can be understood as seeking the similarity between the “anchor” and “positive” while excluding the similarity between the “anchor” and “negative.”
Figure 6. Contrastive Learning Illustration [14]. Anchor is the original image, positives are generally cropped or rotated versions of the original image, or known images of the same category, negatives can be crudely defined as unknown images (possibly of the same category) or known images of different categories.
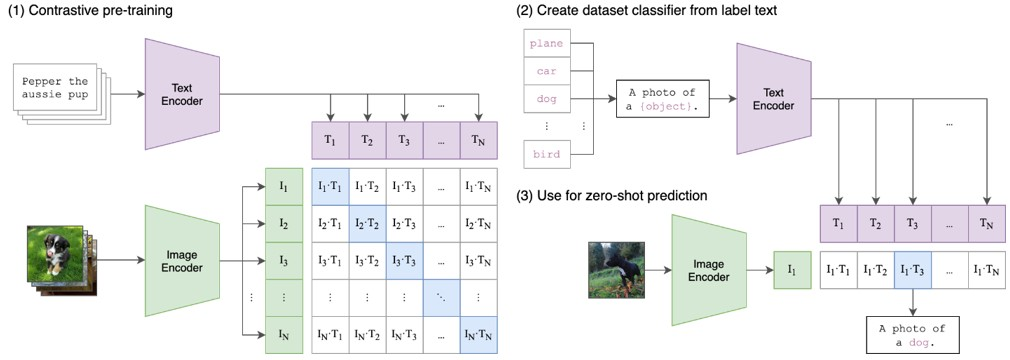
To achieve this goal, CLIP first pre-trains on a large number of images and texts, then uses the pre-trained model for downstream tasks such as classification, retrieval, and generation. The CLIP model adopts a new self-supervised learning method, simultaneously processing text and images to learn how to connect them. It shares an attention mechanism between text and images and uses a set of simple adjustable parameters to learn this mapping. It employs a transformer-based text encoder and a CNN-based image encoder, then calculates the similarity between image and text embeddings. CLIP learns to associate images and texts through a contrastive learning objective, maximizing the consistency between image-text pairs present in the data while minimizing the consistency between randomly sampled image-text pairs.
Figure 7. CLIP Illustration [13]. Compared to Figure 6, it can be simply understood as all positives and negatives in Figure 6 being text.
For example, if we want to use CLIP to determine whether an image is of a “red beach,” we can input this text description along with an image, and CLIP will generate a vector pair to represent their connection. If the distance of this vector pair is small, it indicates that this image might be of a “red beach,” otherwise, it is not. Through this method, CLIP can perform tasks like image classification and image search.
Returning to the full name, the last word of CLIP is pre-training, so it is essentially still a pre-trained model, but it can be used for various downstream tasks involving matching images and texts, such as image classification, zero-shot learning, and image description generation. For instance, CLIP can classify images into categories given by natural language labels, such as “photo of a dog” or “landscape painting.” CLIP can also generate descriptive text for images using language models conditioned on features extracted by CLIP. Furthermore, CLIP can generate images from text using generative models conditioned on text features extracted by CLIP.
DALL-E & Stable Diffusion
With the help of CLIP, a new lord has risen – AIGC (AI Generated Content). In fact, ChatGPT is essentially a type of AIGC, but in this section, we mainly discuss AI painting. Let’s take a look at the development history of this small family of AI painting:
-
In January 2021, OpenAI released DALL-E [15] (AI painting software), which improved GPT-3 to generate images instead of text (Image Transformer Network).
-
Almost simultaneously (January 2021), OpenAI released CLIP [13].
-
In May 2021, Google Brain and DeepMind released Stable Diffusion [17], which continues to iterate new versions. It uses a frozen CLIP text encoder to adjust the model based on text prompts. Stable Diffusion breaks down the image generation process into a runtime “diffusion” process. Starting from pure noise, it gradually refines the image until there’s no noise, making it closer to the provided text description.
-
In April 2022, DALL-E 2 [16] was released. It can create realistic images and artworks based on natural language descriptions. DALL-E 2 employs a two-part model consisting of a prior and a decoder. The prior is a GPT-3 model that generates CLIP image embeddings based on text prompts. The decoder is a diffusion model that generates images based on CLIP embeddings. DALL-E 2 can also perform outpainting, inpainting, and variations of existing images.
The genealogy of this family is evident; the elder brother CLIP connects images and texts, while its twin brother DALL-E proposes the text-to-image task. To improve this task, a distant cousin Stable Diffusion improves the image generation algorithm, and finally, DALL-E 2 combines the strengths of GPT-3, CLIP, and Stable Diffusion to complete its AI painting system.
For the original DALL-E, suppose you are a painter, and DALL-E is your toolbox. In this analogy, the toolbox contains two main tools: one is the brush, and the other is the palette.
The brush is the decoder of DALL-E, which can convert a given text description into an image. The palette is DALL-E’s encoder, which can convert any text description into a feature vector.
When you receive a text description, you first use the palette to generate a feature vector. Then, you can pick up the brush and use the feature vector to generate an image that matches the description. When you need details, you would use a finer brush, and conversely, a rougher brush for less detail.
Unlike a painter, DALL-E uses a neural network instead of a brush and palette. This neural network employs a structure called Image Transformer Network. When generating images, DALL-E uses the previously mentioned GPT-3 model to generate CLIP image embeddings corresponding to the text description. Then, DALL-E uses a beam search algorithm to generate a series of possible images that match the input text description and sends them through a decoder to produce the final image. These embedding vectors are trained using a technique called contrastive learning, which can embed similar images and text close together in space for easier combination.Note that DALL-E does not directly include CLIP, but it uses CLIP’s text and image embeddings to train the transformer and VAE..
As for the beam search algorithm used in the image generation process, it is essentially a greedy search algorithm that finds the optimal sequence within a limited candidate set. The basic idea of beam search is to keep the top k candidates with the highest probabilities each time the current sequence is extended (k is called beam width) and discard other low-probability candidates. This reduces the search space and improves efficiency and accuracy. The specific steps of using beam search to generate images in DALL-E are as follows:
-
Encode the input text description into a vector and use it as the initial input for the transformer model.
-
Starting from a special start symbol, generate the image sequence pixel by pixel. Each time a pixel is generated, the transformer model predicts the probability distribution of the next pixel and selects the top k candidate pixels with the highest probabilities as the extension of the current sequence.
-
For each extended sequence, calculate its cumulative probability and retain the top k sequences with the highest probabilities while discarding others.
-
Repeat steps 2 and 3 until a special end symbol is generated or the maximum length limit is reached.
-
Return the sequence with the highest probability as the final generated image.
How does Stable Diffusion generate an image? When we want to create a piece of art, we usually need a good composition and specific elements to build. Stable Diffusion is a method of generating images that divides the process into two parts: the diffusion process and the reconstruction process. The diffusion process can be imagined as mixing a bunch of scattered brushes, paints, and canvases together, gradually creating more and more elements on the canvas. During this process, we do not know what the final image will look like, nor can we determine the position of each element. However, we can gradually add and adjust these elements until the entire painting is complete. Then, the input text description acts as a rough description of the artwork we want to create, using the beam search algorithm to finely match the text description with the generated image. This process is akin to continuously modifying and adjusting elements to better match the image we envision. Ultimately, the generated image will closely match the text description, presenting the artistic work we imagine.
As shown in Figure 8, the diffusion model is a generative model that learns the distribution of data by gradually adding noise to the data and then reversely recovering the original data. Stable Diffusion employs a pre-trained variational autoencoder (VAE) to encode images into low-dimensional latent vectors and uses a transformer-based diffusion model to generate images from the latent vectors. Stable Diffusion also uses a frozen CLIP text encoder to convert text prompts into image embeddings, thus conditioning the diffusion model.
Figure 8. The Stable Diffusion Process. First, the upper arrow shows an image being continuously added with noise until it becomes pure noise. Then the lower arrow shows the gradual removal of noise to reconstruct the original image. (Source: From DALL・E to Stable Diffusion: how do text-to-image generation models work? | Tryolabs)
It is worth noting that the diffusion process in Stable Diffusion is a random process, so the images generated each time will differ, even for the same text description. This randomness enhances the diversity of generated images while increasing the algorithm’s uncertainty. To stabilize the generated images, Stable Diffusion employs several techniques, such as adding gradually increasing noise during the diffusion process and using multiple reconstruction processes to further improve image quality.
Stable Diffusion has made significant progress over DALL-E:
-
Resolution: Stable Diffusion can generate images up to 1024×1024 pixels, while DALL-E can only generate 256×256 pixel images.
-
Speed: Stable Diffusion requires multiple iterations to generate images, making it slower. DALL-E can generate images all at once, thus faster.
-
Flexibility: Stable Diffusion can extend, patch, and alter existing images, while DALL-E can only generate images from text prompts.
-
Realism: Stable Diffusion can generate more realistic and detailed images, especially under complex and abstract descriptions. DALL-E may produce images that do not conform to physical laws or common sense.
This is also why DALL-E 2 has incorporated diffusion models into its system.
The Emerging Power – GPT-3.5 [18]
While other lords are actively implementing reforms, the GPT branch has been quietly working hard. At the beginning, GPT-3 was already powerful, but it was not very “user-friendly” for non-technical users, so the waves it stirred were mostly within the tech community, and these not-so-vigorous waves have gradually dissipated due to its not-so-low fees.
The Transformer was quite dissatisfied, and GPT thought for a moment, “Let’s reform!”
The first to respond to the call for reform was GPT 3.5:
“I’m a bit stupid and can’t think of good ways to reform, so let’s first solidify the foundation.”
Thus, GPT3.5 was based on GPT-3, using a training dataset called Text+Code, which added some programming code data to the text data. In simple terms, it used a larger dataset. This allows the model to better understand and generate code, improving its diversity and creativity. Text+Code is a training dataset based on text and code, collected and organized by OpenAI from the internet. It includes two parts: text and code. The text consists of content described in natural language, such as articles, comments, dialogues, etc. The code consists of content written in programming languages, such as Python, Java, HTML, etc.
Text+Code training data enables the model to better understand and generate code, enhancing its diversity and creativity. For example, in programming tasks, the model can generate corresponding code based on text descriptions, with high correctness and readability. In content generation tasks, the model can generate corresponding text based on code descriptions, with high consistency and interest. The Text+Code training data also enables the model to better handle multilingual, multimodal, and multi-domain data and tasks. For instance, in language translation tasks, the model can accurately and fluently translate based on the correspondence between different languages. In image generation tasks, the model can generate corresponding images based on text or code descriptions, with high clarity and realism.
The second to respond to the call is Instruct GPT, who discovered a new problem:
“To blend in with humans, we need to listen to their opinions more effectively.”
Thus, the well-known new recruit appeared, which is the RLHF training strategy. RLHF is a reinforcement learning-based training strategy, and its full name is Reinforcement Learning from Human Feedback. The core idea is to provide the model with some instructions during training and reward or punish based on the model’s output. This allows the model to better follow instructions, enhancing its controllability and credibility. In fact, GPT-3.5 also had human feedback, but after incorporating reinforcement learning, what changes occurred?
-
GPT3.5’s human feedback is directly used to fine-tune the model’s parameters, while Instruct GPT’s RLHF is used to train a reward model, which then guides the model’s behavior.
-
GPT3.5’s human feedback is based on the evaluation of a single output, while Instruct GPT’s RLHF is based on comparisons between multiple outputs.
-
GPT3.5’s human feedback was conducted only once, while Instruct GPT’s RLHF can undergo multiple iterations, continuously collecting new comparison data, training new reward models, and optimizing new strategies.
In other words, less manpower is invested, but it brings greater benefits to the model.
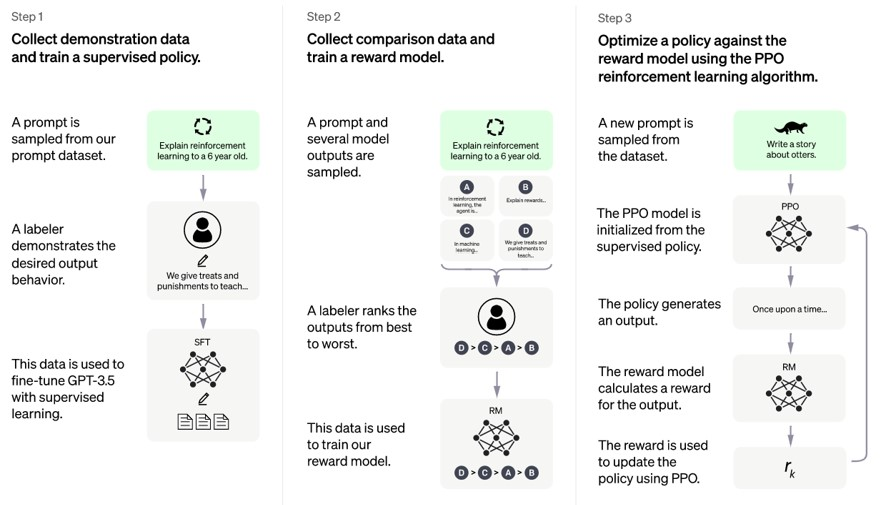
Figure 9. RLHF Process (Source: GPT-4 (openai.com))
As shown in Figure 9, the RLHF training strategy consists of two stages: pre-training and fine-tuning. In the pre-training stage, the model uses the same dataset as GPT-3 for unsupervised learning, learning the basic knowledge and rules of language. In the fine-tuning stage, the model uses some artificially labeled data for reinforcement learning, learning how to generate appropriate outputs based on instructions.
The artificially labeled data includes two parts: instructions and feedback. Instructions are tasks described in natural language, such as “write a poem about spring” or “give me a joke about dogs.” Feedback is numerical ratings, such as “1” for very poor and “5” for very good. Feedback is provided by human annotators based on the model’s output, reflecting the quality and rationality of the output.
In the fine-tuning stage, the model uses an algorithm called Actor-Critic for reinforcement learning. The Actor is a generator that generates outputs based on instructions. The Critic is an evaluator that assesses the reward value of the output based on feedback. The Actor and Critic cooperate and compete with each other, continuously updating their parameters to improve the reward value.
The RLHF training strategy allows the model to better follow instructions, enhancing its controllability and credibility. For instance, in writing tasks, the model can generate texts of different styles and themes based on instructions, with high coherence and logic. In conversational tasks, the model can generate responses of different emotions and tones based on instructions, with high relevance and politeness.
Finally, after the accumulation of reforms by predecessors, the more flexible younger son of the GPT family, ChatGPT, felt it was time to launch a dialogue mode more aligned with human communication styles based on Instruct GPT, creating huge waves in human society (with hundreds of millions of users). Moreover, it is free, and after years of dormancy, the GPT family finally made a stunning debut, becoming the most favored prince of the Transformer family, directly winning the throne in the succession struggle and becoming the crown prince.
Meanwhile, for ChatGPT, being a crown prince is not everything; it inherits the grand ambition of the Transformer:
“The current situation is too chaotic; a powerful dynasty does not need so many lords; it is time to unify them.”
Unifying the Lords – The Era of Large Models
GPT-4: “This era is the era of large models, and I say so.” (not really)
ChatGPT is now based on GPT-4, the grand front. GPT-4, fearing its competitors’ rapid responses, has kept most of its technical details closed. However, from its functionalities, the GPT family’s ambition to unify all lords is evident; besides text dialogue, GPT-4 has also incorporated AI painting features. The GPT family has learned an important lesson from its years of dormancy: large models are just and aims to promote this principle across various fields.
If we delve into the confidence behind this principle, it might be the training method for large models. GPT-3 is currently one of the largest language models, boasting 175 billion parameters, which is 100 times more than its predecessor GPT-2 and 10 times more than the previous largest NLP models, making it a pioneer of large predictive models.
Therefore, let’s take a look at how the architecture and training methods of GPT-3 achieve such scale and performance:
-
Distributed training: GPT-3 employs a distributed training approach, which disperses the model and data across multiple computing nodes and coordinates and synchronizes them through communication protocols. This allows the utilization of multiple nodes’ computational resources and memory space, accelerating the model training process and supporting larger models and datasets.
-
GPT-3 uses approximately 2000 GPU nodes for distributed training, with multiple GPUs on each node, each GPU having the same memory.
-
GPT-3 employs two methods of distributed training: data parallelism and model parallelism.
-
Data parallelism refers to splitting the data into multiple subsets, with each node processing one subset, updating the model parameters on each node, and then synchronizing parameters across all nodes.
-
Model parallelism refers to splitting the model into multiple parts, with each node processing one part, calculating the output and gradients for that part on each node, and then passing the output and gradients across all nodes.
-
GPT-3 employs a hybrid method of data parallelism and model parallelism, using data parallelism within each node while using model parallelism between different nodes. This fully utilizes the computational capabilities and communication bandwidth of GPUs while reducing communication overhead and memory usage.
-
Activation function checkpointing: GPT-3 uses a technique called activation function checkpointing, which saves only the values of the activation functions for some layers during the forward propagation process, rather than for all layers. This saves memory space because the values of activation functions occupy most of the memory. During the backward propagation process, if the values of some layers’ activation functions are needed, they are recalculated instead of read from memory. This sacrifices some computation time to gain more memory space, thus supporting larger models and batch sizes.
-
Sparse attention mechanism: GPT-3 employs a technique called sparse attention mechanism, which only considers certain words in the input sequence when computing self-attention, rather than all words. This reduces computational load and memory usage since the complexity of self-attention is quadratic to the length of the input sequence. GPT-3 uses a sparse attention mechanism based on local windows and global blocks, meaning that each input sequence is divided into multiple blocks, and each block only performs attention calculations with a few neighboring blocks, while also performing attention calculations with some randomly selected global blocks. This ensures that the model can capture both local and global information while reducing computational complexity and memory usage.
Having reached this point, ChatGPT frowned, seemingly dissatisfied with GPT-3’s plan: “This is not enough.”
“Large models are indeed the trend, but we should not blindly pursue scale for the sake of competition. Before training large models, we need to consider more details and technical challenges to ensure that they can run stably and efficiently, producing useful results.”
“First, choosing appropriate training hyperparameters and model initialization is crucial. The selection of hyperparameters such as learning rate, batch size, and iteration count significantly impacts the model’s convergence speed, stability, and performance. Model initialization determines the weight values before training begins, affecting the quality of the final results. These parameters need to be carefully adjusted based on empirical experiments or theoretical analysis to ensure optimal model performance.”
“Secondly, to achieve high throughput and avoid bottlenecks, we need to optimize all aspects of the training process, including hardware configuration, network bandwidth, data loading speed, and model architecture. Optimizing these aspects can significantly enhance the processing speed and efficiency of the model. For example, using faster storage devices or data formats can reduce data loading times; using larger batch sizes or gradient accumulation can reduce communication overhead; using simpler or sparser models can reduce computation times, etc.”
“Lastly, various instabilities and failures may arise when training large models, such as numerical errors, overfitting, hardware failures, and data quality issues. To avoid or recover from these issues, we need to closely monitor the model’s behavior and performance, using debugging tools and techniques to identify and fix any errors or defects. Additionally, we can employ various safety measures and protective mechanisms, such as pruning, regularization, dropout, noise injection, data filtering, and data augmentation, to enhance the model’s robustness and reliability.”
“In this era, large models are indeed important, but merely pursuing scale cannot yield useful results. Only through thoughtful training and optimization can large models truly unleash their potential and bring more value to humanity.”
The crown prince is right.
The Decline of the Strong Lord – BERT
Finally, a dead camel is still bigger than a horse; although BERT has recently been overshadowed by GPT, it was once a strong lord, and despite the unstoppable development of GPT, BERT still retains its fief. When discussing natural language processing models, BERT (Bidirectional Encoder Representations from Transformers) was once a highly popular model, as it performed exceptionally well in many tasks. When it was first released, it was nearly unbeatable, even more successful than GPT. This is because BERT’s design has different goals and advantages compared to GPT.
BERT’s goal is to elevate the ability to model context to a new height to better support downstream tasks, such as text classification and question answering. It achieves this by training a bidirectional transformer encoder. This encoder can simultaneously consider the left and right sides of the input sequence, thereby obtaining a better contextual representation, which allows BERT to model context more effectively, improving the model’s performance in downstream tasks.
However, over time, the emergence of the GPT series of models has allowed GPT-3 to surpass BERT in multiple tasks. One possible reason is that the GPT series of models are more focused on generative tasks, such as text generation and dialogue systems, while BERT emphasizes classification and question answering tasks. Additionally, the GPT series of models utilize larger parameters and more data for training, enabling them to achieve better performance across a wider range of tasks.
Of course, BERT remains a very useful model, especially for tasks requiring text classification or answering questions. The GPT series models are better suited for generative tasks, such as text generation and dialogue systems. Overall, both models have their unique advantages and limitations, and we need to choose the appropriate model based on the specific task requirements.
The Succession Struggle – The Formidable Segment Anything Model (SAM) [20]
As previously mentioned, while the elder brother GPT was quietly working hard, the diligent Transformer stirred up quite a storm in the CV field (ViT) and multimodal field (CLIP), but ultimately became an experience baby, taught by the favored prince GPT, which led to the so-called unification of GPT-4.
ViT and CLIP, which inherently possess the blood of the Transformer, are understandably unhappy: “Why should lords and princes have distinctions? Isn’t the elder brother learning from us?”
“But he is too powerful in the NLP field; we need to find a new battlefield.”
Thus, SAM emerged. On its official website, they describe themselves as:
Segment Anything Model (SAM): a new AI model from Meta AI that can “cut out” any object, in any image, with a single click.
In simple terms, we can view SAM as an efficient “image clipping master,” capable of precisely identifying and segmenting various objects in images through various input prompts. For example, when we click a point in an image, SAM will automatically cut out the object located at that point like an experienced painter; when we input the word “cat,” SAM will automatically find and cut out all the cats in the image like a clever detective; when we provide SAM with a target detection box, it will accurately cut out the object within the box like a skilled surgeon. SAM’s zero-shot generalization ability makes it a true “universal clipping master.” This means that whether it’s common objects like cars, trees, and buildings, or rare objects like dinosaurs, aliens, and magic wands, SAM can effortlessly identify and clip them. This powerful capability stems from its advanced model design and large dataset. I selected four complex scene examples from the original paper (Figure 10) to illustrate what SAM can do.
 Figure 10. Examples of SAM’s Effectiveness. Each colored object in the image can be clipped and extracted, akin to a highly efficient Photoshop master (image clipping master).
In simple terms, previously, when others excitedly proposed demands to us, we would helplessly ask, “Please wait, what kind of data can you provide?” Now it’s no longer necessary, at least in the CV field, it is closer to the understanding of AI by non-technical groups.
To achieve the powerful capabilities mentioned above, let’s see how ViT and CLIP have conspired:
ViT: “Although I primarily focused on image classification tasks before, my architecture is also suitable for image segmentation. Because I utilize the transformer architecture to decompose images into a series of patches and process them in parallel, if my advantages are integrated, SAM can inherit my parallel processing and global attention advantages, enabling efficient image segmentation.”
CLIP: “Great, then I will bring in my joint training method, allowing SAM to handle different types of input prompts (question prompts and visual prompts).”
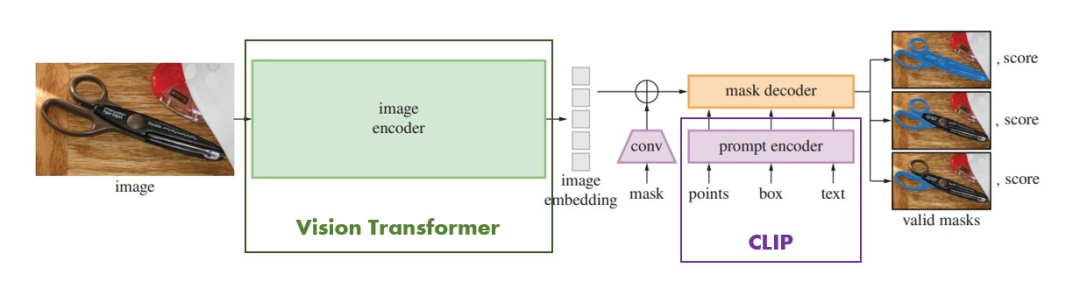
Thus, the SAM model architecture was formed (Figure 11), with ViT used as the image encoder and CLIP used to encode the prompt information. The idea is good, but how to implement it? – Of course, we learn from the elder brother!
“We want to utilize pre-trained language models for image segmentation tasks, just like using text prompts (prompts) to generate or predict text. With CLIP, our prompts can be quite diverse, including points, boxes, masks, and texts, which tell the language model what to segment in the image. Our goal is to obtain an effective segmentation mask (segmentation result) for any prompt. An effective mask means that even if the prompt is ambiguous (for example, shirt or person), the output should still produce a reasonable mask for one of the objects. This is similar to how the elder brother GPT (language model) can provide a coherent response to an ambiguous prompt. We chose this task because it allows us to pre-train the language model in a natural way and achieve zero-shot transfer to different segmentation tasks through prompts.”
Figure 11. SAM Model Architecture
As for the results, the powerful capabilities mentioned earlier have confirmed the feasibility of this idea. However, it must be noted that while SAM no longer requires retraining of the model, like when ChatGPT was first launched, it still has some limitations. In the limitation section of the paper, the authors explicitly pointed out some limitations and shortcomings of SAM, such as defects in details, connectivity, boundaries, and challenges in tasks like interactive segmentation, real-time performance, text prompts, semantics, and panoramic segmentation, while also acknowledging the advantages of some domain-specific tools.
For instance, I conducted two simple tests in the demo: one was lesion detection in the medical imaging field, as the lesions were too small to detect; the second was portrait cutting, where the cut-out portrait looked good at first glance, but the hair still appeared unnatural, and upon closer inspection, the cutting traces were evident.
Of course, this is a very good start; these two brothers are still working hard. What more can they ask for? Thus, the outcome of this succession struggle remains to be seen!
The vast family of the Transformer family is evidently too large to be covered in this article. When discussing the achievements based on the Transformer, we can see the continuous innovation in this field: Vision Transformer (ViT) demonstrates the successful application of the Transformer in the computer vision field, directly processing image pixel data without requiring manual feature engineering. DALL-E and CLIP apply the Transformer to image generation and classification tasks, showcasing its superior performance in visual semantic understanding. Stable Diffusion proposes a stable diffusion process for modeling probability distributions, applicable to tasks like image segmentation and generation. These achievements collectively reveal the broad application prospects of Transformer models, compelling us to acknowledge that one day, it might truly be that “Attention is all you need.”
In summary, we can see the vitality of continuous innovation in the field of artificial intelligence from these achievements. Whether it’s GPT or BERT, or Vision Transformer, DALL-E, CLIP, Stable Diffusion, etc., these achievements represent the latest advancements in the field of artificial intelligence.
As for the current situation of the big exam (ChatGPT), it might be like this:
The top students are attending classes well this semester, flipping through their books and recalling the teacher’s expressions and tones when discussing knowledge points, even starting to plan their study schedule for the next semester.
The pseudo-top students occupy the front row and open their books, but their faces are blank, starting to join the underachievers in “one book a day, one semester a week,” with the only difference being that their books aren’t brand new and they have a slight memory of the content.
As for the true underachievers…
“Knowledge comes, knowledge comes, knowledge comes from all directions.”
In fact, I believe that whether they are pseudo-top students or underachievers, they should remain calm before the final exam, review what has been taught this semester, borrow notes from top students, and even consider a deferred exam. For top students, speed is a natural outcome. For pseudo-top students and underachievers, speed can be harmful.
In the competition of artificial intelligence, continuous innovation is crucial. Therefore, as researchers, we should closely monitor the latest developments in this field and maintain a humble and open mindset to promote continuous progress in artificial intelligence.
[1] Mikolov, Tomas; et al. (2013). “Efficient Estimation of Word Representations in Vector Space”. arXiv (https://en.wikipedia.org/wiki/ArXiv_(identifier)):1301.3781 (https://arxiv.org/abs/1301.3781) [cs.CL (https://arxiv.org/archive/cs.CL)].
[2] Mikolov, Tomas (2013). “Distributed representations of words and phrases and their compositionality”. Advances in neural information processing systems.
[3] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, & Luke Zettlemoyer. (2018). Deep contextualized word representations.
[4] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
[5] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[6] Attention mechanism and self-attention (transformer). Accessed at: https://blog.csdn.net/Enjoy_endless/article/details/88679989
[7] Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).
[8] Radford, Alec, et al. “Language models are unsupervised multitask learners.” OpenAI blog 1.8 (2019): 9.
[9] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
[11] Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina (11 October 2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. arXiv:1810.04805v2 [cs.CL].
[12] Dosovitskiy, Alexey, et al. “An image is worth 16×16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[13] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International conference on machine learning. PMLR, 2021.
[14] Zheng, Laura, Yu Shen, and Ming C. Lin. “Exploring Contrastive Learning with Attention for Self-Driving Generalization.”
[15] Reddy, Mr D. Murahari, et al. “Dall-e: Creating images from text.” UGC Care Group I Journal 8.14 (2021): 71-75.
[16] Ramesh, Aditya, et al. “Hierarchical text-conditional image generation with clip latents.” arXiv preprint arXiv:2204.06125 (2022).
[17] Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[18] Chen, Xuanting, et al. “How Robust is GPT-3.5 to Predecessors? A Comprehensive Study on Language Understanding Tasks.” arXiv preprint arXiv:2303.00293 (2023).
[19] Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
Figure 10. Examples of SAM’s Effectiveness. Each colored object in the image can be clipped and extracted, akin to a highly efficient Photoshop master (image clipping master).
In simple terms, previously, when others excitedly proposed demands to us, we would helplessly ask, “Please wait, what kind of data can you provide?” Now it’s no longer necessary, at least in the CV field, it is closer to the understanding of AI by non-technical groups.
To achieve the powerful capabilities mentioned above, let’s see how ViT and CLIP have conspired:
ViT: “Although I primarily focused on image classification tasks before, my architecture is also suitable for image segmentation. Because I utilize the transformer architecture to decompose images into a series of patches and process them in parallel, if my advantages are integrated, SAM can inherit my parallel processing and global attention advantages, enabling efficient image segmentation.”
CLIP: “Great, then I will bring in my joint training method, allowing SAM to handle different types of input prompts (question prompts and visual prompts).”
Thus, the SAM model architecture was formed (Figure 11), with ViT used as the image encoder and CLIP used to encode the prompt information. The idea is good, but how to implement it? – Of course, we learn from the elder brother!
“We want to utilize pre-trained language models for image segmentation tasks, just like using text prompts (prompts) to generate or predict text. With CLIP, our prompts can be quite diverse, including points, boxes, masks, and texts, which tell the language model what to segment in the image. Our goal is to obtain an effective segmentation mask (segmentation result) for any prompt. An effective mask means that even if the prompt is ambiguous (for example, shirt or person), the output should still produce a reasonable mask for one of the objects. This is similar to how the elder brother GPT (language model) can provide a coherent response to an ambiguous prompt. We chose this task because it allows us to pre-train the language model in a natural way and achieve zero-shot transfer to different segmentation tasks through prompts.”
Figure 11. SAM Model Architecture
As for the results, the powerful capabilities mentioned earlier have confirmed the feasibility of this idea. However, it must be noted that while SAM no longer requires retraining of the model, like when ChatGPT was first launched, it still has some limitations. In the limitation section of the paper, the authors explicitly pointed out some limitations and shortcomings of SAM, such as defects in details, connectivity, boundaries, and challenges in tasks like interactive segmentation, real-time performance, text prompts, semantics, and panoramic segmentation, while also acknowledging the advantages of some domain-specific tools.
For instance, I conducted two simple tests in the demo: one was lesion detection in the medical imaging field, as the lesions were too small to detect; the second was portrait cutting, where the cut-out portrait looked good at first glance, but the hair still appeared unnatural, and upon closer inspection, the cutting traces were evident.
Of course, this is a very good start; these two brothers are still working hard. What more can they ask for? Thus, the outcome of this succession struggle remains to be seen!
The vast family of the Transformer family is evidently too large to be covered in this article. When discussing the achievements based on the Transformer, we can see the continuous innovation in this field: Vision Transformer (ViT) demonstrates the successful application of the Transformer in the computer vision field, directly processing image pixel data without requiring manual feature engineering. DALL-E and CLIP apply the Transformer to image generation and classification tasks, showcasing its superior performance in visual semantic understanding. Stable Diffusion proposes a stable diffusion process for modeling probability distributions, applicable to tasks like image segmentation and generation. These achievements collectively reveal the broad application prospects of Transformer models, compelling us to acknowledge that one day, it might truly be that “Attention is all you need.”
In summary, we can see the vitality of continuous innovation in the field of artificial intelligence from these achievements. Whether it’s GPT or BERT, or Vision Transformer, DALL-E, CLIP, Stable Diffusion, etc., these achievements represent the latest advancements in the field of artificial intelligence.
As for the current situation of the big exam (ChatGPT), it might be like this:
The top students are attending classes well this semester, flipping through their books and recalling the teacher’s expressions and tones when discussing knowledge points, even starting to plan their study schedule for the next semester.
The pseudo-top students occupy the front row and open their books, but their faces are blank, starting to join the underachievers in “one book a day, one semester a week,” with the only difference being that their books aren’t brand new and they have a slight memory of the content.
As for the true underachievers…
“Knowledge comes, knowledge comes, knowledge comes from all directions.”
In fact, I believe that whether they are pseudo-top students or underachievers, they should remain calm before the final exam, review what has been taught this semester, borrow notes from top students, and even consider a deferred exam. For top students, speed is a natural outcome. For pseudo-top students and underachievers, speed can be harmful.
In the competition of artificial intelligence, continuous innovation is crucial. Therefore, as researchers, we should closely monitor the latest developments in this field and maintain a humble and open mindset to promote continuous progress in artificial intelligence.
[1] Mikolov, Tomas; et al. (2013). “Efficient Estimation of Word Representations in Vector Space”. arXiv (https://en.wikipedia.org/wiki/ArXiv_(identifier)):1301.3781 (https://arxiv.org/abs/1301.3781) [cs.CL (https://arxiv.org/archive/cs.CL)].
[2] Mikolov, Tomas (2013). “Distributed representations of words and phrases and their compositionality”. Advances in neural information processing systems.
[3] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, & Luke Zettlemoyer. (2018). Deep contextualized word representations.
[4] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
[5] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[6] Attention mechanism and self-attention (transformer). Accessed at: https://blog.csdn.net/Enjoy_endless/article/details/88679989
[7] Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).
[8] Radford, Alec, et al. “Language models are unsupervised multitask learners.” OpenAI blog 1.8 (2019): 9.
[9] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
[11] Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina (11 October 2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. arXiv:1810.04805v2 [cs.CL].
[12] Dosovitskiy, Alexey, et al. “An image is worth 16×16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[13] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International conference on machine learning. PMLR, 2021.
[14] Zheng, Laura, Yu Shen, and Ming C. Lin. “Exploring Contrastive Learning with Attention for Self-Driving Generalization.”
[15] Reddy, Mr D. Murahari, et al. “Dall-e: Creating images from text.” UGC Care Group I Journal 8.14 (2021): 71-75.
[16] Ramesh, Aditya, et al. “Hierarchical text-conditional image generation with clip latents.” arXiv preprint arXiv:2204.06125 (2022).
[17] Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[18] Chen, Xuanting, et al. “How Robust is GPT-3.5 to Predecessors? A Comprehensive Study on Language Understanding Tasks.” arXiv preprint arXiv:2303.00293 (2023).
[19] Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
This article is authored by Wang Zijia, an AI scientist in the Chief Technology Officer’s office at Dell Technologies, a graduate of Imperial College London in AI, primarily researching computer vision, 3D reconstruction, AIGC, etc., focusing on exploring and innovating new technologies in related fields, including data privacy protection enabled by new AI technologies and the application of AIGC technology in data management. He joined Dell Technologies in 2019 and has published five papers and holds 139 patents in related fields.
About Machine Heart Global Analyst Network
Machine Heart Global Analyst Network is a global AI knowledge-sharing network initiated by Machine Heart. Over the past four years, hundreds of AI professionals, scholars, engineering experts, and business experts from around the world have utilized their spare time outside of their academic work to share their research ideas, engineering experiences, and industry insights with the global AI community through online sharing, column interpretations, knowledge base construction, report releases, evaluations, and project consultations, gaining personal growth, experience accumulation, and career development.
Interested in joining the Machine Heart Global Analyst Network? Click Read the original text to submit your application.