
Mingmin from QbitAI | WeChat Official Account
Elon Musk delivers on his promise by open-sourcing Grok-1, and the open-source community is ecstatic.
However, there are still some challenges for modifications or commercial use based on Grok-1:
Grok-1 is built with Rust+JAX, which poses a high entry barrier for users accustomed to the mainstream software ecosystem of Python+PyTorch+HuggingFace.
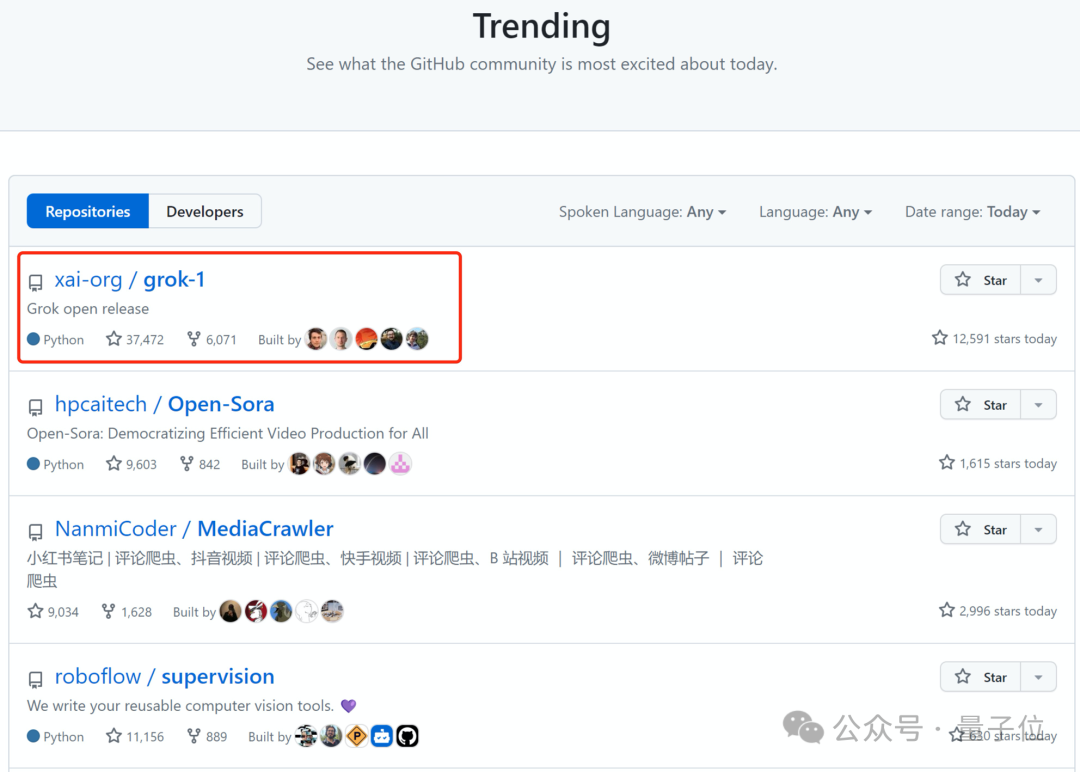
△Caption: Grok tops the GitHub trending list worldwide
The Colossal-AI team has made significant progress, providing an easy-to-use Python+PyTorch+HuggingFace Grok-1 that can accelerate inference latency by nearly 4 times!
The model has now been released on HuggingFace and ModelScope.
HuggingFace download link: https://huggingface.co/hpcai-tech/grok-1
ModelScope download link: https://www.modelscope.cn/models/colossalai/grok-1-pytorch/summary
Performance Optimization
Combining Colossal-AI’s rich experience in optimizing AI large model systems, tensor parallelism for Grok-1 is now rapidly supported.
On a single 8H800 80GB server, the inference performance is accelerated by nearly 4 times compared to methods like JAX and HuggingFace’s auto device map.

Usage Tutorial
After downloading and installing Colossal-AI, simply start the inference script.
./run_inference_fast.sh hpcaitech/grok-1The model weights will be automatically downloaded and loaded, and the inference results will remain aligned. Below is a running test of Grok-1’s greedy search.
For more details, you can refer to the usage examples of grok-1: https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/grok-1
The Colossal Grok-1
This open-source release includes the basic model weights and network architecture of Grok-1.
Specifically, it is the original foundational model from the pre-training phase in October 2023, not fine-tuned for any specific application (e.g., dialogue).
Structurally, Grok-1 employs a mixture of experts (MoE) architecture, containing 8 experts with a total parameter count of 314B (314 billion). When processing tokens, two of the experts will be activated, with an active parameter count of 86B.
Just looking at the active parameter count, it already exceeds the 70B of the dense model Llama 2, making such a parameter count a colossal entity for the MoE architecture.
More parameter information is as follows:
-
Window length of 8192 tokens, precision of bf16
-
Tokenizer vocab size of 131072 (2^17), close to GPT-4;
-
Embedding size of 6144 (48×128);
-
Number of Transformer layers is 64, each with a decoder layer, including multi-head attention blocks and dense blocks;
-
Key value size of 128;
-
In the multi-head attention block, there are 48 heads for queries, 8 for KV, with KV size of 128;
-
The dense block (dense feedforward block) expansion factor is 8, with hidden layer size of 32768

On the GitHub page, the official notes that due to the large model size (314B parameters), sufficient GPU and memory are required to run Grok.
The efficiency of the MoE layer implementation is not high; this implementation choice was made to avoid the need for custom kernels when validating the model’s correctness.
The model’s weight files are provided in the form of magnet links, with a file size of nearly 300GB.
It is worth mentioning that Grok-1 is licensed under the Apache 2.0 license, which is commercially friendly.
Currently, Grok-1 has reached 43.9k stars on GitHub.
Quantum Bit understands that Colossal-AI will further launch optimizations for Grok-1 in parallel acceleration, quantization to reduce memory costs, etc., so stay tuned.
Colossal-AI open-source address: https://github.com/hpcaitech/ColossalAI
— The End —
Registration for the selection is about to close!
2024 Notable AIGC Companies & Products
Quantum Bit is selecting the 2024 Most Notable AIGC Companies and 2024 Most Anticipated AIGC Products, welcome to register for the selection!
Registration deadline: March 31, 2024 

China AIGC Industry Summit is also in hot preparation, for more details please click: In the Era of Sora, how should we focus on new applications? Everything is at the China AIGC Industry Summit
For business cooperation, please contact WeChat: 18600164356 Xu Feng
For event cooperation, please contact WeChat: 18801103170 Wang Linyu
Click here👇 to follow me, and remember to star it!
One-click triple connection “Share”, “Like” and “View”
See cutting-edge technology developments every day ~
