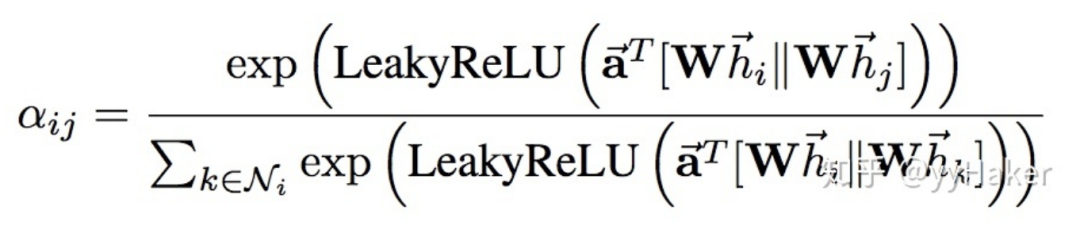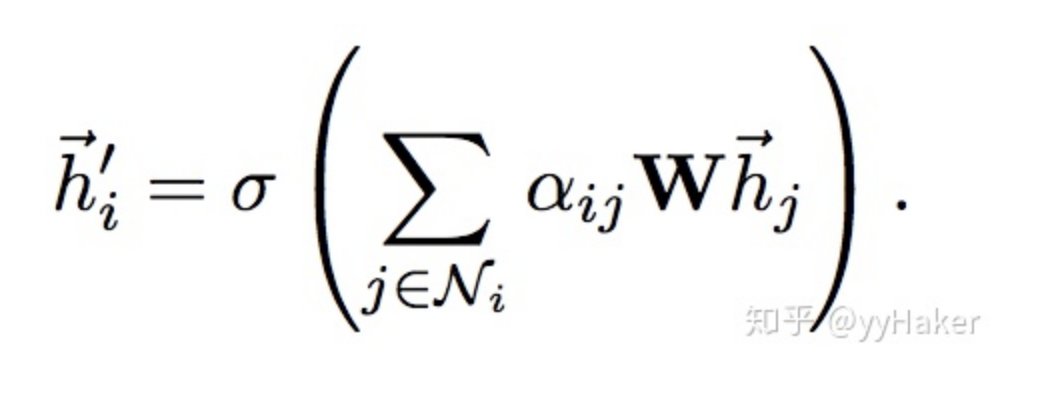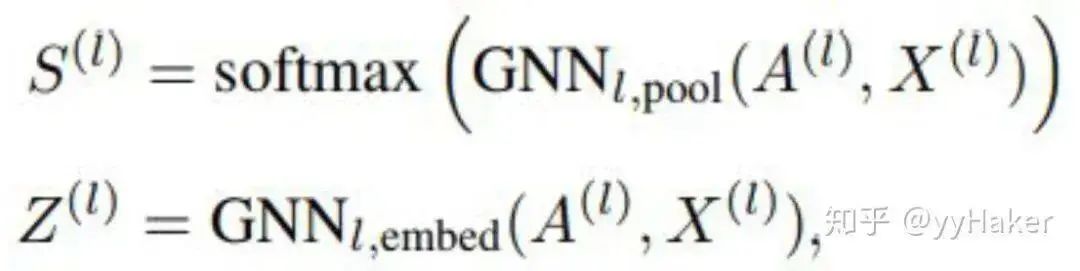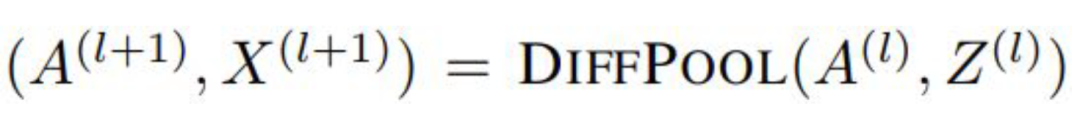Source: AI Youdao Extreme Market Platform
This article is approximately 5900 words long and is recommended for a reading time of 10 minutes.
This article will provide a brief summary from a more intuitive perspective of the currently classic and popular GNN networks, including GCN, GraphSAGE, GAT, GAE, and graph pooling strategies like DiffPool, etc.
In recent years, the research enthusiasm for Graph Neural Networks (GNN) in the field of deep learning has been increasing, making GNN a research hotspot at major deep learning conferences. The outstanding ability of GNN to handle unstructured data has led to breakthroughs in network data analysis, recommendation systems, physical modeling, natural language processing, and combinatorial optimization problems on graphs.There are many good reviews on Graph Neural Networks [1][2][3] that can be referenced, and more papers can be found in the GNN paper list compiled by Tsinghua University [4]. This article will provide a brief summary of the currently classic and popular GNN networks, including GCN, GraphSAGE, GAT, GAE, and graph pooling strategies like DiffPool, etc.
1. Why Do We Need Graph Neural Networks?
With the development of machine learning and deep learning, significant breakthroughs have been made in speech, image, and natural language processing. However, speech, images, and text are simple sequences or grid data, which are structured data, and deep learning is very good at handling this type of data (Figure 1).
Figure 1However, in the real world, not all things can be represented as a sequence or a grid, such as social networks, knowledge graphs, complex file systems, etc. (Figure 2). In other words, many things are unstructured.Figure 2Compared to simple text and images, this type of unstructured data from networks is very complex, and the challenges in processing it include:
The size of the graph is arbitrary, and the topology of the graph is complex, lacking spatial locality like images;
Graphs do not have a fixed node order, or there is no reference node;
Graphs are often dynamic and contain multimodal features.
So how should we model this type of data? Can deep learning be extended to model such data? These questions prompted the emergence and development of Graph Neural Networks.
2. What Do Graph Neural Networks Look Like?
Compared to the most basic network structure of neural networks, the fully connected layer (MLP), where the feature matrix is multiplied by the weight matrix, Graph Neural Networks add an adjacency matrix. The computation is quite simple: three matrices are multiplied and then a non-linear transformation is applied (Figure 3).Figure 3Thus, a common application pattern of Graph Neural Networks is shown in the following figure (Figure 4). The input is a graph, which goes through multiple layers of graph convolution and various operations along with activation functions, ultimately yielding representations of each node for tasks such as node classification, link prediction, and graph and subgraph generation.Figure 4The above provides a relatively simple and intuitive understanding of Graph Neural Networks, but the underlying principles and logic are still quite complex, which will be discussed in detail later. Next, we will introduce the development of Graph Neural Networks through several classic GNN models.
3. Several Classic Models and Developments of Graph Neural Networks
1. Graph Convolutional Networks (GCN) [5]GCN can be considered the “pioneering work” of Graph Neural Networks, as it was the first to apply the convolution operation from image processing to graph-structured data processing and provided a specific derivation involving complex spectral graph theory. For detailed derivation, please refer to [6][7]. The derivation process is quite complex, but the final result is very simple (Figure 5).Figure 5Let’s take a look at this formula. My goodness, isn’t this just aggregating the features of neighboring nodes and then performing a linear transformation? Yes, that’s exactly it. Moreover, to enable GCN to capture the information of K-hop neighboring nodes, the authors stack multiple layers of GCN layers, such that stacking K layers results in:The above formula can also be represented in matrix form as follows:Where is the normalized adjacency matrix, corresponds to a linear transformation of all node embeddings in the layer, and the left multiplication by the adjacency matrix indicates that for each node, its feature representation is the sum of the features of its neighboring nodes. (Note that replacing with a matrix is the three-matrix multiplication mentioned in Figure 3)So how effective is GCN? The authors applied GCN to the node classification task and conducted experiments on datasets such as Citeseer, Cora, Pubmed, and NELL, achieving significant improvements compared to traditional methods. This is likely due to GCN’s ability to encode the structural information of the graph, allowing it to learn better node representations.Figure 6Of course, the drawbacks of GCN are also quite apparent. First, GCN requires the entire graph to be loaded into memory and GPU memory, which can be very memory-intensive and cannot handle large graphs. Second, GCN needs to know the entire graph’s structural information (including the nodes to be predicted) during training, which may not be feasible in certain real-world tasks (for example, using a model trained today to predict data for tomorrow, where tomorrow’s nodes are not available).2. Graph Sample and Aggregate (GraphSAGE) [8]To address the two drawbacks of GCN, GraphSAGE was proposed. Before introducing GraphSAGE, let’s first explain Inductive Learning and Transductive Learning. Noting the differences between graph data and other types of data, each node in graph data can utilize information from other nodes through edge relationships. This leads to a problem: GCN inputs the entire graph, and when training nodes collect information from neighboring nodes, it uses samples from the test and validation sets, which we call Transductive Learning. However, most of the machine learning problems we handle are Inductive Learning, as we deliberately split the sample set into training/validation/testing, using only training samples during training. This is beneficial for graphs as it can handle newly arrived nodes, generating embeddings for unknown nodes using information from known nodes, which is exactly what GraphSAGE does.GraphSAGE is an Inductive Learning framework. In its implementation, during training, it only retains edges from training samples to training samples, and includes two major steps: Sample and Aggregate. Sample refers to how to sample the number of neighbors, and Aggregate refers to how to aggregate the embeddings of neighboring nodes to update its own embedding. The following figure illustrates a process of learning in GraphSAGE.Figure 7 First, sample neighbors;Second, the sampled neighbor embeddings are passed to the node, and an aggregation function is used to aggregate this neighbor information to update the node’s embedding;Third, predict the node’s label based on the updated embedding;Next, we will explain in detail how a trained GraphSAGE generates embeddings for a new node (a forward propagation process), as shown in the algorithm diagram:First, (line 1) the algorithm initializes the feature vectors of all nodes in the input graph, (line 3) for each node , after obtaining its sampled neighboring nodes , (line 4) it uses the aggregation function to aggregate the information of neighboring nodes, (line 5) and combines its own embedding to update its embedding representation through a non-linear transformation.Note that in the algorithm, refers to the number of aggregators, which also indicates the number of weight matrices and the number of layers in the network. This is because the aggregator and weight matrix are shared in each layer of the network. The number of layers in the network can be understood as the maximum number of hops to access neighbors. For example, in Figure 7, the red node’s update obtains information from its first and second-hop neighbors, so the network layer count is 2. To update the red node, in the first layer (k=1), we aggregate information from blue nodes to the red node, and aggregate information from green nodes to the blue nodes. In the second layer (k=2), the embedding of the red node is updated again, but this time using the updated blue node embeddings, ensuring that the updated embedding of the red node includes information from both blue and green nodes, i.e., two-hop information.For clarity, let’s expand the process of updating a specific node. Figures 8 show the update processes for nodes A and B, where we can see that the process of updating different nodes shares the aggregator and weight matrix in each layer of the network.Figure 8So how does GraphSAGE perform sampling? GraphSAGE employs a fixed-length sampling method, specifically defining the required number of neighbors , and then using resampling/negative sampling methods to achieve . This ensures that the number of neighbors for each node (after sampling) is consistent, which allows multiple nodes and their neighbors to be concatenated into a Tensor for batch training on the GPU.What aggregators does GraphSAGE have? There are mainly three:It is worth noting that the Mean Aggregator and GCN’s approach are basically the same (GCN actually sums the values).At this point, the entire architecture of the model has been covered. How does GraphSAGE learn the parameters of the aggregator and the weight matrix ? In the case of supervised learning, the cross-entropy loss can be used based on the predicted labels and true labels for each node. In the case of unsupervised learning, it can be assumed that the embeddings of adjacent nodes should be as close as possible, thus forming the following loss function:How effective is GraphSAGE in actual experiments? The authors provided results for both unsupervised and fully supervised cases on datasets such as Citation, Reddit, and PPI, showing significant improvements compared to traditional methods.Thus, the introduction of GraphSAGE is complete. Let’s summarize some advantages of GraphSAGE:(1) By utilizing a sampling mechanism, it effectively solves the problem of GCN needing to know the entire graph’s information, overcoming the memory and GPU limitations during GCN training, allowing it to obtain representations even for unknown new nodes;(2) The parameters of the aggregator and weight matrix are shared across all nodes;(3) The number of model parameters is independent of the number of nodes in the graph, enabling GraphSAGE to handle larger graphs;(4) It can handle both supervised and unsupervised tasks.(I really like ideas that solve problems simply and effectively!!!)Of course, GraphSAGE also has some drawbacks. With so many neighbors for each node, GraphSAGE’s sampling does not consider the varying importance of different neighboring nodes, and the importance of neighboring nodes can differ from that of the current node during aggregation calculations.3. Graph Attention Networks (GAT) [9]To address the issue of GNN not considering the varying importance of neighboring nodes during aggregation, GAT borrowed the idea from Transformers, introducing a masked self-attention mechanism. When calculating the representation of each node in the graph, it assigns different weights based on the features of neighboring nodes.Specifically, for the input graph, a graph attention layer is shown in Figure 9:
Figure 9
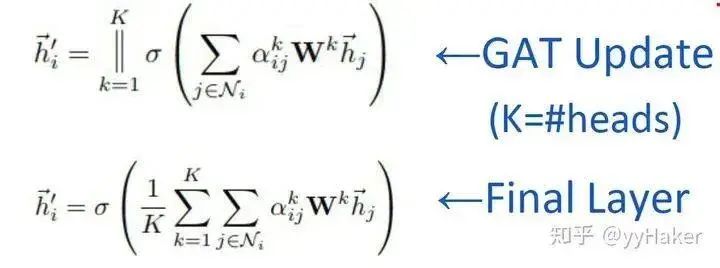
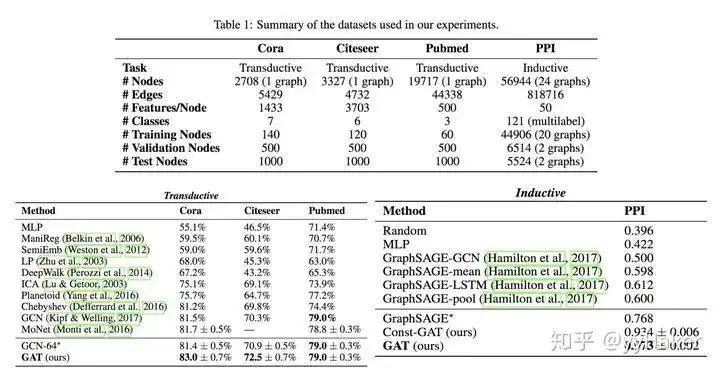
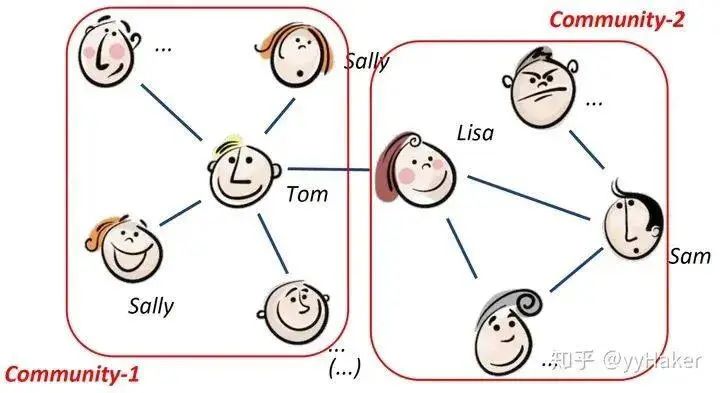
In this, employs a single-layer feedforward neural network to implement the computation process (note that the weight matrix is shared across all nodes):Once the attention is computed, a new representation of a node aggregating its neighboring node information can be obtained, as shown in the calculation process:To enhance the model’s fitting ability, a multi-head self-attention mechanism is also introduced, which simultaneously uses multiple to compute self-attention and then merges (concatenates or sums) the results:Additionally, due to the characteristics of the GAT structure, GAT does not require a pre-constructed graph, making it suitable for both Transductive Learning and Inductive Learning.What are the specific effects of GAT? The authors conducted experiments on three Transductive Learning tasks and one Inductive Learning task, with the results as follows:In both Transductive Learning and Inductive Learning tasks, GAT outperformed traditional methods.At this point, the introduction of GAT is complete. Let’s summarize some advantages of GAT:(1) Training GCN does not require knowledge of the entire graph structure, only the neighbor nodes of each node;(2) Fast computation speed, allowing for parallel computation across different nodes;(3) Suitable for both Transductive Learning and Inductive Learning, able to handle unseen graph structures.(Once again, a simple idea that solves the problem effectively!!!)Thus, we have introduced the most classic models in GNN: GCN, GraphSAGE, and GAT. Next, we will introduce some popular GNN models and methods based on specific task categories.4. Unsupervised Node Representation LearningBecause the cost of labeled data is very high, being able to learn node representations well using unsupervised methods will have tremendous value and significance, such as finding communities with similar interests, discovering interesting structures in large-scale graphs, etc.Figure 10Among them, classic models include GraphSAGE, Graph Auto-Encoder (GAE), etc. GraphSAGE is a very good unsupervised representation learning method, which has already been introduced, so it will not be repeated here. Next, we will explain the latter two in detail.
Graph Auto-Encoder (GAE) [10]
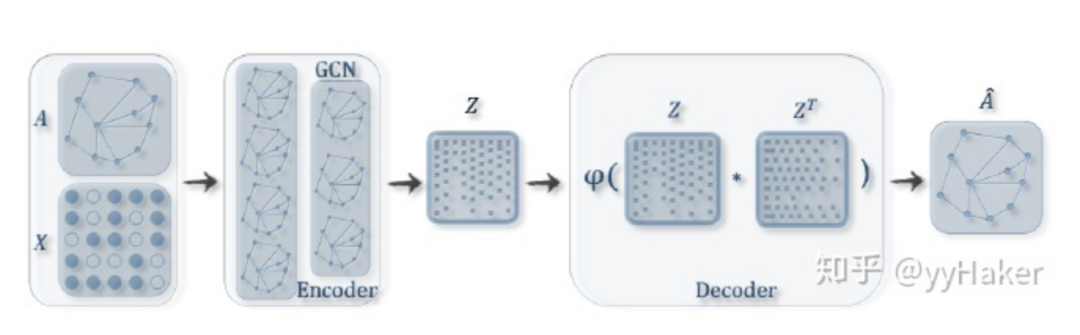
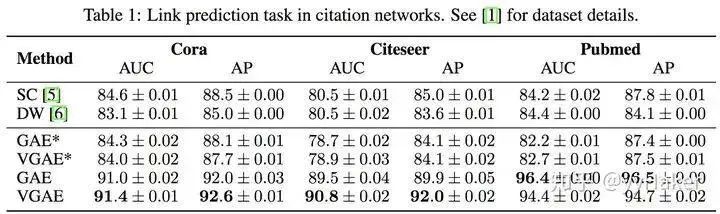
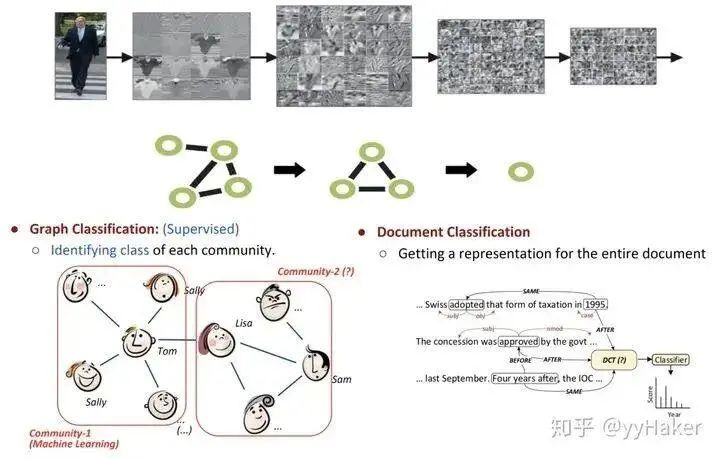
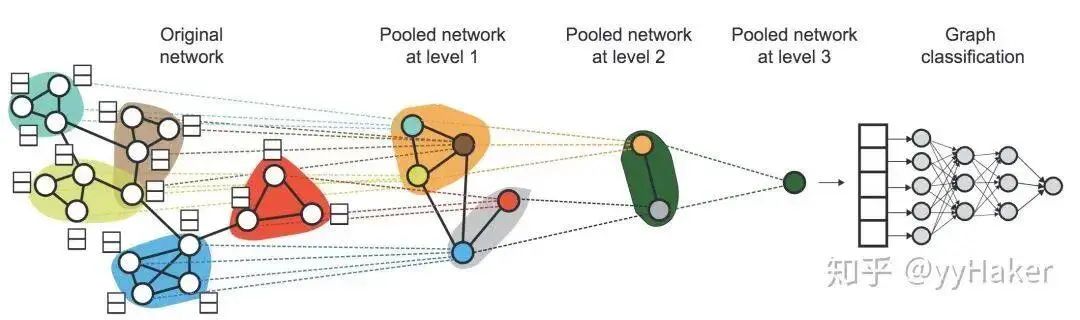
Before introducing Graph Auto-Encoder, it is important to understand Auto-Encoders and Variational Auto-Encoders. For details, please refer to [11], and it will not be elaborated here.Once you understand Auto-Encoders, it becomes much easier to understand Variational Graph Auto-Encoders. As shown in Figure 11, the input graph’s adjacency matrix and node feature matrix are processed through an encoder (graph convolutional network) to learn the mean μ and variance σ of the low-dimensional vector representation of the nodes, and then the decoder (link prediction) generates the graph.Figure 11The encoder employs a simple two-layer GCN network, while the decoder calculates the probability of an edge existing between two points to reconstruct the graph. The loss function includes a distance measure between the generated graph and the original graph, as well as the KL divergence between the node representation vector distribution and the normal distribution. The specific formulas are shown in Figure 12:Figure 12Additionally, for comparison, the authors proposed the Graph Auto-Encoder. Compared to the Variational Graph Auto-Encoder, the Graph Auto-Encoder is much simpler, with the encoder being two layers of GCN and the loss function only containing Reconstruction Loss.How effective are the two types of graph auto-encoders? The authors conducted link prediction tasks on the Cora, Citeseer, and Pubmed datasets, with the experimental results shown in the following table. The Graph Auto-Encoder (GAE) and Variational Graph Auto-Encoder (VGAE) generally outperform traditional methods, with the Variational Graph Auto-Encoder performing even better; however, on Pubmed, GAE achieved the best results. This may be due to the larger size of the Pubmed network, making the more complex VGAE model harder to tune.5. Graph PoolingGraph pooling is a very popular operation in GNN, aimed at obtaining a representation of an entire graph, primarily used for graph-level classification tasks, such as supervised graph classification and document classification.Figure 13There are many methods for graph pooling, such as simple max pooling and mean pooling. However, these two pooling methods are not efficient and ignore the order information of nodes. Here, we introduce a method: Differentiable Pooling (DiffPool).1. DiffPool [12]In graph-level tasks, many current methods simply perform global pooling on all node embeddings, neglecting any hierarchical structures that may exist in the graph. This is particularly problematic for graph classification tasks, as the goal is to predict the label of the entire graph. To address this issue, the Stanford University team proposed a differentiable pooling operation module for graph classification—DiffPool—which can generate hierarchical representations of graphs and can be integrated into various graph neural networks in an end-to-end manner.The core idea of DiffPool is to use a differentiable pooling operation module to hierarchically aggregate graph nodes. Specifically, this differentiable pooling operation module is based on the node embeddings generated by the previous layer of GNN and a allocation matrix, allocating clusters to the next layer in an end-to-end manner, allowing multiple GNN layers to be stacked hierarchically (Figure 14).Figure 14So how are the node embeddings and allocation matrix calculated? After calculating, how are they allocated to the next layer? This involves two parts: learning the allocation matrix and pooling the allocation matrix.
Learning the Allocation Matrix
Two separate GNNs are used to generate the allocation matrix and new embeddings for each cluster node, which both take the cluster node feature matrix and the coarsened adjacency matrix as input:
Pooling the Allocation Matrix
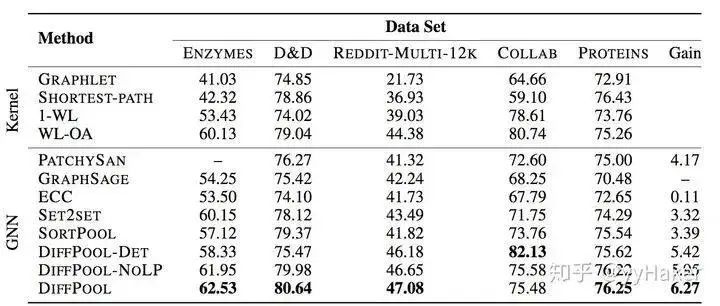
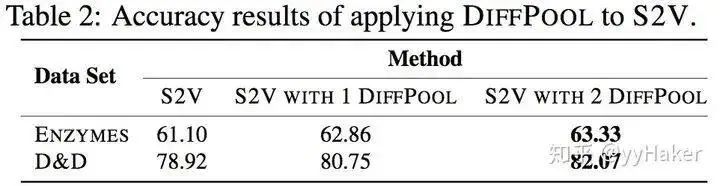
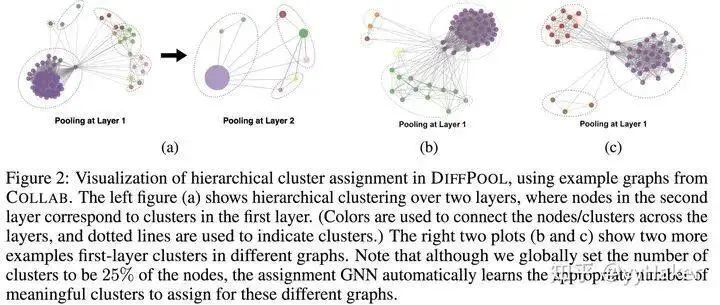
After calculating the allocation matrix and the new embeddings for each cluster node, the DiffPool layer generates a new coarsened adjacency matrix and a new embedding matrix for each node/cluster in the graph based on the allocation matrix:Overall, each layer of DiffPool essentially updates the embeddings of each cluster node and the feature matrix of the cluster nodes, as shown in the following formula:At this point, the basic idea of DiffPool has been explained. How effective is it? The authors conducted experiments on various benchmark datasets for graph classification, such as protein datasets (ENZYMES, PROTEINS, D&D), social network datasets (REDDIT-MULTI-12K), and research collaboration datasets (COLLAB), with the experimental results as follows:Among them, GraphSAGE uses global average pooling; DiffPool-DET is a variant of DiffPool that uses a deterministic graph clustering algorithm to generate the allocation matrix; DiffPool-NOLP is a variant of DiffPool that removes the link prediction objective. Overall, the DiffPool method achieves the highest average performance among all pooling methods in GNN.To further demonstrate the effectiveness of DiffPool for graph classification, the paper also used other GNN architectures (Structure2Vec (s2v)) and constructed two variants for comparative experiments, as shown in the following table:It can be seen that DiffPool significantly improves the performance of S2V on the ENZYMES and D&D datasets.Moreover, DiffPool can automatically learn an appropriate number of clusters.At this point, let’s summarize the advantages of DiffPool:(1) It can learn hierarchical pooling strategies;(2) It can learn hierarchical representations of graphs;(3) It can be integrated into various graph neural networks in an end-to-end manner.However, it should be noted that DiffPool also has its limitations, as the allocation matrix requires a large amount of space for storage, with a space complexity of , being the number of pooling layers, thus it cannot handle very large graphs.
References
[1] Graph Neural Networks: A Review of Methods and Applications. arxiv 2018 https://arxiv.org/pdf/1812.08434.pdf[2] A Comprehensive Survey on Graph Neural Networks. arxiv 2019. https://arxiv.org/pdf/1901.00596.pdf[3] Deep Learning on Graphs: A Survey. arxiv 2018 https://arxiv.org/pdf/1812.04202.pdf[4] GNNpapers https://github.com/thunlp/GNNPapers/blob/master/README.md[5] Semi-Supervised Classification with Graph Convolutional Networks (ICLR 2017) https://arxiv.org/pdf/1609.02907[6] How to Understand Graph Convolutional Network (GCN)? https://www.zhihu.com/question/54504471[7] GNN Series: The “Pioneering Work” of Graph Neural Networks CGN Model https://mp.weixin.qq.com/s/jBQOgP-I4FQT1EU8y72ICA[8] Inductive Representation Learning on Large Graphs (2017 NIPS) https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf[9] Graph Attention Networks (ICLR 2018) https://arxiv.org/pdf/1710.10903[10] Variational Graph Auto-Encoders (NIPS 2016) https://arxiv.org/pdf/1611.07308[11] VGAE (Variational Graph Auto-Encoders)Paper Explanation https://zhuanlan.zhihu.com/p/78340397[12] Hierarchical Graph Representation Learning with Differentiable Pooling (NIPS 2018) https://arxiv.org/pdf/1806.08
Highlights of This Article
1. The drawbacks of GCN are quite evident:
First, GCN requires the entire graph to be loaded into memory and GPU memory, which can be very memory-intensive and cannot handle large graphs;
Second, GCN needs to know the entire graph’s structural information (including the nodes to be predicted).
2. Advantages of GraphSAGE:
(1) By utilizing a sampling mechanism, it effectively solves the problem of GCN needing to know the entire graph’s information, overcoming memory and GPU limitations during GCN training, allowing it to obtain representations even for unknown new nodes;
(2) The parameters of the aggregator and weight matrix are shared across all nodes;
(3) The number of model parameters is independent of the number of nodes in the graph, enabling GraphSAGE to handle larger graphs;
(4) It can handle both supervised and unsupervised tasks. 3. Advantages of GAT:
(1) Training GCN does not require knowledge of the entire graph structure, only the neighbor nodes of each node;
(2) Fast computation speed, allowing for parallel computation across different nodes;
(3) Suitable for both Transductive Learning and Inductive Learning, able to handle unseen graph structures.
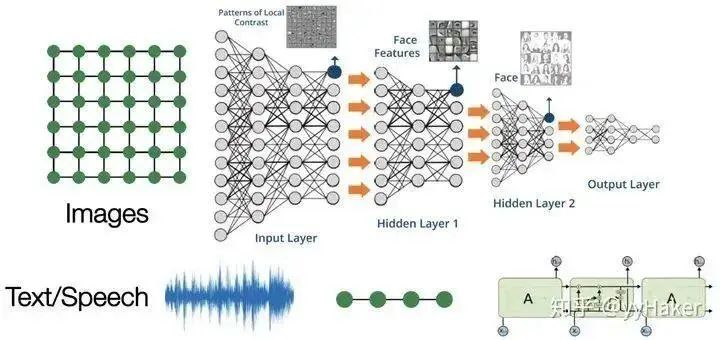
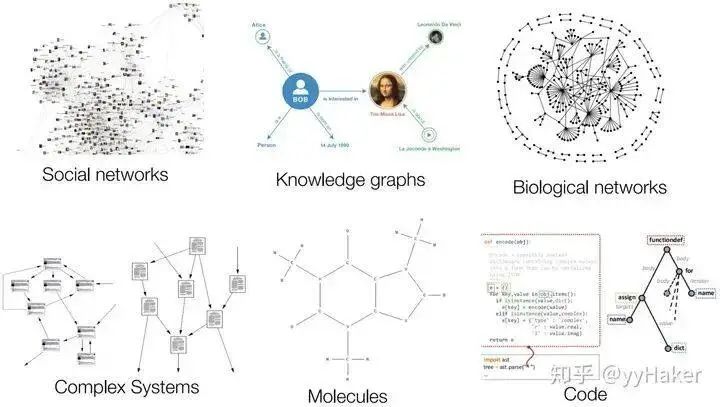
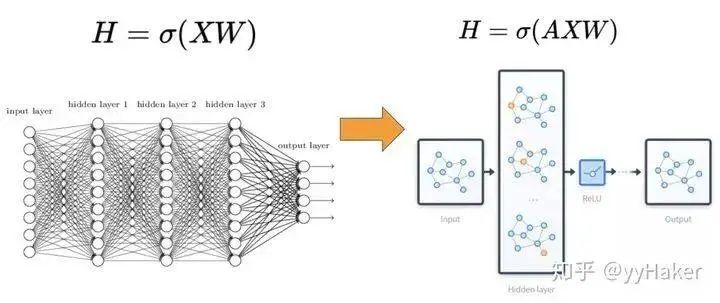
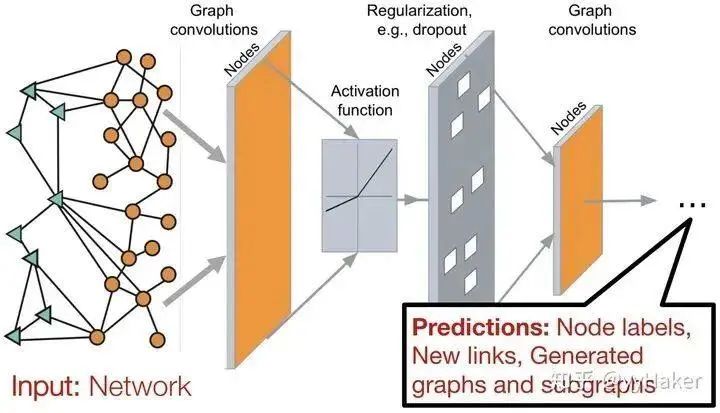
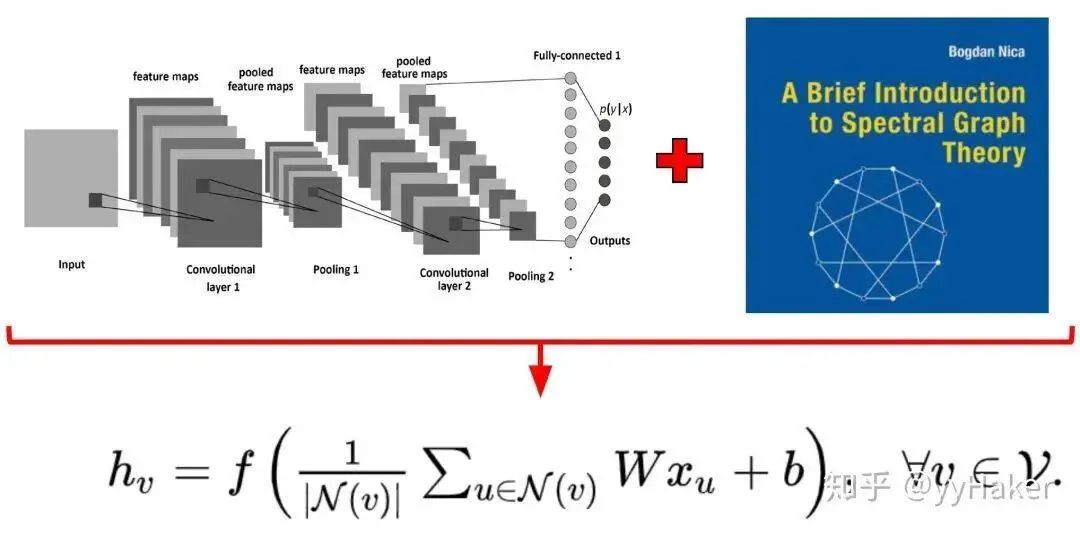
 Figure 6
Figure 6


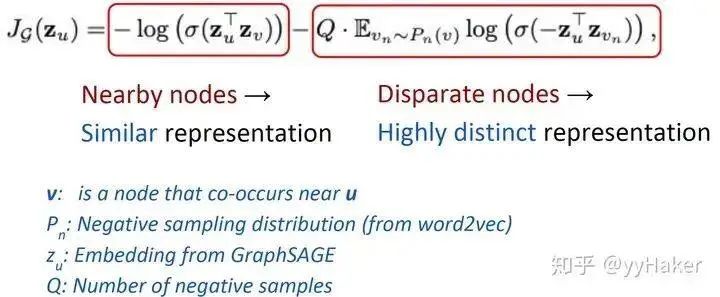
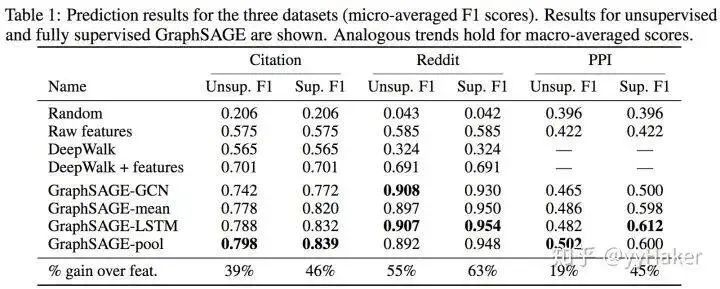
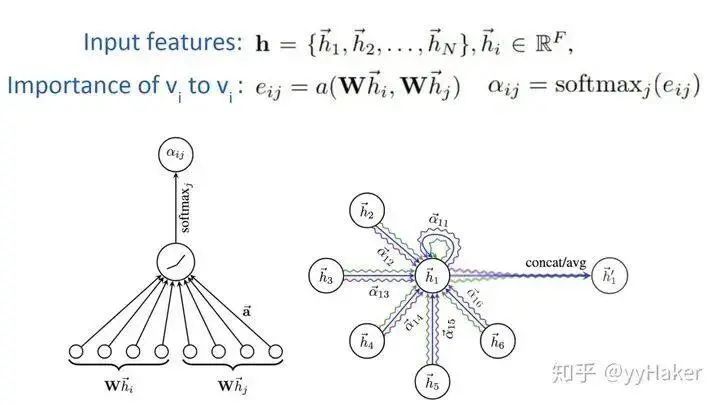 Figure 9
Figure 9