

This article is approximately 5400 words, and it is recommended to read in 10minutes
From neural search to multimodal applications, here neural search refers to the use of neural network models in search systems.
When it comes to neural search, multimodal data inevitably comes to mind because the greatest advantage of neural networks over traditional search methods lies in their ability to easily fuse data from different modalities.
This article will introduce the following aspects:
-
From Neural Search to Multimodal Applications
-
Multimodal Data
-
Multimodal Application Services
-
Practices of Jina Family in DocsQA
01 From Neural Search to Multimodal Applications
First, let’s look at a typical multimodal data—news, which contains not only text but also images, and some news may even contain video information. It is a mixture of different modal data. Another noteworthy aspect is the nested structure within multimodal data. For example, news has different paragraphs, and paragraphs can be broken down into sentences and further segmented.
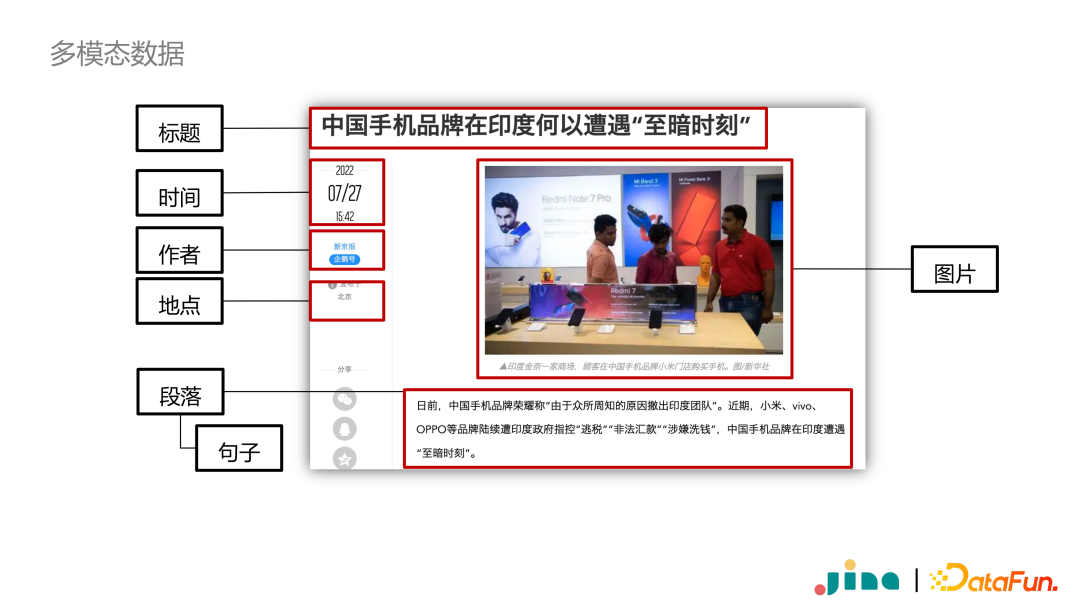
Why is this nested structure very important for multimodal data? Because multimodal data not only involves different modalities, but its semantics need to be represented at different granularities. Therefore, multimodal data has two important characteristics: one is multiple modalities, and the other is nested structure.
Common multimodal data also includes products in e-commerce, videos on video websites, music on music websites, etc. In recent years, research on multimodal data has also increased. For example, OpenAI is working on two models, DALL·E and CLIP, and recently on DALL·E2; domestically, Baidu and Wudao are also conducting related research; internationally, Microsoft, Google, and Facebook have also been doing related research.

Now, more and more researchers are beginning to engage in the multimodal field. One main reason is that models in the fields of CV and NLP are increasingly tending towards unification, leading to the natural thought of whether they can be integrated.
Since multimodal applications are becoming increasingly popular, can we easily build a complete, production-ready multimodal service from scratch? In fact, building from scratch and deploying it online is still a very complex process. Let’s look at the issues we might encounter.
02 Multimodal Data
The first issue is that after obtaining multimodal data, we need to represent this multimodal data. Returning to the news example we just looked at, we can simply write a dataclass in Python, defining several fields, one for storing the picture’s URL; we can also define the title as a string type; define paragraphs; and add a dictionary to define meta information, including the author, location, etc.

This doesn’t seem too complicated. We can achieve support for different modal data through a dataclass, and it can also have a nested structure.
However, after having this representation, we still need some operations on the data. For example, if we have news data and want to perform vector representation calculations, such as using the CLIP model, the first step is to download the image and store it in a local cache, then load it and hand it over to the model for processing. This requires writing additional code. After generating the vector, we will also encounter the issue of how to store the vector. One method is to store the vector in a vector database, which inevitably involves configuring the vector database.
On the other hand, when developing a multimodal application, it is inevitable to spend some time exploring the data initially. At this time, we will need to retrieve data, possibly using vectors to see what similar data looks like, or using fields to filter, such as only looking at news written by the Beijing News. To achieve these functions, we either need to query the database directly or write for loops, both of which are relatively inefficient.
In addition, multimodal data usually contains data from different modalities, such as video and audio, and often we hope to preview these data. At this point, we will need to implement these preview functions ourselves.
Finally, we also need to consider network transmission. In multimodal applications, the services we build often form a pipeline, and data will flow between different modules, which involves the efficiency of data transmission during the flow process. Of course, the simplest way is to use JSON for serialization, but this results in low transmission efficiency, which can impact the overall efficiency of the service.

To address these issues, we developed DocArray, a data structure toolkit for handling unstructured multimodal data. It can unify various types of unstructured data into the same data structure Document.
Let’s use the earlier news example to introduce how to use the Document class. The code that needs to be modified only requires two steps: the first step is to use the dataclass encapsulation provided by DocArray to replace Python’s native dataclass; the second step is to use our provided multimodal data type to replace Python’s native data type. Using the Document class to represent multimodal data is much more powerful than before.
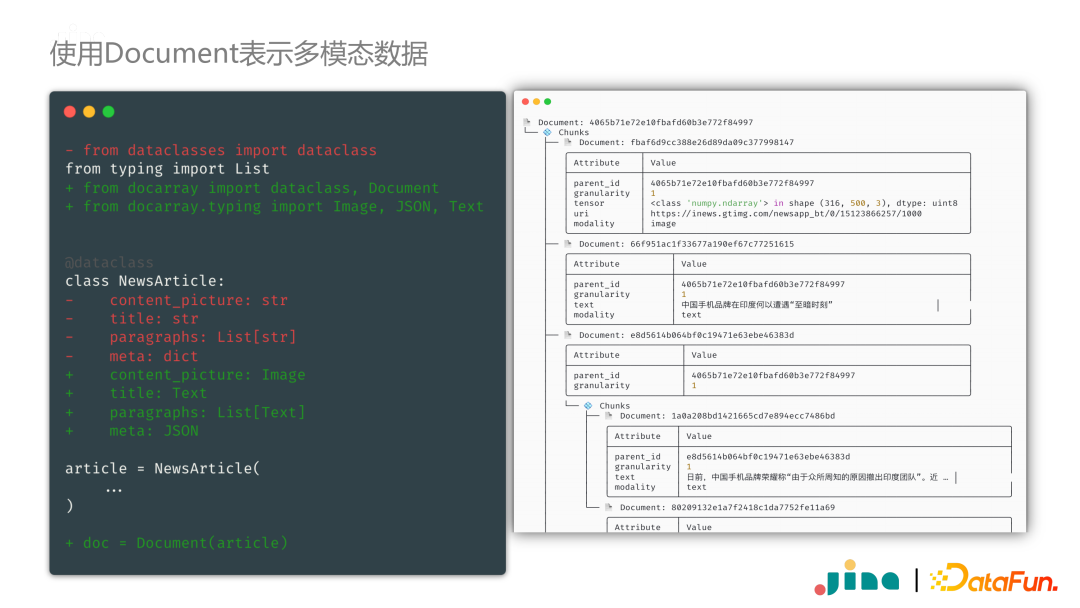
Firstly, the Document class has better support for different modalities of data. For example, the field content_picture for storing images previously only stored the URL, and required us to write an image downloading module during loading. After encapsulating with Document, these operations can be completed automatically. As seen in the right part of the image above, we have saved the URL of the image along with the corresponding image.
Secondly, the Document class provides native support for nested structures. Returning to the example of representing news, to represent the paragraph structure of an article, we only need to choose List when defining paragraphs, along with the required modal types, and it can automatically be transformed into a nested structure. The Document also supports multi-layer nesting, making it very convenient to represent information at different semantic granularities.

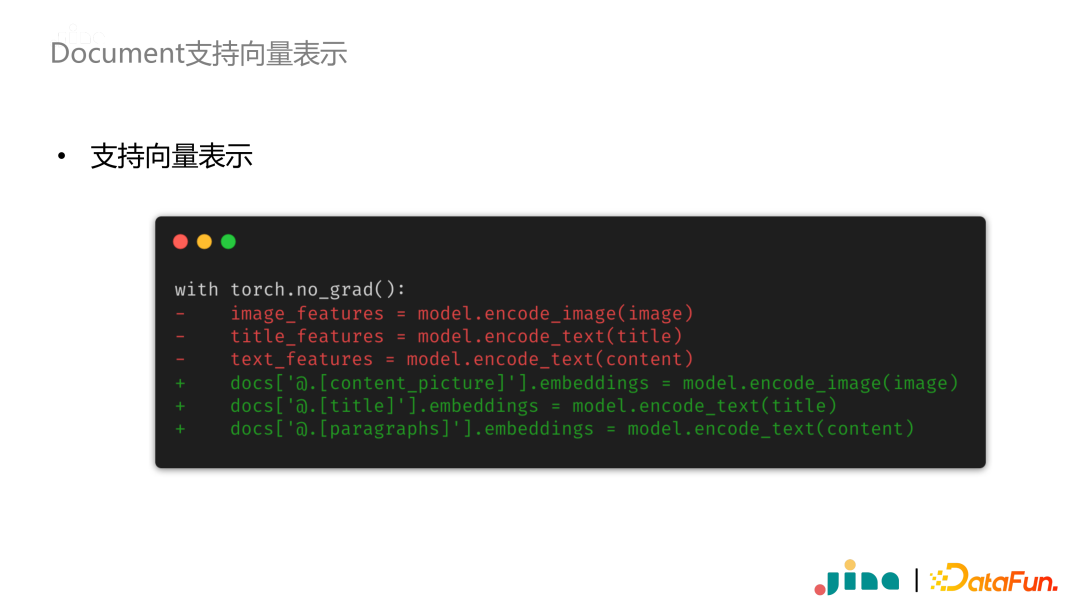
Thirdly, the Document class natively supports the representation of embeddings. After calculating the embeddings with a model, we can directly save them.
In addition, the Document class also provides various very convenient operation functions. For example, when processing video data, it often requires frame extraction, which is natively supported by Document. In the data exploration process, the Document data type provides preview functions, allowing direct listening to audio, watching videos, and displaying information in each nested structure.
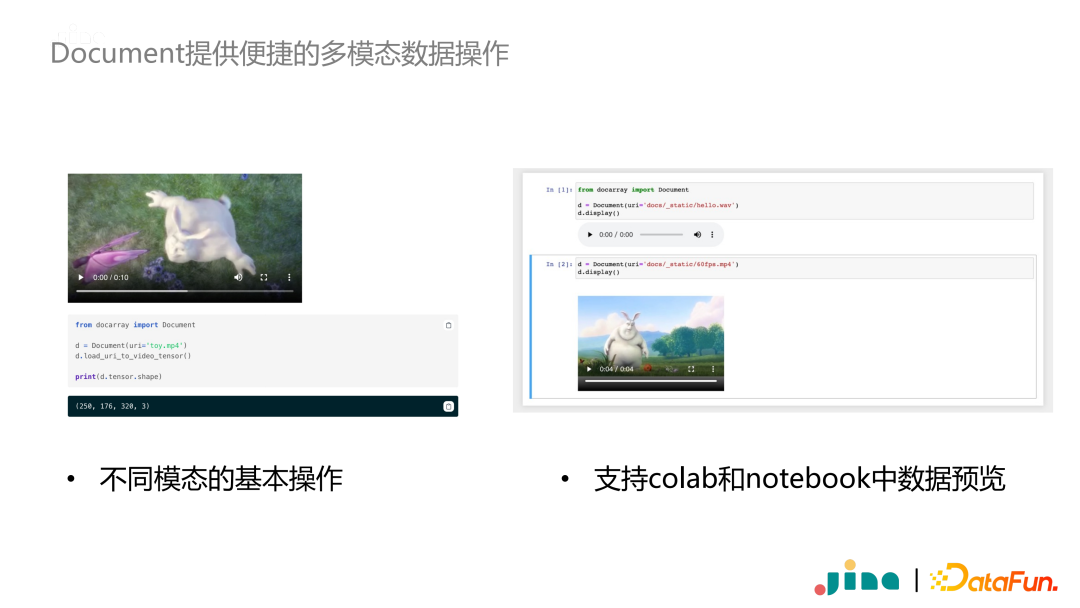
The Document class also provides previews of embeddings and supports different frameworks. Whether using PyTorch, TensorFlow, or Paddle, tensors can be directly stored in Document and previewed in lower-dimensional space.

The Document class only encapsulates a single multimodal text. In actual training or inference, we often need to perform batch processing on a group of Documents. Therefore, we defined the DocumentArray data type, which developers can use as a List(Document).
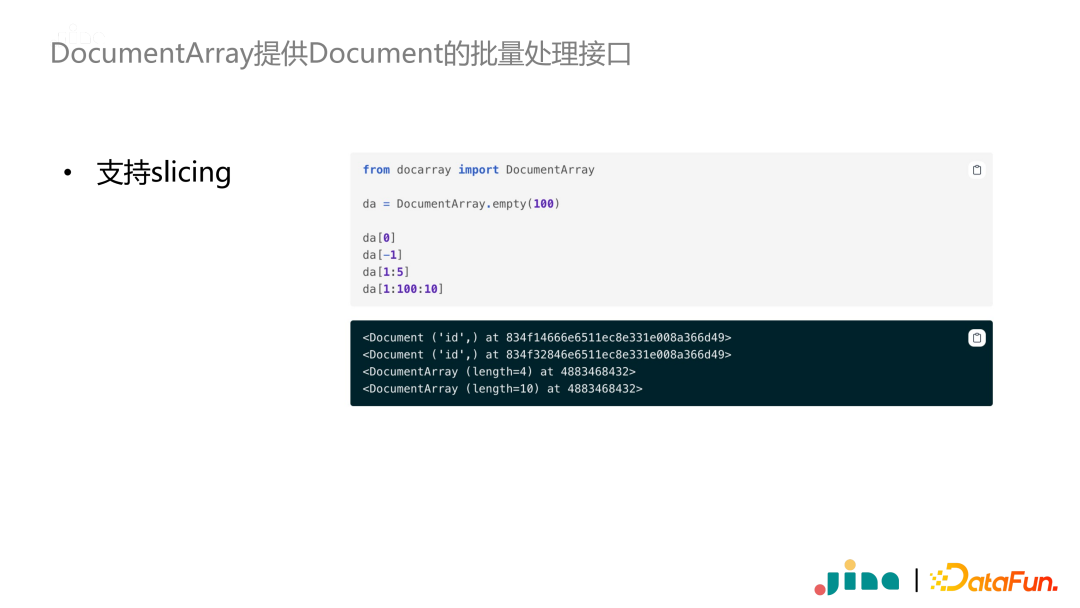
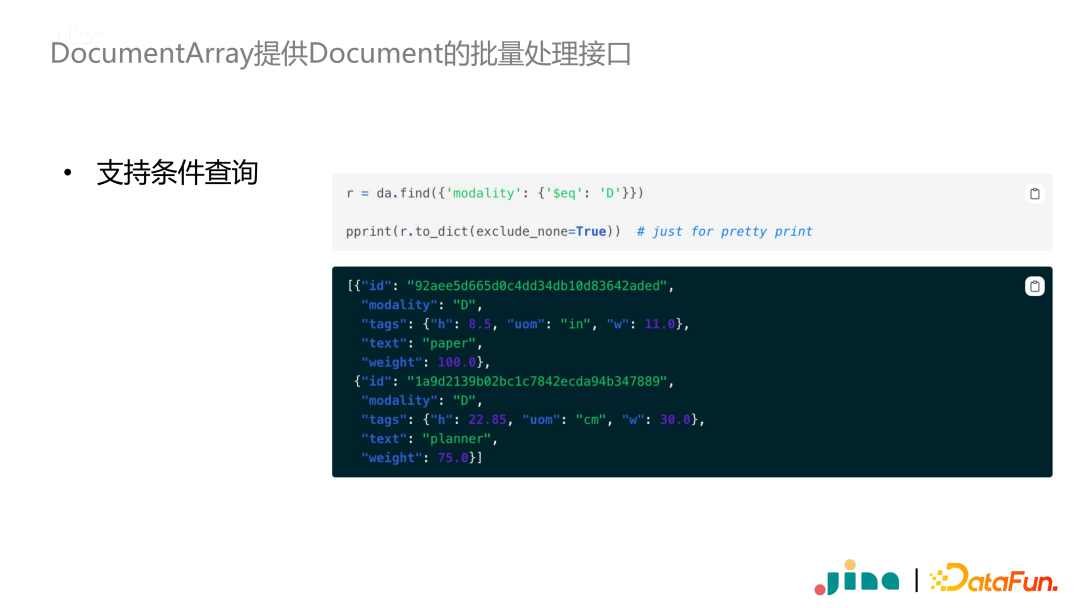
DocumentArray supports slicing. Moreover, DocumentArray supports conditional queries. For example, in the image below, we want to find all Documents where the modality field equals D.
DocumentArray supports various vector storage solutions. The native storage solution is in-memory storage, which is convenient for quick data exploration. If the data is too large, it can be stored on disk using SQLite. Additionally, DocumentArray supports various vector storage solutions, including Weaviate, Qdrant, ElasticSearch, Redis, etc. We also provide a library called ANNLite based on SQLite and HNSWlib for approximate vector indexing. Choosing between different storage solutions is also very convenient; you only need to adjust the storage parameters.

The Document and DocumentArray classes were originally part of our Jina framework. During the development of the framework, we found that these two data structures are very useful for representing multimodal data, and many community members have provided feedback that they hope to use these two classes separately. Therefore, we extracted these two data structures and released a software package called DocArray. Now, DocArray provides the underlying data structure for our Jina family, serving as the common language in the entire framework.
03 Multimodal Application Services
After solving the representation problem of multimodal data, the next challenge is how to build multimodal application services. During the construction process, common issues encountered include the following:
-
Building multimodal applications cannot do without neural network models. When deploying neural network models, developers often encounter issues of inconsistent framework versions and development environments. This usually requires the use of containerization while ensuring normal communication between different containers. This is a very challenging engineering issue.
-
Secondly, since services need to be provided externally, developers often need to build their own external service interfaces. They may use FastAPI, Flask, or GraphQL, and sometimes downstream services may require gRPC or HTTP. All these interfaces need to be adapted by developers.
-
The third point is that multimodal data and application services often involve many modules, each with significantly different computational requirements. Therefore, building services usually showcases distributed systems, ensuring that different modules run on different machines while maintaining scalability. For example, using multiple replicas for parallel processing in modules with high computational demands.
-
The fourth point is that the production environment is now based on cloud-native environments based on Kubernetes. If one wants to complete this by themselves, they need to have a certain understanding of commonly used monitoring and alerting tools. The entire process, not including model tuning time, takes at least several weeks to complete.

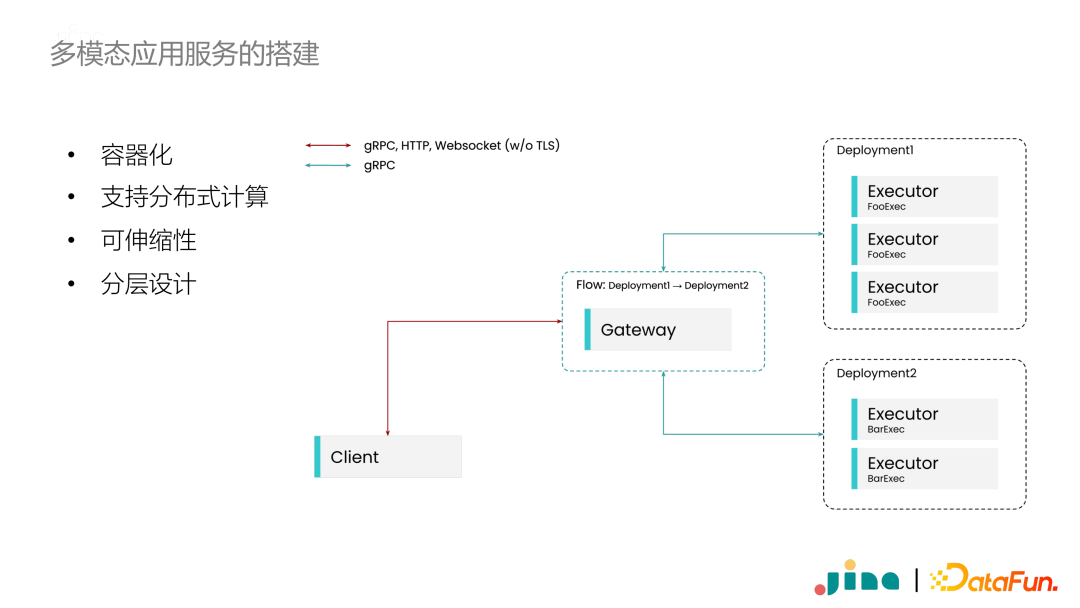
To address these issues, we designed the Jina framework. In Jina, we fully consider the use of distributed systems and containers, and specifically designed for cloud-native environments. In the multimodal services implemented in Jina, we refer to it as a Flow. The Flow itself constitutes a star network, with the central core referred to as a gateway. Each small module in the network, which can also be understood as each step in the data processing, is referred to as an Executor. Executors come together to form a Flow, and data transfer between Executors occurs via network communication.
Additionally, we follow a layered design principle. The lowest layer is network communication; the middle layer is responsible for orchestrating the entire service; the top layer is the Executors, responsible for business logic. For the vast majority of developers, they only need to focus on the Executor layer, while the other two layers of services are entirely handled by Jina. There is a concept called Deployment, which corresponds to the middle layer. The Deployment encapsulates one or more functionally identical Executors, unifying communication with the gateway and providing support for service scalability.
Now, let’s look at an example of writing an executor using Jina. In the earlier example of calculating embeddings using the CLIP model, the only change in the code is to use a class instead of a function. The entire process only requires two steps: the first step is to create a class that inherits from the Executor class; the second step is to add a request decorator in the data processing part, indicating to the framework that we want to use this function to handle the corresponding request. Once these two steps are completed, the Jina framework can add the necessary APIs for your class to ensure that it can be directly integrated into the Flow.

After defining the Executor, we can define our system. For example, the diagram below defines a simple system that includes two encoders, one for calculating embeddings for text and the other for calculating embeddings for images, which are then merged. The Flow can be accessed through the Jina client or by sending requests directly using tools like curl. The external service is managed by the previously mentioned Gateway, which serves as the center of the entire service, providing different protocols such as HTTP, WebSocket, gRPC, and GraphQL.

Jina automatically generates Open API, making it very convenient for downstream developers to interface and debug. When we debug and trace bugs, we can also use these interfaces for some debugging.

On the other hand, we considered that code and configuration must be separated during the design process. Therefore, all Flow definitions can be directly utilized through YAML configuration files, which are entirely equivalent to Python code. This design allows developers to modify configurations anytime and anywhere. For example, if a certain module lacks computational resources, and we wish to horizontally scale it, we can simply add a variable in the configuration file to set replicas to 3, and Jina will automatically scale the service.
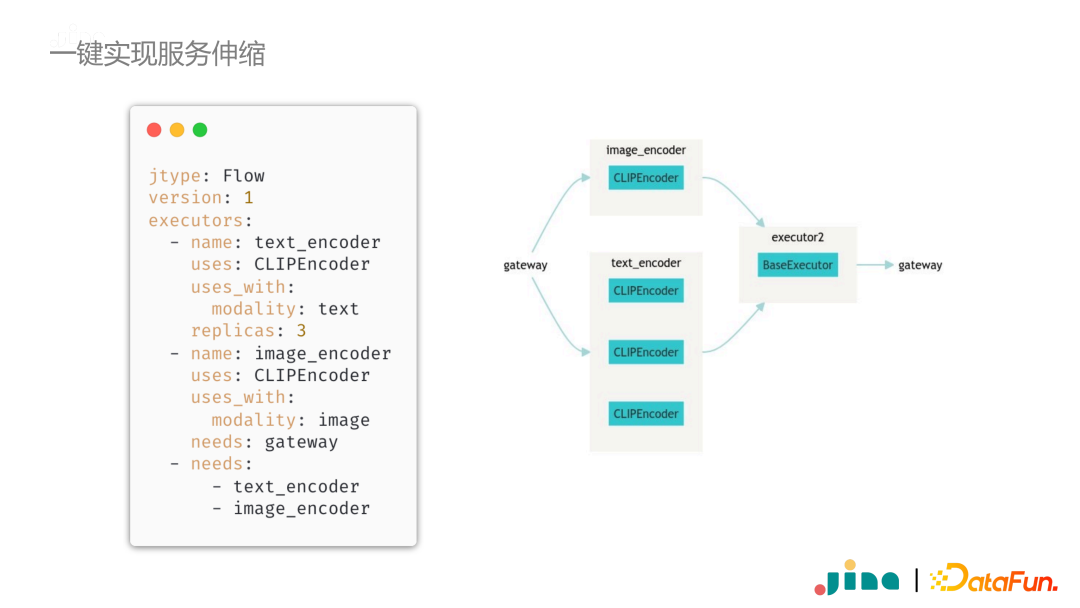
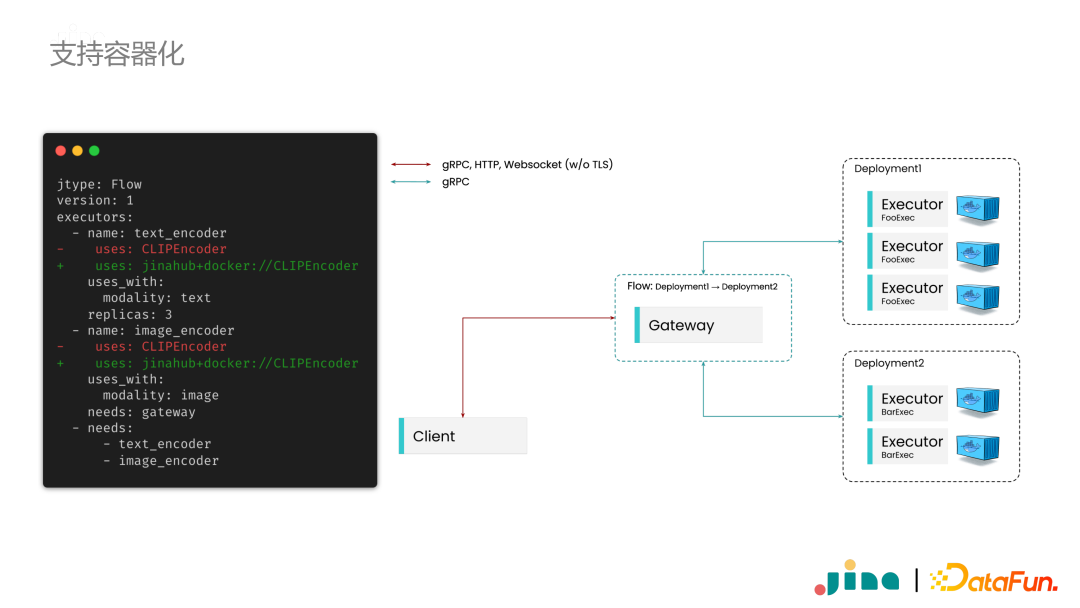
As previously mentioned, deep learning models often rely on complex dependencies, especially during deployment. One solution is to use containerization technology. In Jina, if you want to use containerization during flow invocation, simply use the Jina Hub + docker protocol prefix in the configuration file to directly enable the container and call the corresponding service.
Regarding cloud-native environments, if you do not wish to use Jina’s orchestration, we also provide one-click deployment in Kubernetes environments. After defining your Flow, you can export the Kubernetes configuration file. Additionally, we provide support for commonly used interfaces such as Grafana, Prometheus, and fluentd.

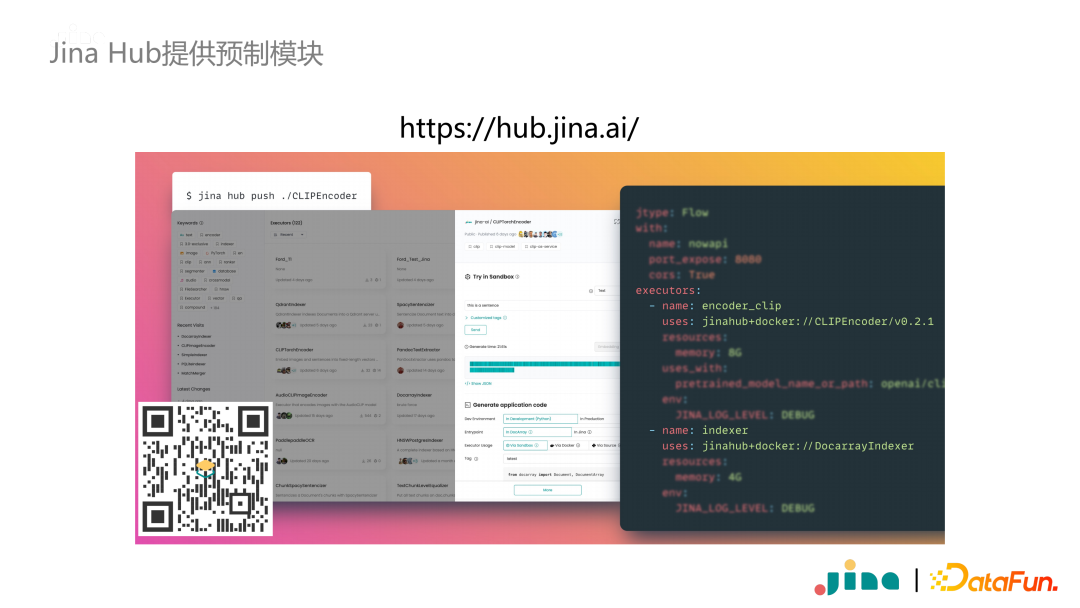
As previously mentioned, we have a Jina Hub protocol prefix. If you want to use containers, you can publish using Jina Hub. Jina Hub provides a large number of pre-built modules. For example, in information extraction tasks, commonly used modules extract text and images from PDF files, or extract frames or subtitles from videos, all of which can be found in Jina Hub. Another function of Jina Hub is to facilitate sharing modules. For instance, if I write a module and want to use it in another project a few days later, I can share it using Jina Hub.
Another important feature in the Jina ecosystem is the JCloud hosting service. After defining a Flow, you can simply use jc deploy to deploy the service in our cloud environment, JCloud. For example, when local computational resources are limited but you want to run larger encoding models, you can use JCloud to start an embedding service remotely and call it locally. We also provide monitoring, logging, and other backend support. More importantly, all of these services are free.

The following image shows our Jina code repository, and we welcome everyone to follow us. Our intention is to help everyone save time by writing framework code for you so that you can focus more on business logic.

04 Practices of Jina Family in DocsQA
Finally, let’s introduce an instance of the Jina family in our internal product.
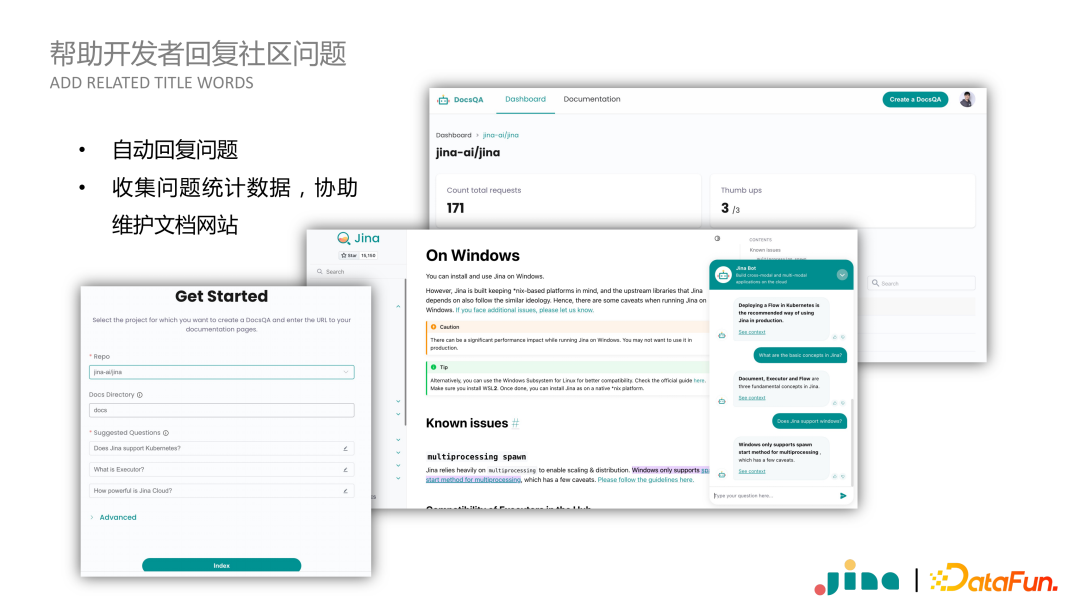
Internally, we have a product called DocsQA, which was originally created because our community is quite large, and there are often repeated questions. To save time, we built a QA system. After completion, we found this service to be very practical, so we opened this service to all open-source software. You only need to provide the documentation address on GitHub, and we can index the documentation. After indexing, you will receive a segment of HTML code to insert into your website to obtain a QA dialog box. In the backend, we provide a dashboard that allows developers to view QA statistics, such as which questions users frequently ask, facilitating targeted adjustments to the documentation by developers.
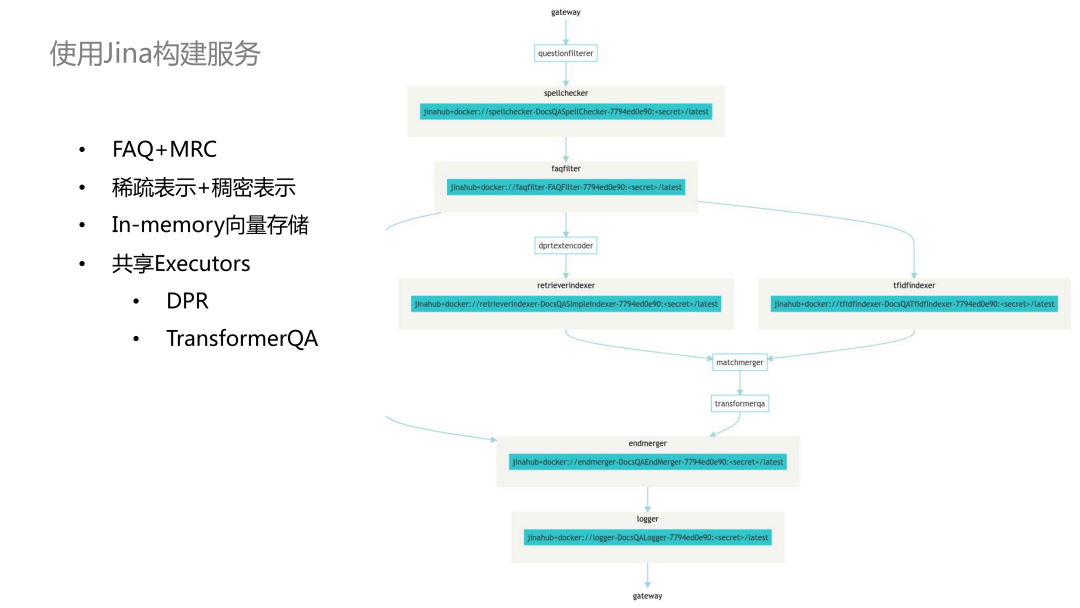
The entire product is built using the Jina family. The diagram below shows the architecture of the Flow. The main recall path is through FAQs, which are matched based on questions; another recall path is through typical Machine Reading Comprehension (MRC) recalls. First, candidates are recalled through sparse and dense methods, and then a Transformer model extracts the answers. It is worth noting that each node in the diagram is a set of microservices, which are the Deployments mentioned earlier. When implementing, you only need to write the core Executor code, and the entire service can be automatically started. The hollow boxes in the diagram represent shared modules. The DPR model and TransformerQA model we use have high computational costs, and most open-source websites have low traffic, so it is impractical to deploy a service for each open-source website to wait for requests. By using Jina’s sharing mechanism, multiple services can share the DPR and TransformerQA services. This approach can save a lot of operational costs and thus provide free services to all open-source software.
In the backend of DocsQA, all deployments are also completed using JCloud. Here we show that when using JCloud for deployment, you only need to call the Python API to complete the deployment. Previously, we used AWS EKS services for deployment, and after migrating to JCloud, the overall cost has decreased by over 80%, as JCloud allows many different services to share nodes and cluster resources.

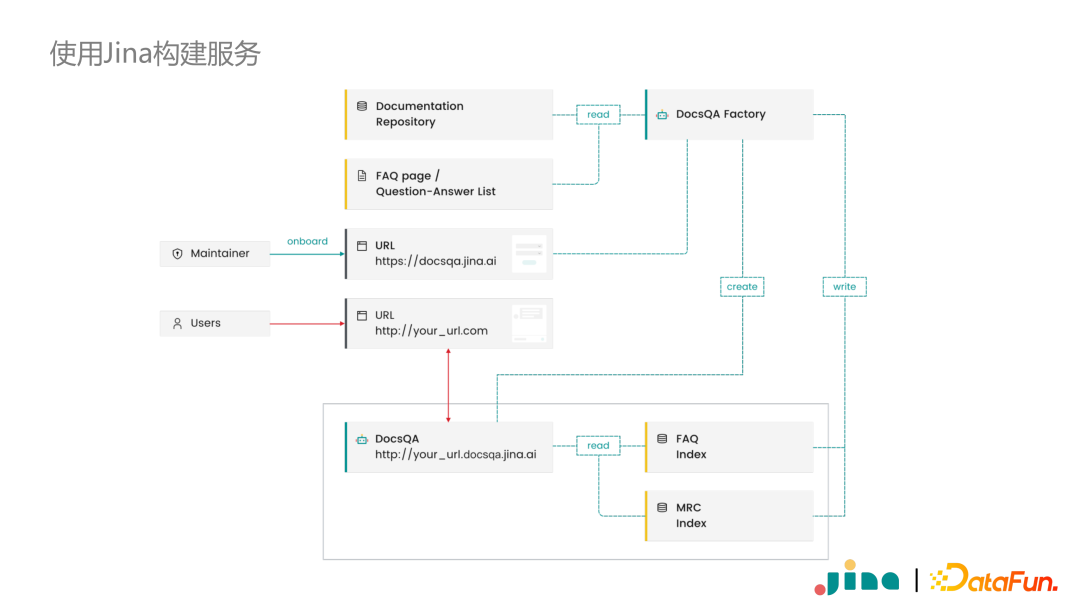
The following diagram shows the entire DocsQA system. The website maintainers only need to provide basic information on our service, primarily the code repository address. The system will automatically initiate an indexing service on JCloud, analyze the content of the code repository, store the index, and then start a query Flow to create a query service. The query service will load the previously created index and provide services externally. The corresponding UI component on the documentation website provides services by calling the service interface. The entire process is very simple and represents a classic QA architecture.
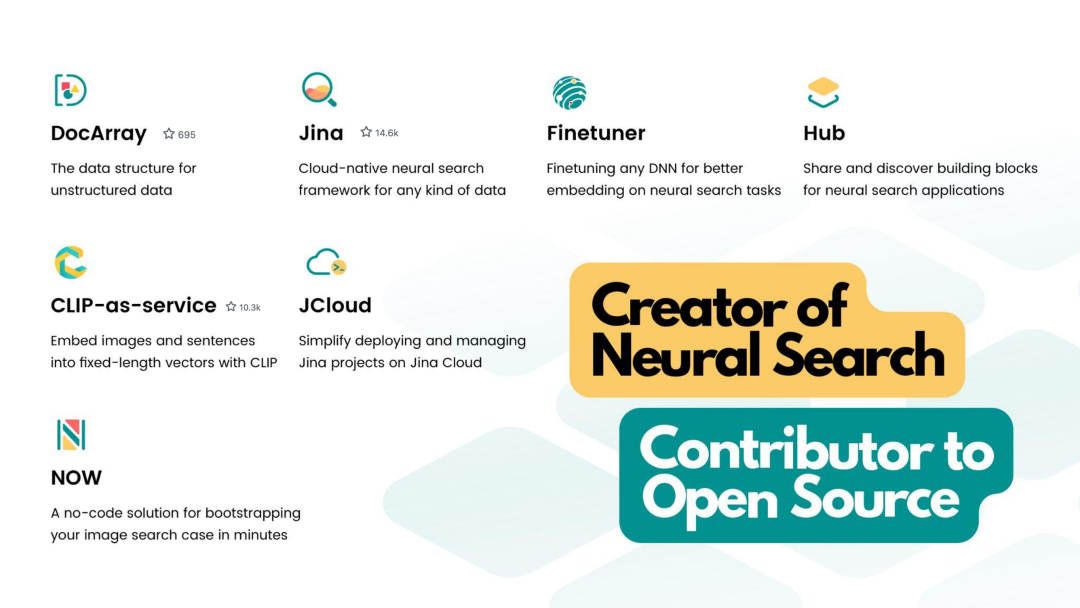
Finally, here’s a summary of our current open-source family. DocArray provides a data type for encapsulating multimodal data; Jina helps everyone build multimodal service applications. In addition, there are a few components that we didn’t have time to introduce, including Finetuner, which provides a SaaS service for model fine-tuning for developers with little deep learning knowledge; Jina Now is an end-to-end neural search solution; and CLIP-as-service is an embedding service based on Jina, where you can directly clone the code and start an embedding service or use the SaaS service.
Additionally, we recommend two projects that are quite popular in our community: one is DALL·E Flow, and the other is DiscoArt. These are AI-assisted creative projects, and both are built using the Jina family, offering high playability. We welcome everyone to try them out.

