
Most applications of artificial intelligence in medicine utilize a single data modality to address tasks within a narrow scope, such as computed tomography (CT) scans or retinal photographs. However, clinicians integrate multi-source, multimodal data for diagnosis, prognosis assessment, and treatment planning. In this review, the authors explore the applications of multimodal datasets in healthcare, the key challenges faced, and promising strategies.
Professor Pranav Rajpurkar and his team from Harvard Medical School published an article titled “Multimodal Biomedical AI” in the journal Nature Medicine (IF=82.9), which discusses multimodal biomedical AI. Although this is an article from 18 months ago, the foresight it provides is still valuable today. Here is the full text:

Abstract
Biomedical data from large biobanks, electronic health records (EHR), medical imaging, wearable and environmental biosensors are increasingly abundant, while the costs of genomic and microbiome sequencing are decreasing, laying the foundation for developing multimodal AI solutions to understand complex human health and disease states. In this review, we outline the existing key applications and the challenges faced in technology and analysis. We also explore opportunities in personalized medicine, digital clinical trials, remote monitoring and care, epidemiological monitoring, digital twin technology, and virtual health assistants. Additionally, we survey the inevitable difficulties in data, modeling, and privacy protection to unleash the full potential of multimodal AI in healthcare.
Main Text
Most applications of AI in medicine utilize a single data modality to solve tasks within a narrow scope, such as CT scans or retinal photographs. However, clinicians integrate multi-source, multimodal data for diagnosis, prognosis assessment, and treatment planning. Furthermore, current AI assessments are often based on instantaneous judgments at the moment of evaluation, neglecting the continuity of bodily states. However, theoretically, AI models should be able to incorporate all data sources available to clinicians, even considering data sources that are not accessible to doctors (e.g., most clinicians have limited knowledge of genomic medicine). The development of multimodal AI models involves cross-modal data—such as biosensors, genetics, epigenetics, proteomics, microbiomics, metabolomics, imaging data, text data, clinical information, social factors, and environmental data—promising to partially bridge this gap and achieve applications such as personalized medicine, integrated epidemiological monitoring, digital clinical trials, and virtual health assistants (Figure 1). In this article, we explore the application of such multimodal datasets in healthcare; next, we discuss the key challenges faced and promising strategies. This article will not discuss the basic concepts of AI and machine learning, but other review articles can be referenced.
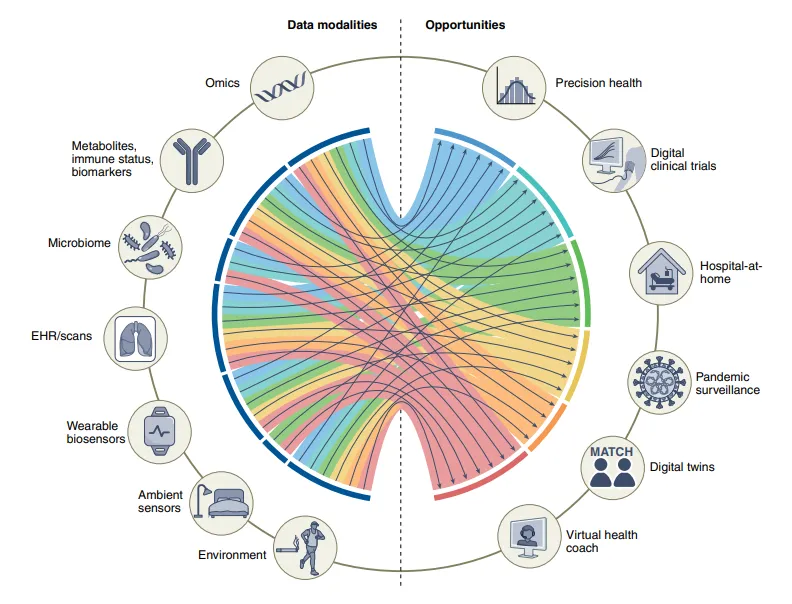
Figure 1. Data modalities and opportunities for multimodal biomedical AI.
Possibilities of Utilizing Multimodal Data
Personalized “Omics” Data for Precision Medicine
With the significant advancements in sequencing technologies over the past 20 years, the number of fine-grained biological data obtained using new technologies has undergone a revolutionary change. These data collectively referred to as “omics” include genomics, proteomics, transcriptomics, immunomics, epigenomics, metabolomics, and microbiomics. These omics data can be analyzed at the bulk or single-cell level. Many medical issues (such as cancer) are heterogeneous at the tissue level and mostly have biological specificity at the cellular and tissue levels.
Various omics have significant value in different clinical and research environments. The detection of malignant tumor genes and molecular markers has been incorporated into clinical practice, and the FDA has approved several diagnostic devices and nucleic acid testing methods. For example, Foundation Medicine and Oncotype IQ provide comprehensive genomic analyses tailored to the major categories of genomic alterations, with the ultimate goal of identifying potential therapeutic targets. In addition to molecular markers, liquid biopsy samples (such as easily obtained bodily fluids like blood and urine) are becoming widely used tools in precision oncology analysis, some of which are based on circulating tumor cells and circulating tumor DNA tests that have been approved by the FDA. Over the past 15 years, the availability of genetic data outside the field of oncology and the development of data sharing have rapidly advanced, making it possible to conduct genome-wide association studies (GWAS) and characterize the genetic architecture of complex human conditions. This has improved our understanding of biological pathways and produced tools such as polygenic risk scores that capture individuals’ overall genetic predisposition to complex traits, which may aid in risk stratification, personalized treatment, and identifying participants most likely to benefit from interventions in clinical research, facilitating the recruitment of relevant experimental subjects.
Integrating these vastly different data for comprehensive analysis remains challenging. Overcoming this challenge is crucial, as integrating EHR and imaging data with omics data is expected to further enhance our understanding of human health and achieve precision, personalized prevention, diagnosis, and treatment strategies. Currently, several methods have been developed to integrate multimodal omics data for precision medicine. For example, graph neural networks (GNNs), which are deep learning model architectures that process computational graphs (a commonly used data structure that includes nodes and edges representing concepts or entities and the connections or relationships between nodes)—help scientists interpret the associative structures of multimodal omics data to improve model performance. Another approach is dimensionality reduction, including new methods such as PHATE and MultiscalePHATE, which can represent low-dimensional representations of biological and clinical data at different granularities, and these methods have proven to predict clinical outcomes during the COVID-19 pandemic.
In the field of cancer, overcoming challenges related to data acquisition, sharing, and accurate labeling may yield effective tools that utilize personalized multimodal omics data combined with tissue pathology, imaging, and clinical data to provide more accurate clinical trajectories and improve patient prognosis. The combination of tissue pathology, morphological data, and transcriptomic data has generated spatial transcriptomics, constituting a novel and promising methodological advancement that allows researchers to study gene expression in a more granular spatial perspective. Notably, researchers have cited deep learning methods that predict gene expression levels at the spatial level using only tissue pathology images, and the morphological features in these images are not manually identified by experts, which may enhance the practicality of this technology and reduce costs.
The costs of genetic data are decreasing, and a single test is sufficient for an individual, but the predictive power of genomic data alone is relatively limited. Combining genomic data with other omics data can capture more real-time dynamic information and understand the interactions between specific combinations of genetic background and environmental exposures to assess a quantifiable continuum of health status. For example, Kellogg et al. conducted individual multimodal (N-of-1) studies with whole genome sequencing (WGS) and periodic measurements of other omics (transcriptomics, proteomics, metabolomics, antibodies, and clinical biomarkers); the results of polygenic risk scores indicated an increased risk of type II diabetes, while the comprehensive analysis of other omics data can early detect and dissect changes in signaling networks during the transition from health to disease.
With technological advancements, the cost-effectiveness of WGS has gradually improved, facilitating the integration of clinical biomarker data with existing genetic data, enabling rapid diagnosis of previously difficult-to-detect diseases. Ultimately, we anticipate the ability to develop multimodal AI tools that incorporate multimodal omics data for deep phenotyping of individuals; in other words, truly understanding the biological specificity of each individual and its impact on health.
Digital Clinical Trials
Randomized clinical trials are the gold standard in clinical settings for studying the causal relationships of new diagnostics, prognostics, and treatment interventions, providing evidence support. Unfortunately, planning and executing high-quality clinical trials are not only time-consuming (often requiring many years to recruit enough volunteers and timely follow up on trials) but also incur high economic costs. Moreover, geographic, sociocultural, and economic differences can lead to weak representation of groups in these studies. This can impact the generalizability of results and exacerbate the prevalent issue of underrepresentation in biomedical research, further exacerbating disparities in clinical trials. Digital clinical trials can facilitate volunteer participation by reducing barriers to volunteer registration and follow-up, optimizing trial measurement methods and interventions, providing unprecedented assistance in overcoming the aforementioned limitations. Additionally, using digital technologies can optimize the granularity of information provided by volunteers, thereby enhancing the value of research.
Data from wearable technologies (including heart rate, sleep, physical activity, electrocardiograms, oxygen saturation, and blood glucose monitoring) and self-administered questionnaires on smartphones can be used to monitor clinical trial patients, identify adverse events, and determine trial outcomes. Furthermore, recent studies have emphasized the potential of data from wearable sensors in predicting laboratory results. Consequently, research involving digital devices has rapidly increased in recent years, with a compound annual growth rate of approximately 34%. Most of these studies utilize data from a single wearable device. A pioneering trial used a “patch”—a patch sensor for detecting atrial fibrillation; remotely registered volunteers could receive trial sensors by mail without needing to go to offline trial sites, laying the foundation for digital clinical trials. Many remote trials using wearable devices to detect COVID-19 were conducted during the pandemic.
Effectively combining data from different wearable sensors with clinical data is both a challenge and an opportunity. Digital clinical trials can achieve automatic phenotyping and subgroup analysis through the multi-source data of volunteers, and for adaptive clinical trials, digital clinical trials facilitate real-time trial design based on ongoing trial results. In the future, we look forward to improved data availability and innovative multimodal learning techniques promoting the development of digital clinical trials. Notably, recent achievements by Google in time series analysis demonstrate that attention-based model architectures hold promise for combining static data with temporal inputs to achieve interpretable time series predictions. Here, a hypothesis is proposed that such models can autonomously determine which features to focus on, such as static features (e.g., genetic background), known temporal features (e.g., time of day), or measured features (e.g., current blood glucose levels), to predict the risk of future hypoglycemia or hyperglycemia. Recently, it has been suggested that graph neural networks can address the issue of data loss or irregular sampling of data from multiple health sensors by leveraging the connectivity characteristics of information between sensors.
Recruitment and follow-up of patients in clinical trials is crucial but remains a challenge. In this context, there is a growing tendency to use synthetic control methods, which utilize external data to achieve control. Although synthetic control trials are still relatively novel, the FDA has already approved several drugs based on historical controls and developed a framework using real-world generated data. Leveraging AI models from multimodal data may help identify or generate optimized synthetic control groups.
Remote Monitoring: “Home Hospital”
In this environment, wearable sensors play a vital role in remote patient monitoring. Affordable non-invasive devices like smartwatches or wristbands that can accurately measure various physiological indicators are emerging in large numbers. Integrating this data with data from EHR—using standards such as Fast Healthcare Interoperability Resources to query potential disease risk information—can create a more personalized remote monitoring model for patients and caregivers. Environmental wireless sensors can also collect valuable data. Environmental sensors are integrated devices in the environment, such as rooms, walls, or mirrors, primarily in the form of cameras, microphones, depth cameras, and radio signals. These environmental sensors may improve remote care systems in homes and healthcare institutions.
Integrating data collected from multimodal data and sensors greatly enhances the feasibility of remotely monitoring patient status, and studies have demonstrated the potential of multimodal data in these scenarios. For instance, the combination of environmental sensors (such as depth cameras and microphones) with wearable device data (accelerometers measuring physical activity) can enhance the reliability of fall detection systems, maintain low false positive rates, and improve gait analysis performance. Early detection of physical functional impairments through daily activities such as bathing, dressing, and eating is crucial for providing timely clinical care, and utilizing multimodal data from wearable devices and environmental sensors may aid in accurately detecting and classifying these behaviors.
In addition to managing chronic or degenerative diseases, multimodal remote patient monitoring can also be applied to acute diseases. A recent project by Mayo Clinic demonstrated the feasibility and safety of remotely monitoring COVID-19 patients. The remote patient monitoring applied in the home hospital has yet to be validated, requiring randomized controlled trials comparing the multimodal AI-based remote monitoring model with inpatient treatment models to confirm its safety. We need to be able to anticipate deteriorating conditions at any time and implement systematic interventions, which are not yet achievable.
Infectious Disease Monitoring and Control
Studies have also demonstrated that using wearable devices to track resting heart rates and sleep duration can improve the monitoring of influenza-like illnesses in the United States. This case evolved into the Digital Engagement and Tracking for Early Control and Treatment (DETECT) health study, initiated by Scripps Research Translational Institute, as an app-based research project aimed at analyzing various datasets from wearable devices for rapid detection of influenza, coronaviruses, and other rapidly spreading viral diseases. A follow-up study of this program indicated that integrating self-reported symptoms and sensor indicator data had better classification accuracy for COVID-19 positive cases compared to single monitoring modes (ROC curve area of 0.80, 95% confidence interval of 0.73-0.86).
Multimodal AI models have tested several applications in epidemic prevention and control with encouraging results, but further validation and replication of these results are still needed.
Digital Twin
Currently, we rely on clinical trials as the best evidence for assessing whether an intervention is successful. A measure that may be effective in only 10 out of 100 subjects is still considered valid, despite the inability to confirm the effectiveness of interventions for the other 90 individuals. A method called “digital twin” can fill this knowledge gap. This method utilizes big data to generate models and accurately predict the beneficial or harmful outcomes of an intervention for specific patients.
Digital twin technology is a concept derived from engineering, using computational models to develop and test different strategies or methods for complex systems (such as a city, an airplane, or a patient), which is faster and more cost-effective than testing in real scenarios. In the field of healthcare, digital twin technology holds great promise for drug target detection.
Reports have proposed using AI tools to integrate data from multiple sources to develop digital twin models in precision oncology and cardiovascular health. There are currently open-source modular frameworks for developing digital twin models applied in medicine. From a commercial perspective, Unlearn.AI has developed and tested a digital twin model using different clinical datasets to enhance clinical trials for Alzheimer’s disease and multiple sclerosis.
Considering the complexity of the human body, developing accurate and practical medical digital twin technology requires aggregating multimodal data, physiological sensor data, clinical information, and sociodemographic data. This requires extensive collaboration between public health systems, researchers, and various enterprises, such as the Digital Twins Consortium in Sweden. The American Society of Clinical Oncology, through its subsidiary CancerLinQ, has developed a platform that can guide and improve treatment plans using data from cancer patients. Therefore, developing AI models capable of effective learning from multimodal data and making real-time predictions is essential.
Virtual Health Assistants
In recent years, over a third of American consumers have purchased smart speakers. However, virtual health assistants—digital AI butlers that can provide advice for people’s health needs—have yet to be widely developed, and the virtual health assistants currently on the market typically apply only to specific scenarios. Additionally, a recent review of health-related voice assistant applications found that most of these applications rely on predetermined response rules and program-driven conversations.
Although current virtual health assistants are mostly not narrowly defined as multimodal AI, one of the most popular applications is diabetes care assistants. Verily (Alphabet)’s Virta Health, Accolade, and Onduo have developed applications aimed at diabetes control, some of which indicate improvements in hemoglobin A1c levels for individuals following these programs. Many of these companies have already expanded or are expanding into other application scenarios, such as hypertension and obesity. Virtual health assistants can also be applied to common diseases like migraines, asthma, and chronic obstructive pulmonary disease (COPD). Unfortunately, most of these applications have only undergone small-scale observational testing and still require in-depth studies, including randomized clinical trials, to assess their benefits.
Looking ahead, integrating multiple data sources into AI models will promote the development of widely anticipated personalized virtual health assistants. Virtual health assistants can utilize personalized profiles based on genomic sequencing, other omics, continuously monitored blood biomarkers and metabolites, biosensors, and other relevant biomedical data—to improve patient behavior, respond to health inquiry questions, classify symptoms, or communicate with healthcare personnel in a timely manner. However, it is crucial that these virtual health assistants demonstrate positive impacts on clinical outcomes through randomized trials to gain broader recognition in the medical field. Since most of these applications focus on providing healthier behavior options, they need to provide evidence that these options can influence health, which is the ultimate pathway for the successful translation of most interventions.
To fully realize the potential of virtual health assistants powered by integrated multimodal data AI, we have a long way to go, including the technical, data, and privacy challenges that will be discussed below. Given the rapid development of conversational AI and the increasingly sophisticated multimodal learning methods, we look forward to the future of digital health applications integrating with AI to provide precise and personalized health guidance.
Collecting Multimodal Data
The primary requirement for developing data-driven multimodal applications is to collect and organize phenotypic and annotated datasets, as no complex technology can extract information without data. Over the past 20 years, many international studies have collected multimodal data to promote precision medicine (see Table 1). In the UK, the UK Biobank opened registration in 2006, eventually enrolling over 500,000 participants, with plans to track participants for at least 30 years after registration. This large biobank collects diverse data from participants, including sociodemographic information, lifestyle, physical measurements, biological samples, 12-lead electrocardiograms, and EHR data. Additionally, nearly all participants underwent genome-wide array genotyping, and recent expansions include proteomics, whole exome sequencing, and whole genome sequencing (WGS). Some participants also underwent brain MRI, cardiac MRI, abdominal MRI, carotid ultrasound, and dual-energy X-ray absorptiometry, including repeated imaging at least two time points.
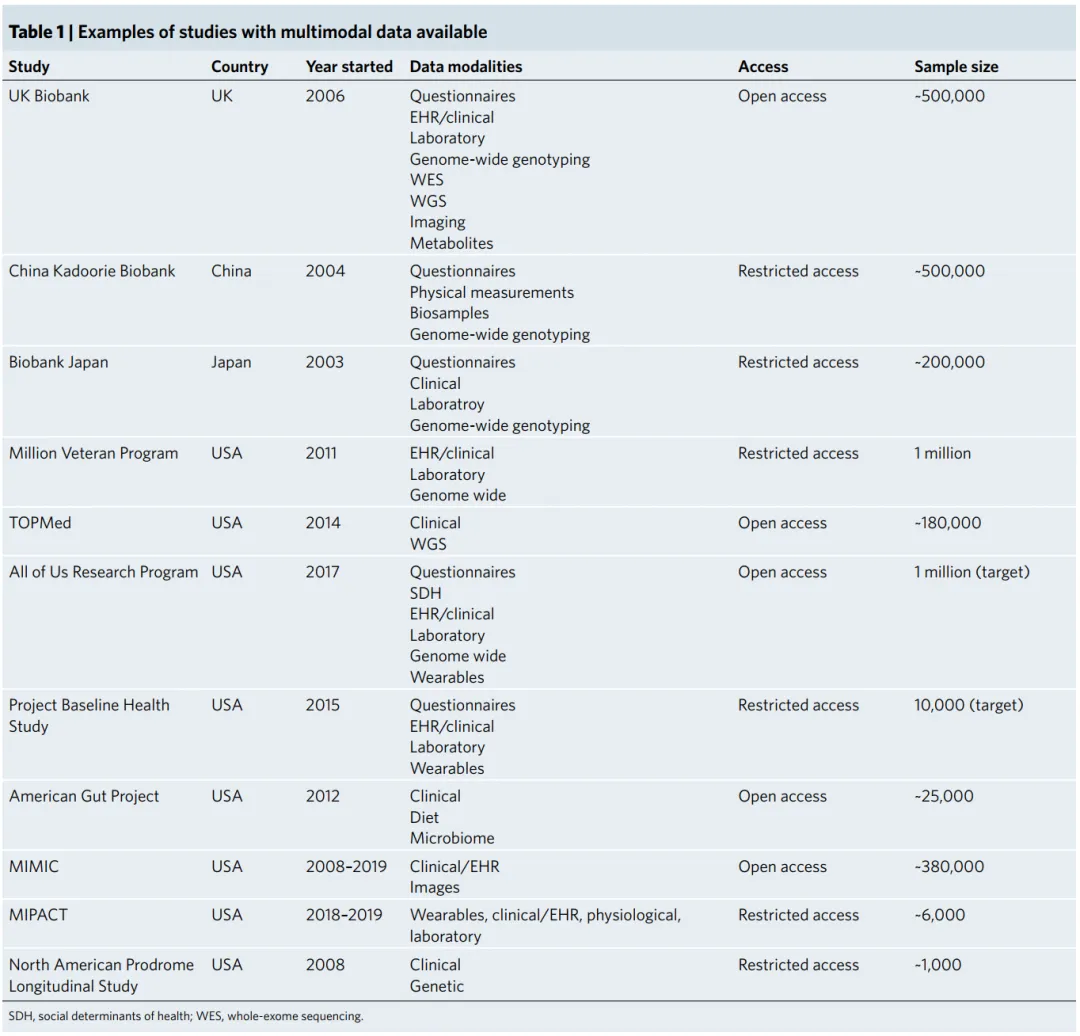
Table 1: Examples of studies with multimodal data available.
Other countries have also conducted similar research, such as the Kadoorie Biobank in China and Biobank Japan. In the US, the Department of Veterans Affairs launched the Million Veteran Program in 2011, aiming to recruit one million veterans to contribute to scientific discoveries. Two significant projects funded by the National Institutes of Health (NIH) include the Trans-Omics for Precision Medicine (TOPMed) program and the All of Us Research program. TOPMed collects WGS and integrates this genetic information with other omics data. The All of Us research program is another novel and ambitious initiative by the NIH, which has recruited approximately 400,000 diverse participants in the US and plans to recruit one million. This project primarily recruits volunteers from groups widely defined as underrepresented in biomedical research, which is particularly important in medical AI.
In addition to these large national projects, various institutions have established in-depth multimodal data resources within minority groups. The Project Baseline Health study, funded by Verily and managed in collaboration with Stanford University, Duke University, and the California Institute for Health and Longevity, aims to recruit at least 10,000 individuals (initially launched with 2,500 participants) and collect extensive multimodal data, ultimately evolving into a comprehensive virtual in-person study. Another example is the American Gut Project, which collects microbiome data from self-selected participants in several countries. The Medical Information Mart for Intensive Care (MIMIC) database organized by MIT is another example of multidimensional data collection and integration, now in its fourth version. MIMIC is an open-source database containing de-identified data from thousands of patients in the intensive care unit at Beth Israel Deaconess Medical Center, including demographic information, EHR data (such as diagnoses, medication use, hospitalization details, and laboratory data), and physiological data (e.g., blood pressure or intracranial pressure values), and in some versions, natural language text such as radiology reports and medical records. This level of data granularity is highly beneficial for the development of data science and machine learning, and MIMIC has become one of the benchmark datasets for AI models aimed at predicting clinical events like kidney failure and outcomes such as survival and readmission.
These multimodal datasets may contribute to better diagnostic performance across a range of different tasks. For example, recent work has shown that combining imaging data and EHR data outperforms using either data alone in identifying pulmonary embolism and distinguishing common causes of acute respiratory failure (such as heart failure, pneumonia, or COPD). The Michigan Health Prediction Activity and Clinical Trajectory (MIPACT) study constitutes another example, where participants provided data from wearable devices, physiological data (blood pressure), clinical information (EHR and surveys), and laboratory data. The North American Prodrome Longitudinal Study is another example. This multicenter initiative recruited many subjects and collected demographic, clinical information, and blood biomarker data to understand prodromal symptoms of psychosis. Other studies focusing on mental health have also collected various types of data and contributed to the development of multimodal machine learning workflows.
Technical Challenges
01 Implementation and Modeling Challenges
Health data is inherently multimodal. Our health status is influenced by many complex social, biological, and environmental factors. Moreover, these factors are hierarchical, with data abstracting from macro-level (e.g., presence or absence of disease) to deep micro-level (e.g., biomarkers, proteomics, and genomics). Additionally, the current healthcare system adds multimodal data: although conditions are recorded in EHR in natural language and tabular data, the system can match radiology imaging data and pathology images with natural language data from their respective reports.
Multimodal machine learning (also known as multimodal learning) is a subfield of machine learning centered on the development and training of models that can leverage multiple different types of data and learn how to associate or combine these multimodal data to improve predictive performance. A promising approach is to learn accurate representations that are similar across different modalities (e.g., an image of an apple can similarly be represented by the word “apple”). In early 2021, OpenAI released an architecture called Contrastive Language Image Pretraining (CLIP), which, trained on millions of “image-text pairs,” achieved competitive performance with fully supervised models without fine-tuning parameters. CLIP was inspired by a similar method developed in the medical imaging field called Contrastive Visual Representation Learning from Text (ConVIRT). Using ConVIRT, image encoders and text encoders are trained to generate image and text representations by maximizing the similarity of correctly paired image-text examples and minimizing the similarity of mispaired examples—this is known as contrastive learning. This approach for paired image-text co-learning has recently been applied to train models for chest X-rays and their associated text reports, outperforming other self-supervised and fully supervised methods. Other architectures integrating multimodal data from images, audio, and text have also been developed and published, such as the Video-Audio-Text Transformer, which uses video to obtain paired multimodal images, text, and audio and trains accurate multimodal representations that can effectively generalize across many tasks—such as recognizing actions in videos, classifying audio events, classifying images, and selecting the most appropriate video for input text.
Another ideal characteristic of multimodal learning frameworks is the ability to learn features of different modalities within the same framework. Ideally, a unified multimodal model would incorporate different types of data (such as images, biosensor data, and structured and unstructured text data) to flexibly and sparsely encode information from these different types of data (i.e., specific tasks corresponding to specific modules), register similar concepts across modalities, such as the image of a dog and the word “dog” should have similar internal representations within the model, and provide outputs of any modality as needed.
In recent years, there has been a shift from architectures with strong modality-specific biases, such as convolutional neural networks (CNNs) for image analysis or recurrent neural networks (RNNs) for text and physiological signals, to the emergence of transformer architectures, which have excelled in various fields with multiple input-output modalities. The key innovation of transformers lies in their ability to dynamically assess the importance of each module (i.e., introducing an attention mechanism to dynamically weight judgments based on Q, K, V matrices). Transformers were originally proposed for natural language processing, thus providing a method to predict the context of each word by focusing on other words in the input sentence, and this architecture has now successfully expanded to other modalities.
In natural language processing, each input token, the smallest unit being processed, corresponds to a specific word, while other modalities typically use segments of images or video clips as input tokens. The transformer architecture allows us to integrate multimodal learning but may still rely on specific tokenization and encoding methods for each modality. A recent study by Meta AI (Meta Platforms) proposed a unified self-supervised learning framework in which the modalities of attention are independent but still require preprocessing and training based on specific modalities. Self-supervised multimodal learning benchmarks allow us to measure progress across multimodal methods: for example, the recently proposed Domain-Agnostic Benchmark for Self-supervised learning (DABS) includes chest X-rays, sensor data, natural images, and text data.
Recent advancements by DeepMind (Alphabet), including Perceiver and Perceiver IO, propose a cross-modal learning framework with the same backbone architecture. Importantly, the input of the Perceiver architecture is modality-agnostic byte arrays, compressing input information through attention mechanism bottlenecks to avoid memory consumption, i.e., limiting the architectural features of the information flow to byte arrays, forcing the model to select the most relevant factors in the data (Figure 2a). After processing the input data, the Perceiver can feed the representations to the final classification layer to obtain probabilities for each output category, while Perceiver IO can decode this information into outputs of specified modalities, such as pixel files, raw audio, and classification labels by specifying query vectors (which represent query vectors in transformer models, similar to keywords input in search engines). For example, in addition to predicting the probability of cure, the model can also predict the imaging data for the onset of brain tumors.

Figure 2: Simplified illustration of the novel technical concepts in multimodal AI.
Another prospect of the transformer framework is its ability to use unlabelled data, which is crucial in biomedical AI because the resources needed to obtain high-quality annotations are limited and expensive. Many of the aforementioned methods require paired (aligned) data from different modalities, such as image-text pairs. A study by DeepMind indicated that managing higher-quality image-text datasets may be more important than generating large single-modality datasets and developing and training algorithms. However, these paired data may not be easily obtainable in biomedical AI. One solution to this problem is to leverage data from one modality to assist learning with another modality—this is a form of multimodal learning known as “co-learning.” For instance, some studies have shown that transformer models pretrained on unlabelled language data can generalize well to many other tasks. In the medical field, an architecture called “CycleGANs” has been used to generate synthetic non-contrast or contrast CT scan data through training on unpaired contrast and non-contrast CT scans, which has improved diagnosis of COVID-19. While promising, this approach has yet to be widely tested in biomedical contexts and requires further exploration.
Another significant challenge in modeling relates to the high dimensionality of multimodal health data, collectively referred to as “the curse of dimensionality.” As the dimensionality (i.e., the number of variables or features contained in the dataset) increases, the number of individuals carrying certain specific combinations of these features decreases or even disappears, leading to the creation of “dataset blind spots”—unobserved feature spaces (the set of all possible combinations of features or variables). These dataset blind spots may degrade the predictive performance of models in applications, and thus dimensionality selection should be an early consideration in the model development and evaluation process. Currently, several strategies can mitigate the high dimensionality issue, as detailed in other articles. In brief, these include collecting data in the highest-performing manner (e.g., using motor-controlled fast tapping instead of finger sampling, rather than passively collecting data during daily activities), ensuring the sample size is large and diverse (i.e., matching the expected conditions when the model is clinically deployed), using domain prior knowledge to guide feature engineering and selection (focusing on the reproducibility of features), appropriate model training and regularization, rigorous model validation, and comprehensive model monitoring (including monitoring differences between training set data and data distributions discovered post-deployment). Looking ahead, developing models that can integrate prior knowledge (e.g., known gene regulatory pathways and protein interactions) may be another promising approach to overcoming the curse of dimensionality. Recent research along these lines has shown that enhancing model performance by retrieving information from large databases outperforms training large models on large datasets, as the former effectively utilizes existing information and gains additional benefits such as model interpretability.
Increasingly, methods used in multimodal learning involve fusing data from different modalities instead of simply inputting several modal data into models separately to improve predictive performance—this process is called “multimodal fusion.” The fusion of different data modalities can occur at different stages. The simplest method is to associate the features of the input data before any processing, known as early fusion. While this method is straightforward, it is not suitable for many complex data modalities. A more sophisticated approach is to combine the features of these different modalities during the training process, allowing for the capture of cross-modal features after specific modality preprocessing, known as joint fusion. Finally, another method involves training separate models for each modality and combining the output probabilities, known as late fusion. This is a simple and robust method, but at the cost of losing all cross-modal information. Early fusion work has focused on introducing time series models, utilizing information from structured covariates to accomplish tasks such as predicting the progression of osteoarthritis and predicting surgical outcomes in patients with cerebral palsy. As another example of fusion, researchers at DeepMind used a high-dimensional EHR dataset with 620,000 dimensions, projecting it into a continuous embedding space of only 800 dimensions within a 6-hour timeframe to parse patient information and establish an RNN model to predict acute kidney injury over time. Many studies can now use bimodal fusion to enhance predictive performance. For instance, fusing imaging data and EHR-based data to improve the detection of pulmonary embolism has shown to outperform single-modal models. Another bimodal study fused imaging features from chest X-rays with clinical information, improving the diagnostic performance of tuberculosis in HIV patients. There have also been reports of combining optical coherence tomography and infrared reflectance disc imaging to predict visual field maps.
Multimodal fusion is a general concept that can be implemented using any architecture. While we can draw from some AI imaging work outside the biomedical field; modern guided image generation models such as DALL-E and GLIDE often input information from different modalities into the same encoder. This method was recently proven successful in research conducted by DeepMind using Gato, which demonstrated that connecting various labels (tokens) created from text, images, and buttons can enable the model to learn to perform various tasks, ranging from captioning images and playing Atari games to stacking blocks with robotic arms (Figure 2b). Importantly, a recent study called Align Before Fuse indicated that performing registration before fusing multimodal data may yield better performance in downstream tasks, such as creating text descriptions for images. A recent study by Google Research proposed using attention bottlenecks for multimodal fusion, thereby restricting the flow of information across modalities to force the model to share the most relevant information across modalities, thereby enhancing computational performance.
Another example of bimodal analysis is “translating” data. In many cases, data from one modality may be closely related to clinical outcomes but is expensive to obtain, difficult to access, or requires specialized equipment for measurement or invasive procedures. Deep learning computer vision algorithms currently show that information previously requiring higher precision from manual annotations can be captured. For instance, a convolutional neural network study used echocardiogram videos to predict laboratory measurements, such as cardiac biomarkers (troponin I and brain natriuretic peptide) and other common biomarkers. Results indicated that the model predicted outcomes accurately compared to traditional laboratory tests and even outperformed conventional methods in prognosing heart failure hospitalization. Deep learning has also been widely studied in cancer pathology, where models need only input pathology images and have surpassed the interpretative capabilities of pathologists regarding H&E staining, with various applications such as predicting genotypes and gene expression, feedback on treatments, and survival outcomes.
Multimodal model architectures also face significant challenges in other areas. For instance, for three-dimensional imaging data, even using a model with only a single time point requires high computational capacity, thus presenting challenges for implementing large-scale omics and text data models for large-scale parallel computing. Despite the rapid development of multimodal learning in the past few years, we predict that existing methods are insufficient to overcome all the aforementioned challenges. Therefore, continuous innovation will be necessary to utilize efficient multimodal AI models in the future.
02 Data Challenges
There are still widespread challenges in the collection, linking, and annotation of multidimensional baseline health data. Medical datasets can be described from multiple dimensions, including sample size, sequencing depth, follow-up time and intervals, the degree of interaction between subjects, the heterogeneity and diversity of samples, the level of standardization and integration of data, and the correlation between data sources. Despite significant advancements in data collection and phenotypic analysis with technological progress, trade-offs inevitably exist between the characteristics of biomedical datasets. For instance, in most cases, hundreds of thousands or even millions of samples are needed to train AI models (especially multimodal AI models), but the depth sequencing and long-term longitudinal analysis associated with such a large number of samples rapidly increase costs. Unless automated data collection methods are adopted, maintaining funding becomes challenging.
For example, the Observational Health Data Sciences and Informatics collaboration has made significant efforts in integrating biomedical datasets through the Observational Medical Outcomes Partnership Common Data Model.
Data integration greatly facilitates research advancements in related fields, enhances data reproducibility, and promotes data translation to clinical settings. However, data integration may obscure certain pathophysiological processes of diseases. For example, ischemic stroke subtypes are often not accurately identified, but using raw data from EHR or radiology reports allows for phenotypic analysis through natural language processing. Similarly, the DSM (Diagnostic and Statistical Manual of Mental Disorders) classifies diagnoses based on clinical presentations, which may not fully capture the underlying pathophysiological processes.
Achieving diversity across race/ethnicity, ancestry, income level, education level, healthcare access, age, disability status, geographic location, gender, and sexual orientation has proven nearly unachievable. Genomic studies are a notable example, as the vast majority of research focuses on individuals of European ancestry. However, the diversity of biomedical datasets is critical, as this ensures the datasets have generalizability to broader populations. Beyond these considerations, a necessary step for multimodal AI is appropriately linking all data types within the dataset, leading to another challenge of increasing risks of individual identity recognition and regulatory difficulties.
Another common issue with biomedical data is that the proportion of missing data is often high. While in some cases, it may be sufficient to exclude patients with missing data before training, selection bias may occur, which is often better addressed with statistical tools to handle these missing values, such as multiple imputation. Thus, imputation is a common preprocessing step across various biomedical sciences, from genomics to clinical data. Imputation has significantly enhanced the statistical power of genome-wide association studies (GWAS) to identify new genetic risk loci and has been facilitated by large reference datasets with deep genotype coverage (such as 1000Genomes, UK10K, Haplotype Reference Consortium, and the recently emerging TOPMed). Besides genomics, imputation is also useful for other types of medical data. Many different strategies have been employed to reduce the number of assumptions. These include carry-forward imputation, marking imputed values at the last measurement and adding information, and more complex methods, such as using learnable decay terms to obtain missing data and time intervals.
When conducting studies collecting health data, it is essential to emphasize the risk of generating biases and employ various methods to observe and mitigate these biases. The risk of these biases amplifies when combining data from multiple sources, as it is more likely that individual biases of each data modality will be accepted and amplified when merging data from populations with these potential biases. This complex and unresolved issue is more critical in multimodal health data compared to single-modal data, necessitating in-depth study. Medical AI algorithms using demographic features such as race as input data may learn and iterate biases present in historical data, causing harm when deploying models. Importantly, recent work has shown that AI models can identify these features solely from imaging data, highlighting the necessity of consciously detecting racial biases and balancing racial outcomes during data quality control and model development processes. Notably, reports have indicated that selection bias is a common type of bias in large biobanks, and this issue has been prevalent in COVID-19 work as well. For example, patients using allergy medications are more likely to undergo COVID-19 testing, artificially lowering positive detection rates, and creating a notable protective effect among those tested due to selection bias. Importantly, selection bias can lead to significant differences between the training samples of AI models and the general population, thereby affecting model inference.
03 Privacy Challenges
The successful development of multimodal AI in healthcare relies on the breadth and depth of data, which presents higher privacy challenges than single-modal AI models. For instance, previous studies have shown that attackers can re-identify individuals in large datasets (e.g., Netflix prize dataset) using only a small amount of background information from participants to uncover sensitive information about individuals.
In the United States, the Health Insurance Portability and Accountability Act (HIPAA) privacy rule is the fundamental legislation protecting the privacy of health data. However, certain types of health data—such as user-generated and de-identified health data—are not covered by this regulation, which can pose re-identification risks by combining information from multiple sources. In contrast, the European Union’s recently enacted General Data Protection Regulation (GDPR) has a broader definition of health data, extending beyond data protection to require disclosure of information related to automated decision-making using such data.
Given these challenges, various technical solutions have been proposed and explored to ensure the security and privacy of training multimodal AI models, including differential privacy, federated learning, homomorphic encryption, and swarm learning. Differential privacy proposes systematically adding random perturbations to the data, with the ultimate goal of obfuscating individual-level information while maintaining the global distribution of the dataset. As expected, this approach achieves a trade-off between privacy protection and model performance. On the other hand, federated learning allows multiple individual researchers or health institutions to collaboratively train models without transmitting raw data. In this approach, a trusted central server distributes models to each endpoint; then, each endpoint performs a certain number of iterations of training on the model and shares the model updates back to the trusted central server. Finally, the trusted central server integrates model updates from all endpoints and begins a new round of training. Multimodal federated learning has been implemented in multi-institutional collaborations to predict clinical outcomes for COVID-19 patients. Homomorphic encryption is a cryptographic technique that allows mathematical operations to be performed on encrypted input data, enabling the sharing of model weights without disclosing information. Finally, swarm learning is a relatively novel approach that, similar to federated learning, trains models on local data across several endpoints but uses blockchain smart contracts instead of a trusted central server.
Importantly, these methods are often complementary, and they can and should be used together. A recent study demonstrated the performance potential of combining federated learning with homomorphic encryption to train models predicting COVID-19 diagnoses from chest CT scans, outperforming all locally trained models. While these methods show promise, multimodal health data is typically distributed across several different organizations, from healthcare institutions and academic centers to pharmaceutical companies. Therefore, developing new methods to incentivize interdepartmental data sharing while protecting patient privacy is essential.
By leveraging recent developments in edge computing, an additional layer of safety can be obtained. Unlike cloud computing, edge computing refers to bringing computation closer to the data source (e.g., near environmental sensors or wearable devices). Combined with other methods such as federated learning, edge computing offers enhanced security by avoiding the transmission of sensitive data to centralized servers. Additionally, edge computing provides other advantages, such as reduced storage costs, latency, and bandwidth usage. For instance, some X-ray systems now run optimized versions of deep learning models directly on their hardware instead of transmitting images to cloud servers for identifying potentially life-threatening features.
As the healthcare AI market expands, the value of biomedical data is increasing, leading to another challenge related to data ownership. To date, this has constituted a public debate issue. Some voices advocate for patients to have private ownership of their data, arguing that this approach would ensure patient autonomy, support health data trading, and maximize the benefits patients gain from data markets; while others suggest viewing this data as “non-property” and better protecting the security and transparent use of data through regulation. Beyond this, appropriate incentive measures should be established to promote data sharing while ensuring data security and privacy.

Conclusion
With the ability to capture multidimensional biomedical data, we face the challenge of deep phenotyping—understanding the uniqueness of each individual. Collaboration across industries and sectors is needed to collect and link large amounts of diverse multimodal health data (see Box 1). However, today, we are better at organizing and storing data than analyzing it. To meaningfully process these high-dimensional data and realize these exciting uses, medical experts and AI experts need to focus on building and validating new models and ultimately proving their utility in improving health.