

This article is approximately 4200 words long, and it is recommended to read it in 8 minutes
Pre-trained language models such as BERT and GPT-3 have been proven to achieve excellent results in the NLP field. With the gradual maturity of research in the multimodal field over the past two years, more and more researchers are focusing on multimodal pre-trained large models, such as the initial ViLBERT and later CLIP proposed by OpenAI, as well as the recent OFA which can support various modal tasks in a unified paradigm, all of which have achieved quite good results in various downstream tasks.
However, there are many challenges in applying cutting-edge open-source large models in the industry, such as language mismatches, low domain fit, and task discrepancies. Today’s topic is the exploration of lightweight adaptation techniques for multimodal pre-trained models.
Today’s presentation will revolve around the following four points:
-
Current Status and Application Challenges of Multimodal Large Models
-
Language Adaptation of Multimodal Large Models
-
Domain Adaptation of Multimodal Large Models
-
Optimization Goal Adaptation of Multimodal Large Models
-
Application Cases
01 Current Status and Application Challenges of Multimodal Large Models
First, let me share the current status and application challenges of multimodal large models with everyone.
In recent years, open-source multimodal pre-trained large models have achieved good results in various downstream tasks, prompting the industry to start trying to apply these large models to their own business scenarios. Taking CLIP as an example, various variants of the model have emerged for different downstream scenarios, allowing CLIP to be applicable to specific tasks.
Currently, there are three main challenges in applying cutting-edge open-source multimodal pre-trained large models in the industry:
-
Language mismatch between open-source large models and application tasks, making direct application impossible;
-
Low domain fit between open-source large models and application tasks (for example, general large models are difficult to apply directly to downstream tasks such as e-commerce), making it hard to achieve significant effects;
-
Differences in optimization goals between open-source large models and application tasks, requiring a lot of downstream labeled data.

In response to the above three issues, the following content will also be divided into three major propositions to introduce the adaptation techniques of open-source multimodal pre-trained large models:
-
Language adaptation techniques for open-source large models, addressing the inconsistency in language between large models and application scenarios;
-
Domain adaptation techniques for open-source large models, addressing the low domain fit between large models and application scenarios;
-
Optimization goal adaptation techniques for open-source large models, addressing the differences in optimization goals between large models and application tasks.
02 Language Adaptation of Multimodal Large Models
Let me first share the language adaptation techniques of multimodal large models.

Multimodal large models in academia, such as CLIP and OFA, are primarily designed for English scenarios, making them difficult to apply directly to Chinese business contexts. Currently, there are two solutions to this problem: using multilingual multimodal large models; pre-training large models based on multimodal data in the target language. For example, M3P is a typical multilingual multimodal large model, while Huawei’s Wukong is a multimodal large model based on a large-scale Chinese corpus. However, these solutions have high training costs and are difficult to continuously follow academic progress in large models, which in turn limits their effective utilization in business scenarios.
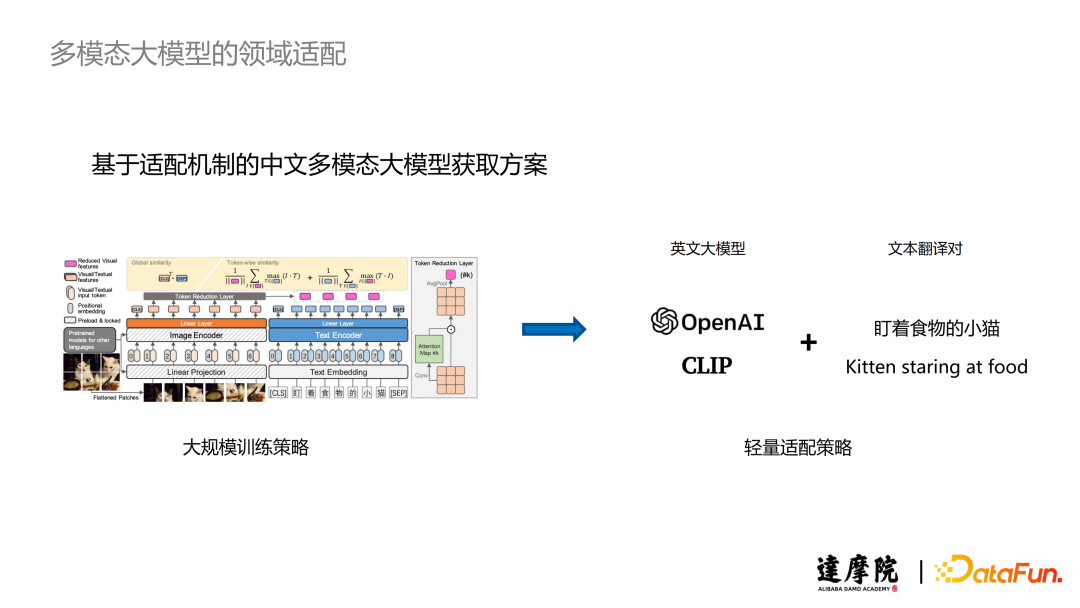
Our goal is to find a lightweight adaptation scheme to address the language mismatch problem of multimodal large models. Previous large-scale training strategies did not leverage the decoupling nature of vision and language, so we can focus on adapting only the text during the training process. For instance, when using CLIP, we can utilize a pair of Chinese and English text translations to obtain a CLIP model that can be directly used in Chinese scenarios.

Based on this idea, we designed a language adaptation link based on the Adapter mechanism. We focus on two points: first, we only need to adapt the text side, avoiding additional training on the visual side; second, the Adapter mechanism allows us to avoid the training inadequacy caused by a small amount of data, improving training efficiency.
Specifically, we replace an English Encoder with a Chinese Encoder so that its output vector can remain as consistent as possible with the output vector of the English Encoder, minimizing performance loss during the subsequent Fusion through Cross-model Transformer and alignment with visual Embedding.
In summary, our training goal is to minimize the distance between the two vectors. During the training process, we did not choose to re-pretrain a language model but instead used a pre-trained Chinese BERT and a learnable Adapter, mapping the output vector of Chinese BERT into the representation space of the English Encoder through the Adapter. This approach effectively avoids the training inadequacy issues caused by a small amount of data and significantly shortens training time due to the relatively small number of parameters in the Adapter. The network structure of the Adapter consists of stacked Transformer Layers and two Down and Up mapping layers. For parameter efficiency, the Transformer Layer is generally set to 1 or 2 layers during the experiment.
We designed accuracy loss experiments to validate the effectiveness of our proposed scheme. We adopted a Zero-Shot approach, conducting experiments on the original CLIP model using both a small amount of carefully translated English data and the original Chinese data on the CLIP and CLIP model + Chinese Adapter. The experimental results showed that if we used carefully translated data, the accuracy of the CLIP model could reach 56%, while using the original Chinese data, the accuracy of CLIP was only 18%. This indicates that the CLIP model indeed cannot handle Chinese data.
Moreover, after using the adapted Chinese version of CLIP, the model’s Zero-Shot accuracy reached 55%, indicating that our lightweight adaptation scheme has an extremely limited impact on accuracy, thereby proving that the Adapter adaptation scheme can enable multimodal large-scale pre-trained models to be applied in real business scenarios.
Furthermore, we used multiple cross-language multimodal large models in academia to conduct Zero-Shot experiments on the COCO-CN Text2img retrieval benchmark. The mR metric of M3P reached 32.3, Wukong’s mR metric reached 72.2, while the mR metric of the CLIP model adapted for Chinese using the Adapter reached 73.5, surpassing the Wukong model trained specifically on Chinese datasets. Undoubtedly, the excellent performance of the Adapter scheme is partly due to the high-quality pre-training of the CLIP model, but after applying the Adapter mechanism, the performance of CLIP in Chinese scenarios does not significantly decline, which proves the effectiveness of the Adapter mechanism.
03 Domain Adaptation of Multimodal Large Models
This section will share the work results we have achieved in the domain adaptation of multimodal large models.

Currently, multimodal large models are mainly trained in general domains, which can lead to limited benefits in specific business scenarios (such as e-commerce, customer service scenarios, etc.). This issue has been studied in academia for some time, and the main solution is to collect large-scale data based on specific domains for model training, resulting in a domain-specific pre-trained large model, represented by Alibaba’s FashionBERT. However, this method has very high data collection and training costs. In e-commerce scenarios, we may be able to collect enough data for large model training, but in some niche scenarios, collecting millions or tens of millions of data points is quite challenging.
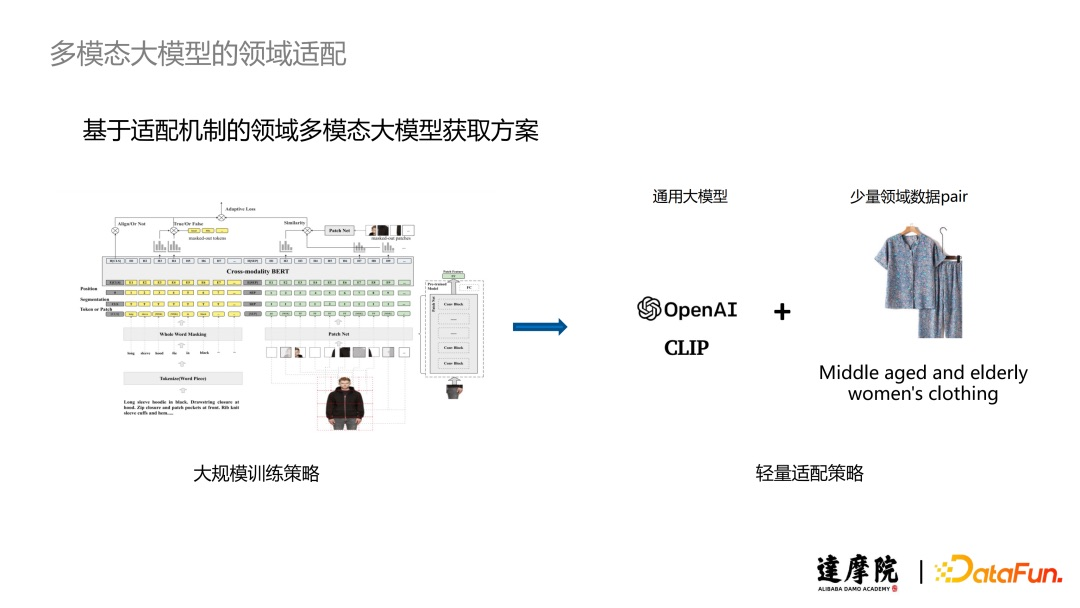
With the previous experience in language adaptation, we considered whether we could find a lightweight adaptation scheme to transfer multimodal large models from general domains to specific domains. In our view, although the knowledge learned by our large models in general domains may not directly meet the needs of specific business scenarios, this general knowledge can effectively help us learn specific domain knowledge more quickly. Based on this idea, we chose to use a general large model along with a small amount of domain data to obtain a domain-specific large model.
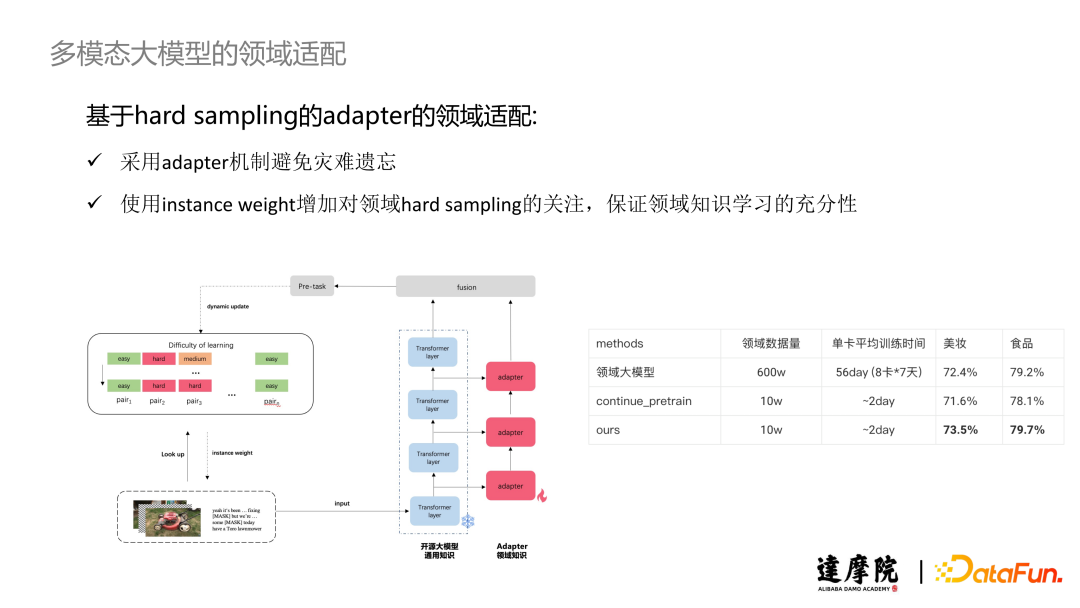
We proposed a domain adaptation link based on Hard Sampling for the Adapter. In this scheme, we adopted the idea from the language adaptation scheme, using the Adapter mechanism to avoid catastrophic forgetting issues. Additionally, we considered whether a data pair is a Hard Sample during data sampling, using Instance Weight to increase attention to domain Hard Sampling, ensuring that samples that are difficult for the model to predict correctly are sufficiently trained, thereby guaranteeing the adequacy of domain knowledge learning. The above diagram shows the model structure with the Adapter mechanism added, where the Transformer Layer can be seen as responsible for representing general knowledge (parameters Frozen), while the Adapter is responsible for learning domain knowledge, obtaining a comprehensive vector representation through the combination of both. Additionally, we designed a structure similar to a Memory Bank to record the difficulty level of each data pair; if this Pair is easily distinguishable by the open-source large model, we consider it a “simple” Pair; otherwise, we classify it as a more difficult Pair. During training, we will assign higher sampling weights to the more difficult Pairs.
In comparative experiments, we compared our approach with two baselines: using a large amount of domain data for end-to-end pre-training of the large model and using continuous learning for training the large model. For the former, we used 6 million domain data points, utilizing 8 GPUs for 7 days (56 days on a single GPU), achieving accuracies of 72.4% and 79.2% in the beauty and food domains, respectively; for the latter, we used 100,000 domain data points, with a single GPU training time of about two days, achieving accuracies of 71.6% and 78.1% in the beauty and food domains, respectively, showing a certain performance decline compared to the domain large model. This phenomenon is caused by the catastrophic forgetting issues in continuous learning and the inadequacy of domain knowledge learning present in small data training. Utilizing our proposed Hard Sampling-based Adapter domain adaptation mechanism, with the same 100,000 small sample data, after approximately 2 days of training on a single GPU, we achieved accuracies of 73.5% and 79.7% in the beauty and food domains, respectively, surpassing the performance of the domain large model trained with 6 million data points. This is attributed to: the Hard Sampling mechanism ensuring sufficient learning of domain knowledge; effectively utilizing general knowledge, combining general and domain knowledge can bring a certain degree of performance gain.
04 Optimization Goal Adaptation of Multimodal Large Models
Finally, let me share the experiences and results we have obtained in the direction of optimization goal adaptation for multimodal large models.

Prompt Learning is widely used in the NLP field, primarily addressing the inconsistency between the optimization goals of downstream tasks and those of large model pre-training. For example, in text classification tasks, if we directly use the pre-trained MLM, we cannot maximize the utilization of the knowledge in the large model, making it difficult to achieve optimal results in text classification, especially in small sample scenarios. Prompt Learning utilizes prompts to transform text classification tasks into generative task forms, aligning tasks with the optimization goals of language model pre-training. In small sample NLP tasks, Prompt Learning shows significant benefits.
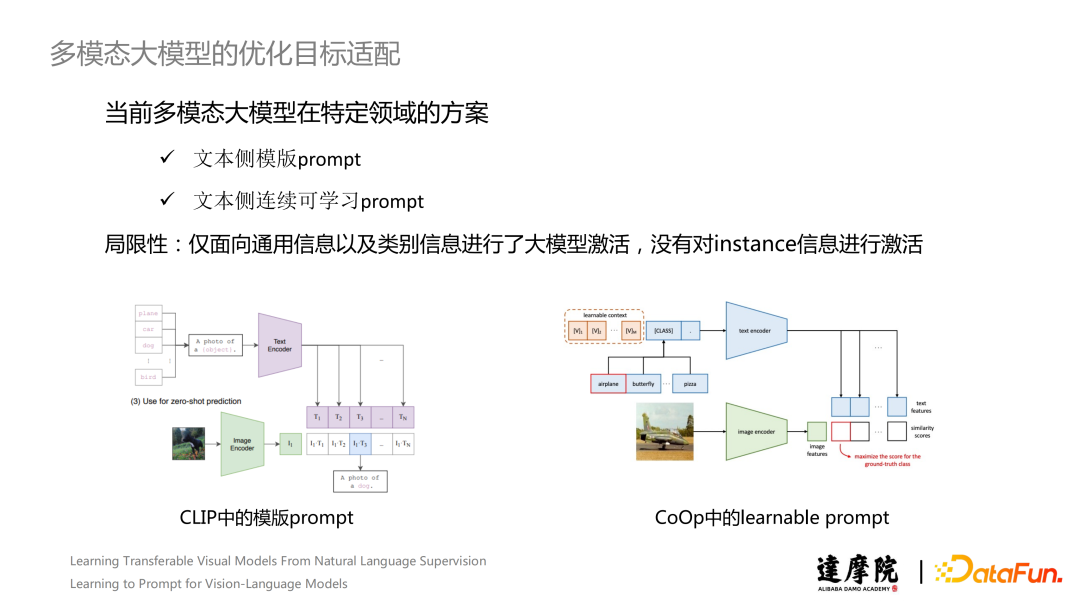
In multimodal large models, there are also works that use the Prompt Learning mechanism for optimization goal adaptation. For example, in the original CLIP paper, the authors added prompts to the Text Encoder to better adapt the downstream classification tasks to the cross-modal alignment tasks during pre-training. Currently, there are two conventional Prompt Learning schemes: text-side template prompts and text-side continuous learnable prompts. The intention behind learnable prompts is to address the time-consuming tuning of discrete prompts, which exhibit significant variability in results and lack flexibility, making it difficult to achieve satisfactory outcomes. However, both methods have certain limitations. These two methods only activate general information and category information in the large model, without considering the activation of Instance information.
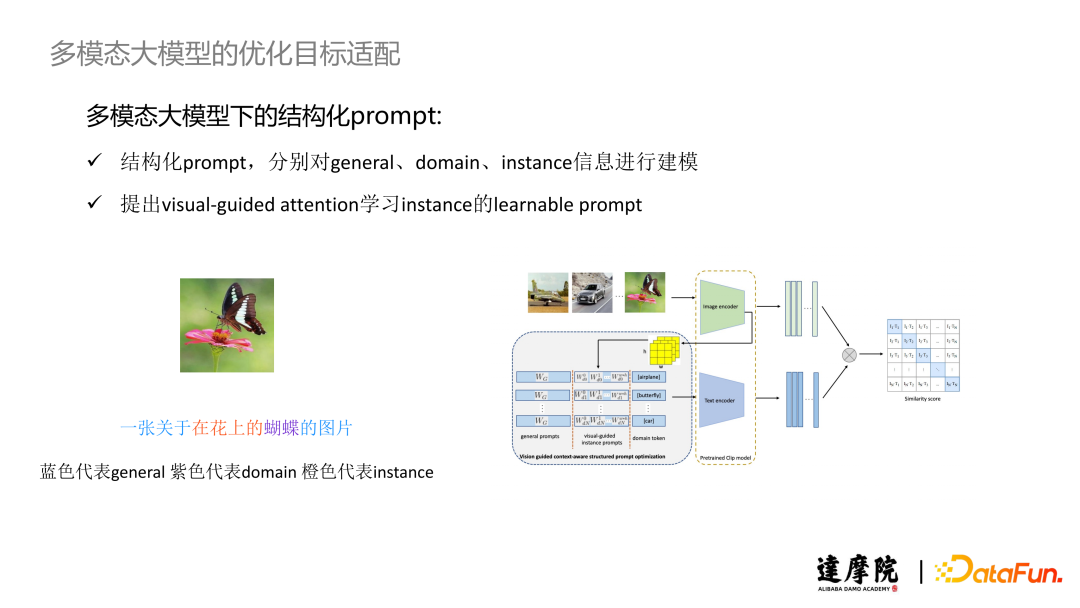
Considering the above issues, we proposed structured prompts, modeling General, Domain, and Instance information separately. For example, the left side of the above image shows a butterfly, where “an image of…” represents General information, “butterfly” represents Domain information, and “on a flower” represents Instance information. Additionally, we use a Visual-Guided Attention mechanism to learn the Instance’s learnable prompt. The right side of the above image shows our model structure, where the first column is the General Prompt, the second column is the Instance Prompt learned through Visual-Guided Attention mechanism, and the third column is the Domain Prompt.
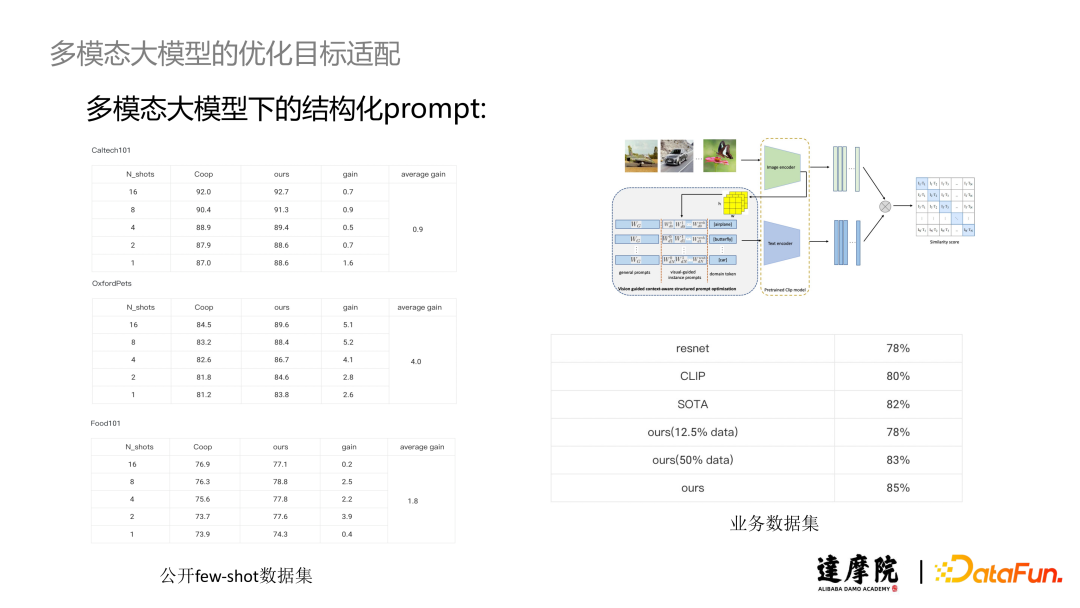
To validate the effectiveness of our proposed structured prompts, we first conducted experiments on small sample data in image classification. The experimental results showed that in different classification scenarios, whether using 1 Shot or N shot training, our scheme consistently outperformed Coop. We also applied the structured prompt scheme to actual business scenarios. We achieved the same accuracy as Resnet using only 12.5% of the data, and using only 50% of the data allowed us to achieve or even surpass SOTA performance, while with full data, we achieved an accuracy exceeding SOTA methods by 3 percentage points.
05 Q&A Session
Q1: How many parameters does the adapter used in the domain adaptation mechanism have?
A1:The parameter count of the Adapter is not large; we typically only use 1-2 layers of Transformer Layers along with two linear layers, and the parameters of the large multimodal pre-trained model used in the model are all frozen.
Q2: How do you differentiate between Domain and Instance information?
A2:Domain information mainly corresponds to category labels in image classification tasks, such as the butterfly shown in the example; “on a flower” is Instance information, as not all images containing butterflies have the visual attribute of “on a flower,” which we regard as Instance-specific information.
Q3: Can the Adapter mechanism be used in the life sciences field?
A3:I believe a reason why the language and domain adaptation schemes can succeed is that the general knowledge contained in large pre-trained models can be transferred and utilized across different languages and domains. If the underlying knowledge contained in large pre-trained models in the life sciences field has generality across different domains, then the Adapter mechanism may be applicable.
Editor: Wang Jing
Proofreader: Wang Xin
