Click the card below to follow the “CVer” public account
Click the card below to follow the “CVer” public account
AI/CV heavy content delivered first-hand
Click to enter —>【Mamba and diffusion model】 WeChat group
AI/CV heavy content delivered first-hand
Click to enter —>【Mamba and diffusion model】 WeChat group
Add WeChat: CVer5555, the assistant will add you to the group!
Scan the QR code below to join the CVer academic community! You can get the latest top conference/top journal paper ideas and resources from beginner to expert in CV, as well as cutting-edge applications! Publishing papers/research/increasing salary, highly recommended!


Paper Title: Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Open Source Code: https://github.com/HaozheLiu-ST/T-GATE
Affiliation: King Abdullah University of Science and Technology (KAUST), National University of Singapore (NUS), IDSIA

The paper discusses the role of the cross-attention (Cross-Attention) module in the inference process of text-conditioned diffusion models. The study finds that during the denoising step of the diffusion model’s inference, the output of the cross-attention module converges to a fixed point. Therefore, the entire inference process can be divided into two stages: 1. The initial semantic planning stage, where the model designs visual semantic information based on text information; 2. The subsequent image fidelity enhancement stage, where the model generates high-quality images based on the semantic information designed in the first stage. Surprisingly, in the second stage of inference, ignoring the given text condition not only reduces the computational complexity of the model but also slightly lowers the FID score. Based on this phenomenon, the research team proposed a simple and training-free efficient generation inference method, TGATE, which caches the output after the cross-attention module converges and replaces the cross-attention module in the remaining inference steps.
1. Motivation
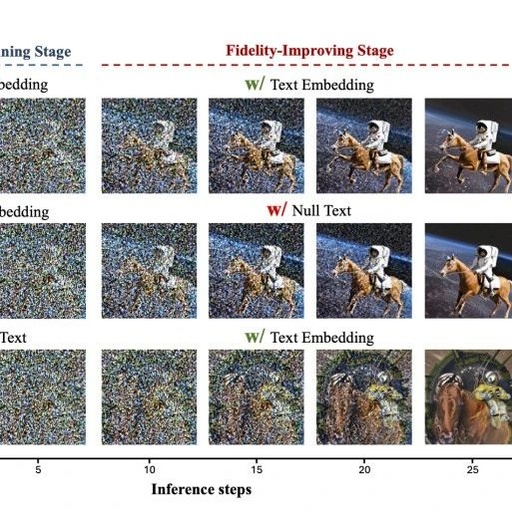
Diffusion models have been widely used for image generation. They use cross-attention (Cross-Attention) to align different modality data, such as text information for conditional generation tasks. Some studies emphasize the importance of cross-attention for spatial control, but few have investigated its role in the denoising process from a temporal perspective. Additionally, the scaled dot-product in the cross-attention module has a computational complexity of $O(n^2)$. As image resolution and token length continue to increase in modern models, the cross-attention module incurs extremely high computational costs and becomes a significant source of latency in end devices like mobile phones. This prompts the research team to reevaluate the role of the cross-attention module. This paper explores a new question: “Is cross-attention critical at every step during inference in text-to-image diffusion models?” The summary of the research on this question is as follows: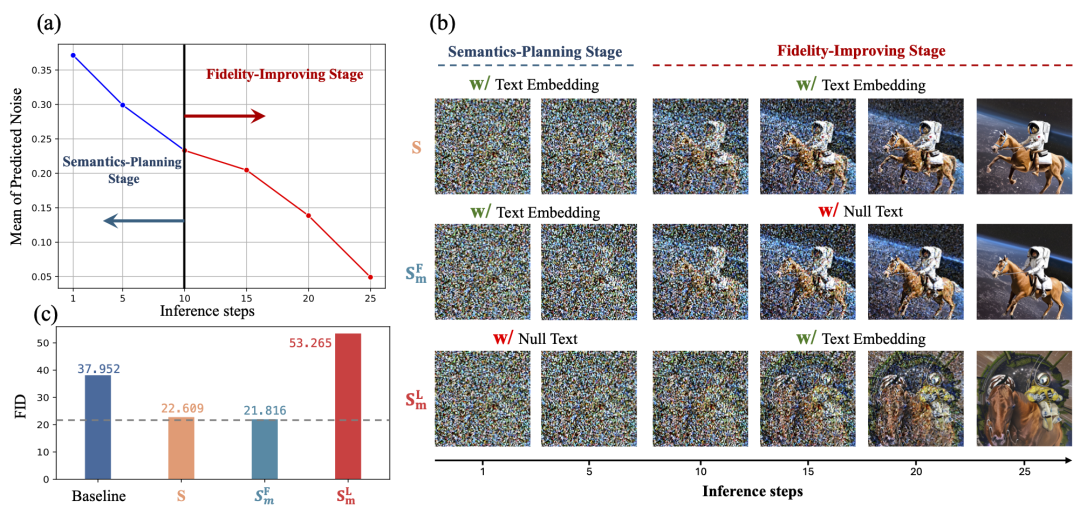
-
The cross-attention module converges early during inference. The convergence time point (time step) divides the denoising process of the diffusion model into two stages: i) the initial stage, where the model relies on the cross-attention module to design text-oriented visual semantics; this is referred to as the semantic planning stage, and ii) the subsequent stage, where the model learns to generate images from the previous semantic planning, i.e., the image fidelity enhancement stage.
-
In the image fidelity enhancement stage, the cross-attention module is redundant. In the semantic planning stage, cross-attention plays an important role in creating meaningful semantics. However, in the second stage, the cross-attention module has already converged, and its output has little impact on the generation process. In fact, bypassing the cross-attention module during the image fidelity enhancement stage not only reduces computational costs but also maintains high image generation quality.
2. Contributions
The research team designed a simple, effective, and training-free method called Time-Gated Cross-Attention (TGATE) to improve model inference efficiency while maintaining the generation quality of existing diffusion models. This method caches the output of the cross-attention module after convergence and replaces the cross-attention module in the remaining inference steps. The main contributions are as follows:
-
TGATE improves efficiency by caching and reusing the results of cross-attention after convergence, eliminating redundant cross-attention. Generating an image can reduce 65T MACs and decrease the parameter count of the inference model by 0.5B, resulting in approximately 50% less image generation time compared to the baseline model SD-XL.
-
TGATE does not lead to performance degradation, as the cross-attention module is converged and redundant. In some cases, the FID metrics for generated images are even slightly lower than those of the baseline model.
-
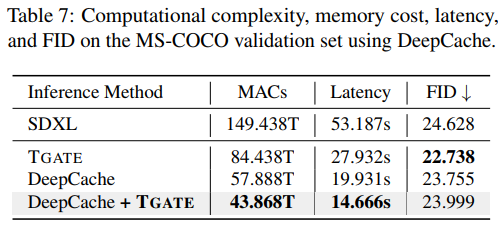
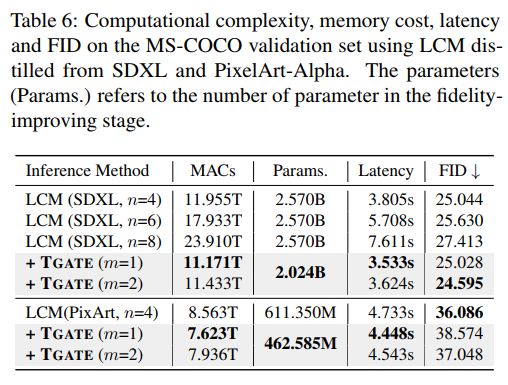
TGATE supports diffusion models based on CNN U-Net, Transformer models, and Consistency Models. It can also be combined with other optimization algorithms such as DeepCache for faster model inference.
3. Experimental Evaluation
The paper validates the proposed TGATE method on mainstream pre-trained diffusion models, including SD-1.5, SD-2.1, SD-XL, and PixArt-Alpha, using four metrics: Multiple-Accumulate Operations (MACs), parameter count (parameters), inference time (latency), and zero-shot FID on the MS-COCO-10k dataset. The experimental results are as follows:
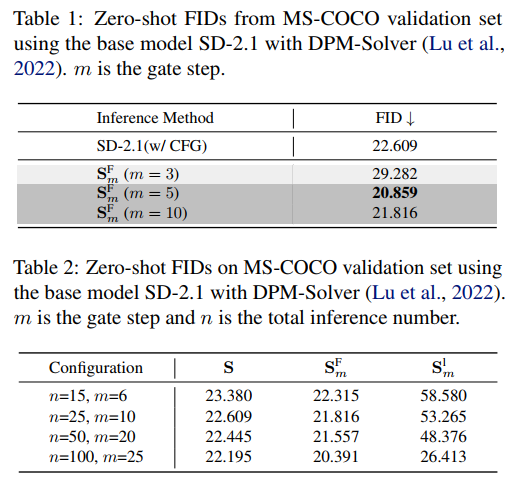
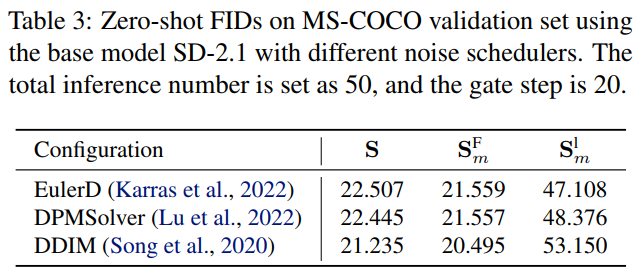
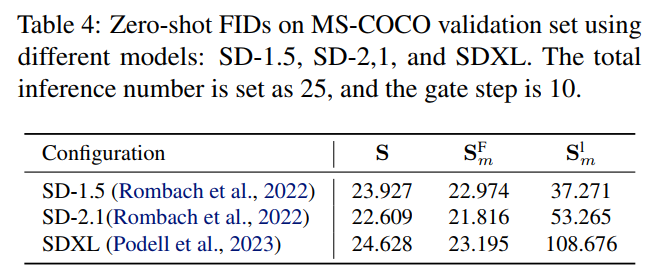
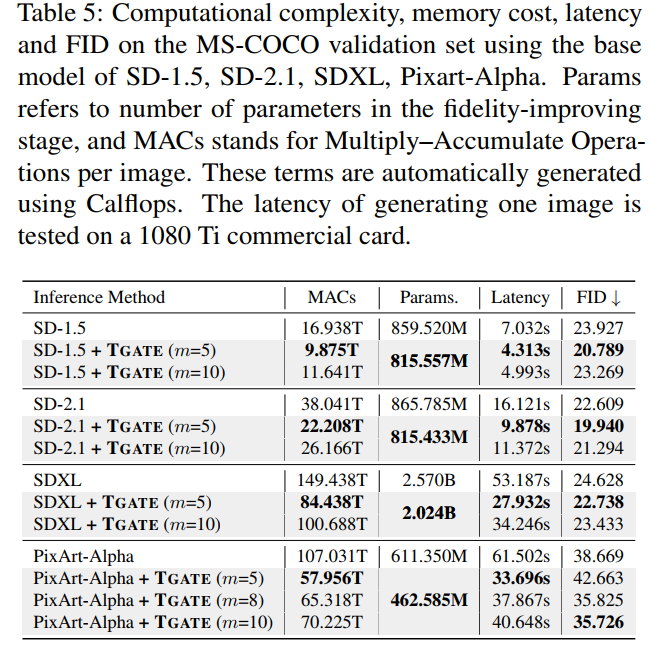
This paper also validates against existing diffusion model acceleration methods DeepCache and Latent Consistency Model.
4. Visualization Results
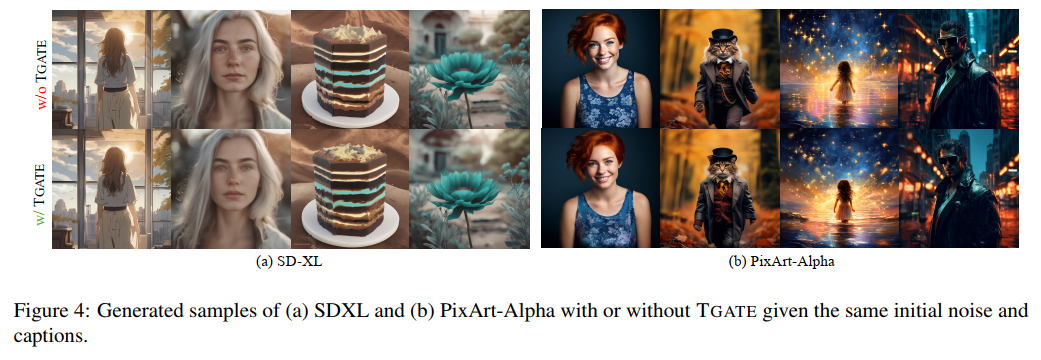

Download the PPT slides from He Kaiming’s MIT course
Download the PPT slides from He Kaiming’s MIT course
Reply "He Kaiming" in the CVer public account backend to download all 566 pages of this course's PPT! Hurry up and start learning!
CVPR 2024 Paper and Code Download
CVPR 2024 Paper and Code Download
Reply "CVPR2024" in the CVer public account backend to download the collection of CVPR 2024 papers and open-source codesMamba and diffusion model communication group established
Scan the QR code below, or add WeChat: CVer5555, to add the CVer assistant on WeChat, to apply to join the CVer-Mamba and diffusion model WeChat group. Other vertical fields covered include: object detection, image segmentation, object tracking, face detection & recognition, OCR, pose estimation, super-resolution, SLAM, medical imaging, Re-ID, GAN, NAS, depth estimation, autonomous driving, reinforcement learning, lane line detection, model pruning & compression, denoising, dehazing, deraining, style transfer, remote sensing images, action recognition, video understanding, image fusion, image retrieval, paper submission & communication, PyTorch, TensorFlow, and Transformer, NeRF, 3DGS, Mamba, etc.
Please note: research direction + location + school/company + nickname (e.g., Mamba or diffusion model + Shanghai + SJTU + Kaka), according to this format note, it can be processed faster and invited to join the group
▲ Scan or add WeChat: CVer5555 to join the group
CVer Computer Vision (Knowledge Planet) is here! If you want to learn about the latest, fastest, and best CV/DL/AI paper delivery, quality practical projects, AI industry frontiers, and study materials from beginner to expert, please scan the QR code below to join CVer Computer Vision (Knowledge Planet), which has gathered nearly ten thousand people!
▲ Scan to join the planet to learn
▲ Click the card above to follow the CVer public account
Organizing is not easy, please like and share
▲ Scan or add WeChat: CVer5555 to join the group
CVer Computer Vision (Knowledge Planet) is here! If you want to learn about the latest, fastest, and best CV/DL/AI paper delivery, quality practical projects, AI industry frontiers, and study materials from beginner to expert, please scan the QR code below to join CVer Computer Vision (Knowledge Planet), which has gathered nearly ten thousand people!
▲ Scan to join the planet to learn
▲ Click the card above to follow the CVer public account
Organizing is not easy, please like and share