

New Intelligence Report
New Intelligence Report
[New Intelligence Guide] GAN models also have the potential to scale up!
The explosion of AIGC is, from a technical perspective, due to a huge change in the architecture of image generation models.
With OpenAI’s release of DALL-E 2, autoregressive and diffusion models overnight became the new standard for large-scale generative models, while before that, generative adversarial networks (GANs) had always been the mainstream choice, giving rise to technologies like StyleGAN.

The switch from GAN to diffusion model architecture also raises a question: Can we enhance performance by scaling up GAN models, for example, by further improving performance on large datasets like LAION?
Recently, addressing the instability issues that arise from increasing the capacity of the StyleGAN architecture, researchers from POSTECH (Korea), Carnegie Mellon University, and Adobe Research proposed a novel generative adversarial network architecture called GigaGAN, breaking the scale limitations of the model and demonstrating that GANs can still excel as text-to-image synthesis models.

Paper link: https://arxiv.org/abs/2303.05511
Project link: https://mingukkang.github.io/GigaGAN/
GigaGAN has three major advantages.
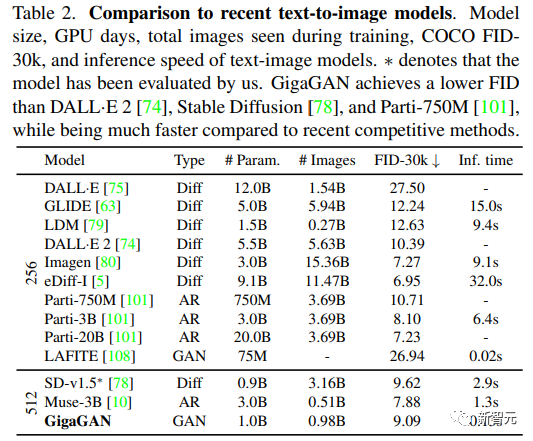
1. It is faster during inference, with image generation speed at 0.13 seconds for 512 resolution, reduced from 2.9 seconds compared to Stable Diffusion-v1.5 with the same number of parameters.
2. It can synthesize high-resolution images, for example, synthesizing 16 million pixel images within 3.66 seconds.

3. It supports various latent space editing applications, such as latent interpolation, style mixing, and vector arithmetic operations.

Is GAN at its limits?
Is GAN at its limits?
A series of recently released models, such as DALL-E 2, Imagen, Parti, and Stable Diffusion, have ushered in a new era of image generation, achieving unprecedented levels of image quality and model flexibility.
The currently dominant paradigms of “diffusion models” and “autoregressive models” rely on iterative inference, a double-edged sword, as iterative methods allow for stable training with simple objectives but incur higher computational costs during inference.
In contrast, generative adversarial networks (GANs) can generate images with just one forward pass, making them inherently more efficient.
While GAN models dominated the “previous era” of generative modeling, scaling up GANs requires careful tuning of network structures and training considerations due to instability during training. Therefore, while GANs excel at modeling single or multiple object categories, scaling to complex datasets (let alone open-world object generation) remains challenging.
Thus, current large-scale models, data, and computational resources are primarily concentrated on diffusion and autoregressive models.
In this work, researchers primarily address the following questions:
Can GANs continue to scale and potentially benefit from these resources? Or have GANs reached their limits? What hinders further scaling of GANs? Can these obstacles be overcome?
Stabilizing GAN Training
Stabilizing GAN Training
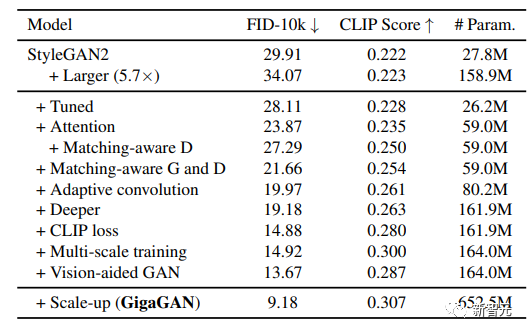
Researchers first experimented with StyleGAN2, observing that simply scaling up the backbone led to unstable training. After identifying several key issues, they proposed techniques to stabilize training while increasing model capacity.
Firstly, by retaining a bank of filters, they effectively expanded the generator’s capacity by taking a linear combination of specific samples.
Several techniques commonly used in the context of diffusion models were adapted and confirmed to yield similar performance improvements for GANs, such as interleaving self-attention mechanisms (image-only) and cross-attention (image-text) with convolutional layers to enhance performance.
Moreover, the researchers reintroduced multi-scale training, finding a new scheme that improves image-text alignment and low-frequency details of generated outputs.
Multi-scale training allows GAN-based generators to utilize parameters in low-resolution blocks more effectively, leading to better image-text alignment and image quality.
Generator
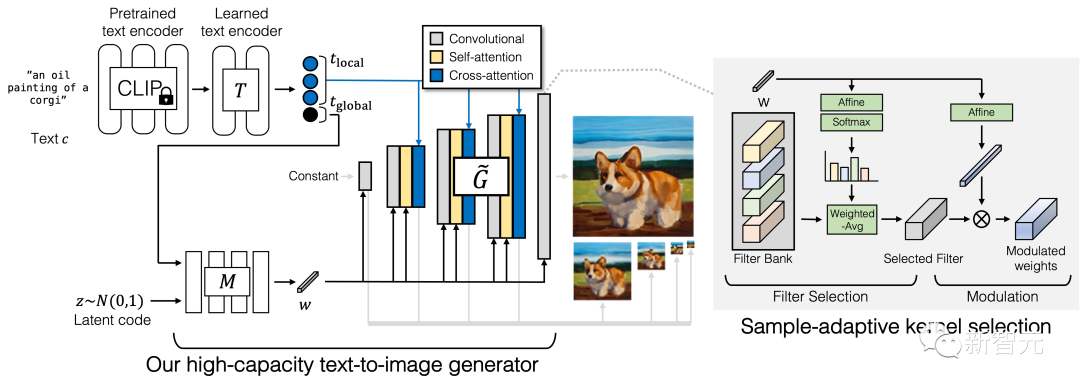
The GigaGAN generator consists of a text encoding branch, style mapping network, and multi-scale synthesis network, supplemented by stable attention and adaptive kernel selection.
In the text encoding branch, a pre-trained CLIP model and a learned attention layer T are first used to extract text embeddings, which are then passed to the style mapping network M to generate style vectors w similar to StyleGAN.
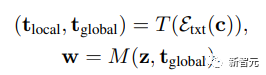
The synthesis network uses style encoding as modulation and text embeddings as attention to generate an image pyramid, and introduces a sample adaptive kernel selection algorithm to achieve convolution kernel selection based on input text conditions.
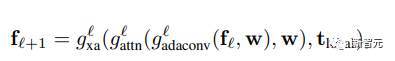
Discriminator
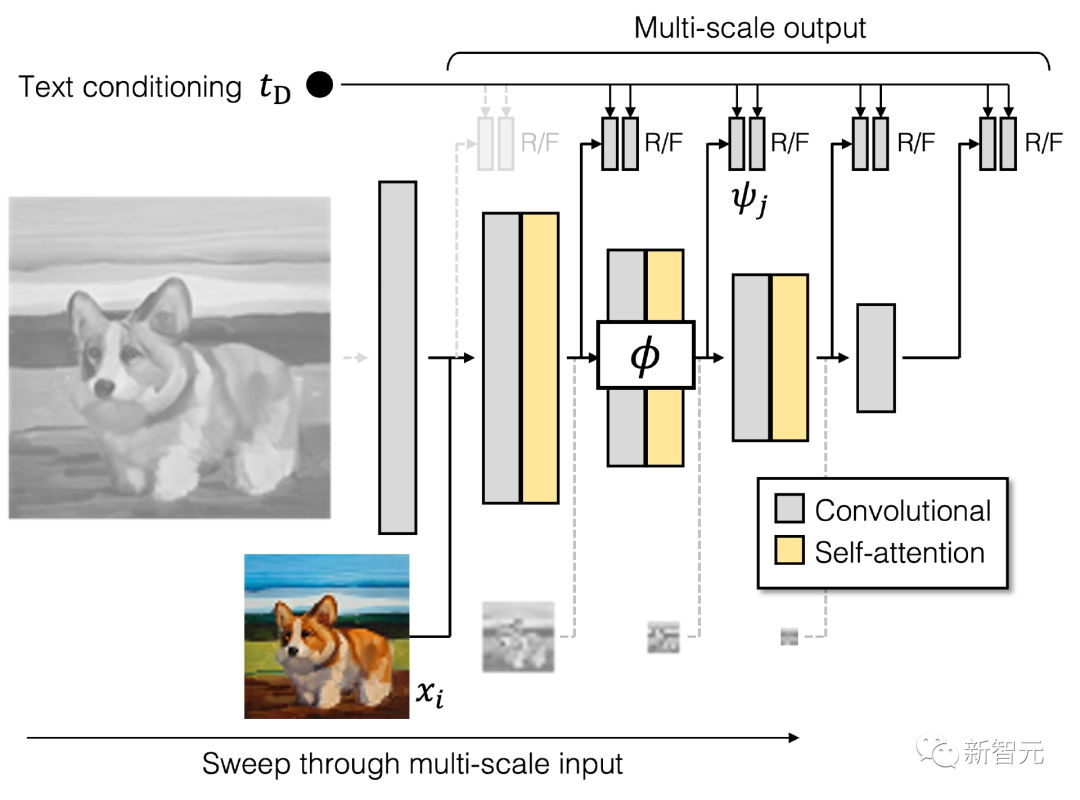
Similar to the generator, GigaGAN’s discriminator consists of two branches, one for processing image conditions and the other for text conditions.
The text branch processes similarly to the generator’s text branch; the image branch receives an image pyramid as input and makes independent predictions for each image scale.
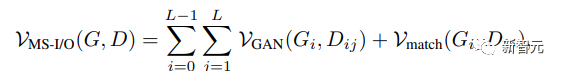
Multiple additional loss functions were introduced in the equations to promote rapid convergence.
Experimental Results
Experimental Results
Systematic and controlled evaluation of large-scale text-image synthesis tasks is difficult, as most existing models are not publicly available. Even if training code is available, the cost of training a new model from scratch can be prohibitively high.
Researchers chose to compare with Imagen, Latent Diffusion Models (LDM), Stable Diffusion, and Parti in their experiments, while acknowledging significant differences in training datasets, iteration counts, batch sizes, and model sizes.
For quantitative evaluation metrics, Frechet Inception Distance (FID) was primarily used to measure the authenticity of output distributions, and CLIP scores were used to evaluate image-text alignment.
Five different experiments were conducted in the paper:
1. Demonstrating the effectiveness of the proposed method by gradually incorporating each technical component;
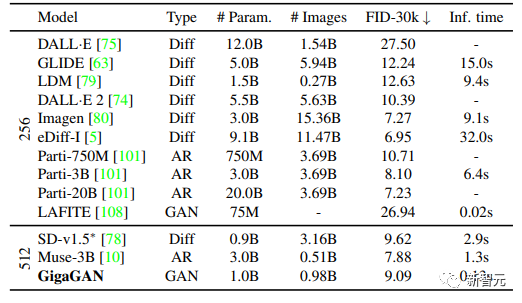
2. Text-image synthesis results show that GigaGAN exhibits comparable FID to Stable Diffusion (SD-v1.5), while the generated results are hundreds of times faster than diffusion or autoregressive models;
3. Comparing GigaGAN with distilled diffusion models, showing that GigaGAN can synthesize higher quality images faster than distilled diffusion models;
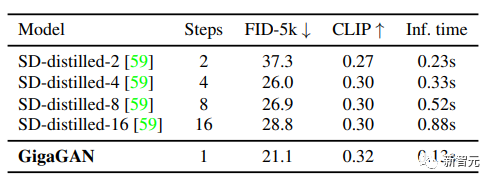
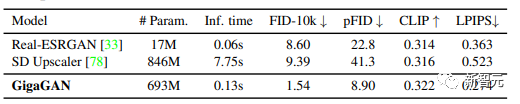
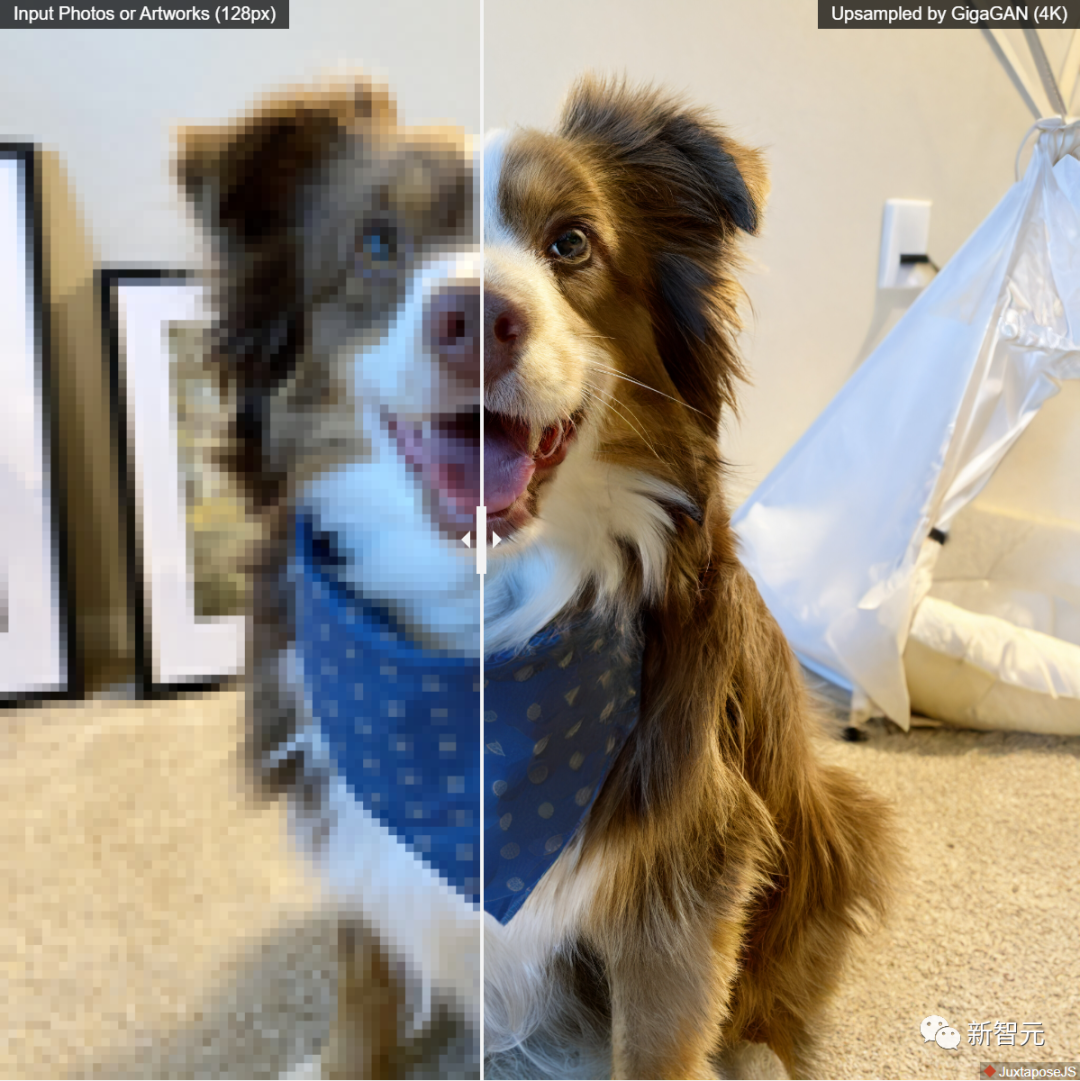
4. Validating the advantages of GigaGAN’s upsampler in conditional and unconditional super-resolution tasks compared to other upsamplers;
5. Results indicate that large-scale GANs still enjoy the operational benefits of GANs’ continuous and decomposed latent spaces, enabling new image editing modes.
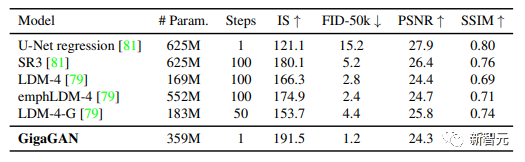
After parameter tuning, researchers achieved stable and scalable training of the billion-parameter GAN (GigaGAN) on large datasets like LAION2B-en.
The method adopts a multi-stage approach, generating first at 64×64 and then upsampling to 512×512. Both networks are modular and powerful enough to be used in a plug-and-play manner.
The results indicate that although diffusion model images were never seen during training, the GAN upsampling network conditioned on text can serve as an efficient and high-quality upsampler for foundational diffusion models (like DALL-E 2).

These results combined make GigaGAN far exceed previous GAN models, 36 times larger than StyleGAN2 and 6 times larger than StyleGAN-XL and XMC-GAN.
Although GigaGAN’s 1 billion parameter count is still lower than the recently released largest synthesis models, such as Imagen (3B), DALL-E 2 (5.5B), and Parti (20B), no saturation in quality related to model size has been observed so far.
GigaGAN achieved a zero-shot FID of 9.09 on the COCO2014 dataset, lower than DALL-E 2, Parti-750M, and Stable Diffusion’s FID.
Application Scenarios
Application Scenarios
Prompt Interpolation
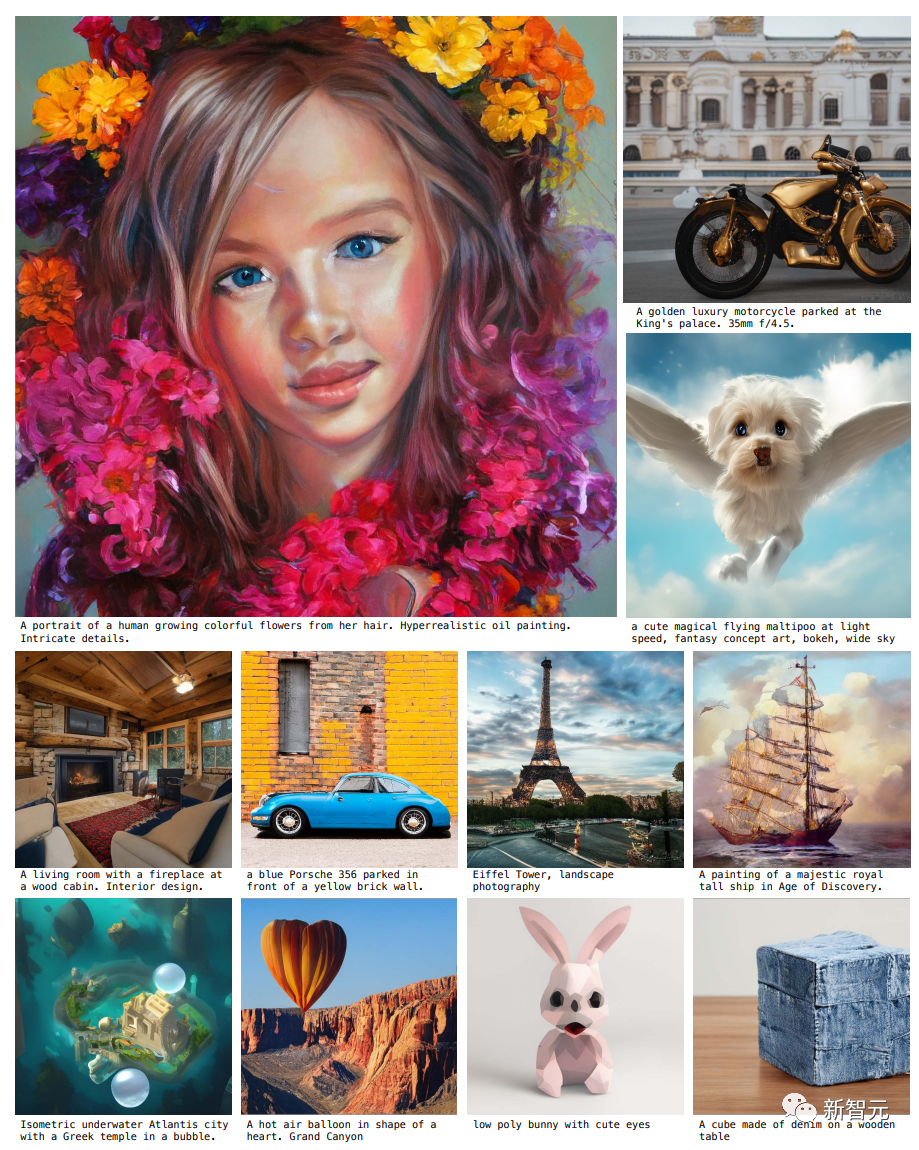
GigaGAN can smoothly interpolate between prompts, with the four corners of the image below generated from the same latent code but with different text prompts.

Disentangled Prompt Mixing
GigaGAN retains a separated latent space, allowing for the combination of a sample’s coarse style with another sample’s fine style, and GigaGAN can directly control styles through text prompts.

Coarse-to-Fine Style Swapping
The GAN-based model architecture retains a separated latent space, allowing for the mixing of a sample’s coarse style with another sample’s fine style.


