
“
Happy New Year! This article should be the last piece in the collection of algorithm insights regarding RAG. Throughout the past year, most of my work has focused on some aspects of large model applications, and I would like to briefly discuss two points that left a significant impression on me regarding RAG system models.
The previous article [Evolution Guide for Large Model Retrieval-Augmented Generation (RAG) Systems] (you can access it from the collection at the end of this article) shared some thoughts on RAG systems, focusing on discussing potential issues that may arise after a RAG system goes live, as well as some simple optimization ideas related to retrieval.
This article mainly discusses thoughts on the RAG system model, presenting a somewhat one-sided view, without involving any technical skills; it is all random musings. (It’s crucial to stay safe; these days, writing content is really not easy. Just the other day, someone privately messaged me criticizing the recall, saying that langchain is recognized as a garbage framework in their company. I was really baffled~)
There Is a Critical Point Between RAG Systems and Large Models
More than a year has passed since the release of ChatGPT, and many versions of GPT-4 have come out, with the latest version supporting a context length of up to 128k. After extensive testing by numerous users, its knowledge retrieval capability has proven to be outstanding. Since mid-year, the entire open-source community has made rapid progress in length extrapolation, moving from linear interpolation to a series of extrapolation schemes that allow large models to support longer lengths without fine-tuning; later, low-cost extrapolation fine-tuning strategies like longlora emerged; subsequently, the difficulty of fine-tuning ultra-long texts is no longer in the GPU memory, thanks to open-source solutions like flash attention v2 and 8bit adamw that can significantly reduce the memory requirements for long text fine-tuning. How to effectively fine-tune long text data has become a new challenge.
In some practical RAG scenarios, many issues are simply information retrieval problems, such as “What is the net profit of Moutai in Q3?” or “What is the buy rating for Moutai?” When not considering recall misses, the model’s knowledge retrieval capability is put to the test. Based on the question, it is crucial to find the correct answer from the retrieved candidate segments and organize it into an easily understandable output for the frontend.
This year, my work related to RAG has involved not only knowledge base Q&A but also Q&A for cloud documents. In the early stages, trying to use the RAG system to respond to questions like “What did the second part discuss?” was quite painful, as it was impossible to retrieve the content of “the second part” using a simple recall strategy.
If a large model can purely solve the problem, there is no need to resort to slice recall methods. We can use some strategies to evaluate the model’s knowledge retrieval capabilities and find the critical point in between. Of course, having an excellent foundational model is also crucial. Many open-source models claim to support long context lengths, but their knowledge retrieval capabilities are often abysmal.
Conclusion: If you haven’t started building a RAG system yet, you may need to think carefully about whether you really need a RAG system. Is it absolutely necessary? Although RAG has numerous advantages, many times the ideal is beautiful, but the reality is harsh. If you already have a complete RAG system, is there a possibility of combining RAG with a pure large model?
Is Recall Dominating the Large Model or Is the Large Model Dominating Recall?
A typical case of recall dominating the large model is the common single-turn format, where suitable knowledge segments are searched based on user queries, and then the large model makes decisions to generate the final answer. This approach is indeed very simple to set up; you just need to import the data into Elasticsearch, choose a large model, and you can complete the simplest system construction. Overall, it is equivalent to letting the large model complete the last mile of the Q&A task, preparing everything for the model to summarize or extract tasks.
In the case of the large model dominating recall, it started with OpenAI’s WebGPT, followed by Meta’s Toolformer, and many subsequent works have discussed this topic. Essentially, the large model decides when to call tools (recall), what the retrieval query is, and the entire system’s focus has shifted to the large model. Q&A can also be understood as an agent system. For example, a simple case is: “What is the area difference between East Lake in Wuhan and West Lake in Hangzhou?” The model will appropriately decide to retrieve “the area of East Lake in Wuhan,” “the area of West Lake in Hangzhou,” and the [calculator] tool to arrive at the final answer.
In Q1 and Q2 of this year, we developed self-researched 7B and 13B models as foundational models. The main issue with these larger models is that they are not very obedient; you cannot expect them to completely follow your prompt instructions. Therefore, appropriate instruction fine-tuning is very important for the 7B model, essentially acting as a strong prompt constraint to produce outputs according to the constraints. The advantage of this size of model is that it can be easily deployed on a single 4090 card (we purchased dozens of 8-card 4090s at the beginning of the year, which are cost-effective for deploying models). Through appropriate fine-tuning and alignment strategies, we can achieve satisfactory results in summarization and extraction tasks.
Later, as we learned from users abroad, they began to experiment with even larger models, such as 30B and 70B, continuing to pre-train a Chinese 30B Llama. With larger models, reasoning capabilities easily emerge. I still have a picture of the results from the first test case, as shown below (the image cannot be displayed, text is pasted below):
Q: What was the total operating income of AVIC Xi'an Aircraft Industry Group in 2020?
Ignore the candidate segments retrieved.
LLM: According to knowledge segment 1, the employee compensation/total operating income of AVIC Xi'an in 2020 was 18.6%. This means that the total operating income of AVIC Xi'an in 2020 was the employee compensation divided by 18.6%.
The employee compensation provided in Figure 25 is 6.22 billion yuan, so the total operating income of AVIC Xi'an in 2020 is:
6.22 billion yuan / 18.6% = 33.44 billion yuan.
Therefore, the total operating income of AVIC Xi'an in 2020 is 33.44 billion yuan.
In fact, the retrieved segments do not correspond to the total operating income, but the model can calculate the result using some segments and chart information. This reasoning ability is difficult for 7B and 13B models to achieve. The 30B model can be deployed through quantization to int4 on a 4090 (which is somewhat challenging as there is not much space left for the KV cache), or on multiple cards through tensor parallelism and pipeline parallelism, which is not too big of an issue. Fortunately, the Chinese open-source community has made significant advancements in large models in Q4, with larger models like Yi and Qwen being open-sourced, which is excellent news for many enterprises.
As the model size increases, not only does it bring stronger reasoning capabilities, but it also improves understanding of prompts. A portion of the recall module’s burden can be transferred to the large model, rather than trying various methods to improve the recall system. Regarding how the large model decides on suitable recalls and generates content, there are two ideas: one is to build an agent platform from a system architecture perspective, and the other is fine-tuning in a purely RAG scenario. For the first idea, there are many open-source solutions, such as ReAct, AutoGPT, ToolLlama, etc. It is not limited to knowledge recall and can integrate more capabilities. The design of the agent system will be discussed separately later. For the second idea, it is essentially about constructing a suitable input-target dataset, where the target can be broken down into multiple parts, allowing the model to learn to trigger recall at appropriate times. For example, in the case of “What is the area difference between East Lake in Wuhan and West Lake in Hangzhou?” the target needs to include two questions for recall, along with candidate segments for each question. All of this can be accomplished through open-source APIs for data construction, and the overall difficulty is not high. The key is to ensure data diversity and to construct it step by step to minimize errors in the training data while ensuring it works in real scenarios.
Evaluation Dimensions for RAG Systems
Ending with system evaluation.
Evaluating recall tools is quite straightforward, assessing the recall of correct answer segments and the proportion of recall noise (irrelevant).
Evaluation of generation also consists of two dimensions: hallucination (divided into two parts: 1. omitted content from knowledge segments, 2. provided unexpected knowledge from knowledge segments) and question relevance (whether the user’s question was fully answered).
Finally, here is a slide from OpenAI’s DevDay presentation, which illustrates the advantages of a large model dominating. As the capabilities of large models in the open-source community continue to strengthen, it is likely that large models dominating various scenarios will become a new trend. (Does this resonate with the title? Not trying to be clickbait 🤡)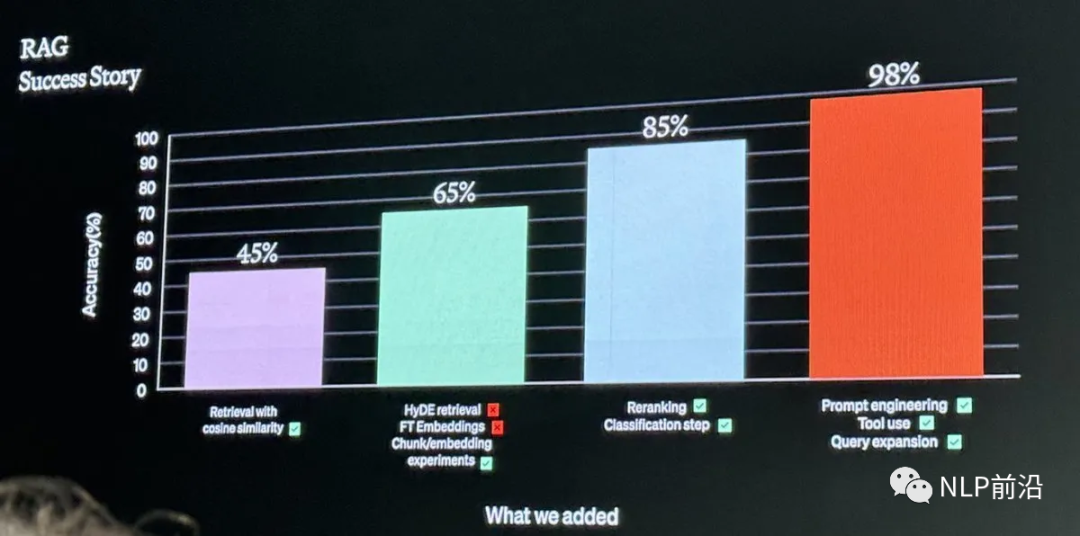
As usual, for algorithm discussions, feel free to message me or add me on WeChat, WeChat ID: nipi64310