1. Introduction
Since leaving the last company with Yuanwai, we started our own company focusing on the development of RAG large model AI product applications. During this period, which included a Spring Festival, the total time was about three months. We worked day and night, and as of the end of March, the product has taken on a basic form.
During this time, Yuanwai was responsible for the marketing of the entire product and negotiations with commercial clients, while I and Abao were responsible for the overall technical architecture setup and coding from scratch. We launched a preliminary version of the product on January 26, 2024, and began accepting trials from corporate clients. This allowed us to gather a lot of feedback on the demand and identify areas where our product lacks competitiveness in the current market environment.
As three months have passed, with our TorchV AI product taking shape, I would like to share some insights and experiences from developing RAG and LLM systems.
2. Introduction to RAG
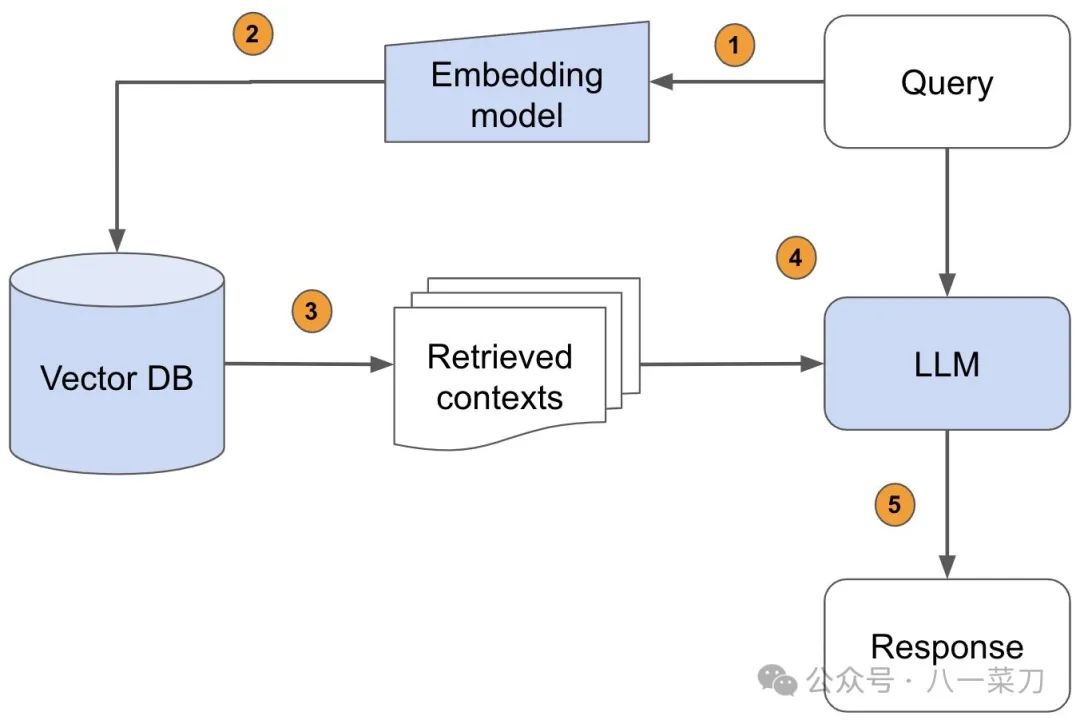
RAG (Retrieval-Augmented Generation) originated from a paper in 2020 titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, aiming to provide additional information from external knowledge sources to large language models (LLMs). This way, LLMs can generate more accurate and contextually relevant answers while effectively reducing the likelihood of producing misleading information.
In today’s explosion of large models, RAG has pointed the way for handling knowledge-intensive NLP tasks, combined with AI large models, causing a revolutionary change in the world. Countless developers have flooded into this field, competing with one another.
We know that LLMs currently face some problems and challenges:
In my understanding, the essence of LLMs is just a binary file, where all knowledge is compressed into one or multiple GB binary files. Ultimately, when retrieving data, the LLM’s model architecture and inference capabilities regenerate all the knowledge information.
-
Providing false information (hallucinations) in the absence of answers. -
Cost and cycle of updating model knowledge, and issues with the general capabilities of large models (only large companies can manage). -
Data security and privacy issues.
The emergence of RAG technology can effectively alleviate some of the current issues with large models, mainly reflected in the following aspects:
-
Economically efficient handling of knowledge & ready-to-use: By leveraging information retrieval & vector technology, we can efficiently provide knowledge that the large model does not know by combining the user’s questions with the knowledge base through relevance search, while also possessing authority. -
Effectively avoiding hallucination issues: Although it cannot completely solve the hallucination problem of large models, RAG technology can significantly reduce it. By combining large models with idempotent API interfaces in software systems, we can leverage the significant capabilities of large models. -
Data security: Companies’ data can be effectively protected. By privatizing the deployment of AI products developed based on RAG systems, we can enjoy the convenience brought by AI while avoiding the leakage of corporate privacy data.
3. RAG Technology & Architectural Considerations
Since we know that RAG has a natural advantage when combined with knowledge-intensive databases, how can we effectively develop RAG?
The core technology foundation of RAG applications is: enabling large models to accurately answer user questions based on existing data (PDF/WORD/Excel/HTML, etc.)
This is the most basic function and the minimum requirement. Any AI application product in the RAG field must tackle this technical challenge.
Note the two core points:
-
📁 Reliance on existing knowledge bases: Relying on the client’s own data is to provide strong data support for the large model, avoiding the large model from generating nonsense. The large model does not incorporate the client’s private data into its training, so it cannot know about the client’s private data and related issues. Even if the large model can answer questions in this field, it is because those questions already exist in the training dataset of the large model, which is a public dataset. However, the large model cannot have access to private data (financial reports, private data, etc.). -
🏹 Precise answers: Once the client has uploaded their private data, our task is to rely on this data to accurately answer user questions. To achieve precise answers, technical personnel need to make multi-faceted efforts 💪.
The most critical considerations for technical personnel regarding RAG applications are these two points. To achieve this goal, the breadth of knowledge and technical difficulty involved is substantial.
Previously, I referenced the development of large model architectures to sketch a similar diagram for RAG:
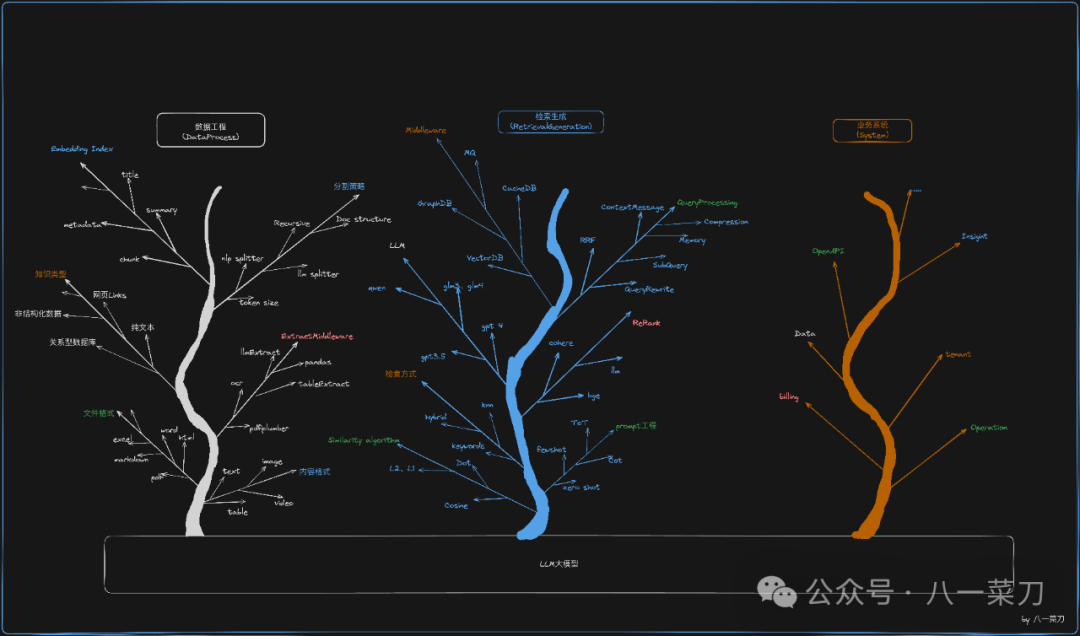
In this, I summarize the RAG system into three trees, where the LLM large model is the soil, mainly consisting of: Data Engineering, Retrieval Generation, and Business Systems.
Here, I did not include model fine-tuning. Once we achieve a basic engineering score of 80, we may consider incorporating fine-tuning work for embedding models, chat models, etc., to optimize for specific business scenarios.
-
Data Engineering: The forms of knowledge bases are diverse. In conjunction with RAG, we have a lot to do, including file types, formats, segmentation strategies, knowledge types, indexing methods, etc. -
Retrieval Generation: After processing the data, we need to conduct retrieval generation with the large model, which includes: prompt engineering, algorithm strategies, retrieval methods, middleware, large models, query processing, etc. -
Business Systems: This involves the business systems derived from commercial activities & upper-layer product applications, including tenants, billing, open platforms, insights, operations, etc. These business systems are all reflected in the product system of TorchV AI.
From the above diagram, we can see that the product development of RAG + LLM large model systems is a highly comprehensive task, akin to the training of large models. The entire project is large and complex, constituting a systemic engineering challenge.
If we consider each item in the three trees as a technical factor, optimizing the different steps will affect the final external commercial impact, leading to a transformation from quantitative to qualitative change.
Assuming: If we improve all steps in data engineering and retrieval engineering by 10% on a technical level, what would our advantage be in competing with similar products?
3.1 Data Engineering
In the world of large models, there is a classic saying: Garbage in and garbage out. The meaning is obvious: the higher the quality of data you feed to the large model, the better the response results. Conversely, if you provide garbage data, the large model will return garbage to you.
Therefore, from this perspective, upper-layer application developers must treat data engineering as the first hurdle to overcome when developing knowledge base-type products. This involves classifying datasets from different domains, as there are currently many data formats.
This includes a variety of challenges:
-
Common file parsing: Data sets based on file types are the most common and widely used formats, such as (PDF/WORD/Excel/CSV/HTML/Markdown), etc. -
Relational/NoSQL databases: Users’ data is all stored in middleware databases, such as MySQL/Postgres, etc. Extracting data from NoSQL databases is not difficult; developers just need to connect and extract according to different database standard protocols, adapting to different database types. -
Web datasets: For processing web datasets, developers need to be proficient in web scraping techniques. There is also a wide variety of data types available online, including ordinary W3C web pages (with complex and varied formats), videos, audios, etc. -
Different types of data extraction: This includes text, images, tables, videos, etc. Just processing tabular data in different file formats requires a lot of effort to optimize. -
Extraction method categories: Traditional software engineering, OCR, large models, etc. -
Segmentation strategies: Segmentation strategies play a crucial role in the RAG technical system. Poor segmentation can lead to the loss of semantics during information retrieval (IR), including: semantic segmentation, large model segmentation, fixed-token segmentation, document structure segmentation, etc. -
Embedding index construction: In addition to building vector indices for each chunk, metadata, titles, summaries, etc., also have different requirements for system accuracy and must be integrated with upper-layer business. -
More…
In data engineering, all technological developments are not stagnant. The above merely lists some fundamental branches. I believe that in today’s explosion of large model AI, data engineering (ETL) will advance even faster.
3.2 Retrieval Generation
When we have processed all knowledge data and constructed a chat system using large models, information retrieval technology is inevitably involved.
From this, it seems that doing RAG is just doing search?
In the current RAG retrieval technology system, the two most common methods are keyword and vector semantic retrieval.
-
Keyword retrieval: Based on inverted index techniques like BM25, this method executes searches by counting keywords, but it lacks semantic information. -
Vector semantic retrieval: This method represents all knowledge fragments using pre-trained language models like BERT to extract representations as multi-dimensional vector data, and retrieves results using KNN/ANN algorithms.
Of course, both retrieval engines are supported in many vector database middleware, and hybrid retrieval is also an important technical means.
Throughout the retrieval generation process, this tree also has many technical details to focus on, as follows:
-
Prompt engineering: This is essential for interacting with large models. Technical personnel must master prompt engineering, which can play a significant role through FewShot, CoT, ZeroShot techniques, and developers need to debug according to specific business scenarios. It is also an important means of ensuring idempotency when interfacing with large models. -
LLM large models: Models like glm3/4, Baichuan, Qianwen, Yuezhi Anmian, gpt3.5, gpt4, etc., each have different strengths in various scenarios and capabilities, making deep business debugging/adaptation equally important. -
Retrieval recall process handling: Multi-turn dialogue, query rewriting, multi-hop, multi-route recall, subqueries, etc. As business scenarios deepen, ensuring stability and reliability in each chain link is not an easy task. -
Middleware: System stability, high availability, and scalability cannot be achieved without middleware support. Essential components include caches, message queues, vector databases, graph databases, etc. -
More:….
In this retrieval generation tree, close cooperation with data engineering is inseparable, both deeply digging into technical details to reduce large model hallucinations.
4. Technology & Product Leadership Driving Business Development
Since developing AI applications like RAG, I have felt that it is quite different from previous product/project work. On one hand, the technology stack is relatively new, and the technological transformations brought by new technologies present significant challenges. With the advent of large models, the demands & ideas are diverse. Moreover, I believe that current AI applications are more about technology & product leading the drive for business development, which may differ from the development processes of ordinary software companies.
Here are a few points I find very important:
-
The rapid development of new AI technologies will inevitably revolutionize previous software processes and development methods, necessitating a shift in mindset. -
The hallucination problem of large models is severe. Solving hallucinations through RAG technology is easy to achieve at a score of 60, but raising the underlying capabilities to 80 or even 90 is very challenging and requires a long-term iterative process. -
Enterprise clients will not pay for a technology product that only scores 60-70. Product researchers and developers need to hold themselves to a higher standard regarding software coding, technical architecture, and product interaction, striving for perfection.
After several iterations within our team and encountering many client demands, the team’s direction is constantly adjusting and evolving.
When we established TorchV AI, the overall architecture was as follows:
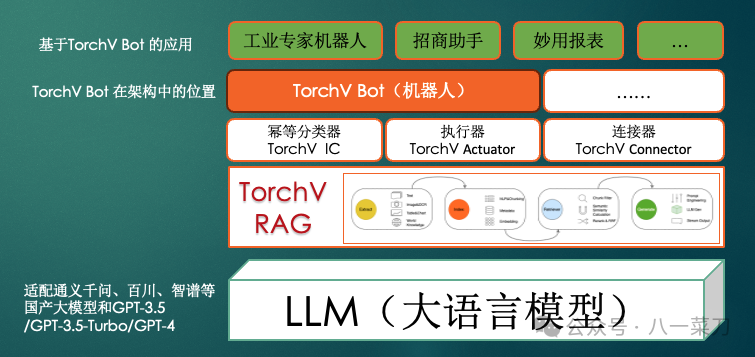
We focus on RAG technology as the core, creating our middleware layer above it, with the three core components being:
The main core issues focus on reducing large model hallucinations and connecting different data sources.
-
TorchV IC (Idempotent Classifier): This component aims to maximize the impact of established factual data, introducing as much idempotency as possible to combat and reduce LLM hallucinations; -
TorchV Actuator (Executor): This optimizes the output format unique to TorchV, including the assembly of interactive interfaces for better application friendliness; -
TorchV Connector (Connector): This connects local data and orderly resolves the diversity and complexity of data in localized scenarios.
By combining RAG technology with middleware, we developed our first baseline product, TorchV Bot. Through continuous product iterations and the collision of different client demands, the architecture of our TorchV Bot baseline product has also taken shape. As shown in the following diagram:
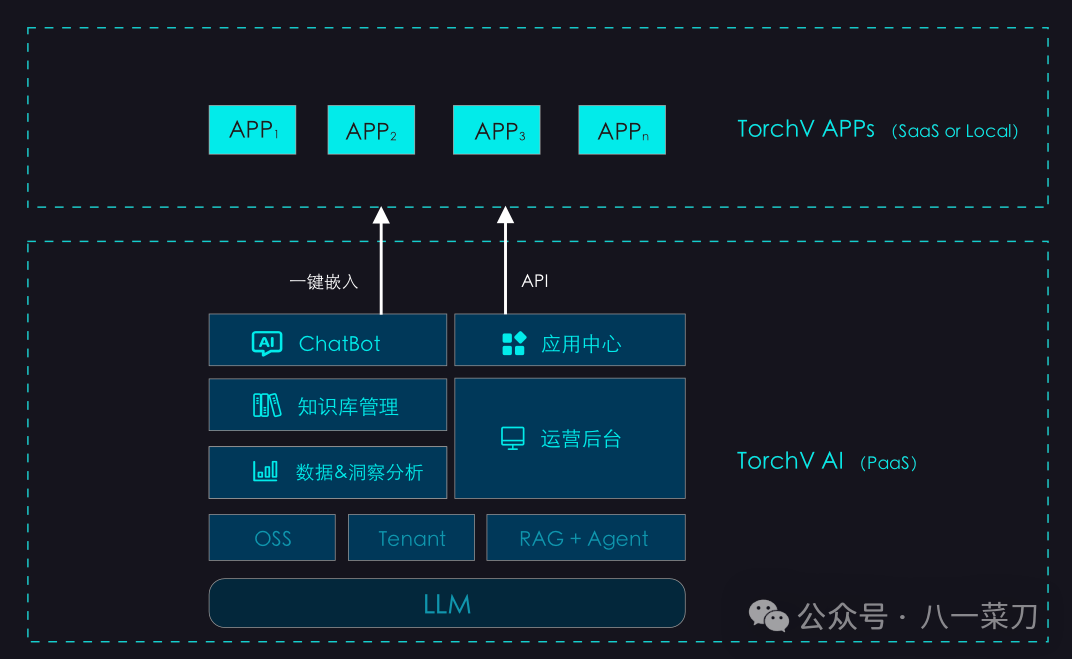
The main components are broken down as follows:
-
RAG and Agent: RAG (Retrieval-Augmented Generation) and Agent are currently the factual standards for deploying large language models in enterprise applications and are also one of the core middleware components of TorchV AI; -
Tenant: The tenant system serves as the foundation for our multi-tenant PaaS/SaaS platform; -
OSS: Online file storage, including files uploaded by clients and data imported from URLs; -
ChatBot: TorchV AI will provide a default web-based Q&A system where clients can test knowledge and directly use it in internal scenarios; -
Data & Insight Analysis: Analyzing data, including some insight conditions preset by clients, which, once triggered, will execute designated actions, such as product and service recommendations, consultation diversion, etc. Clients can also synchronize data here and import it into their systems as a data analysis foundation; -
Knowledge Base Management: Creating a knowledge base to upload and import files for each knowledge base. Once uploaded, files are immediately processed by the system into chunks (small text blocks) and vector data after embedding; -
Operational Backend: This includes billing systems, various parameter configurations, conversation record viewing and annotation, user permission settings, and feedback processing functions; -
Application Center: A client can create multiple applications and connect their existing systems through APIs or create new applications based on APIs. Besides APIs, we also provide an easy embedding connection method, requiring only a few lines of JS code to activate the floating icon on the client’s web application, providing TorchV AI’s dialogue capabilities.
The above describes the current product prototype of TorchV. For more details, please visit our official website: https://www.torchv.com
5. Choosing Architecture & Programming Languages
With the explosive popularity of large models (LLMs), many developers may find it challenging to start when selecting programming languages for developing RAG system applications.
Initially, when developing RAG applications, I struggled with the choice of programming languages, encountering many detours and gaining some lessons along the way.
The current product of TorchV.AI has chosen Java and Python as the server-side development languages.
Here are a few reasons:
-
Yuanwai and I both have years of experience in Java development, so our understanding of coding and the ecosystem makes it impossible to abandon Java. -
Python is inevitable, but in the entire project, there are divisions of responsibilities. Stateless logical operations are implemented through Python. -
Enterprise-level development languages and technical component ecosystems. -
The richness of middleware and the healthy development of the developer community.
The following diagram compares some characteristics of Java and Python in different fields.
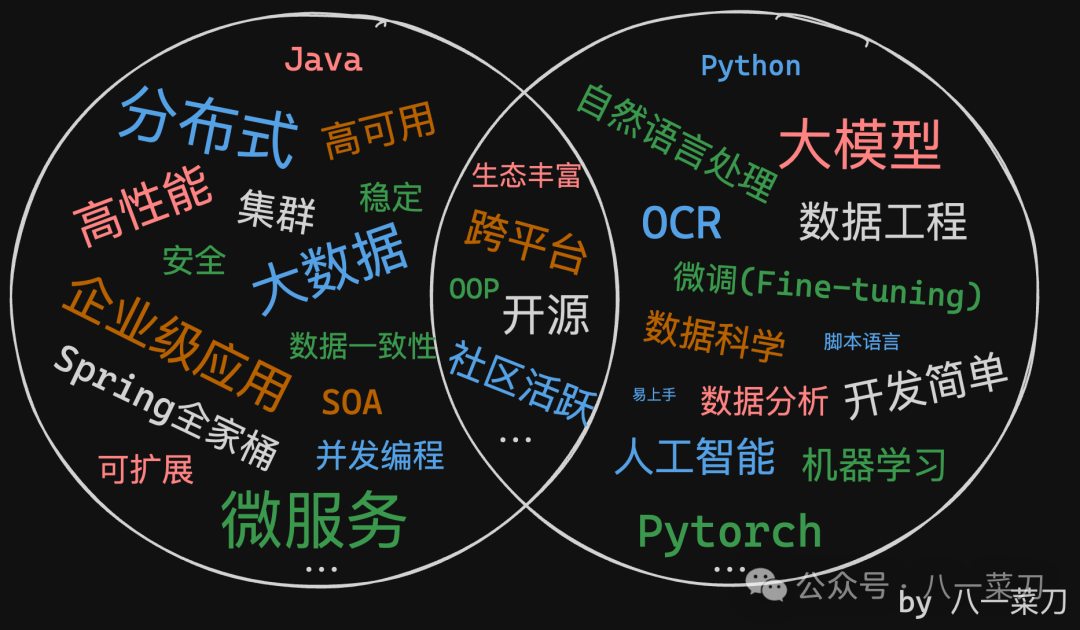
Currently, the most popular frameworks for developing RAG large model applications are LangChain and LlamaIndex, both developed in Python, providing out-of-the-box functionality, allowing you to easily complete a RAG large model application demo in no more than 10 lines of code.
Initially, we also struggled with how to make better choices during this period. After discussions within the team, we decided to keep some business logic in Java and rewrite some core logic and components during the RAG process.
Here are my thoughts:
-
RAG architecture involves many diverse elements, and out-of-the-box LLM data processing frameworks may not meet enterprise business demands (which can vary widely). -
RAG has not yet developed into a protocol agreement like HTTP specifications, so different RAG processes and LLM models can lead to variations in RAG outcomes. -
With a plethora of domestic LLMs, out-of-the-box solutions may not be feasible, as different local requirements also need to be met (localization adaptations).
By combining the data engineering and other logical aspects involved in developing RAG applications, we can easily sketch a language-level architecture diagram that covers how to quickly adapt upper-layer application requirements in enterprise development and business scenarios. As shown in the following diagram:
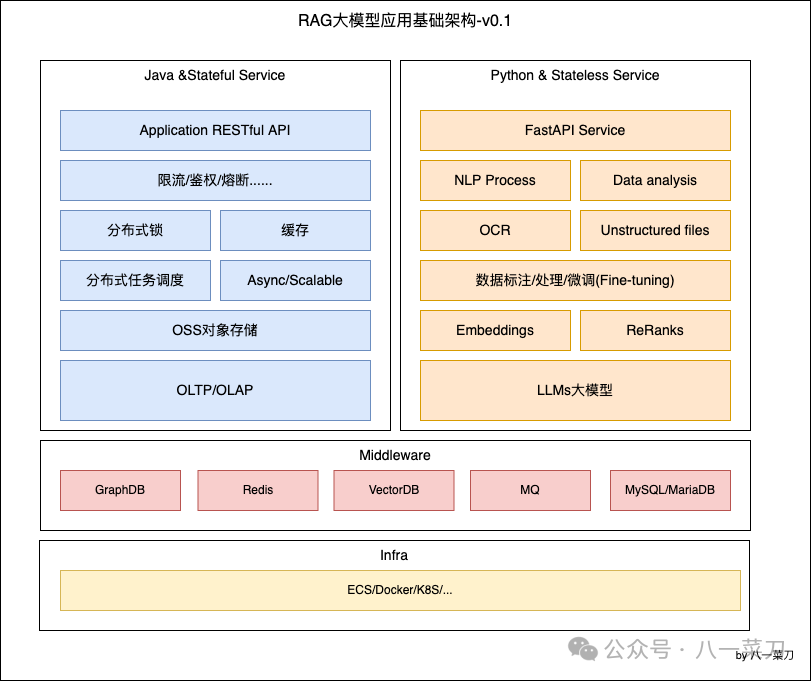
In this diagram, we can clearly see that for different tasks and requirements, the division of responsibilities is relatively clear.
-
Java: When using the Java ecosystem, development focuses on the characteristics of business system data consistency, distributed systems, authentication, rate limiting, etc., for which there are currently very mature solutions. -
Python: For stateless services, supporting the processing of upper-layer applications, including data engineering, chat models, data processing, fine-tuning, and other system engineering, using Python is undoubtedly the best choice.
When developing applications, the priority in selecting programming languages should be based on their ecosystem and stability.
Of course, there is no unique standard; the optimal choice depends on one’s actual situation. The above is merely my perspective.
6. Conclusion
Alright, that concludes the text. To summarize:
-
Development of AI products like RAG and LLM is rapidly evolving, and the technology stack will develop quickly. For companies, small steps and rapid iterations may be very important. -
Currently, application scenarios are only focused on knowledge-intensive tasks. In the future, with technological advancements, they will expand into more industries.
TorchV.AI is currently in its early stages, and we welcome more enterprise clients to try and collaborate!!!
If you have business cooperation needs:
Please scan to add the following WeChat (Yuanwai 🔥TorchV), and please inform your name and company name.

Our official website is: https://www.torchv.com
7. References
-
https://www.torchv.com -
https://www.luxiangdong.com -
https://arxiv.org/abs/2005.11401