
This article is a joint introduction to computer industry terminology launched by the CCF Computer Terminology Review Committee and the CCF Natural Language Processing Special Committee. The hot word selected for this issue is Unsupervised Machine Translation, which is one of the current popular research directions. Unsupervised machine translation methods no longer rely on large-scale parallel corpora, making them suitable for translation scenarios of low-resource languages. This article briefly introduces the development history of unsupervised machine translation, as well as its basic implementation methods, and finally discusses and analyzes the challenges faced by this technology.
Definition of the Term
Unsupervised machine translation (UMT) is a type of machine translation that automatically translates from one natural language to another without given large-scale bilingual parallel corpora, using machine learning algorithms. Since unsupervised machine translation methods avoid over-reliance on large-scale parallel corpora, they are more suitable for low-resource languages or domains.
Development of Unsupervised Machine Translation
Early research considered the task of unsupervised machine translation as a deciphering problem[1-2]. Specifically, the source language was viewed as ciphertext, and the process of generating ciphertext was divided into two stages: the generation of the target language and the probabilistic replacement of words within it. However, this method was only applicable to the translation of shorter sentences.
In recent years, neural networks have demonstrated strong autonomous learning capabilities, and deep learning has achieved significant effects in many natural language processing tasks. Researchers have applied deep learning methods to unsupervised machine translation tasks, referred to as Unsupervised Neural Machine Translation (UNMT). Since its first implementation in 2017[3-6], it has made great progress. Its development history can be roughly divided into three stages:
The first stage was in 2017, when Artetxe et al. and Conneau et al. respectively used unsupervised methods to achieve cross-lingual word embeddings[3][4], and then obtained a vocabulary based on the learned mapping matrix, subsequently achieving unsupervised neural machine translation through language model training and back-translation techniques[5][6].
The second stage involved Lample’s induction of the three main principles of unsupervised neural machine translation[7], jointly learning bilingual word embeddings while sharing a bilingual vocabulary, and converting the vocabulary from words to subwords using BPE encoding.
The third stage saw the proposal of unsupervised cross-lingual pre-training models, which successfully applied pre-trained models to unsupervised neural machine translation tasks[8], significantly refreshing the performance of unsupervised neural machine translation.
Based on the developments in these three stages, researchers have proposed their own improvements to unsupervised neural machine translation models, such as Yang et al.’s proposal in 2019 to change shared encoders to independent encoders to enhance the language features of sentences themselves[9]; Ji et al. used dictionaries to achieve unsupervised neural machine translation across different language systems in 2020[10].
Basic Implementation Methods of Unsupervised Neural Machine Translation
Unsupervised neural machine translation does not use parallel corpora, but only employs monolingual corpora to perform translations from the source language to the target language. Specifically, let S and T represent the sentence sets of the source and target languages, respectively, and s(s∈S) and t (t∈T) represent individual sentences from the two languages. 𝑃𝑠 and 𝑃𝑡 represent the language models trained using the source and target language monolingual corpora, respectively, while 𝑃𝑠→𝑡 represents the translation model from the source language to the target language, and similarly, 𝑃𝑡→𝑠 represents the translation model from the target language to the source language. Before the emergence of unsupervised cross-lingual pre-training models, the training process of unsupervised neural machine translation models mainly consisted of the following three steps[3][4]:
(1) Initialize the bilingual vocabulary. The initialization of word vectors in the unsupervised neural machine translation model can generally be divided into two methods: The first method uses Word2vec to independently train the word vectors of the two languages and then learns a transformation matrix to map the word vectors of the two languages into the same latent space. This way, a bilingual vocabulary with good accuracy can be obtained. The second method uses byte pair encoding (BPE) of words as subword units. The advantage of this approach is that it reduces vocabulary size while eliminating the issue of “unknown (UNK)” words during translation. Additionally, compared to the first method, the second method chooses to mix and shuffle the two monolingual corpora to jointly learn the features of word vectors, allowing the source and target languages to share the same vocabulary. However, this cross-lingual word embedding has a prerequisite, which is that the two languages are similar languages within the same language family.
(2) Train the language model. In the bilingual UNMT model, the denoising autoencoder’s loss function is minimized as follows:
𝐿𝑙𝑚 = 𝐸𝑥∈𝑆[− log 𝑃𝑠→𝑠(𝑥|𝐶(𝑥))] + 𝐸𝑦∈𝑇[−𝑙𝑜𝑔 𝑃𝑡→𝑡(𝑦|𝐶(𝑦))](Formula 1)
Where: 𝐶(𝑥) represents the sentence 𝑥 with noise added, achieved by swapping some words in the sentence or deleting some words. 𝐸 represents the expectation of the loss of all sentence pairs in the training set. The training process of the language model essentially takes the noisy sentence 𝐶(𝑥) as the source input sentence and the original sentence 𝑥 as the target input sentence, treating (𝐶(𝑥), 𝑥) as a parallel sentence pair for training.
(3) Back-translation: The back-translation process treats pseudo-parallel sentence pairs as parallel sentence pairs for training. The loss function for training is shown in Formula (2).
𝐿𝑏𝑎𝑐𝑘 = 𝐸𝑦∈𝑇[−𝑙𝑜𝑔𝑃𝑠→𝑡(𝑦|𝑢∗(𝑦))] + 𝐸𝑥∈𝑆[−𝑙𝑜𝑔𝑃𝑡→𝑠(𝑥|𝑢∗(𝑥))](Formula 2)
Where: 𝑢∗(𝑦) represents the source language sentence obtained from the target language sentence based on the current language model; conversely, 𝑢∗(𝑥) represents the target language sentence obtained from the source language sentence. The back-translation process treats both (𝑢∗(𝑦), 𝑦) and (𝑢∗(𝑥), 𝑥) as parallel sentence pairs for training, transforming the unsupervised problem into a supervised one.
The models in (2) and (3) share encoders and decoders, and through repeated iterations of (2) and (3), the complete training process of the bilingual single-task unsupervised neural machine translation model is achieved. The algorithm flow is shown in Figure 1[7].
With the introduction of pre-trained models, cross-lingual pre-training models have been used to train the bilingual word embedding features and the parameters of the Transformer network structure used in unsupervised neural machine translation, significantly improving the translation performance of unsupervised neural machine translation models.

Figure 1 Algorithm flow of unsupervised neural machine translation
Challenges Faced by Unsupervised Machine Translation
Despite the rapid development of unsupervised (neural) machine translation in recent years, current research in unsupervised machine translation still has many limitations and faces various challenges.
First, current research on unsupervised machine translation is mostly based on related languages such as English, French, and German. Due to the lower quality of learned word vectors between non-related languages, such as Chinese-English and English-Japanese, the performance of unsupervised neural machine translation on these language pairs is poor[11][12].
Second, current research on unsupervised machine translation often assumes that the domain of the test set is similar to that of the training set, which presents certain limitations. In addition to the potential inconsistency between the domains of the test set and training set, the monolingual corpora used for the source and target ends of unsupervised translation may also have domain inconsistencies and differences in scale, making the domain adaptation problem for unsupervised neural machine translation more challenging[12].
More Terminology
If readers are interested in learning more about professional terms and industry hot words, they can visit the CCFpedia computer terminology platform (http://term.ccf.org.cn), where they can quickly and conveniently search for terms in the search bar on the homepage and enter the definition interface of the target term. This interface provides a detailed introduction to the target term from multiple perspectives, facilitating better understanding for users. The attribute introduction includes Chinese name, foreign name, abbreviation, category, and industry application, and based on this, multi-angle analysis is conducted according to the different characteristics of the terms, such as: technical performance, development history, key technologies, implementation methods, challenges faced, etc. Finally, hyperlinks to relevant references are attached, allowing users to click the links to browse more information and expand their professional horizons.
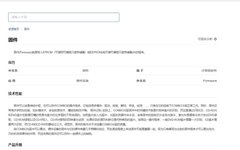
For example, the term “firmware” is detailed in CCFpedia, showcasing a concise definition, basic attributes, and detailed content about its technical performance and product upgrades for readers to browse and learn.
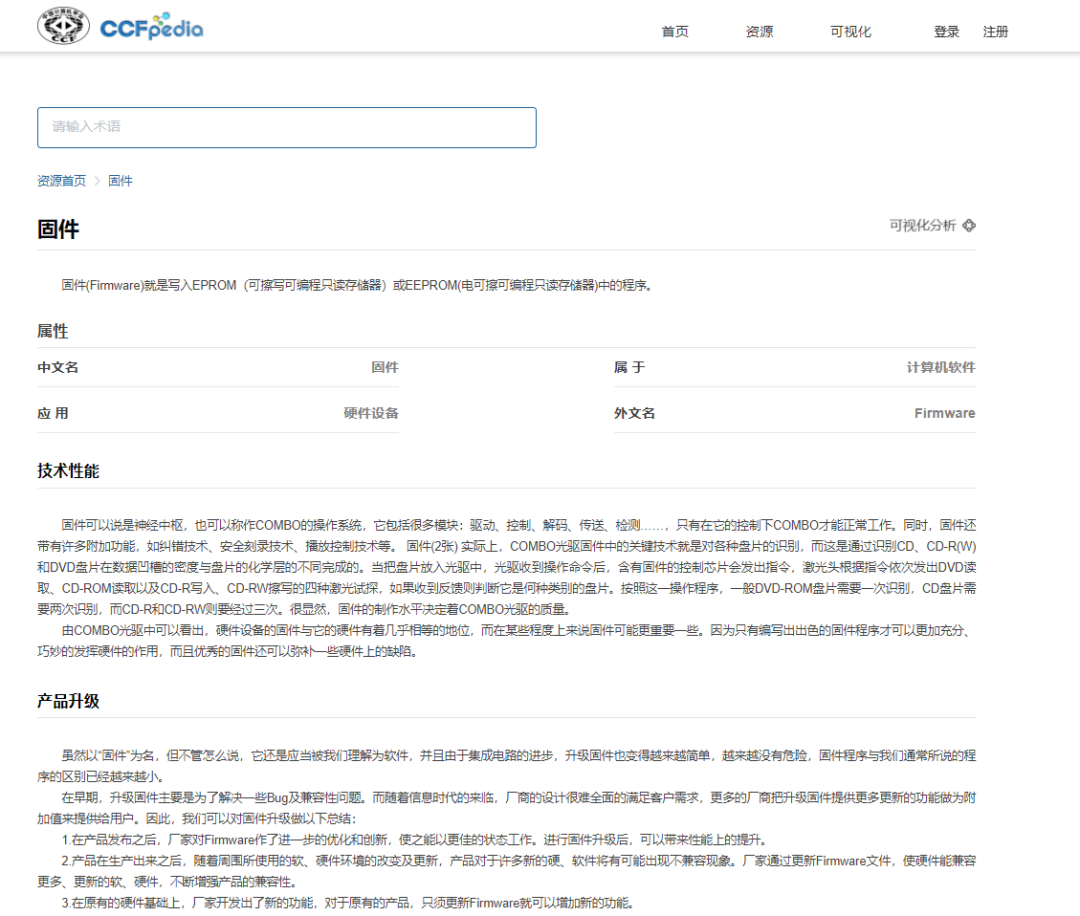
Additionally, users can click the upper right corner “Visualize” to switch views, presenting the rich associative hierarchical relationships of terms in the form of a knowledge graph, with the knowledge card for the terms displayed succinctly on the right, providing key information including definition description and basic information.
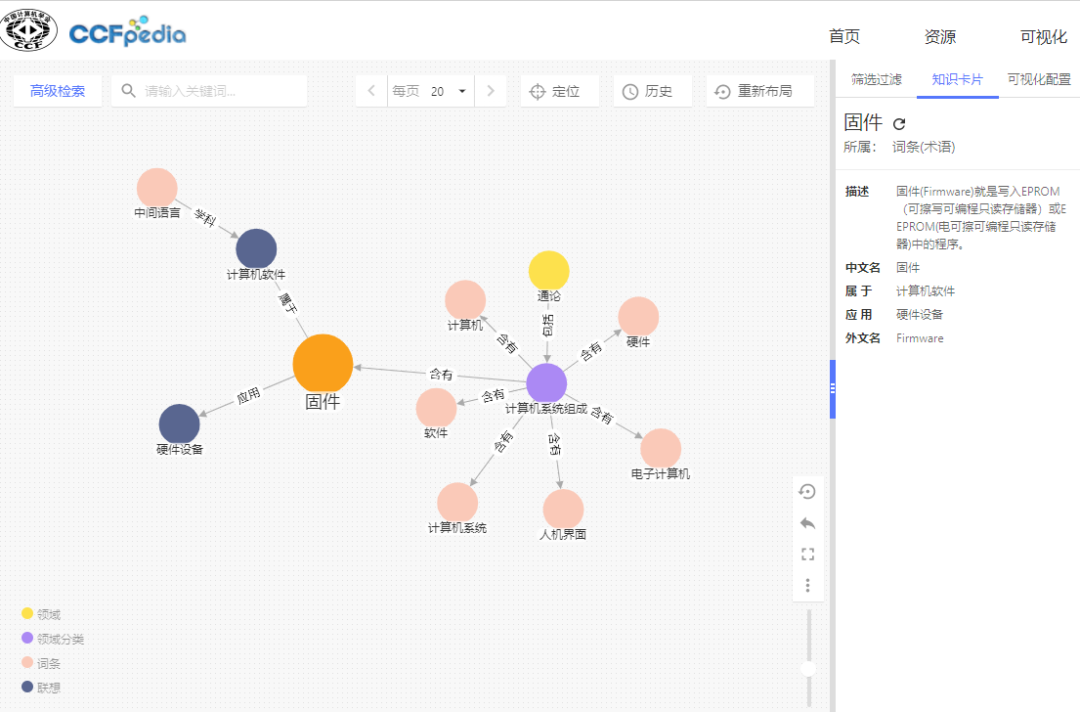
Users can also click “Filter” to switch the right sidebar view for visual selection and editing of the graph, lowering the threshold for graph construction and enhancing usability. It supports setting exploration filtering conditions, including setting display layers, setting expansion levels, setting the direction of query relationships, setting query nodes, confidence range of relationships, setting query nodes, and weight range of relationships.
Introduction to the Terminology Committee and Terminology Platform
The Committee on Terminology mainly functions to collect, translate, interpret, review, and recommend new computer terms, and promote them on the CCF platform. This is of great significance for clarifying the discipline system, conducting scientific research, and widely disseminating science and knowledge throughout society.
The construction and continuous optimization of the crowdsourced terminology platform CCFpedia can effectively promote the collection, review, standardization, and dissemination of computer terminology in China, while also serving to promote standardized customization across various fields.
The new version of the CCFpedia computer terminology platform (http://term.ccf.org.cn) integrates the editing operation and browsing use of terms, eliminating the cumbersome steps of cross-platform operations in the old version, upgrading the interface visibility, allowing users to easily and conveniently access term information. Meanwhile, the new platform introduces a knowledge graph approach to organize all term data, upgrading the application form of term browsing through multi-layer associative forms of the graph.
References
[1]Sujith Ravi and Kevin Knight. Deciphering Foreign Language. In Proceedings of ACL 2011, pages 12– 21.
[2]Qing Dou, Ashish Vaswani, Kevin Knight, and Chris Dyer. Unifying Bayesian Inference and Vector Space Models for Improved Decipherment. In Proceedings of ACL-IJCNLP 2015, pages 836–845.
[3]Mikel Artetxe, Gorka Labaka, and Eneko Agirre. Learning bilingual word embedding with (almost) no bilingual data. In Proceedings of ACL 2017, pages 451-462.
[4]Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Word translation without parallel data. In Proceedings of ICLR 2018.
[5]Mikel Artetxe, Gorka Labaka, Eneko Agirre, and Kyunghyun Cho. Unsupervised neural machine translation. In Proceedings of ICLR 2018.
[6]Guillaume Lample, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. Unsupervised machine translation using monolingual corpora only. In Proceedings of ICLR 2018.
[7]Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. Phrase- based & neural unsupervised machine translation. In Proceedings of EMNLP 2018, pages 5039-5049.
[8]Alexis Conneau and Guillaume Lample. Cross-lingual language model pretraining. In Proceedings of NeurIPS 2019, pages 7057-7067.
[9]Zhen Yang, Wei Chen, Feng Wang, and Bo Xu. Unsupervised neural machine translation with weight sharing. In Proceedings of ACL 2018, pages 46-55.
[10]Baijun Ji, Zhirui Zhang, Xiangyu Duan, Min Zhang, Boxing Chen, and Weihua Luo. Cross-Lingual Pre- Training Based Transfer for Zero-Shot Neural Machine Translation. In Proceedings of AAAI, 2020, pages 115-122.
[11]Yunsu Kim, Miguel Graça, and Hermann Ney. When and Why is Unsupervised Neural Machine Translation Useless? In Proceedings of EAMT 2020, pages 35-44.
[12]Kelly Marchisio and Kevin Duh and Philipp Koehn. When Does Unsupervised Machine Translation Work? In Proceedings of WMT 2020, pages 571-583.