Compiled and Organized by Annie Ruo Po | QbitAI WeChat Official Account
Author Bio: Edwin Chen, researching mathematics/linguistics at MIT, speech recognition at Microsoft Research, quantitative trading at Clarium, advertising at Twitter, and machine learning at Google.
In this article, the author first introduces the basic concepts of neural networks, RNNs, and LSTMs, then compares the performance of the three types of networks, and further explains LSTM.
LSTM is a relatively simple extension of neural networks, and it has achieved many remarkable accomplishments in recent years. When I first learned about LSTM, I was quite astonished. I wonder if you can discover the beauty of LSTM from the following diagram.
OK, let’s get into the main topic. First, let’s briefly introduce neural networks and LSTM.
Neural Networks
Suppose we have a sequence of images from a movie, and we want to label each image with an action. For example, is this a fight? Are the characters talking? Are the characters eating?
What should we do?
One way is to ignore the sequential property of the images, consider each image individually, and build a classifier for single images. For instance, given enough images and labels:
-
The algorithm first learns to detect low-level patterns such as shapes and edges.
-
Driven by more data, the algorithm learns to combine low-level patterns into complex forms, such as an oval with two circles on top and a triangle can be considered a face.
-
If there is even more data, the algorithm learns to map these high-level patterns to the actions themselves, such as a scene with a mouth, a steak, and a fork might indicate eating.
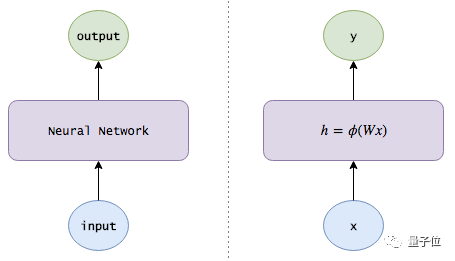
This is a deep neural network: it takes an image input and returns an action output.
The mathematical principles of neural networks are illustrated in the figure below:
Using RNN to Remember Information
Ignoring the order of images can be seen as a preliminary form of machine learning. Further, if the scene is a beach, we should reinforce beach-related labels in subsequent frames: if someone is in the water, it can probably be labeled as swimming; and if the scene shows someone with their eyes closed, it might indicate sunbathing.
Similarly, if the scene is a supermarket, someone holding bacon should be labeled as shopping, not cooking.
What we want to do is to let the model track the state of the world.
-
After seeing each image, the model outputs a label and updates its knowledge of the world. For example, the model can learn to automatically discover and track information such as location, time, and movie progress. Importantly, the model should be able to automatically discover useful information.
-
For a given new image, the model should integrate the knowledge it has gathered to perform better.
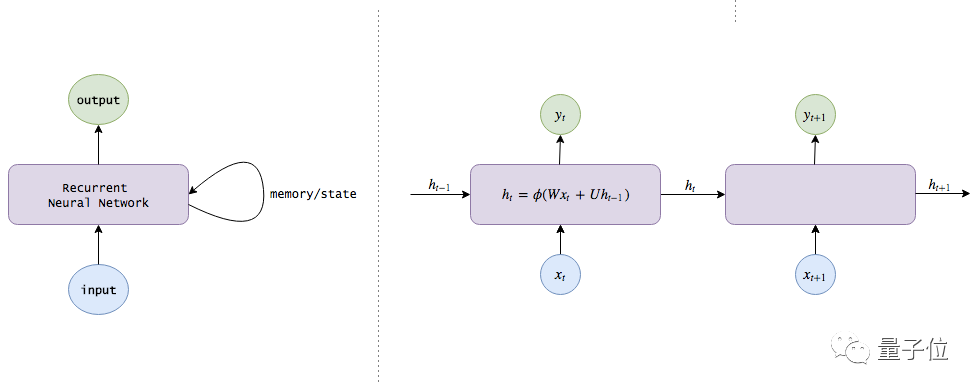
Thus, we have a Recurrent Neural Network (RNN). Instead of simply receiving an image and returning an action label, the RNN retains a memory of the world internally by assigning different weights to information, allowing it to perform classification tasks more effectively.
The mathematical principles of RNN are illustrated in the figure below:
Implementing Long-Term Memory with LSTM
How does the model update its understanding of the world? So far, there are no rules limiting this, so the model’s understanding can be very chaotic. In one frame, the model might think a character is in the US, and in the next frame, if sushi appears, the model might think the character is in Japan…
This chaos is due to the rapid change and disappearance of information, making it difficult for the model to maintain long-term memory. Therefore, we need to teach the network how to update information. The methods are as follows:
-
Introduce a forgetting mechanism. For instance, when a scene ends, the model should reset the relevant information such as location and time. If a character dies, the model should also remember this. Thus, we want the model to learn an independent forgetting/memory mechanism, knowing what information to discard when new input arrives.
-
Introduce a saving mechanism. When the model sees a new image, it needs to learn whether there is information worth using and saving.
-
So when there is a new input, the model first forgets which long-term memory information is not useful, then learns what information from the new input is worth using, and finally stores it in long-term memory.
-
Focus long-term memory on working memory. Finally, the model needs to learn which parts of long-term memory can be immediately useful. It should not always use the complete long-term memory but know which parts are key.
Thus, we have a Long Short-Term Memory Network (LSTM).
RNN rewrites its memory in a rather uncontrolled manner at each time step, while LSTM changes memory in a very precise way, applying specialized learning mechanisms to remember, update, and focus on information. This helps track information over longer periods.
The mathematical principles of LSTM are illustrated in the figure below:
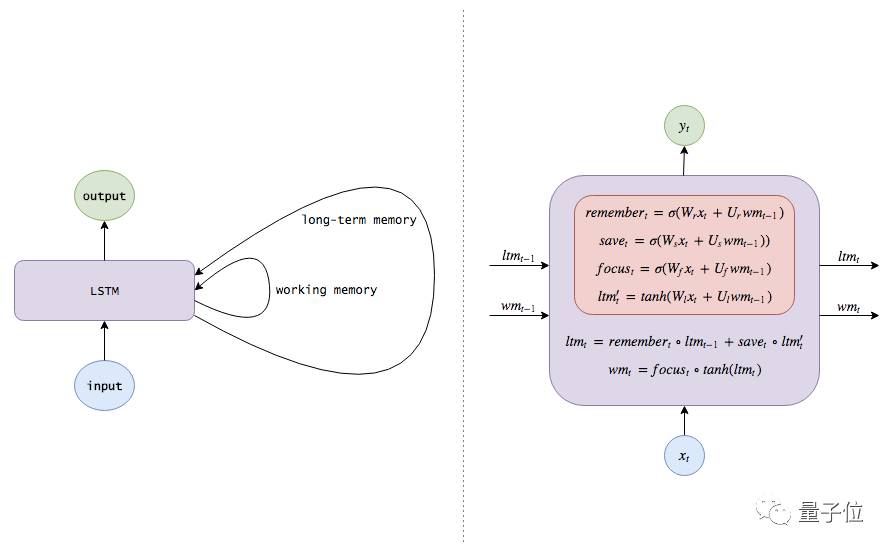
Snorlax

△ Snorlax from Pokémon
Let’s compare Snorlax from Pokémon with different types of neural networks.
Neural Networks
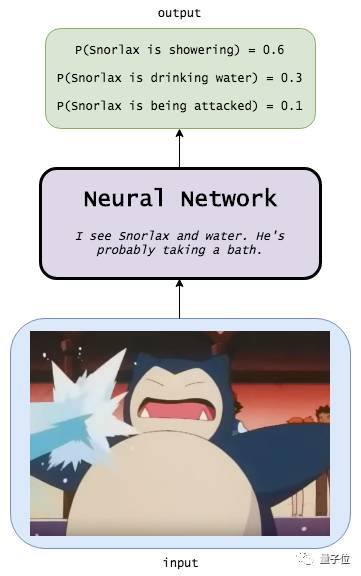
When we input an image of Snorlax being sprayed with water, the neural network recognizes Snorlax and water, inferring that there is a 60% probability that Snorlax is taking a bath, a 30% probability that it is drinking water, and a 10% probability that it is being attacked.
Recurrent Neural Networks (RNN)

With the hidden state being ‘battle scene starts’, when we input the image of Pokémon spraying an attack, the RNN can infer that the Pokémon in the image is attacking with a probability of 85% based on the ‘spraying from the mouth’ scene. After that, when we input a second image with the memory of ‘in battle, enemy is attacking, and enemy is a water type’, the RNN will analyze that ‘Snorlax is being attacked’ is the most probable situation.
LSTM
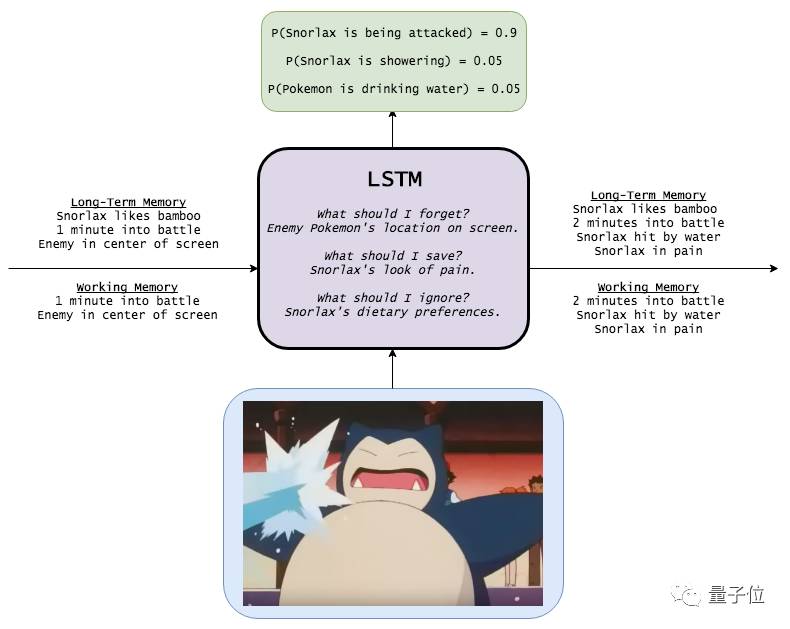
With the long-term memory being ‘Snorlax likes to eat bamboo’, ‘each battle round is one minute’, and ‘the enemy is in the center of the screen’, and the working memory being ‘each battle round is one minute’, ‘the enemy is in the center of the screen’, when we input the image of Snorlax being sprayed with water, LSTM selectively processes some information. It selectively remembers Snorlax’s painful expression, forgetting the information ‘the enemy is in the center of the screen’, concluding that the probability of Snorlax being attacked is the highest.
Learning to Encode
There is a character-level LSTM model that can predict the next likely character based on the input character sequence. I will use this model to demonstrate the usage of LSTM.
Although this method seems immature, it must be said that character-level models are very practical, and I personally find them even more useful than word-level models. Here are two examples:
1. Suppose there is a code auto-completer that is smart enough to allow mobile programming.
Theoretically, LSTM can track the return type of the current method and better suggest which variable to return; it can also tell you if there is a bug in the program by returning an error type.
2. Natural language processing programs like machine translation often struggle with obscure terminology.
How can we convert an adjective that has never been seen before into the corresponding adverb? Even if we understand what a tweet means, how do we generate a tag for it? Character-level models can help you deal with these new terms, but that is another area of research.
So at the beginning, I trained a three-layer LSTM on the Apache Commons Lang codebase using Amazon AWS Elastic Compute Cloud EC2’s p2.xlarge, and after a few hours, I generated this program:

Although this code is not perfect, it is already better than the code written by many data experts I know. From this, we can see that LSTM has learned many interesting and correct coding behaviors:
It can build classes: prioritizing licenses, then packages and imports, followed by comments and class definitions, and finally variables and methods. It also knows how to create methods: following the correct descriptive order, checking if decorators are in the right place, and returning a non-type pointer with appropriate statements. Importantly, these behaviors span a large amount of code.
It can track subroutines and nesting levels: if statement loops are always closed, indentation handling is a good choice.
It even knows how to create tests.
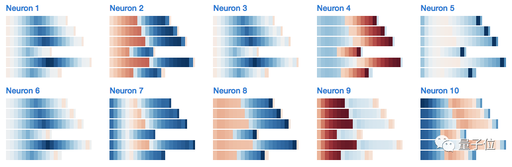
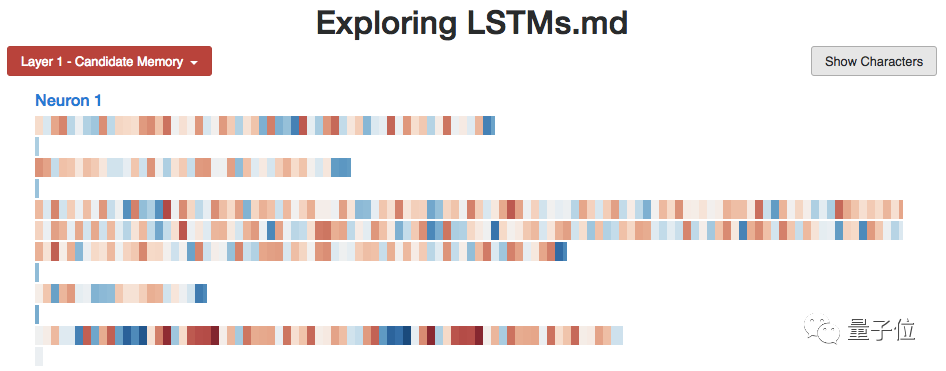
How does this model achieve these functions? We can look at some hidden states.
This is a neuron that seems to be tracking the indentation level of the code. When the neuron reads character-level input, such as trying to generate the next character, each character is colored based on the state of the neuron, with red indicating negative values and blue indicating positive values.

Here is a neuron that can calculate the distance between two labels:

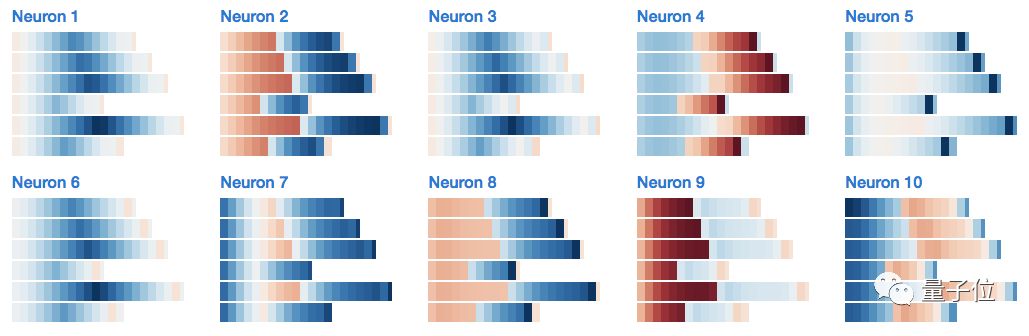
And here is an interesting output from a different three-layer LSTM generated in the TensorFlow codebase:
Studying the Internal Structure of LSTM
Above, we learned about several examples of hidden states, but let’s dive deeper. I am considering LSTM cells and their other memory mechanisms. Perhaps there are amazing relationships between them.
Counting
To explore this issue, we need to teach LSTM to count, so I generated the following sequence:
aaaaaXbbbbb
In this sequence, there is a delimiter X following N a’s, followed by N b’s. Here, 1<=N<=10. We trained a single-layer LSTM with 10 hidden neurons using this sequence.
As expected, LSTM performed well within its training range and even generated some outputs that exceeded the training range.
aaaaaaaaaaaaaaaXbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaXbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaXbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaXbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaXbbbbbbbbbbbbbbbbbb
We expect to find a hidden state neuron that calculates the number of a’s:
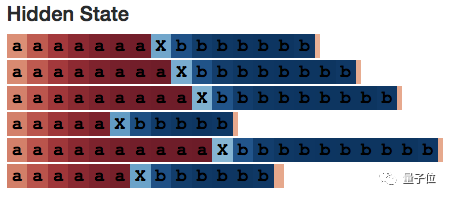
For this, I also built a small web application that can not only count the number of a’s but also count the number of b’s.
At this point, the cell performs very similarly:
Another interesting thing is that working memory seems to be an enhanced version of long-term memory. Is this normal in general?
The answer is yes, and it is completely in line with our expectations. Because long-term memory is constrained by the hyperbolic tangent activation function.
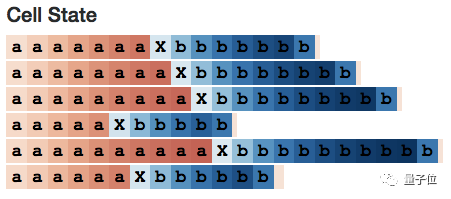
Below is an overview of the 10 cell state nodes, where we can see many light-colored cells representing values close to 0.
In contrast, these 10 working memory neurons appear more focused, with neurons 1, 3, 5, and 7 appearing to be 0 in the first half of the sequence.
Now let’s take a look at neuron 2, where I will show some backup memory and input gates (Input Gate). They are stable in each half of the neuron—it’s as if the neuron is calculating a+=1 or b+=1 at each step.

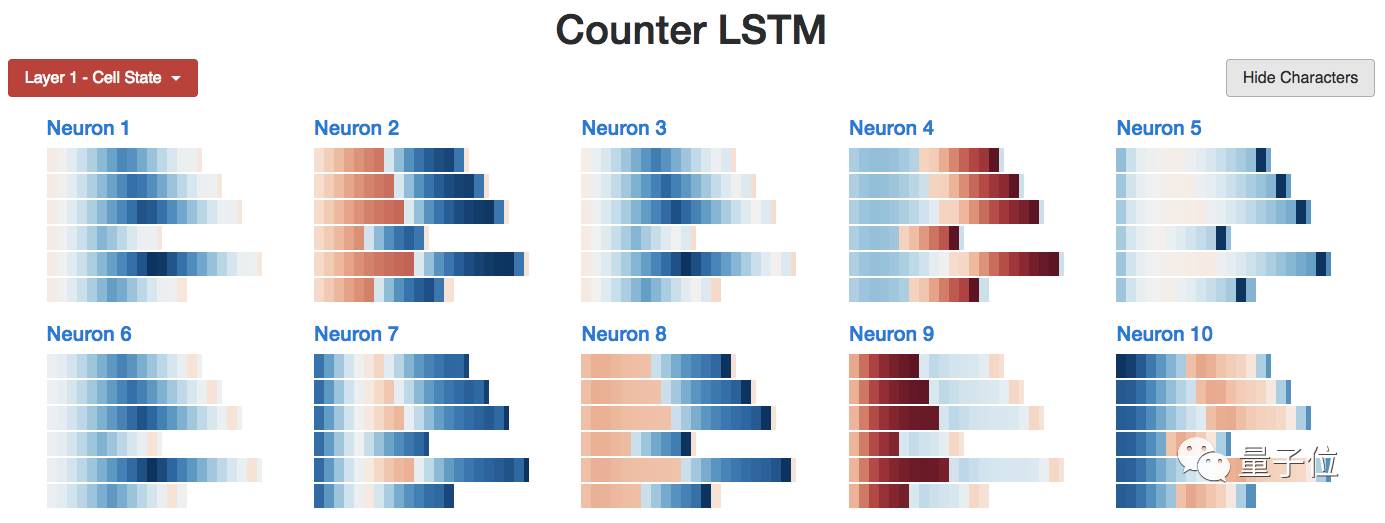
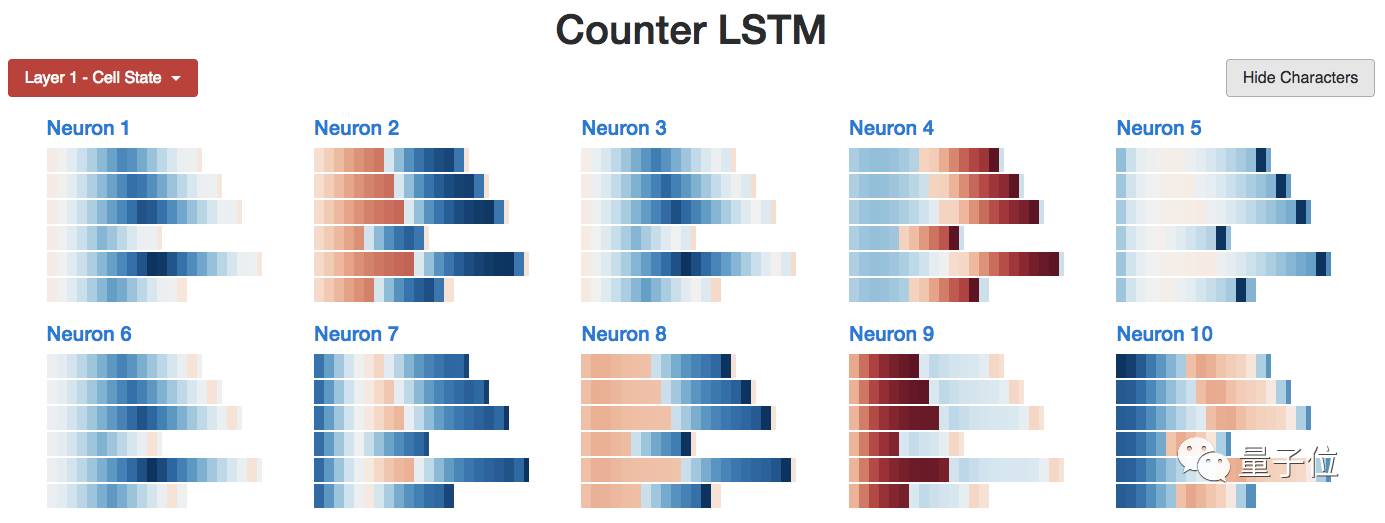
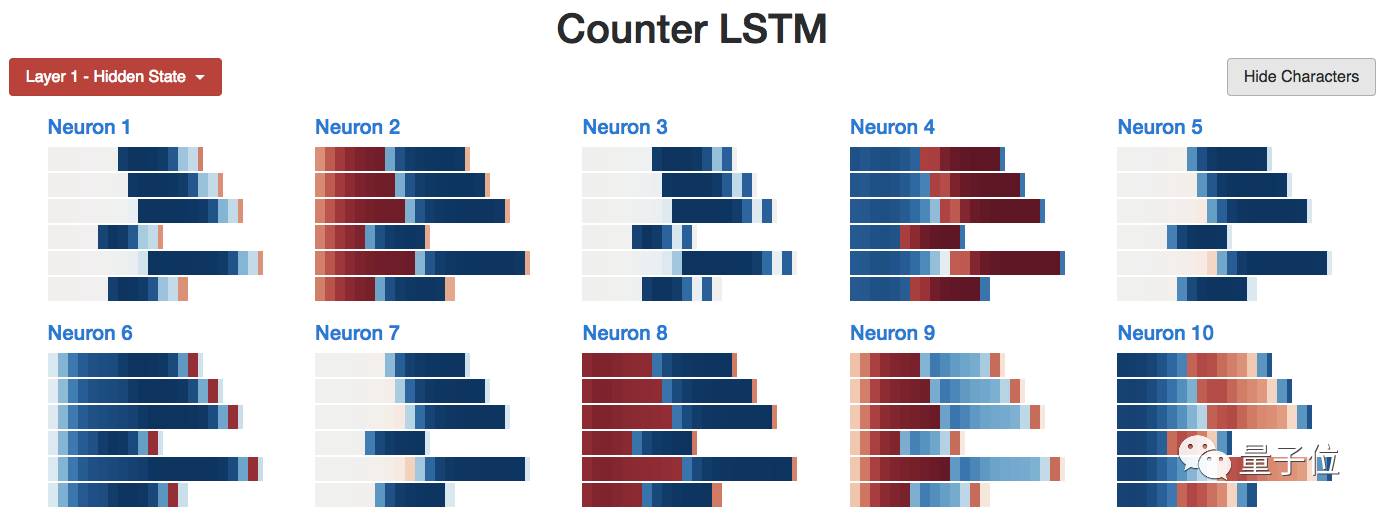
Finally, we obtained the internal structure of all neurons:
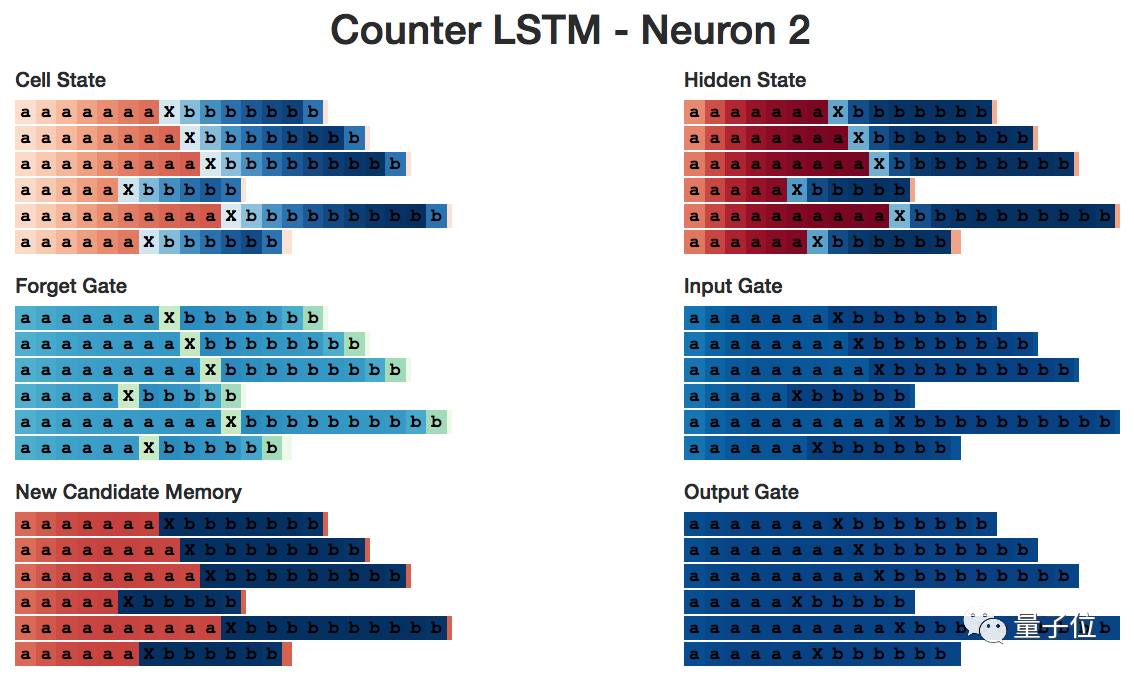
If you also want to count for different neurons, you can check out this visualization tool.
Link to visualization tool:http://blog.echen.me/lstm-explorer/#/network?file=counter
The Count Count
Remember the character from the American Public Broadcasting Service (PBS) children’s educational television show Sesame Street, a design resembling a vampire who loves to count? I will name this section Count.

△ The computer enthusiast “Count” from Sesame Street
Now let’s look at a slightly more complex counter. This time I generated a serialized form:
aaXaXaaYbbbbb
The above sequence features N a’s and X arranged in any order, followed by a delimiter Y, and finally N b’s. LSTM still needs to count the number of a’s, this time also ignoring X.
Complete LSTM link:http://blog.echen.me/lstm-explorer/#/network?file=selective_counter
We hope to find a counting neuron that has an input gate of 0 when encountering X.

The above is the cell state of neuron 20. It increases until it reaches the delimiter Y, then decreases until the end of the sequence—just like it is calculating the variable num_bs_left_to_print, constantly changing based on the increment of a and the decrement of b.
Its input gate indeed ignores X:
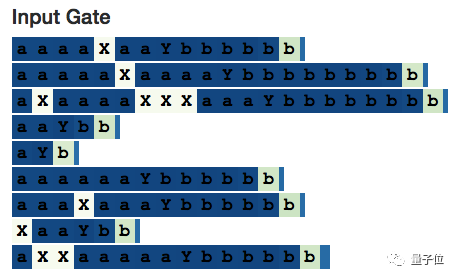
Interestingly, the backup memory is fully activated for the irrelevant delimiter X, so we still need an input gate. (If the input gate were not part of the architecture, the neural network would learn to ignore X in other ways.)
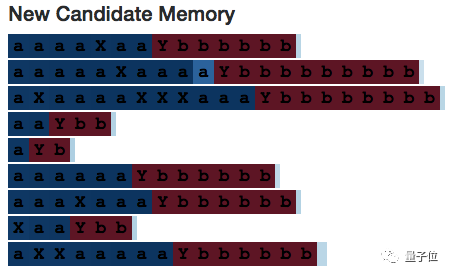
Now let’s continue to look at neuron 10.

This neuron is interesting because it only activates when reading the delimiter Y, but it still tries to encode the a’s seen so far in the sequence. This is hard to see from the figure, but when reading Y belonging to a sequence with the same number of a’s, all the cell states are almost the same. We can see that the fewer a’s in the sequence, the lighter the color of Y.
Remembering States
Next, I want to see how LSTM remembers cell states. I generated some sequences again:
AxxxxxxYa
BxxxxxxYb
In this sequence, A or B can be followed by 1-10 x’s, then a delimiter Y, and finally a lowercase letter corresponding to the initial letter. This neural network needs to remember whether the sequence is an A or B sequence state.
We hope to find a neuron that triggers when remembering this sequence starts with A, and another neuron that triggers when remembering it starts with B. And we did find them.
For example, here is a neuron A that activates when it reads an A and remembers it until it needs to generate the final character. Note that the input gate ignores all the x’s in between.
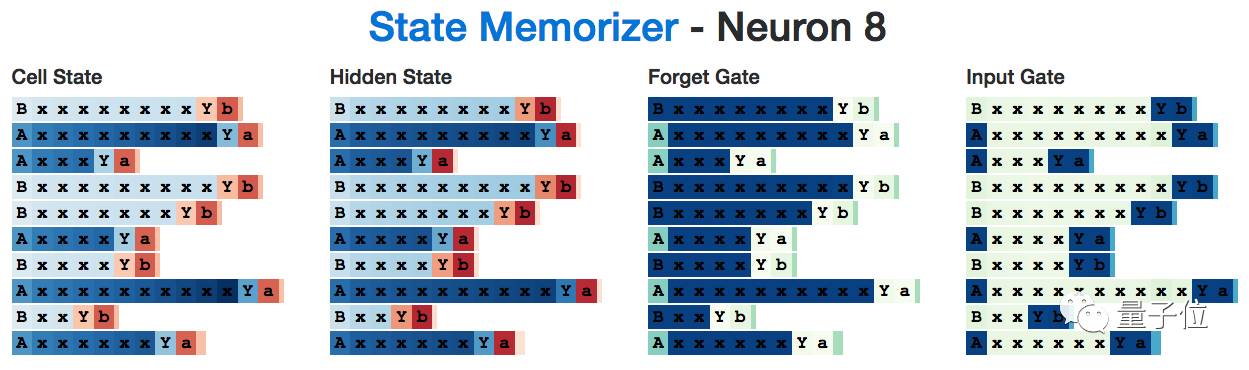
Here is a copy B:
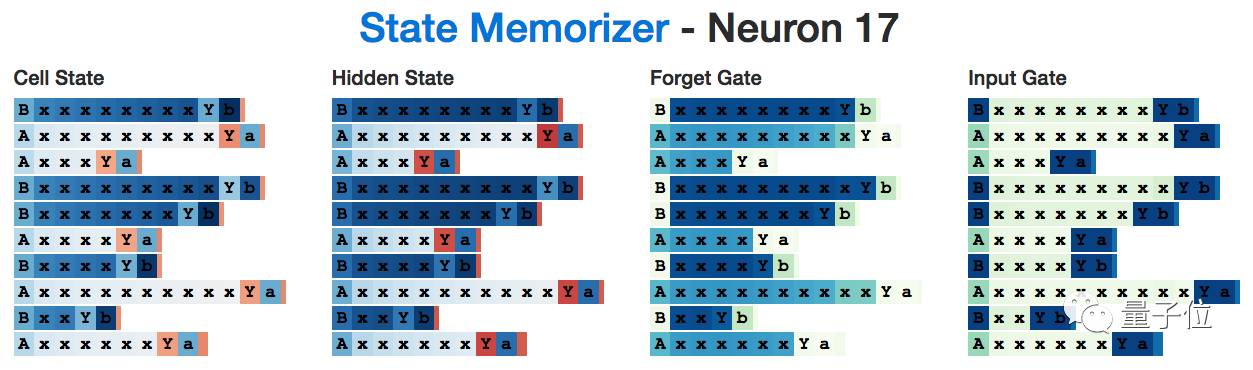
Interestingly, the state information for A and B does not need to be retained until the network reads the delimiter Y, but the hidden state still triggers on all intermediate inputs. This seems a bit “inefficient”, but perhaps it’s because this neuron also takes on the task of calculating the number of x’s.
Copying Tasks
Finally, let’s see how LSTM copies information.
For this training task, I trained two layers of LSTM sequences:
baaXbaa
abcXabc
That is, this is a subsequence composed of three characters a, b, c followed by a delimiter X, and finally followed by an identical sequence.
I am not sure what the copying neuron looks like, so to figure out the neurons that store the initial subsequence part when reading the delimiter X, I looked at their hidden states. Since the network needs to encode the initial subsequence, its state should show different formats based on what it has learned.
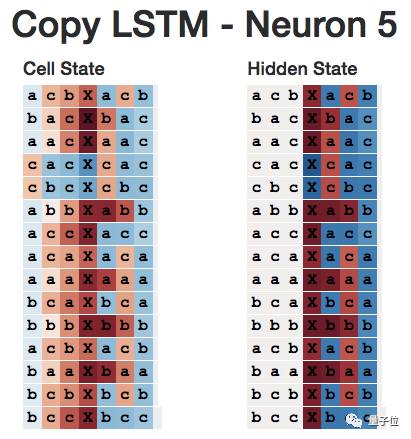
For example, the following chart shows the hidden state of neuron 5 when reading the delimiter X. The neuron can clearly distinguish whether the sequence starts with “c”.
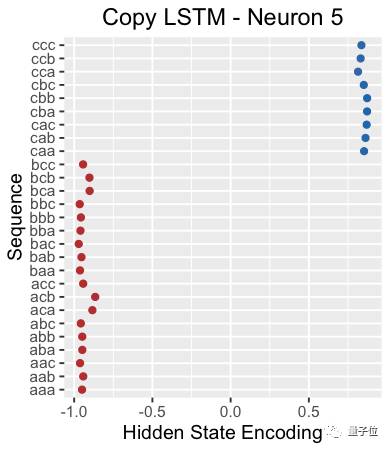
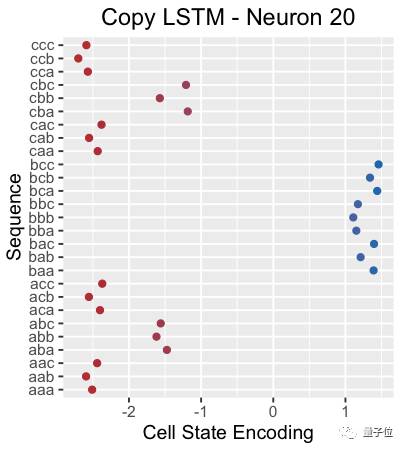
Another example is shown below, where the hidden state of neuron 20 when reading X seems to have picked out sequences starting with b.
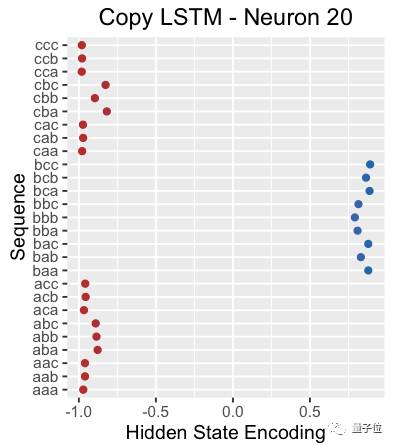
If you observe the cell state of neuron 20, you will find that it can almost independently capture the entire subsequence of three characters. Doing this in only one dimension is quite remarkable.
This is the hidden state of neuron 20 throughout the sequence. Note that its hidden state has been cut off in the entire initial subsequence.
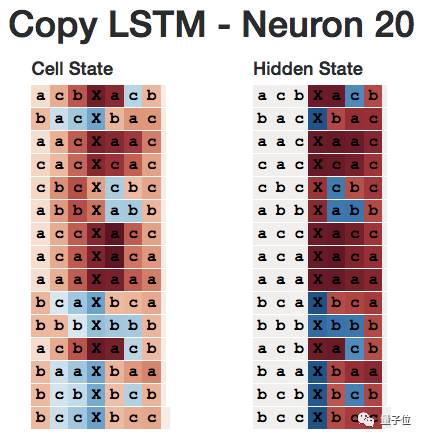
However, if we look closely, we find that the neuron is triggered every time the next character is b. Therefore, rather than saying this neuron represents a sequence starting with b, it is more accurate to say it is a predictor of the next character being b.
To my knowledge, this pattern seems to hold throughout the entire network—all neurons predict the next character rather than remember characters at specific positions. For example, neuron 5 seems to be the predictor for “the next character is c”.
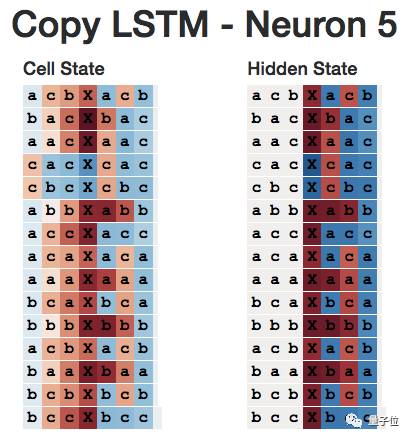
I am not sure if this is the default behavior learned by LSTM when copying information, or if other copying mechanisms do the same.
States and Gates
To truly understand the roles of different states and gates in LSTM, let’s retell the previous section from a different angle.
Cell State and Hidden State
Initially, we described the cell state as a form of long-term memory, while the hidden state is a method to extract and focus these memories.
So when the memory is irrelevant to the current context, we expect the hidden state to shut down—just like the sequence copying neurons we discussed earlier.
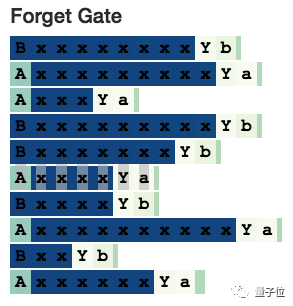
Forget Gate
The forget gate (Forget Gate) discards information from the cell state (0 means completely forget, 1 means completely remember), so we expect it to be fully activated when it needs to remember something specific; when that information is no longer needed, it can be shut down again.
This is what we see with this A memory neuron: the forget gate remembers the A state when it passes through x, and shuts down when it is ready to generate the final a.
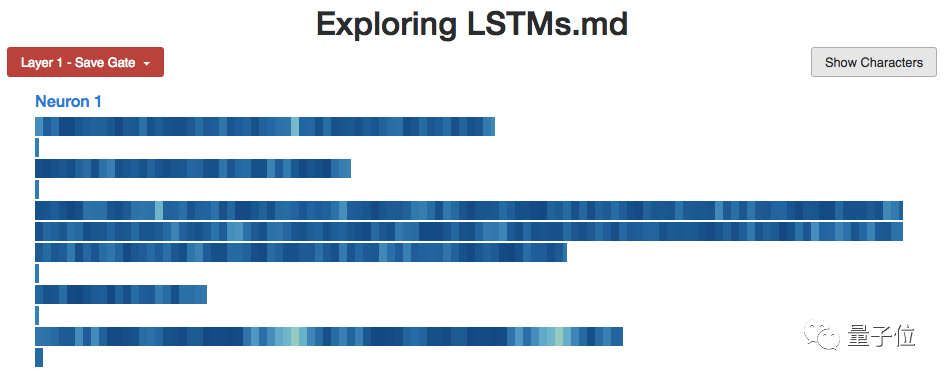
Input Gate (Save Gate)
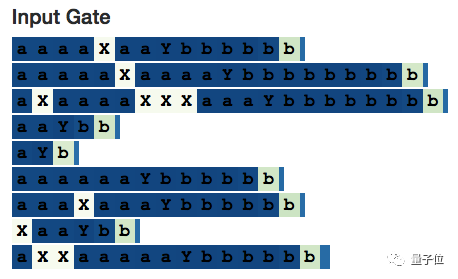
The input gate (Input Gate, which I previously called the “save gate”) determines whether to save information from new inputs. Therefore, it needs to close when encountering useless information.
This is what the selective counting neurons do: calculate the values of a and b, but ignore the irrelevant x’s.
Surprisingly, nowhere in our LSTM equations do we specify how the input, forget, and output gates function; the neural network learns on its own what is best.
Extensions
Now let’s explore how LSTM came about.
First, many of the problems we want to solve are arranged in a time sequence or a certain order, and we can integrate past experiences into our models. However, we already know that the hidden layers of neural networks encode important information, so why not use these hidden layers as memory passed from one time step to another? Thus, Recurrent Neural Networks (RNNs) emerged.
Humans do not easily believe information—when we read an article about politics, we do not immediately believe what we read and take it as our life belief. We choose which information is worth remembering, which information needs to be discarded, and which information can provide some decision-making basis for next reading. In other words, we want to learn how to collect, correct, and apply information. So why not let neural networks learn this? Thus, LSTM was born.
The tasks are all completed, and now we can modify it.
You might think it’s silly for LSTM to distinguish between long-term memory and working memory: why not combine them into one? Or perhaps you find the independent memory gate and storage gate a bit redundant. Now there is a new variant of LSTM proposed, which we call GRU (Gated Recurrent Units).
Want to learn more about GRU? Here is a paper:https://arxiv.org/abs/1412.3555
When deciding memory storage and focusing on which information, we cannot rely solely on working memory, so why not use long-term memory? Thus, we discovered Peephole LSTM.
Peephole LSTM Paper (PDF):http://machinelearning.wustl.edu/mlpapers/paper_files/GersSS02.pdf
Achieving a Great Revival of Neural Networks
Let’s take a look at the final example, where my two-layer LSTM was trained on Trump’s tweets. Despite the dataset being “large”, it still learned many patterns.
For instance, here is a neuron that records hashtags, URLs, and @ mentions.

Here is a named entity detector (note: it does not only activate when encountering capital letters):

This is an auxiliary verb + “to be” detector (including forms like “will be”, “I’ve always been”, “has never been”, etc.):

This is a citation attribute:

And here is a MAGA (Multi-Agent Genetic Algorithm) and capital letter neuron:

Below is the LSTM-generated statement on Trump’s tweets—only one of them is true, so feel free to guess which one:
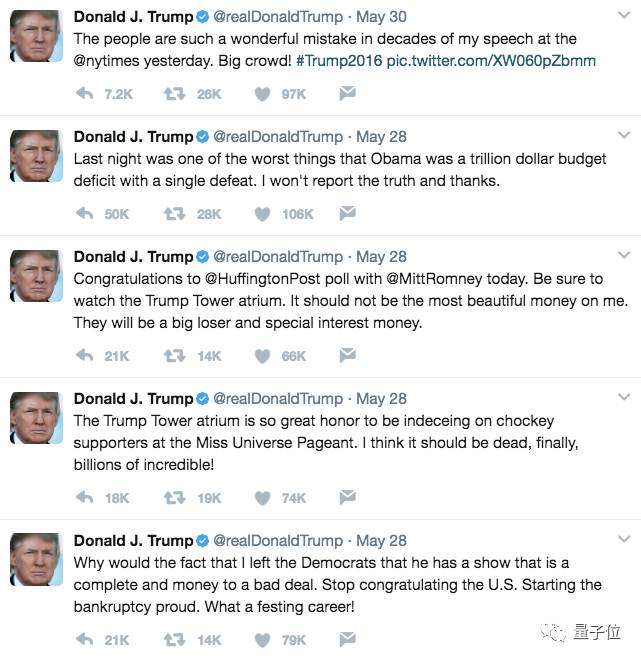
The Trump dataset is here: https://www.kaggle.com/benhamner/clinton-trump-tweets
Conclusion
This article is drawing to a close. Before we finish, let’s review what you have gained:
You need to remember:
Although this article is lengthy and covers a lot of content, LSTM remains a limitless research field. If you happen to be interested in LSTM, dive in and study it well.
[End]
Recommended Learning
On June 15, QbitAI organized a salon, inviting Dr. Wang Naiyan, the chief scientist of Tucson, to share topics related to autonomous driving. Everyone is welcome to scan the QR code below to sign up~

One More Thing…
What else in the AI field is worth paying attention to today? Reply “today” in the QbitAI WeChat official account dialogue interface to see the AI industry and research dynamics we have gathered from across the internet. Love ya~

△ Scan to force follow ‘Qbit’
Track the most exciting content in the field of artificial intelligence