
Previously, I introduced Recurrent Neural Networks (RNNs), which are fascinating because they can effectively utilize historical information. For instance, using the previous video frame to infer the current video content. In earlier articles, we also discussed that traditional RNNs cannot learn connections that are too far apart in time.
Sometimes, we only need the previous moment’s information to complete the current task, such as a language model that predicts the next word based on the context. If we try to predict the last word of “The clouds are in the sky,” we don’t need much context; it’s clear that the last word should be “sky.” In this scenario, the relevant information is close together, and RNNs can learn to use prior information.
However, many scenarios require a significant amount of contextual information to complete the current task. Take the same language model; if we try to predict the last word of “I grew up in France….I speak fluent French,” the current information suggests that the last word is a language, but to know which language, we need to refer to “France” from earlier, which is far away. In reality, it is very likely that the relevant information is far from the current prediction position.

Unfortunately, RNNs cannot learn connections that are too far apart, a problem known as the long-term dependency issue. Bengio and others have conducted in-depth research on this problem, which makes training RNNs difficult due to gradient vanishing.
In essence, the gradient vanishing problem is caused by using the Backpropagation algorithm, where the derivative of the activation function is less than 1. When using RNNs, during each input optimization calculation, the focus is on considering the most recent inputs, which reduces loss, while distant inputs become irrelevant for calculating the current input’s gradient. RNNs can be seen as adjusting parameters to fit recent sequences; for example, when inputting at time t, the current parameters may be adjusted to fit the sequence from t to t-p, where p is relatively small. Thus, RNNs do not account for inputs from long ago and cannot learn long-distance information.
The LSTM model alleviates the gradient vanishing problem and can model sequences of arbitrary lengths.
“Long-Short-Term-Memory networks,” abbreviated as “LSTMs,” are a special type of RNN model that can learn to connect long-distance information. LSTMs were proposed by Hochreiter & Schmidhuber (1997) and were improved and popularized by Alex Graves. LSTMs perform excellently on many problems and have wide applications.
LSTMs are inherently designed to learn to connect long-distance information; this is their default behavior rather than a capability that requires effort to achieve. (Suddenly, I feel that these designed models are quite similar to us humans. Some people are called geniuses; their abilities are unattainable even with countless efforts by ordinary people…)
All RNNs have a chain-like structure of repeated neural network modules, and in standard RNNs, this module has a very simple structure, such as a single tanh layer.
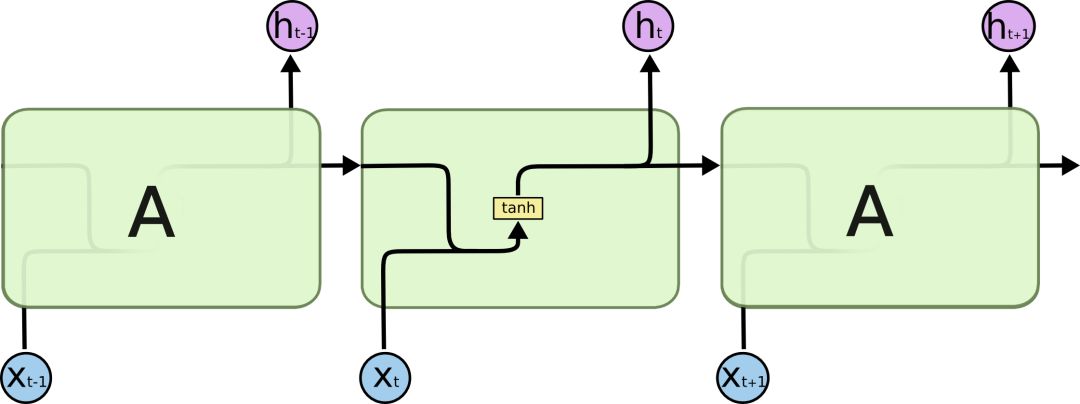
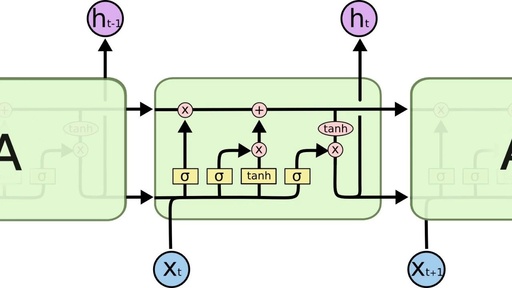
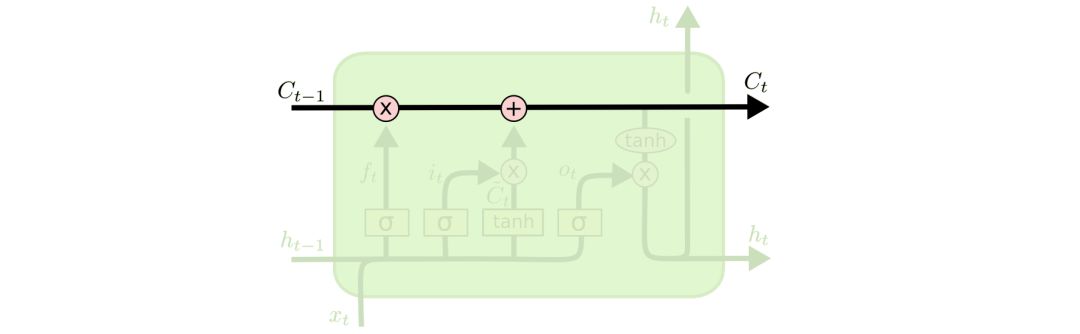
LSTMs also have this chain structure, but the structure of the repeated module is different. It is not a single neural network layer but four, interacting in a special way.
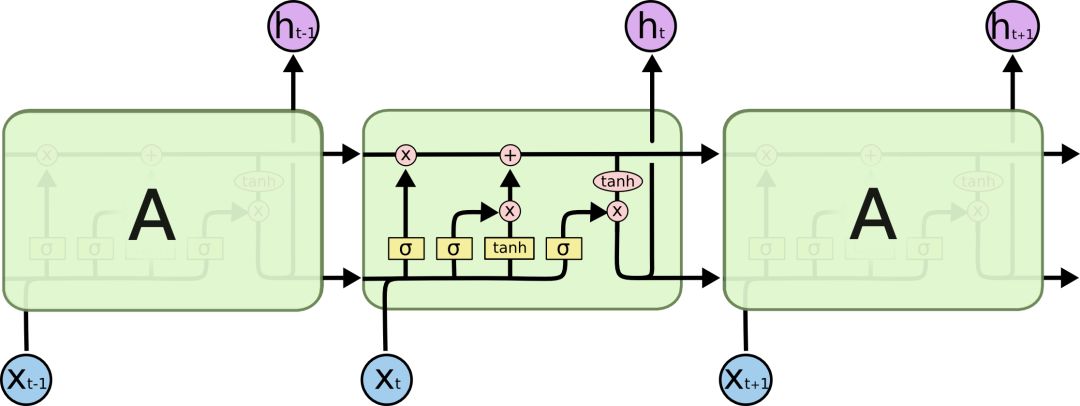
It may seem complex; don’t worry about the details; we will analyze LSTMs step by step. First, let’s understand the icons in the article.
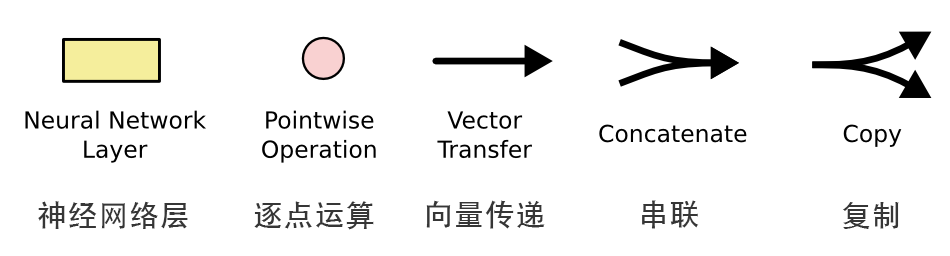
In the above diagram, each black line transmits a complete vector from the output of one node to the input of other nodes. The pink circles represent point-wise operations, such as the sum of vectors, while the yellow rectangles represent learned neural network layers. Combined lines indicate vector connections, while separated lines indicate that content is copied and distributed to different locations.
The key to LSTM is the cell state, which is the horizontal line running across the top of the diagram. This is akin to a conveyor belt, where information moves along the entire chain with only minor linear interactions, allowing information to be retained effectively.
LSTMs have a carefully designed structure called gates, which can be used to delete or add information to the cell. It is a method that allows information to pass selectively, consisting of a sigmoid neural network layer and point-wise operations.
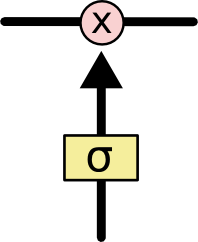
The sigmoid layer outputs a number between 0 and 1, describing how much of each component can pass through. A value of 0 means no amount can pass, while 1 means any amount can pass. LSTMs have three such gates to protect and control the cell state.
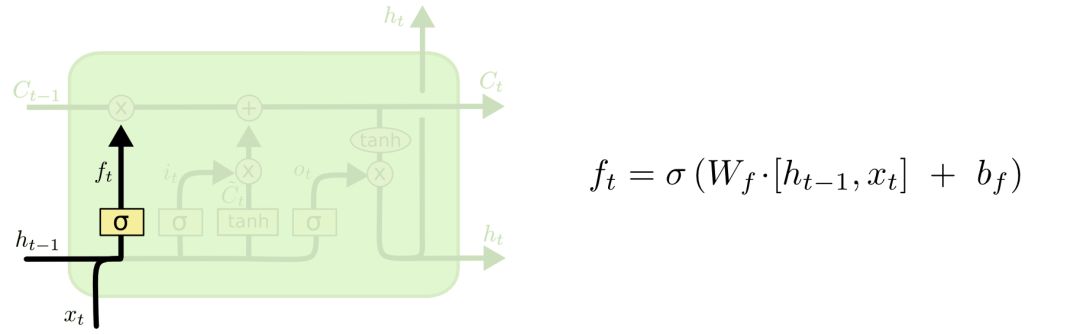
In LSTMs, the first step is to decide what information to discard from the cell, determined by the forget gate. This gate reads ht−1 and xt, passing through a sigmoid layer to determine how much of the previous information Ct-1 to retain. A value of “1” means completely retain, while “0” means completely discard.
Let’s return to the language model predicting the next word. In this case, the cell state may contain attributes of the current subject so that the correct pronoun can be used. However, when a new subject appears, we want to forget the attributes of the previous subject.
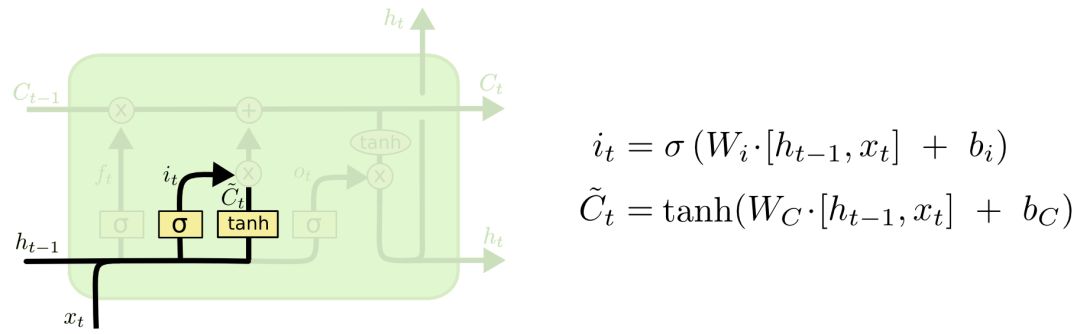
The next step is to consider what new information to store in the cell. This requires two steps: first, an input gate decides what value to update. Then, the tanh layer creates a new candidate value vector C̃ t and adds it to the state. Next, we will combine the two to create a state update.
In the language model, the attributes of the new subject are added to the state to replace those of the old subject.
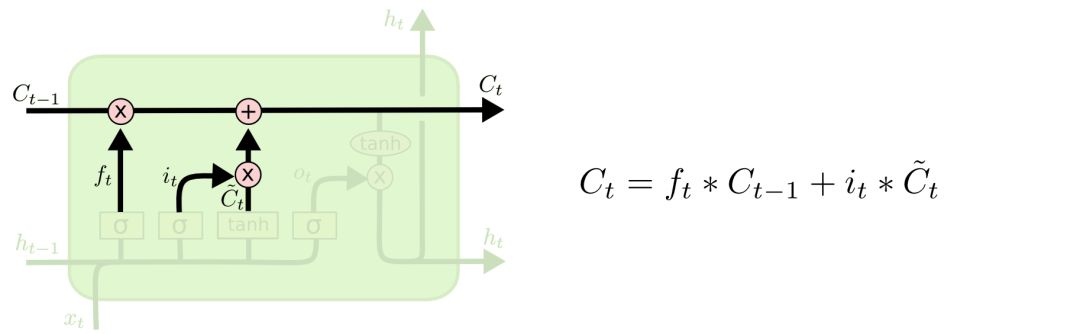
Update the old cell state Ct−1 to the new cell state Ct. Multiply the old state by ft to discard the information we want to forget, then add it to it∗C̃ t, which is the new candidate value, varying based on how much we decide to update each state.
In the language model, this is where we discard the attributes of the old pronoun and add new information.
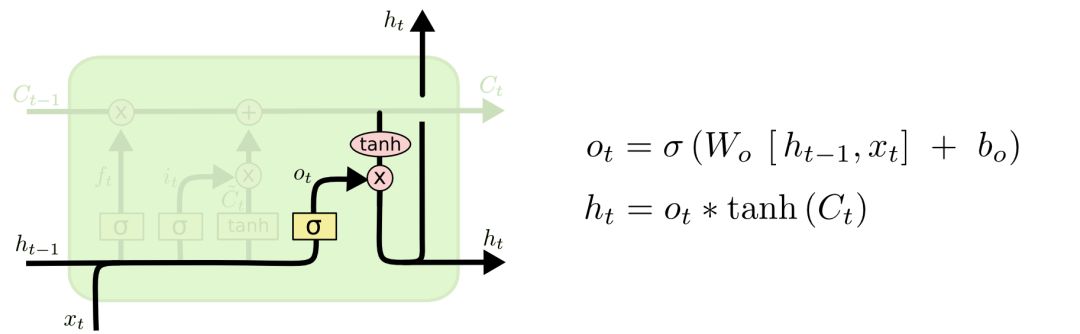
Finally, we need to determine what value to output. This output will be based on the cell state but filtered. First, through an output gate, it decides which part of the cell state to output. Then, we process the cell state through tanh (resulting in a value between -1 and 1) and multiply it by the output of the output gate, ultimately outputting only the part we determined.
In the language model example, since the model has only seen a pronoun, it may need to output information related to a verb. For instance, the output pronoun may indicate whether it is singular or plural, so if we output a verb, we also know what grammatical changes need to be made.
LSTM is a significant success in RNN research. Naturally, researchers also consider: where could there be even more significant breakthroughs? Currently, cutting-edge research is focused on “attention.” This concept allows each step of RNNs to pick information from a larger pool. For example, if you use RNNs to generate a description of an image, it might select a portion of the image and generate output words based on that information. In fact, Xu, et al. (2015) have already done this—if you want to delve deeper into attention, this could be an interesting starting point! There are also some exciting research results using attention, indicating that there is still much to explore…
