This series is organized based on the guest sharing at the Create 2024 Baidu AI Developer Conference “Large Models and Deep Learning Technology Forum”. This article is compiled from the keynote speech by Baidu’s outstanding architect Hu Xiaoguang – “Evolution of PaddlePaddle Framework Architecture and Core Technologies”.
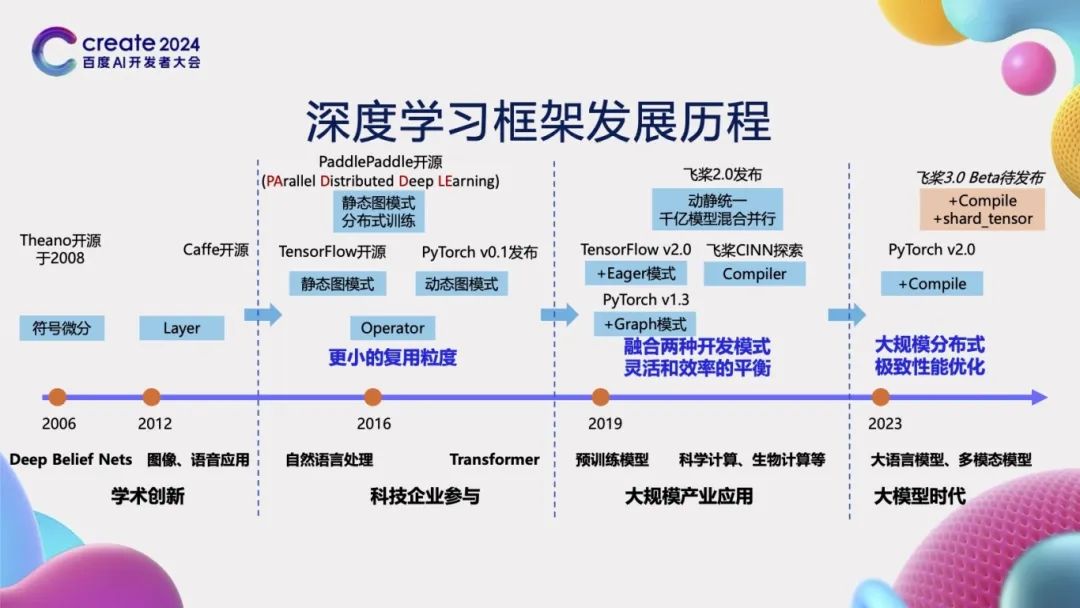
Development History of Deep Learning Frameworks
In the early stages of artificial intelligence development, model structures were relatively simple, and there was no need for deep learning frameworks, which could be implemented directly through handwritten code. However, as the complexity of models gradually increased, deep learning frameworks became crucial. For instance, frameworks such as Theano, which was open-sourced in 2008, and Caffe, launched in 2013, provided strong support for building complex models. In the early stages of framework development, the basic unit granularity used was relatively large. For example, in Caffe, the Layer was the basic unit, requiring developers to manually write the forward and backward logic of the Layer, making operations challenging.
Since 2015, more and more tech companies have invested in the research and development of deep learning frameworks and launched new frameworks. For example, Google’s TensorFlow in 2015, Baidu’s PaddlePaddle in 2016, and Facebook’s PyTorch in 2017 were successively open-sourced. These frameworks, with their advanced design concepts, introduced Operators and more fine-grained reusable units – operators, allowing for the construction of more complex neural network structures through flexible combinations of these operators, thus significantly improving development efficiency. Since its open-source inception, PaddlePaddle has been dedicated to serving industrial practices and supporting large-scale distributed training. Its name “PaddlePaddle” is an abbreviation for “PArallel Distributed Deep LEarning”, reflecting its design philosophy.
By 2019, TensorFlow 2.0 introduced the Eager mode, while PyTorch 1.3 added the Graph mode, marking the beginning of the integration of dynamic graphs and static graphs in deep learning frameworks. By early 2021, PaddlePaddle released version 2.0, further integrating the flexibility of dynamic graphs with the efficiency of static graphs, while also supporting the mixed parallel training of models with hundreds of billions of parameters. At the same time, PaddlePaddle also embarked on the exploration of neural network compiler technology CINN (Compiler Infrastructure for Neural Networks).
With the arrival of the large model era, the scale of model parameters has continuously increased, and training costs have also risen, posing higher demands on deep learning frameworks for large-scale distributed training and performance optimization. Therefore, in 2023, PyTorch released version 2.0, focusing on improving model running speed through the introduction of a Compile mechanism. PaddlePaddle is also set to launch version 3.0 Beta in June, with key features including compiler performance optimization technology and tensor-splitting-based distributed automatic parallel technology to address new challenges in the current deep learning field.
Deep Learning Frameworks in the Era of Large Models
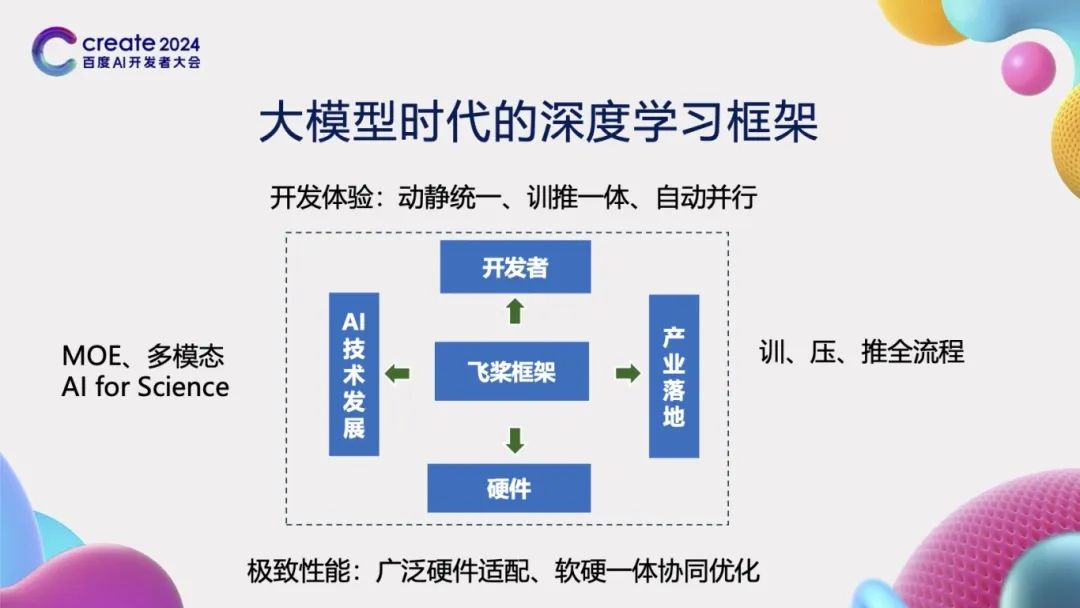
In the era of large models, the design of deep learning frameworks is crucial for advancing artificial intelligence technology. This can be considered from the following four aspects:
First, the framework should connect to the needs of developers. An excellent deep learning framework should provide an exceptional development experience. This not only means offering a user-friendly development environment but also significantly reducing the learning and time costs for developers while greatly enhancing the convenience of development. To this end, the PaddlePaddle framework innovatively proposes the advanced concept of “unified dynamic and static, integrated training and inference, and automatic parallelism”, greatly improving development efficiency.
Secondly, the framework should connect to hardware. Modern deep learning applications often need to run on diverse hardware platforms, so the framework must be compatible with various hardware devices. This requires the framework to intelligently isolate the differences between different hardware interfaces, achieving broad hardware adaptability. Additionally, to fully leverage hardware performance, the framework needs to be capable of soft and hard collaborative work, ensuring optimal performance when utilizing hardware resources.
Moreover, the framework needs to consider the overall trends in AI technology development. With continuous technological advancements, cutting-edge technologies such as MOE (Mixture of Experts), multimodal, and AI for Science are gradually becoming new research hotspots. Deep learning frameworks should keep pace with these technological developments, providing researchers with the necessary support and tools to promote the rapid development and application of related technologies.
Finally, the framework should support the practical application of industry. In terms of industrialization, the framework needs to have the capability to support a full process from training, compression, to inference. This means that from model training to optimization, and then to actual deployment and inference, the framework should provide a complete and efficient solution to meet the practical needs of the industry for deep learning technology.
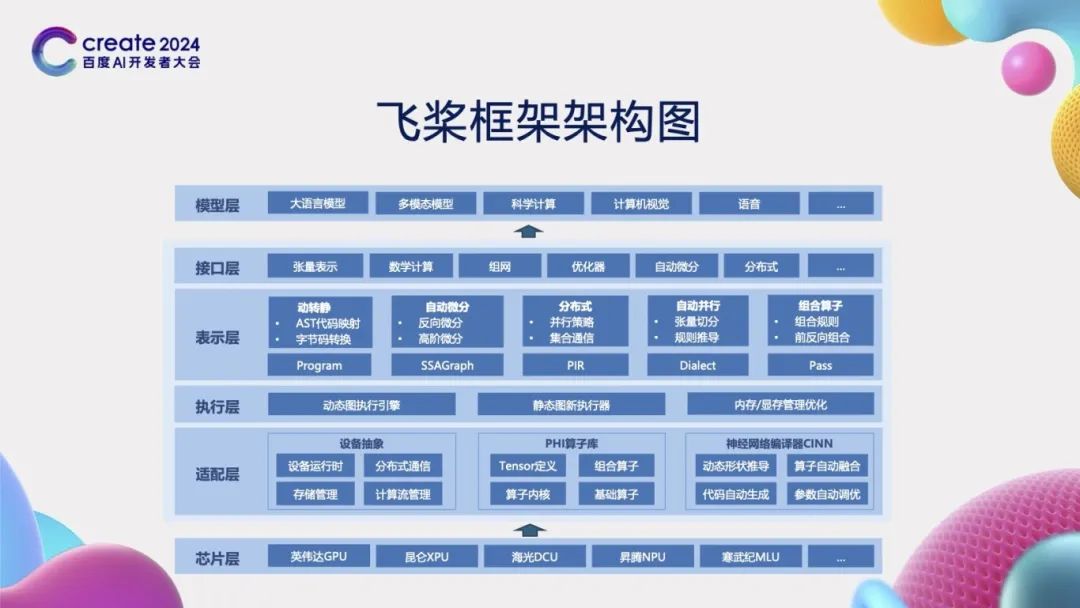
PaddlePaddle Framework Architecture and Core Technologies
To achieve the aforementioned characteristics of the deep learning framework, we must carefully design the framework’s architecture to ensure it can support the construction of various complex models while seamlessly interfacing with diverse chips. The PaddlePaddle framework adopts an advanced layered architecture design, which is divided into the following four layers:
First is the “Interface Layer”, which mainly provides various API interfaces related to deep learning, such as tensor representation, model networking, and optimization strategies. Through these interfaces, developers can conveniently build and train their deep learning models without delving into the underlying technical details.
Next is the “Representation Layer”, which includes several core concept representations, such as Program, SSAGraph, and Paddle Intermediate Representation (PIR). PIR has high flexibility and scalability, capable of achieving various transformations, including dynamic to static graph conversion (dynamic to static), automatic differentiation, distributed training, automatic parallelism, and operator combination optimization. These functions provide strong support for computational optimization of deep learning models.
Then comes the “Execution Layer”, designed to support the execution of dynamic and static graphs, and to optimize memory and storage management based on actual needs. This means that regardless of whether developers choose to use dynamic or static graphs for model development, the PaddlePaddle framework can provide an efficient execution environment while ensuring optimal resource utilization.
Finally, there is the “Adaptation Layer”, which mainly handles interface abstraction and adaptation with hardware devices. This includes the Paddle High Reusability Operator Library (PHI), which provides a series of efficient computation operations to meet the computational needs on different hardware devices. Additionally, the adaptation layer also includes the neural network compiler CINN, enabling efficient execution of deep learning models across various hardware platforms.
Dynamic-Static Conversion Technology
Let’s discuss the two development modes provided by the PaddlePaddle framework: static graph and dynamic graph. Through example code, it can be observed that the code for model networking in these two modes is completely consistent, thus we refer to it as a unified dynamic-static networking method. However, the main differences between them lie in the construction and execution processes of the computation graph. In the static graph development mode, once the computation graph is created, it remains unchanged. This means that regardless of how many batches of data are input, the computation graph will not change. In contrast, in the dynamic graph development mode, every time a new batch of data is input, the computation graph is dynamically generated and executed. This flexibility makes the dynamic graph mode highly popular in modern deep learning tasks. However, despite the many advantages of the dynamic graph mode, it is not without its drawbacks.
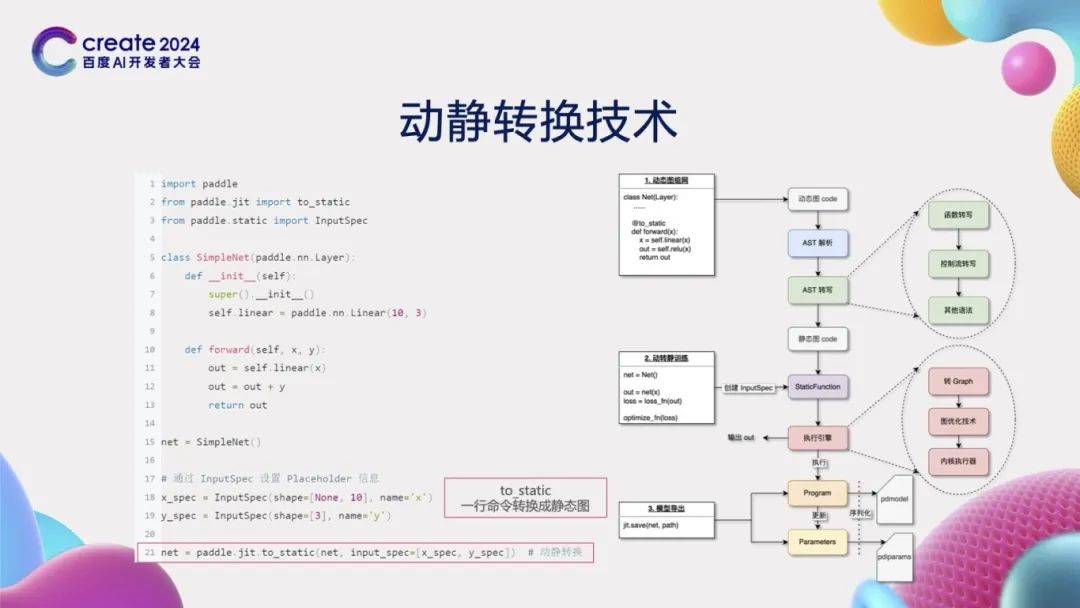 Although the dynamic graph mode is flexible, it has a problem: the computation graph is frequently created and executed, making optimization quite difficult. Particularly in inference deployment scenarios, the dynamic graph mode often struggles to eliminate its dependence on the Python interpreter for deployment. The introduction of the Python interpreter can lead to inefficiencies or even inoperability in certain scenarios, such as resource-constrained edge environments. To overcome this challenge, PaddlePaddle developed dynamic-static conversion technology, allowing for easy conversion of dynamic graph code to static graph code with a simple command (to_static). The technical solution adopted by PaddlePaddle is source-to-source conversion, which involves analyzing and rewriting dynamic graph Python source code to generate the corresponding static graph Python source code; after obtaining the source code, the static Python interpreter is used to execute this static graph code to obtain the representation of the computation graph.
Although the dynamic graph mode is flexible, it has a problem: the computation graph is frequently created and executed, making optimization quite difficult. Particularly in inference deployment scenarios, the dynamic graph mode often struggles to eliminate its dependence on the Python interpreter for deployment. The introduction of the Python interpreter can lead to inefficiencies or even inoperability in certain scenarios, such as resource-constrained edge environments. To overcome this challenge, PaddlePaddle developed dynamic-static conversion technology, allowing for easy conversion of dynamic graph code to static graph code with a simple command (to_static). The technical solution adopted by PaddlePaddle is source-to-source conversion, which involves analyzing and rewriting dynamic graph Python source code to generate the corresponding static graph Python source code; after obtaining the source code, the static Python interpreter is used to execute this static graph code to obtain the representation of the computation graph.
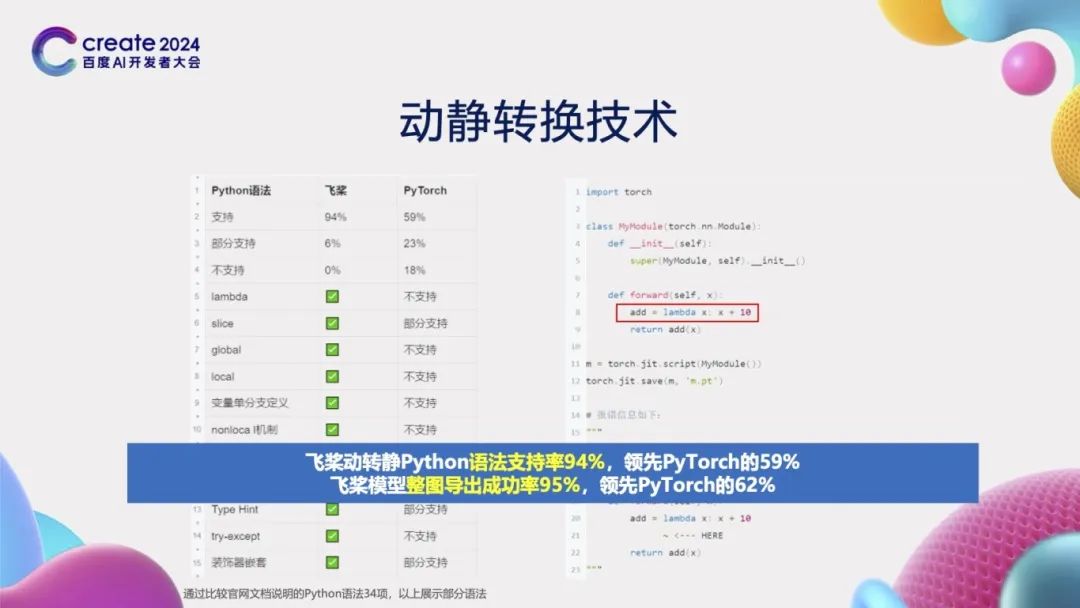 The core challenge of dynamic-static conversion technology lies in the level of support for Python syntax. Through detailed comparisons with official documentation and practical tests, we found that PaddlePaddle achieves a syntax support rate of up to 94%, significantly higher than PyTorch’s TorchScript solution, which only has a support rate of 59%. For instance, the TorchScript solution does not support lambda expressions, which are widely used in Python, while this is well supported in PaddlePaddle. According to our actual tests, PaddlePaddle’s dynamic-static conversion function has a success rate of 95% for whole graph export tasks, far exceeding TorchScript’s 62%. In-depth analysis reveals that the TorchScript solution transforms dynamic graph Python source code into a custom TorchScript source code through source code conversion technology. However, this converted TorchScript code cannot be executed by the Python interpreter. Essentially, the difficulty of converting from Python language to another language is akin to developing an entirely new Python interpreter. In contrast, the advantage of the PaddlePaddle framework lies in its compatibility with both dynamic and static graph development modes. Therefore, during dynamic-static conversion, it only needs to implement the conversion from dynamic graph Python source code to static graph Python source code. This conversion process can further enhance support for Python syntax through the Python interpreter, significantly reducing the implementation difficulty. For this reason, PaddlePaddle far exceeds PyTorch in terms of whole graph export success rates.
The core challenge of dynamic-static conversion technology lies in the level of support for Python syntax. Through detailed comparisons with official documentation and practical tests, we found that PaddlePaddle achieves a syntax support rate of up to 94%, significantly higher than PyTorch’s TorchScript solution, which only has a support rate of 59%. For instance, the TorchScript solution does not support lambda expressions, which are widely used in Python, while this is well supported in PaddlePaddle. According to our actual tests, PaddlePaddle’s dynamic-static conversion function has a success rate of 95% for whole graph export tasks, far exceeding TorchScript’s 62%. In-depth analysis reveals that the TorchScript solution transforms dynamic graph Python source code into a custom TorchScript source code through source code conversion technology. However, this converted TorchScript code cannot be executed by the Python interpreter. Essentially, the difficulty of converting from Python language to another language is akin to developing an entirely new Python interpreter. In contrast, the advantage of the PaddlePaddle framework lies in its compatibility with both dynamic and static graph development modes. Therefore, during dynamic-static conversion, it only needs to implement the conversion from dynamic graph Python source code to static graph Python source code. This conversion process can further enhance support for Python syntax through the Python interpreter, significantly reducing the implementation difficulty. For this reason, PaddlePaddle far exceeds PyTorch in terms of whole graph export success rates.
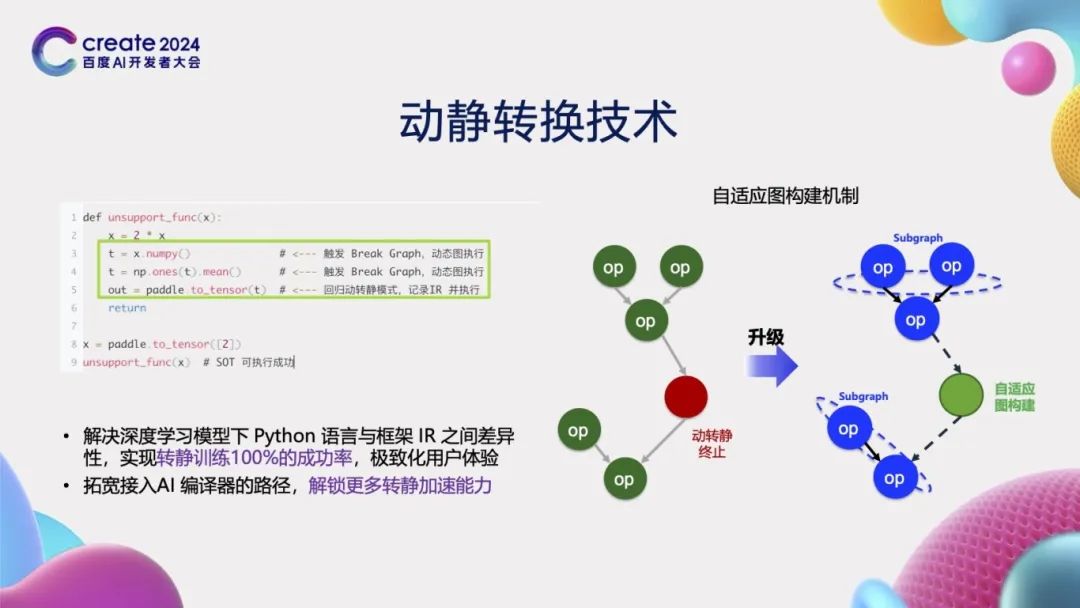 In training scenarios, for cases where dynamic-static conversion cannot be performed, such as when calling third-party libraries like numpy in Python code, these function calls cannot be directly converted to static graph representations. To address this issue, PaddlePaddle innovatively developed an “adaptive graph construction mechanism”. When unsupported syntax is encountered, this mechanism is triggered to automatically disconnect these parts and reconstruct them using adjacent graphs. By adopting this approach, we can achieve a 100% success rate in dynamic-static conversion in training scenarios, thereby providing broader space for optimization technologies such as compilers.
In training scenarios, for cases where dynamic-static conversion cannot be performed, such as when calling third-party libraries like numpy in Python code, these function calls cannot be directly converted to static graph representations. To address this issue, PaddlePaddle innovatively developed an “adaptive graph construction mechanism”. When unsupported syntax is encountered, this mechanism is triggered to automatically disconnect these parts and reconstruct them using adjacent graphs. By adopting this approach, we can achieve a 100% success rate in dynamic-static conversion in training scenarios, thereby providing broader space for optimization technologies such as compilers.
High-Scalability Intermediate Representation PIR
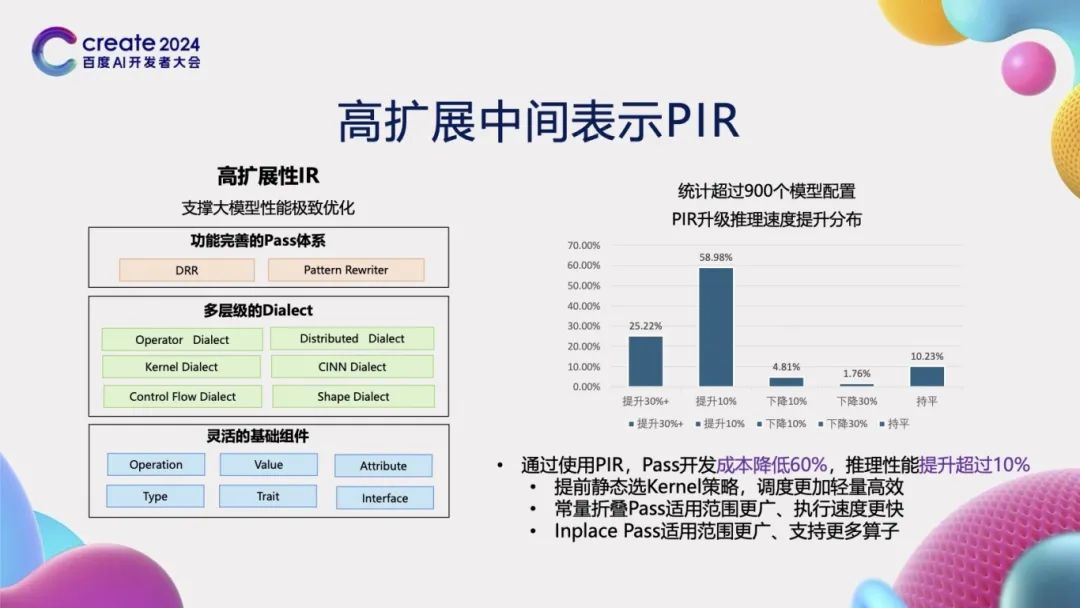
After obtaining the computation graph representation through dynamic-static conversion technology, we still need to conduct a series of optimizations on the computation graph, such as automatic differentiation transformations, distributed transformations, and compiler acceleration. To achieve these optimizations, we need a “high-scalability intermediate representation” – PIR (Paddle Intermediate Representation). PIR has flexible basic components that support the definition of elements such as Operation, Value, and Attribute, facilitating expansion. Among them, the Dialect definition is a core component of PIR, akin to an expression in formal languages, capable of representing a relatively complete system. This system encompasses various aspects, including distribution, compilers, dynamic shape inference, and control flow. Based on this representation, we also need to utilize Pass for transformations. To this end, PIR provides two mechanisms, DRR and Pattern Rewriter, to achieve flexible changes in IR. To verify the effectiveness of PIR, we compared the inference speed improvement of over 900 model configurations after using PIR. The results showed that 25% of models improved inference speed by over 30%, and 60% of models improved by over 10%. Overall, using PIR improved inference performance by over 10%. This significant improvement is primarily due to the new PIR’s ability to statically select Kernels in advance, reducing scheduling costs and overhead. Additionally, the application scope of constant folding strategies has expanded, and the Inplace Pass strategy mechanism has been more widely applied. With the new PIR representation mechanism, we can achieve integrated training and inference, showcasing excellent performance and results.
 High-Order Automatic Differentiation
High-Order Automatic Differentiation
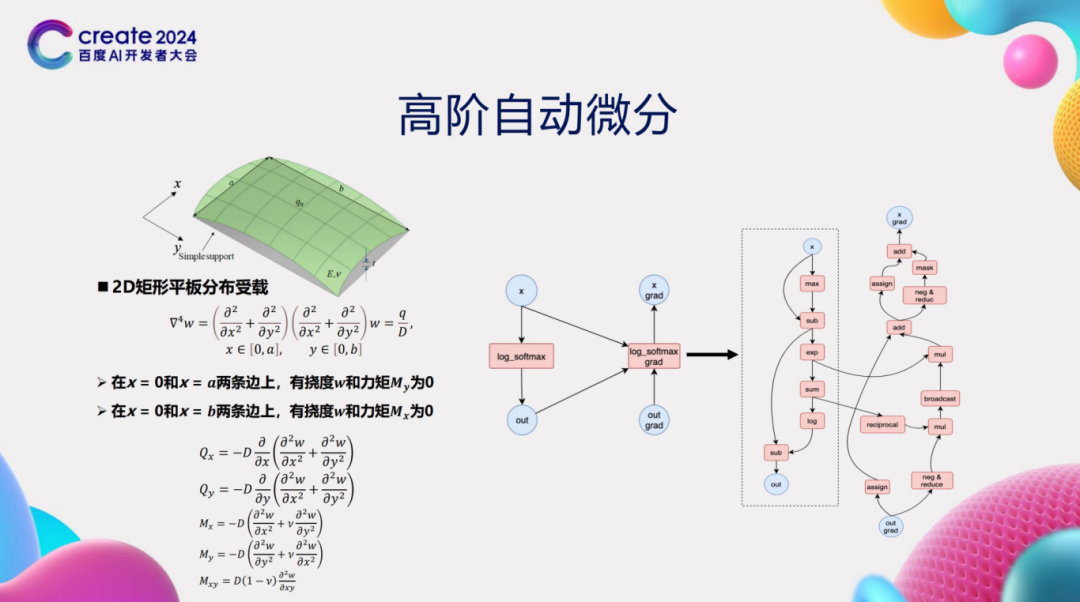 The training process of deep learning models involves using optimization algorithms like stochastic gradient descent (SGD) to update model parameters. In this process, the automatic differentiation function of the deep learning framework plays a core role, automatically calculating the gradient of the loss function with respect to model parameters using the chain rule. Although most deep learning tasks only require the computation of first derivatives, in certain AI for Science scenarios, high-order derivatives need to be calculated, which undoubtedly increases the complexity of automatic differentiation. Taking the problem of 2D rectangular plate distribution under load as an example, its inherent mechanics need to be described using fourth-order differential equations. Therefore, to solve such problems, deep learning frameworks must support high-order automatic differentiation capabilities. However, implementing high-order automatic differentiation faces many challenges. Specifically, the framework needs to write high-order differentiation rules for each operator. As the order increases, the complexity of these differentiation rules also rises. When the order reaches three or higher, writing these rules becomes extremely difficult, and correctness becomes hard to guarantee. To address this issue, we propose a high-order automatic differentiation technique based on the combination of basic operators. The key to this technique is to decompose complex operators (like log_softmax) into combinations of multiple basic operators. We then perform first-order automatic differentiation transformations on these basic operators. Importantly, after the first-order automatic differentiation transformation, the resulting computation graph is still composed of basic operators. By repeatedly applying first-order automatic differentiation rules, we can easily obtain high-order automatic differentiation results.
The training process of deep learning models involves using optimization algorithms like stochastic gradient descent (SGD) to update model parameters. In this process, the automatic differentiation function of the deep learning framework plays a core role, automatically calculating the gradient of the loss function with respect to model parameters using the chain rule. Although most deep learning tasks only require the computation of first derivatives, in certain AI for Science scenarios, high-order derivatives need to be calculated, which undoubtedly increases the complexity of automatic differentiation. Taking the problem of 2D rectangular plate distribution under load as an example, its inherent mechanics need to be described using fourth-order differential equations. Therefore, to solve such problems, deep learning frameworks must support high-order automatic differentiation capabilities. However, implementing high-order automatic differentiation faces many challenges. Specifically, the framework needs to write high-order differentiation rules for each operator. As the order increases, the complexity of these differentiation rules also rises. When the order reaches three or higher, writing these rules becomes extremely difficult, and correctness becomes hard to guarantee. To address this issue, we propose a high-order automatic differentiation technique based on the combination of basic operators. The key to this technique is to decompose complex operators (like log_softmax) into combinations of multiple basic operators. We then perform first-order automatic differentiation transformations on these basic operators. Importantly, after the first-order automatic differentiation transformation, the resulting computation graph is still composed of basic operators. By repeatedly applying first-order automatic differentiation rules, we can easily obtain high-order automatic differentiation results.
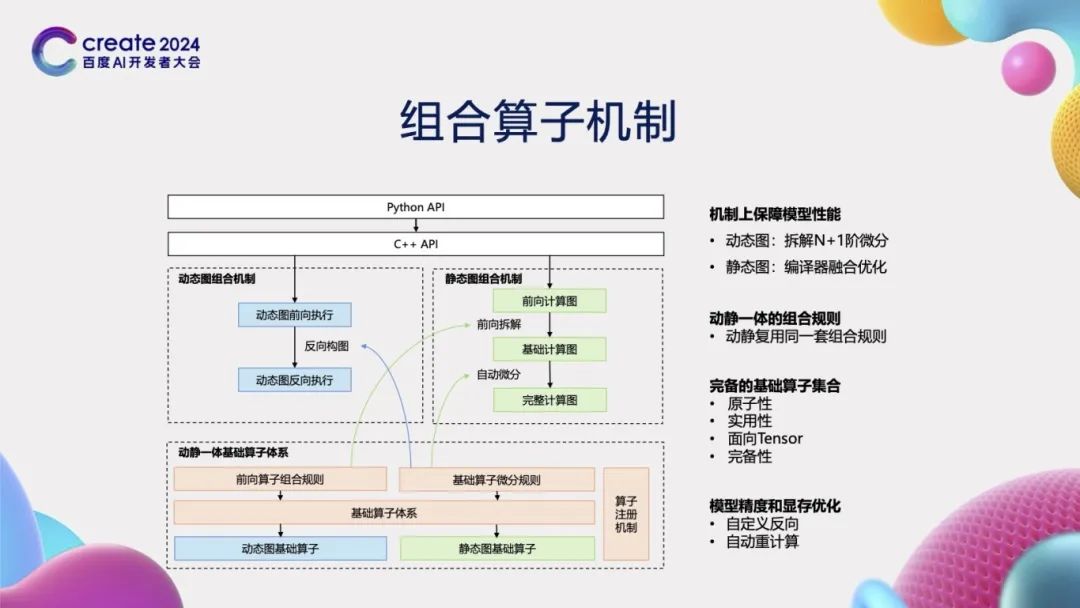 To support high-order automatic differentiation, the PaddlePaddle framework has meticulously designed and implemented a combination operator mechanism. This mechanism not only supports dynamic graph mode and static graph mode but also allows for N+1 order differentiation splits in dynamic graph mode while enabling compiler fusion optimization in static graph mode. We innovatively designed and implemented a unified operator combination rule that can be reused in both dynamic and static graph modes, thereby avoiding redundant development. When constructing the basic operator system, we take Tensor as the core operational object, ensuring the atomicity, practicality, and completeness of the operators. In addition, we support custom reverse operations and automatic recomputation features, which not only enhance model accuracy but also effectively reduce memory usage, providing users with a more efficient and flexible deep learning experience.
To support high-order automatic differentiation, the PaddlePaddle framework has meticulously designed and implemented a combination operator mechanism. This mechanism not only supports dynamic graph mode and static graph mode but also allows for N+1 order differentiation splits in dynamic graph mode while enabling compiler fusion optimization in static graph mode. We innovatively designed and implemented a unified operator combination rule that can be reused in both dynamic and static graph modes, thereby avoiding redundant development. When constructing the basic operator system, we take Tensor as the core operational object, ensuring the atomicity, practicality, and completeness of the operators. In addition, we support custom reverse operations and automatic recomputation features, which not only enhance model accuracy but also effectively reduce memory usage, providing users with a more efficient and flexible deep learning experience.
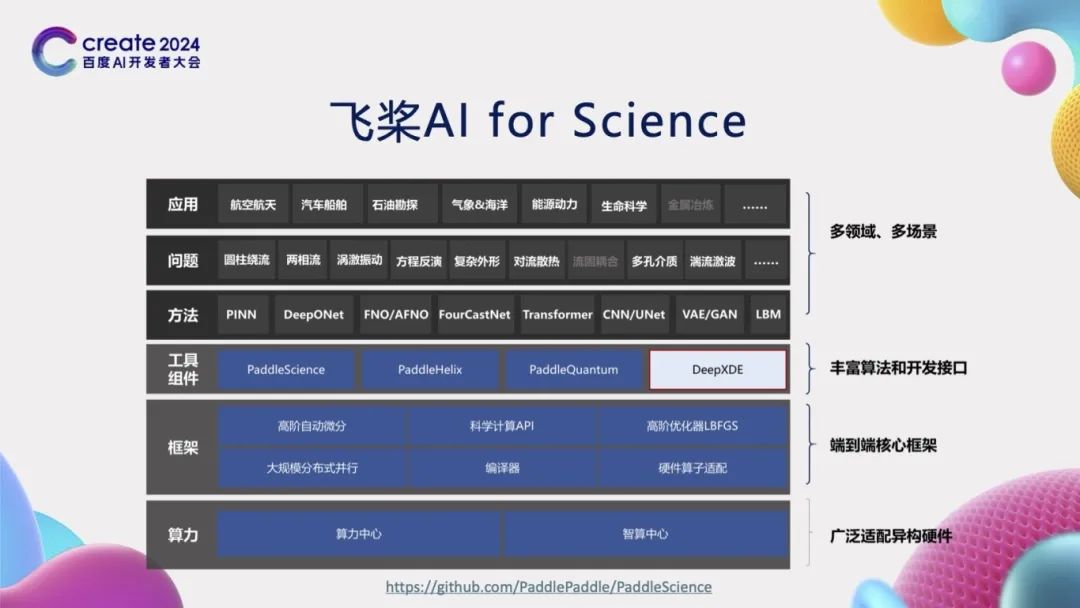 Based on previous work accumulation, PaddlePaddle has begun exploring related work in the field of AI for Science. To meet the various needs of AI for Science tasks, PaddlePaddle has implemented high-order automatic differentiation functions based on combination operators at the framework level, providing dedicated development interfaces for scientific computing, and has also implemented high-order optimizers like LBFGS. At the component level, we have developed series of development kits such as PaddleScience and PaddleHelix, and supported scientific computing libraries like DeepXDE. We have implemented data-driven, mechanism-driven, and data-mechanism fusion methods such as Physics-Informed Neural Networks (PINN) and Fourier Operator Learning (FNO). These methods have broad application potential in various fields including aerospace, automotive, meteorology, and life sciences.
Based on previous work accumulation, PaddlePaddle has begun exploring related work in the field of AI for Science. To meet the various needs of AI for Science tasks, PaddlePaddle has implemented high-order automatic differentiation functions based on combination operators at the framework level, providing dedicated development interfaces for scientific computing, and has also implemented high-order optimizers like LBFGS. At the component level, we have developed series of development kits such as PaddleScience and PaddleHelix, and supported scientific computing libraries like DeepXDE. We have implemented data-driven, mechanism-driven, and data-mechanism fusion methods such as Physics-Informed Neural Networks (PINN) and Fourier Operator Learning (FNO). These methods have broad application potential in various fields including aerospace, automotive, meteorology, and life sciences.
Unified Dynamic-Static Automatic Parallelism
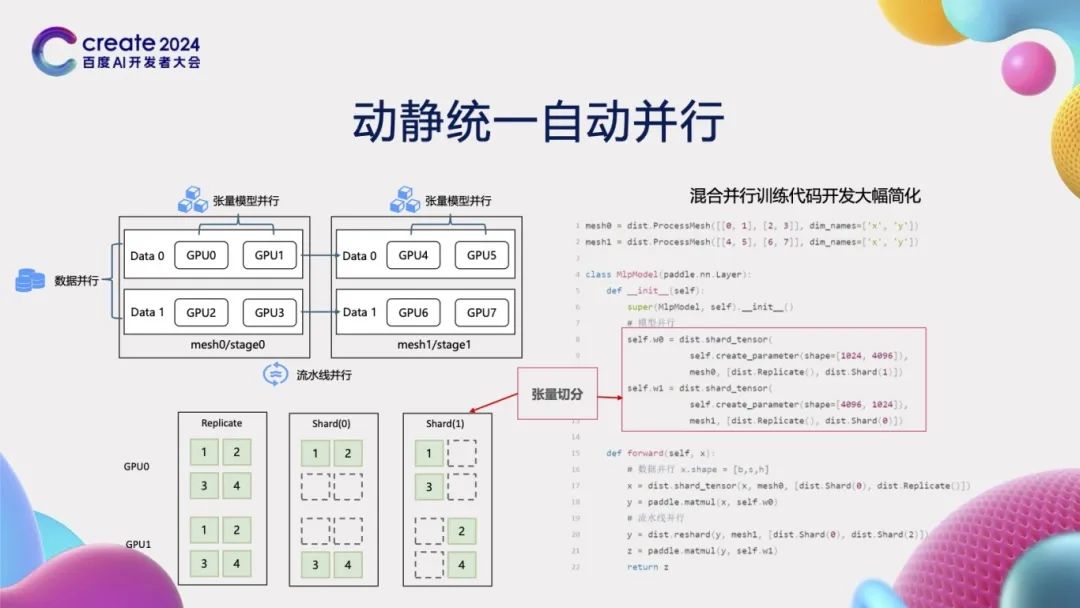 In the large model development scenario, multi-dimensional mixed parallelism is particularly important. However, the development process of multi-dimensional mixed parallelism is often quite complex. For example, with data parallelism, tensor model parallelism, and pipeline parallelism, developers must carefully handle the multifaceted logic of computation, communication, and scheduling to write correct mixed parallel code, undoubtedly increasing development difficulty. To tackle this challenge, we launched a unified dynamic-static automatic parallelism solution. We abstracted different distributed strategies through tensor splitting. As shown in the lower left corner, the different numbers (1, 2, 3, 4) marked on the GPU represent the various elements of the tensor. By clearly specifying the tensor splitting method, we can easily copy or split data between GPUs 0 and 1. As shown in the right-side code, complex parallel strategies can be implemented in just a few lines of code through tensor splitting. Moreover, all cumbersome processes related to communication are automatically handled by the framework, significantly enhancing development efficiency and reducing development difficulty.
In the large model development scenario, multi-dimensional mixed parallelism is particularly important. However, the development process of multi-dimensional mixed parallelism is often quite complex. For example, with data parallelism, tensor model parallelism, and pipeline parallelism, developers must carefully handle the multifaceted logic of computation, communication, and scheduling to write correct mixed parallel code, undoubtedly increasing development difficulty. To tackle this challenge, we launched a unified dynamic-static automatic parallelism solution. We abstracted different distributed strategies through tensor splitting. As shown in the lower left corner, the different numbers (1, 2, 3, 4) marked on the GPU represent the various elements of the tensor. By clearly specifying the tensor splitting method, we can easily copy or split data between GPUs 0 and 1. As shown in the right-side code, complex parallel strategies can be implemented in just a few lines of code through tensor splitting. Moreover, all cumbersome processes related to communication are automatically handled by the framework, significantly enhancing development efficiency and reducing development difficulty.
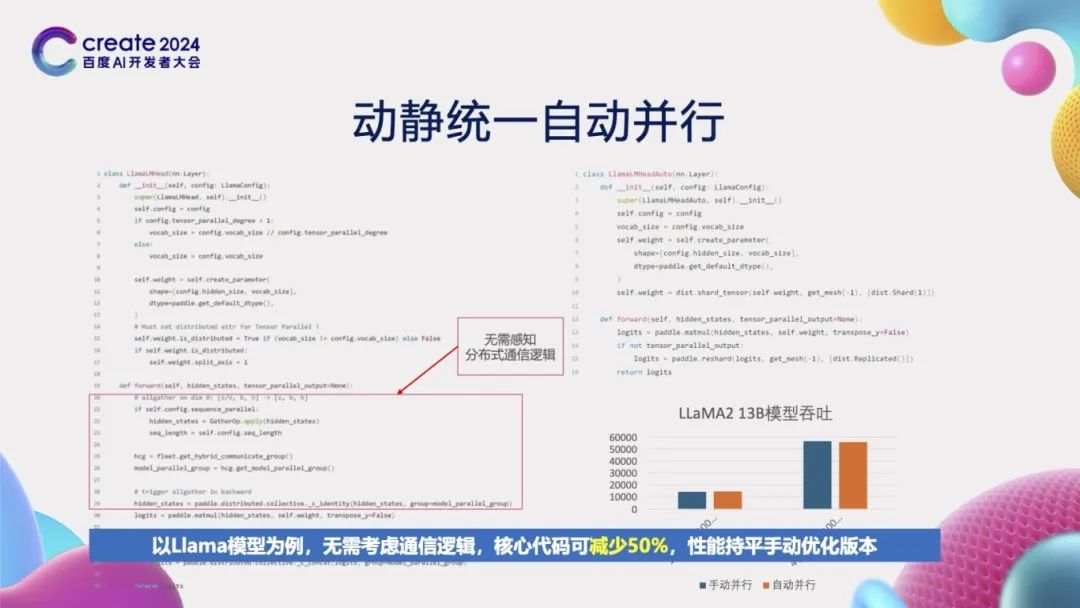 Let’s observe a specific training instance of the llama model. On the left, the manual parallel development method of the dynamic graph is displayed, requiring developers to not only select appropriate parallel strategies but also carefully design communication logic. However, on the right, by adopting the automatic parallel development method, developers no longer need to consider complex communication logic. The advantages of this method are evident: the core code volume is reduced by half, greatly lowering development difficulty; experimental results show that the current performance of this automatic parallelism is comparable to that of manual dynamic graph parallelism, with further improvement potential in the future.
Let’s observe a specific training instance of the llama model. On the left, the manual parallel development method of the dynamic graph is displayed, requiring developers to not only select appropriate parallel strategies but also carefully design communication logic. However, on the right, by adopting the automatic parallel development method, developers no longer need to consider complex communication logic. The advantages of this method are evident: the core code volume is reduced by half, greatly lowering development difficulty; experimental results show that the current performance of this automatic parallelism is comparable to that of manual dynamic graph parallelism, with further improvement potential in the future.

 A key technology in the PaddlePaddle framework is the “deep learning compiler”. So why is it necessary to introduce compiler technology in deep learning frameworks? Let’s illustrate this with an example. Taking RMSNorm, which is frequently used in the LLaMA2 model, as an example, its computation formula is relatively simple and clear. From the code example on the left, it can be seen that the corresponding code is also very intuitive, as it can be composed of basic operators like addition, subtraction, multiplication, and division. However, this method requires independent operator calls for addition and multiplication operations. Operator calls mean that data needs to be copied from the GPU memory to registers for computation, and then copied back to GPU memory after completion, which is very inefficient in memory-intensive computations. Another method is to manually write a large operator, although it runs faster, it has poor flexibility because it becomes a fixed function call, and developers are not aware of its internal implementation, undoubtedly increasing development difficulty. From a performance perspective, the pure operator combination method is the most flexible but the slowest. In contrast, manually written large operators are over four times faster. The application of deep learning compiler technology, however, can achieve significant performance improvements while maintaining flexibility and usability. By using deep learning compiler technology, our speed can increase by 14% compared to the method of manually written large operators, thus finding an ideal balance between flexibility and performance.
A key technology in the PaddlePaddle framework is the “deep learning compiler”. So why is it necessary to introduce compiler technology in deep learning frameworks? Let’s illustrate this with an example. Taking RMSNorm, which is frequently used in the LLaMA2 model, as an example, its computation formula is relatively simple and clear. From the code example on the left, it can be seen that the corresponding code is also very intuitive, as it can be composed of basic operators like addition, subtraction, multiplication, and division. However, this method requires independent operator calls for addition and multiplication operations. Operator calls mean that data needs to be copied from the GPU memory to registers for computation, and then copied back to GPU memory after completion, which is very inefficient in memory-intensive computations. Another method is to manually write a large operator, although it runs faster, it has poor flexibility because it becomes a fixed function call, and developers are not aware of its internal implementation, undoubtedly increasing development difficulty. From a performance perspective, the pure operator combination method is the most flexible but the slowest. In contrast, manually written large operators are over four times faster. The application of deep learning compiler technology, however, can achieve significant performance improvements while maintaining flexibility and usability. By using deep learning compiler technology, our speed can increase by 14% compared to the method of manually written large operators, thus finding an ideal balance between flexibility and performance.
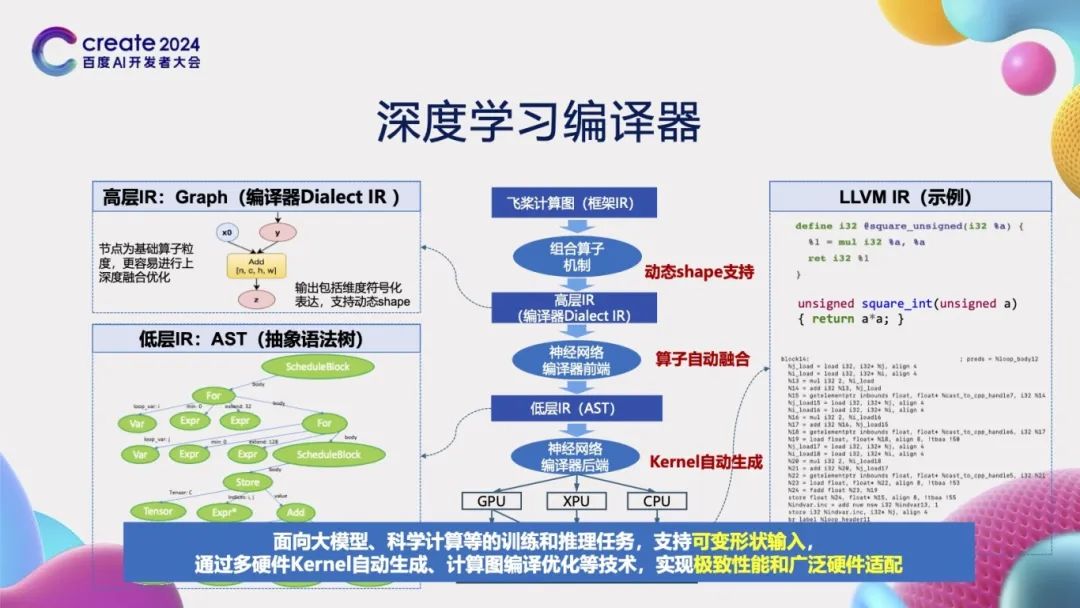
So how can we accelerate deep learning tasks through compilers? The core task of the deep learning compiler is to receive a computation graph as input. First, it uses the operator combination mechanism to decompose this computation graph into a detailed computation graph composed of basic operators, recording the shape relationships between the input and output tensors of the operators in the process to accommodate dynamic shape tensors. Next, through the front end of the neural network compiler, the compiler determines which basic operators can be fused. For the basic operators that can be fused, the compiler calls the basic Compute function to downgrade these operators to a low-level intermediate representation (IR) composed of abstract syntax trees (AST). Then, through the back end of the neural network compiler, these intermediate representations are further transformed into specific code, which may be CUDA C code or LLVM IR code. Finally, using the NVCC compiler or LLVM compiler, these codes are converted into executable code that can run on chips, thus accelerating deep learning tasks.
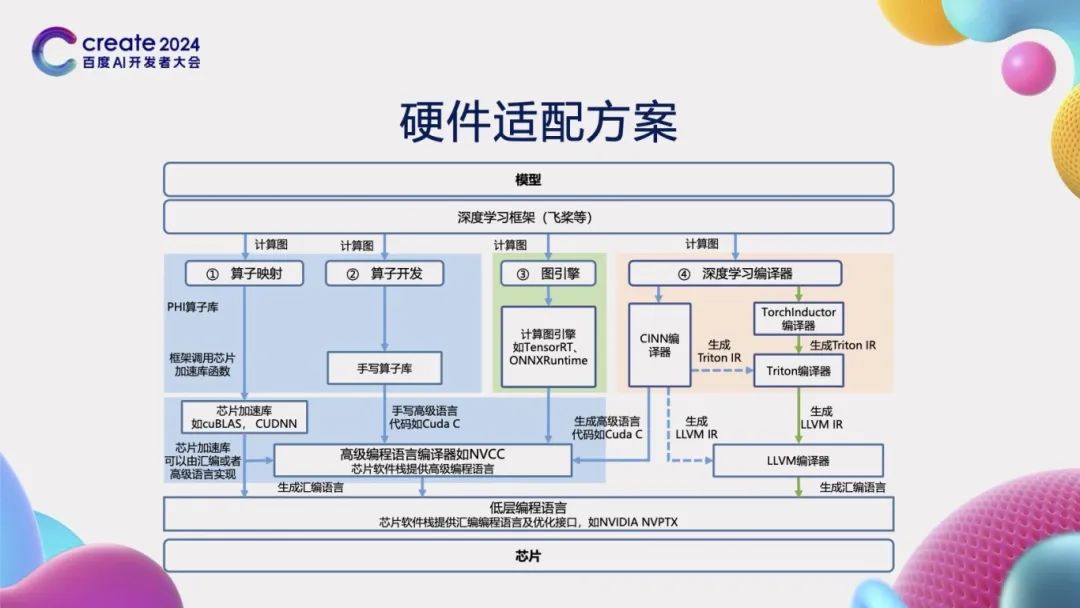
 Hardware Adaptation Solutions
In the process of achieving efficient computing, deep learning frameworks face a key challenge: how to effectively adapt to various hardware. To address this challenge, the PaddlePaddle framework adopts a comprehensive strategy and successfully implements four different access methods to ensure flexible adaptation to different chips. These four methods are operator mapping, operator development, graph engine access, and deep learning compiler. Through these diverse access methods, the PaddlePaddle framework not only enhances the performance of deep learning applications but also ensures broad hardware compatibility, providing developers with a powerful and flexible tool to adapt to the ever-changing computing environment and demands.
Hardware Adaptation Solutions
In the process of achieving efficient computing, deep learning frameworks face a key challenge: how to effectively adapt to various hardware. To address this challenge, the PaddlePaddle framework adopts a comprehensive strategy and successfully implements four different access methods to ensure flexible adaptation to different chips. These four methods are operator mapping, operator development, graph engine access, and deep learning compiler. Through these diverse access methods, the PaddlePaddle framework not only enhances the performance of deep learning applications but also ensures broad hardware compatibility, providing developers with a powerful and flexible tool to adapt to the ever-changing computing environment and demands.
 Based on the aforementioned advanced technologies, PaddlePaddle has partnered with chip manufacturers to jointly build a prosperous hardware ecosystem. This process can be divided into three core stages. First is the “co-gathering” stage, where we, along with several chip manufacturers, jointly initiated the PaddlePaddle hardware ecosystem. Next is the “co-research” stage, where we collaborate with chip manufacturers to achieve integrated software and hardware optimization. Finally, in the “co-creation” stage, we deeply cooperate with chip manufacturers to co-create a prosperous ecosystem. To date, we have successfully launched the PaddlePaddle ecosystem distribution version in collaboration with 22 hardware manufacturer partners, marking a deepening of cooperation and the emergence of results. At the same time, our ecosystem has attracted more than 40 member units, covering mainstream hardware manufacturers and providing a rich framework of hardware support, offering users more diverse choices.
Based on the aforementioned advanced technologies, PaddlePaddle has partnered with chip manufacturers to jointly build a prosperous hardware ecosystem. This process can be divided into three core stages. First is the “co-gathering” stage, where we, along with several chip manufacturers, jointly initiated the PaddlePaddle hardware ecosystem. Next is the “co-research” stage, where we collaborate with chip manufacturers to achieve integrated software and hardware optimization. Finally, in the “co-creation” stage, we deeply cooperate with chip manufacturers to co-create a prosperous ecosystem. To date, we have successfully launched the PaddlePaddle ecosystem distribution version in collaboration with 22 hardware manufacturer partners, marking a deepening of cooperation and the emergence of results. At the same time, our ecosystem has attracted more than 40 member units, covering mainstream hardware manufacturers and providing a rich framework of hardware support, offering users more diverse choices.
 New Generation PaddlePaddle Framework
New Generation PaddlePaddle Framework
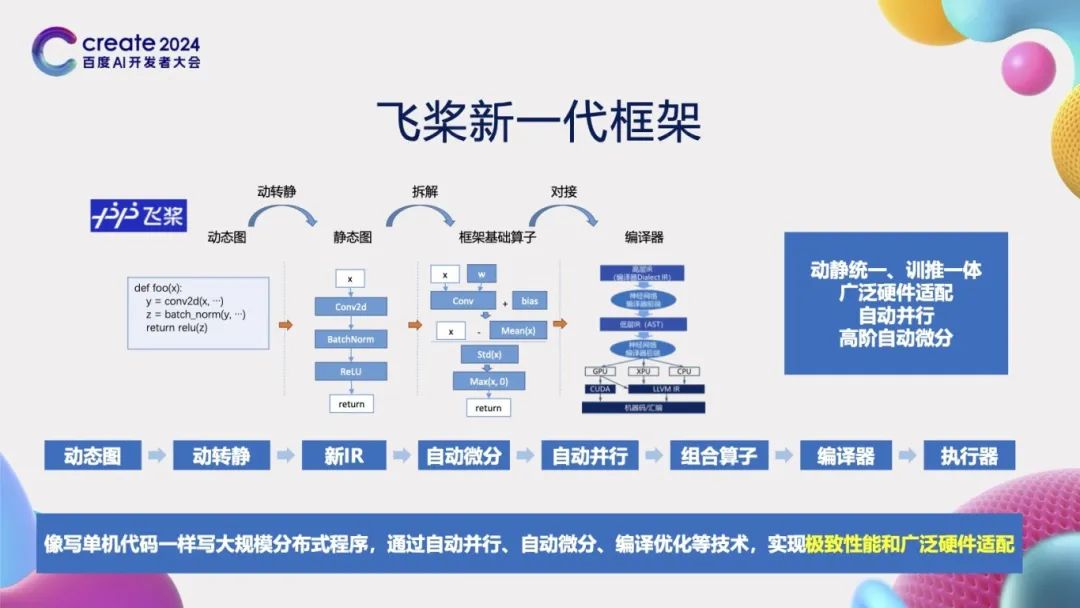 In summary, against the backdrop of the large model era and AI for Science era, the PaddlePaddle framework supports large models and scientific computing through a series of innovative technologies. We designed a complete process: starting from receiving dynamic graphs, converting them into new intermediate representations (IR) through dynamic-static conversion technology, and then performing automatic differentiation processing. After completing automatic differentiation, we apply automatic parallelism technology to optimize the computation process. Next, we decompose the computation through operator combinations, which are then optimized by the compiler and finally executed. The uniqueness of the PaddlePaddle framework lies in its realization of unified dynamic-static, integrated training and inference, broad hardware adaptability, and automatic parallel processing, while also supporting high-order automatic differentiation. We hope to provide developers with a flexible and easy-to-use experience, making the writing of distributed programs as simple as writing single-machine code, achieving extreme performance and broad hardware adaptability through automation technologies such as automatic parallelism, automatic differentiation, and compilation optimization.
In summary, against the backdrop of the large model era and AI for Science era, the PaddlePaddle framework supports large models and scientific computing through a series of innovative technologies. We designed a complete process: starting from receiving dynamic graphs, converting them into new intermediate representations (IR) through dynamic-static conversion technology, and then performing automatic differentiation processing. After completing automatic differentiation, we apply automatic parallelism technology to optimize the computation process. Next, we decompose the computation through operator combinations, which are then optimized by the compiler and finally executed. The uniqueness of the PaddlePaddle framework lies in its realization of unified dynamic-static, integrated training and inference, broad hardware adaptability, and automatic parallel processing, while also supporting high-order automatic differentiation. We hope to provide developers with a flexible and easy-to-use experience, making the writing of distributed programs as simple as writing single-machine code, achieving extreme performance and broad hardware adaptability through automation technologies such as automatic parallelism, automatic differentiation, and compilation optimization.