Follow our WeChat public account to discover the beauty of CV technology
This article shares the CVPR 2024 paper LiDAR Diffusion: Towards Realistic Scene Generation with LiDAR Diffusion Models, which utilizes LiDAR diffusion models to generate realistic scenes.
Details are as follows:

-
Paper link: https://arxiv.org/abs/2404.00815 -
Code link: https://github.com/hancyran/LiDAR-Diffusion -
Project homepage: https://lidar-diffusion.github.io/
Background
In recent years, we have observed a surge in controllable generative models capable of producing visually appealing and highly realistic images. Among these, Diffusion Models have become one of the most popular methods due to their impeccable performance. To generate under arbitrary conditions, Latent Diffusion Models have emerged. Their subsequent applications (e.g., Stable Diffusion, Midjourney, ControlNet) have further enhanced their potential for conditional image synthesis.
From Image Diffusion Models to LiDAR Diffusion Models
This success led us to ponder: can we apply controllable diffusion models to generate LiDAR scenes for autonomous driving and robotics?
For example, given a set of bounding boxes, can these models synthesize the corresponding LiDAR scenes, thus converting them into high-quality and expensive labeled data?
Or, can we generate the corresponding 3D scenes solely from images captured by the camera on the car?
Or, can we design a language-driven LiDAR generator for controllable simulation?
To answer these questions, our goal is to design a diffusion model that incorporates multiple conditions to generate realistic LiDAR scenes.
Related Work
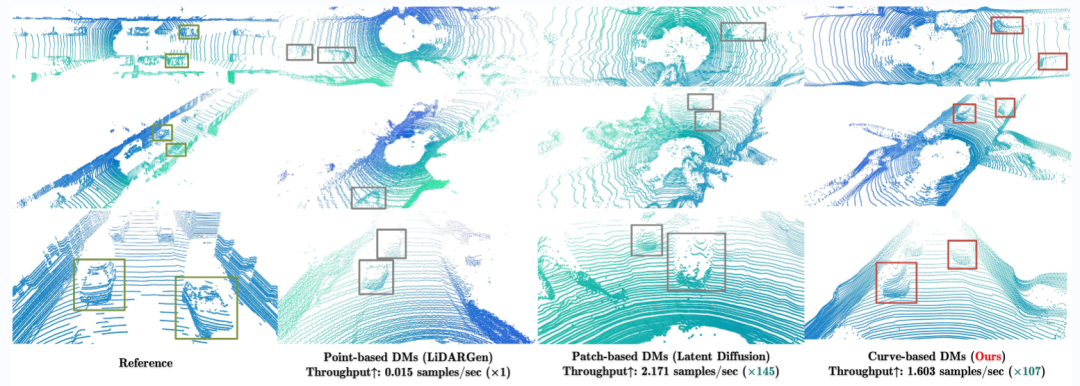
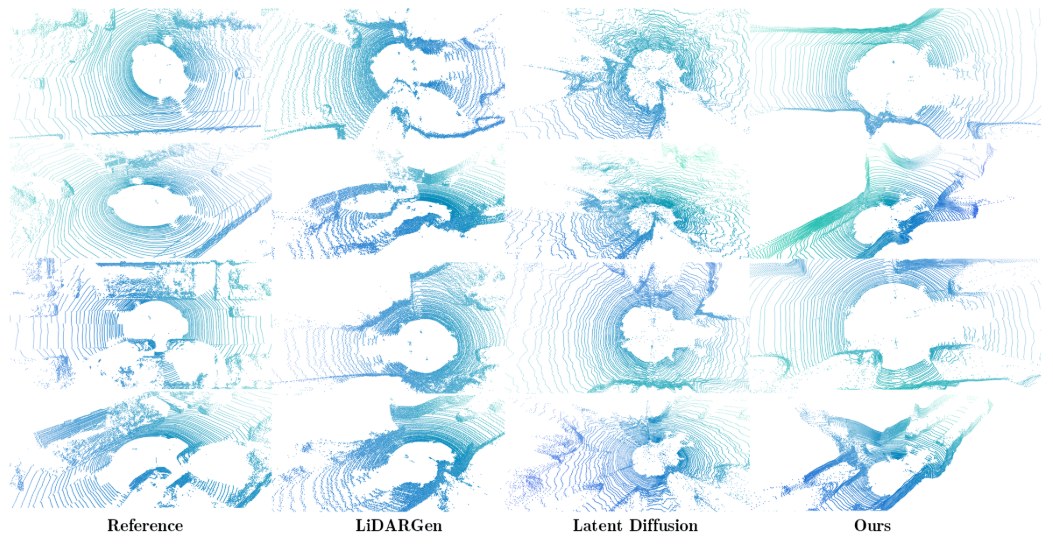
We have observed some phenomena from recent diffusion models related to autonomous driving. Point-based diffusion models, such as LiDARGen, introduced unconditional LiDAR scene generation. However, this model often produces noisy backgrounds (e.g., roads, walls) and blurry objects (e.g., cars), making it difficult to generate realistic LiDAR scenes.
Moreover, applying diffusion to points without any compression can computationally slow down the inference process. Additionally, directly applying Latent Diffusion Models to generate LiDAR scenes has yielded unsatisfactory performance both qualitatively and quantitatively.
LiDAR Diffusion Models
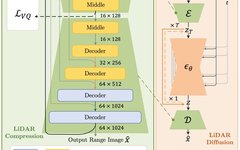
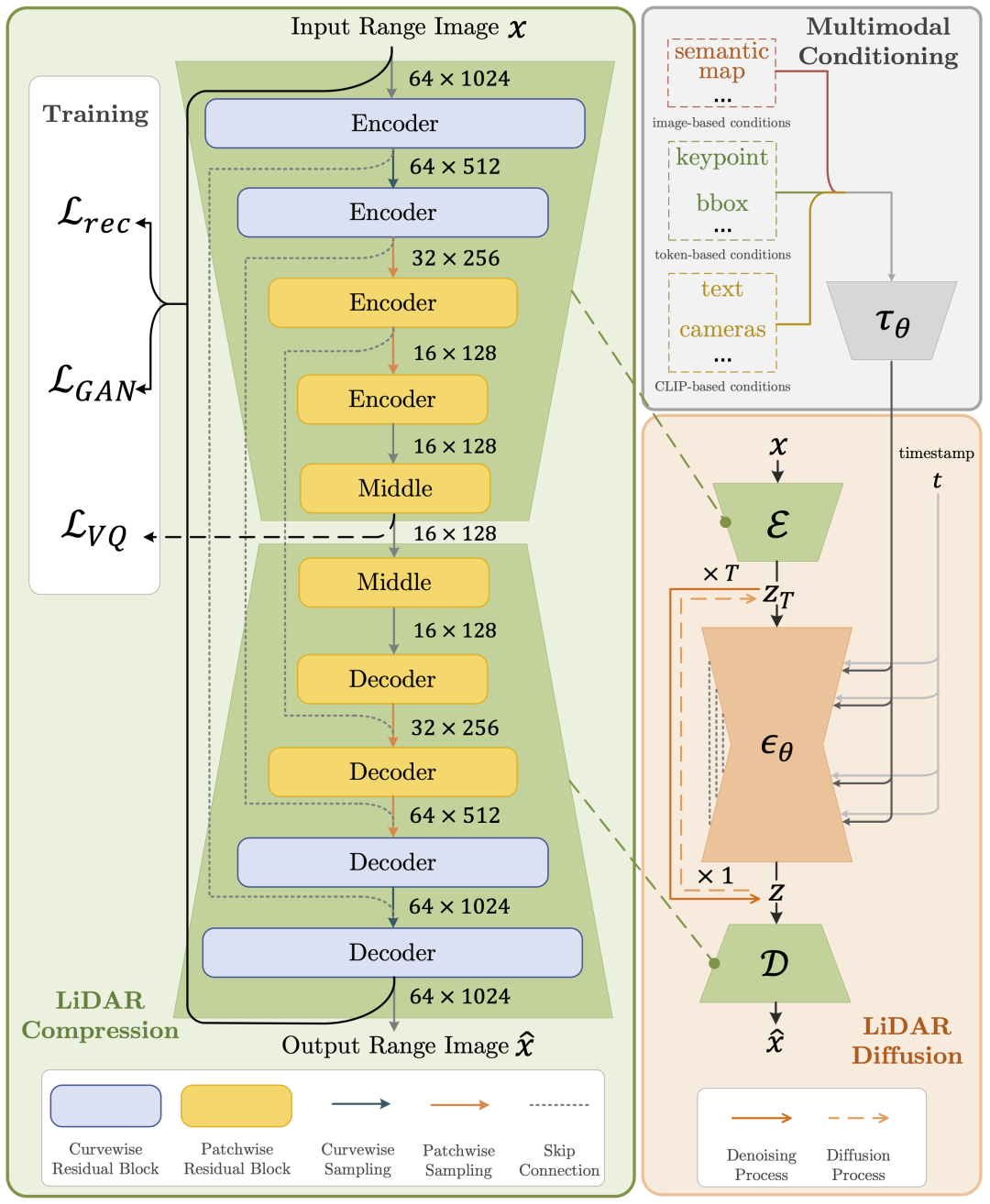
To achieve conditional realistic LiDAR scene generation, we propose a curve-based generator called LiDAR Diffusion Models to address the above questions and rectify some shortcomings of previous work. LiDAR Diffusion Models can take multiple conditions as input, such as bounding boxes, camera images, and semantic maps.
LiDAR Diffusion Models utilize range images as representations of LiDAR scenes, which are common in various downstream tasks such as detection, semantic segmentation, and generation. This choice is based on the reversible and lossless transformation between range images and point clouds, as well as the substantial benefits of highly optimized 2D convolution operations. To capture the semantic information of LiDAR scenes during the diffusion process, our approach encodes the LiDAR scenes into a latent space prior to diffusion.
To further enhance the simulation of LiDAR data authenticity in the real world, we focus on three key components: pattern authenticity, geometric authenticity, and object authenticity.
First, we utilize curve compression during the autoencoding process to extract the curved shapes of points in LiDAR.
Second, to achieve geometric realism, we introduce point-based coordinate supervision to enable our autoencoder to understand scene-level geometry.
Finally, we expand the receptive field by combining a patch-based downsampling strategy to capture the full context of visually larger objects.
Through the proposed modules, the diffusion model can effectively synthesize high-quality LiDAR scenes while also demonstrating exceptional performance, accelerating 107 times compared to LiDARGen, and supporting any type of image-based and token-based conditions as input.
Experiments
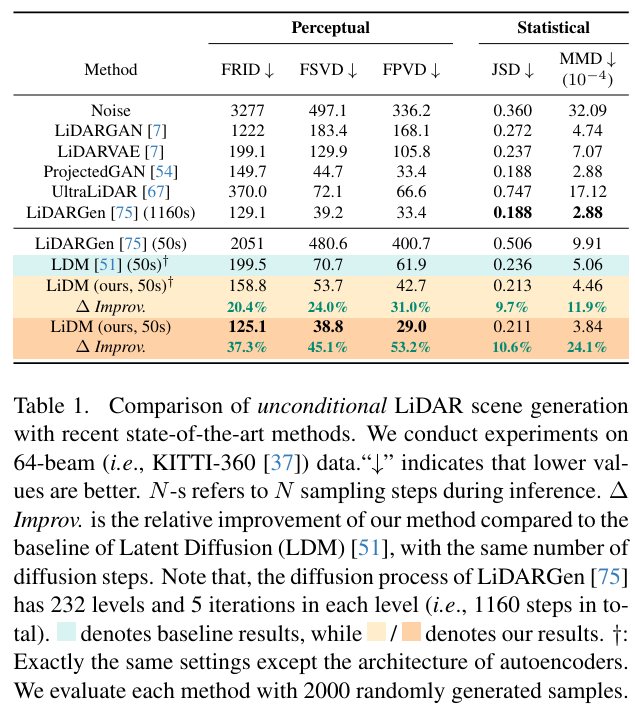
LiDAR Diffusion achieves state-of-the-art in unconditional LiDAR generation:
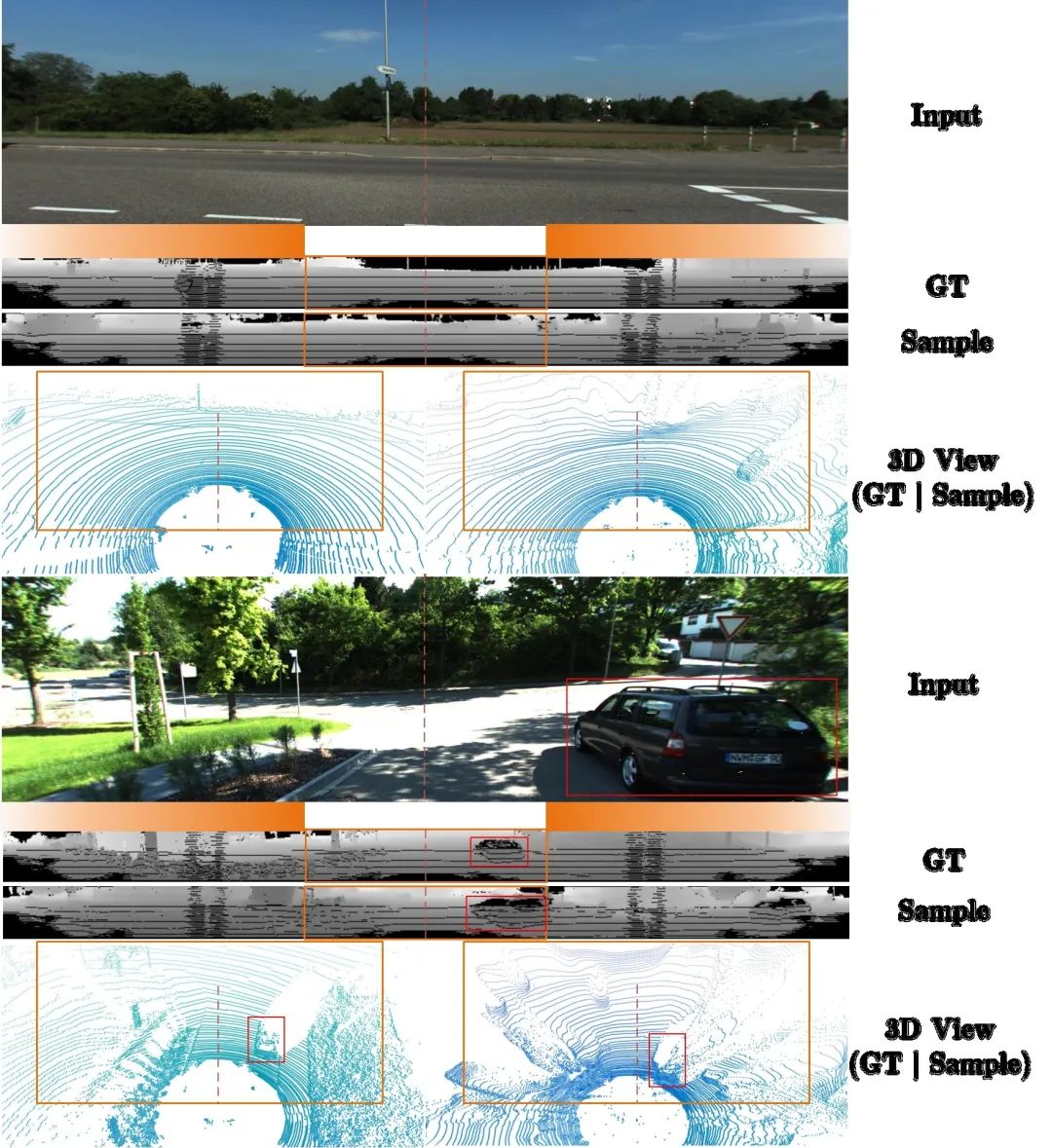
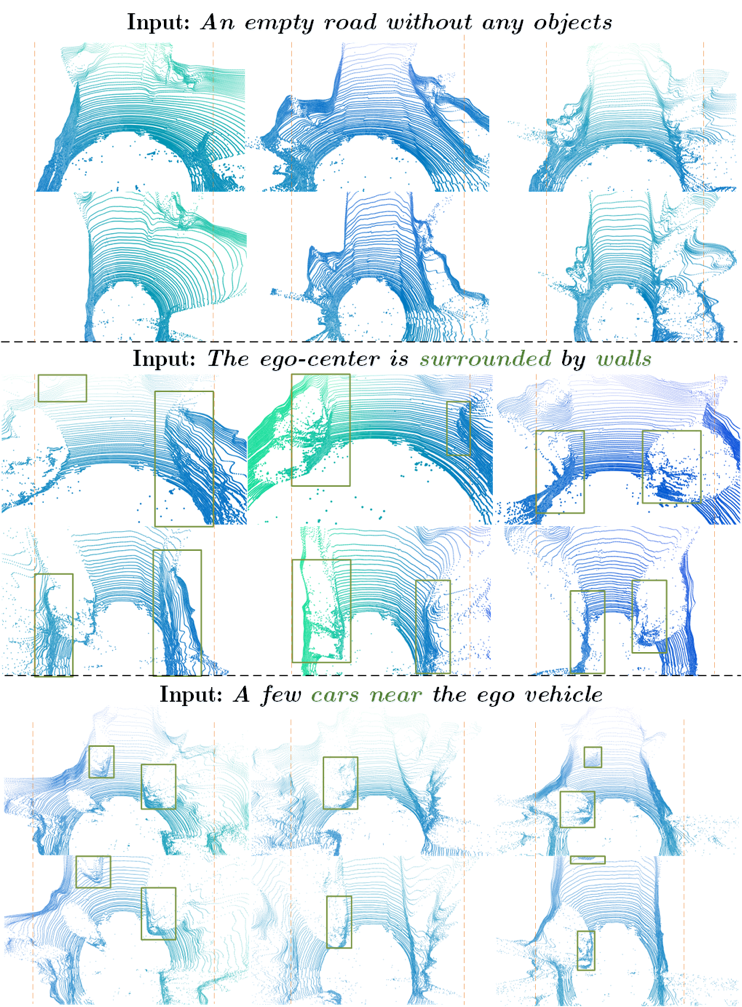
LiDAR Diffusion can also generate corresponding LiDAR scenes under various conditions:


END
