Click on the top “MLNLP“, select to add “starred” or “top”
Heavyweight content delivered first time
Editor: Yi Zhen
https://www.zhihu.com/question/48345431
This article is for academic sharing only, if there is infringement, the article will be deleted.
How to Evaluate fastText Algorithm Proposed by Word2Vec Author?Does Deep Learning Have No Advantage in Simple Tasks like Text Classification?
Author: Dong Lihttps://www.zhihu.com/question/48345431/answer/111513229
fastText, in brief, transforms all words in a document into vectors through a lookup table, averages them, and then uses a linear classifier to obtain classification results.fastText is very similar to the deep averaging network [1] (DAN, as shown below) from ACL-15, with the difference being the removal of the hidden layer in between.The conclusions of both articles are also quite similar, pointing out that for some simple classification tasks, it is unnecessary to use overly complex network structures to achieve comparable results.
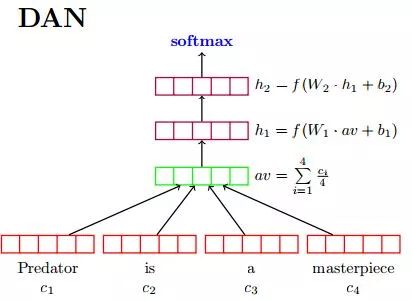
The datasets selected for the experiments in the article are not very sensitive to word order, so the experimental results obtained in the article are not surprising.However, consider the following three examples:
-
The movie is not very good, but I still like it. [2]
-
The movie is very good, but I still do not like it.
-
I do not like it, but the movie is still very good.
Among these, the overall polarity of sentences 1 and 3 is positive, while the overall polarity of sentence 2 is negative.If we only use simple averaging as the sentence representation for classification, it may be difficult to learn the impact of word order on sentence semantics.
From another perspective, fastText can be seen as using window-size=1 + average pooling CNN [3] to model sentences.
In summary:For simple tasks, using simple network structures is generally sufficient, but for more complex tasks, more complex network structures are still needed to learn sentence representations.
Additionally, the two tricks mentioned in fastText are:
-
hierarchical softmax
-
When the number of categories is large, a Huffman coding tree is constructed to accelerate the computation of the softmax layer, similar to the trick used in word2vec.
-
N-gram features
-
Using only unigrams would lose word order information, so N-gram features are added for supplementation.
-
Hashing is used to reduce the storage of N-grams.
[1] Deep Unordered Composition Rivals Syntactic Methods for Text Classification[2] A Statistical Parsing Framework for Sentiment Classification[3] Natural Language Processing (Almost) from Scratch
Recommended Reading:
“Complete Notes on Machine Learning by Li Hongyi” released, Datawhale open-source project LeeML-Notes
From Word2Vec to Bert, discussing the evolution of word vectors (Part 1)
Chen Lijie, a PhD student from Tsinghua’s Yao Class, won the Best Student Paper at the top theoretical computer conference
