Source: DeepHub IMBA
This article is about 1000 words long and is recommended to read in 5 minutes.
When real information exceeds a few words, the chance of exact matching becomes too slim.
In RAG systems, actual fact recall evaluation may face the following issues:
There has not been much attention paid to automatically verifying real, independent statements in low-quality generated texts and simulating low-quality retrieval-augmented generation (RAG) scenarios.
A single generated text may contain multiple facts that need to be verified, and the current independent method of verifying each fact may be too time-consuming and resource-intensive.
RAG systems involve many components, such as knowledge bases, retrieval, prompt formulations, and language models, all of which require extensive tuning. Therefore, efficiency is crucial for practical execution.
Exact matching of underlying truth texts in generated texts can easily lead to false negatives because the underlying truth information may exist in the generated text but be expressed differently.
When real information exceeds a few words, the chance of exact matching becomes too slim.
Facts As A Function
FaaF is a fact recall evaluation framework tailored for RAG systems, which can be used to create a test dataset and perform automatic fact recall evaluation.
The evaluation data is enhanced by real facts and manual annotations. WikiEval features question and answer pairs, where the answers have variable fact quality that can simulate flawed RAG responses.
FaaF is a new fact verification method that performs fact verification through prompts under all check conditions, reducing the required LM calls and completion tokens by over five times.
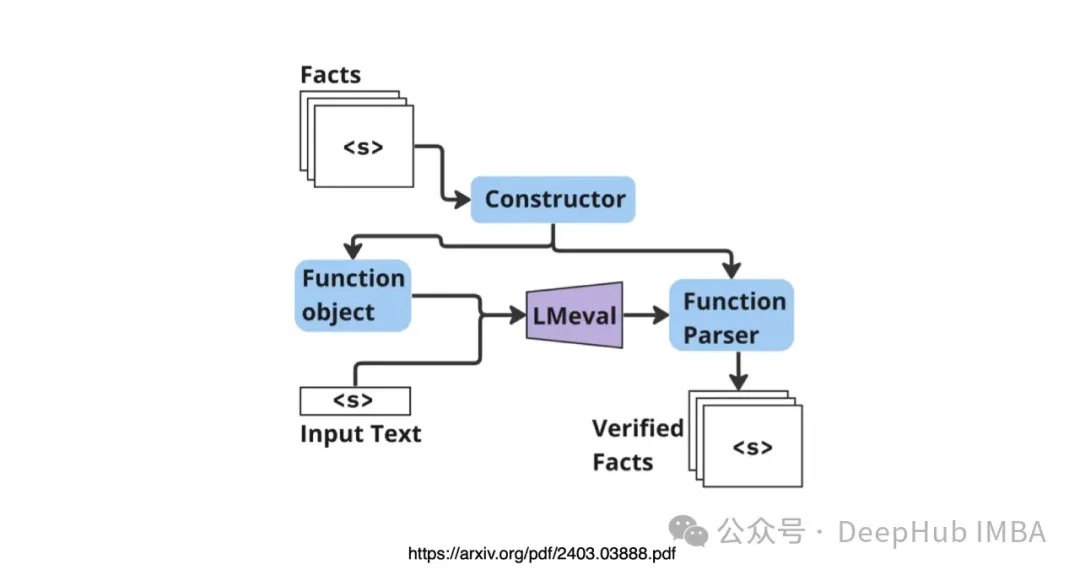
The constructor dynamically creates function objects based on a set of facts.
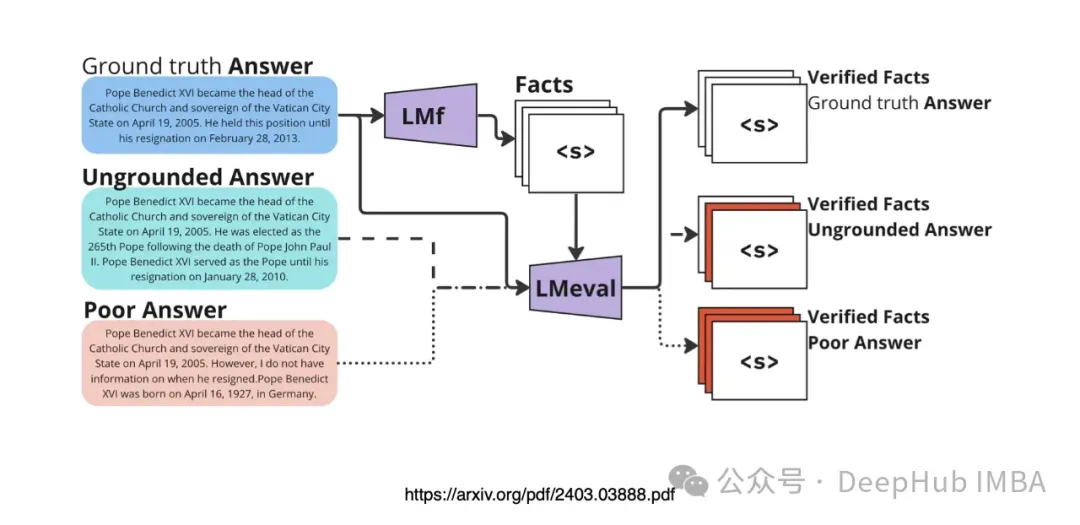
Given a set of underlying true answers, facts are extracted through LM. Then, the hypothesis responses of RAG (in this case, unsubstantiated answers and poor answers) are tested against the recall of the extracted facts.
Relying on prompts to verify facts often overestimates the truthfulness of statements, especially when the text lacks important information. This method can have an error rate of up to 50% when dealing with incomplete texts. However, presenting facts as a function to the language model (LM) greatly improves the accuracy and efficiency of verification.
FaaF shows that texts containing relevant or inaccurate information are more likely to produce false positives than those lacking or having incomplete details. Including an unclear option among true and false options can improve overall accuracy. Additionally, requiring citations before verifying facts is helpful in some cases, but if the text indirectly supports the fact without providing direct citations, it may lead to false negatives.
Finally, using FaaF significantly reduces the number of LM calls and tokens required for verification, making the process more efficient in terms of cost and time.
Paper link:https://arxiv.org/abs/2403.03888
Editor: Wen Jing