Why is Machine Learning Necessary?
Some tasks are complex to encode directly; we cannot handle all the nuances and simple coding. Therefore, machine learning is essential. Instead, we provide a large amount of data to machine learning algorithms, allowing them to explore the data and build models to solve problems. For example: recognizing 3D objects from new angles in a cluttered lighting scene; writing a program to calculate the probability of credit card transaction fraud.
The methods of machine learning are as follows: it does not write corresponding programs for each specific task but collects a large number of examples to specify the correct output for given inputs. The algorithm uses these examples to generate a program. This program differs from handwritten programs, as it may contain millions of data points and can adapt to new examples as well as the trained data. If the data changes, the program trains on the new data and is updated. A large amount of computation is much cheaper than paying for handwritten programs.
The applications of machine learning are as follows:
-
Pattern recognition: recognizing faces or expressions in real scenes, language recognition.
-
Anomaly detection: unusual sequences in credit card transactions, abnormal patterns in nuclear power plant sensor readings.
-
Prediction: future stock prices or currency exchange rates, personal movie preferences.
A neural network is a universal machine learning model, a set of specific algorithms that have revolutionized the field of machine learning. It approximates ordinary functions and can be applied to any complex mapping problem from input to output in machine learning. Generally, neural network architectures can be divided into three categories:
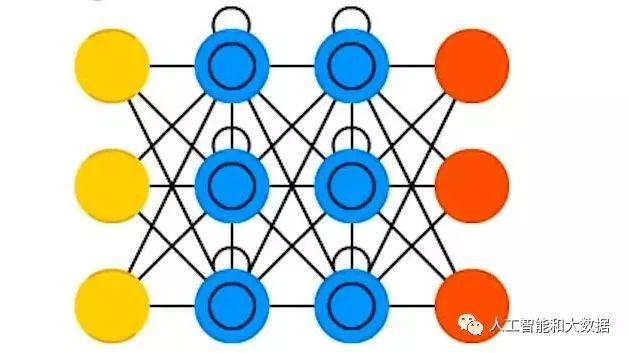
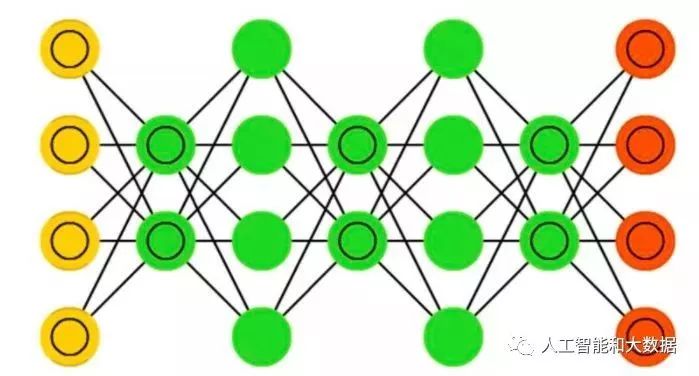
Feedforward Neural Networks: This is the most common type, with the first layer as input and the last layer as output. If there are multiple hidden layers, it is referred to as a “deep” neural network. It can compute the changes between a series of similar transformations of events, where the activity of each layer of neurons is a nonlinear function of the next layer.
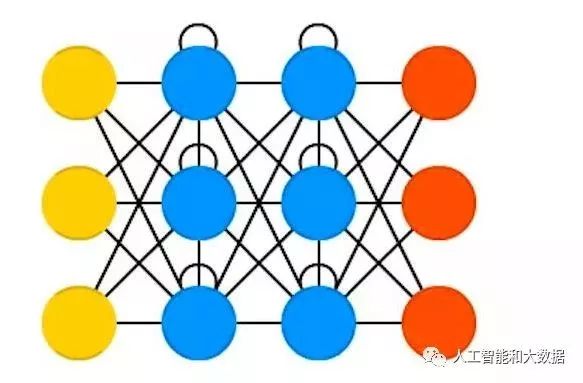
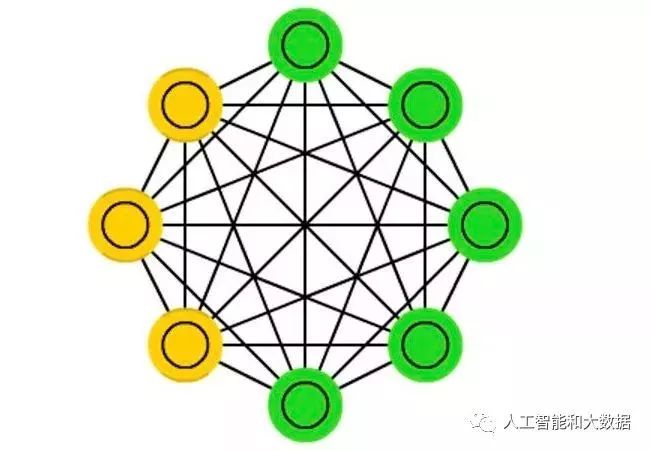
Recurrent Neural Networks: Nodes are connected in a cyclic graph, allowing the direction of the arrows to return to the starting point. Recurrent neural networks have complex dynamics and are difficult to train. They simulate sequential data, equivalent to a deep network with a hidden layer for each time slice, using the same weights at each time slice while also having inputs. The network can remember information about hidden states, but it is challenging to train the network using this information.
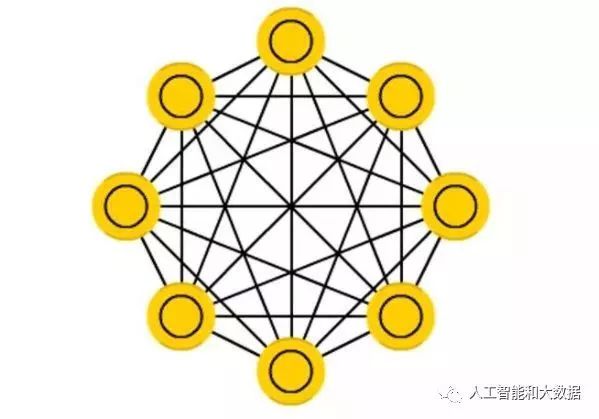
Symmetric Connection Networks: Similar to recurrent neural networks, but the connections between units are symmetric (i.e., the connection weights are the same in both directions). They are easier to analyze than recurrent neural networks but have limited functionality. Networks without hidden units are called “Hopfield Networks,” while those with hidden units are called “Boltzmann Machines.”
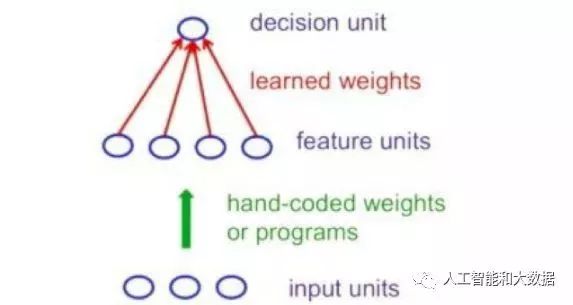
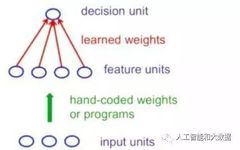
As the first generation neural network, the perceptron is a computational model with only one neuron. It first transforms the raw input vector into a feature vector, then defines features using handwritten programs, and learns how to weight each feature to obtain a scalar. If the scalar value exceeds a certain threshold, the input vector is considered a positive example of the target class. The standard structure of a perceptron is a feedforward model, where inputs are sent to nodes, processed, and produce output results: input at the bottom and output at the top, as shown in the figure below. However, it also has its limitations: once the handwritten coding features are determined, learning is significantly restricted. This is devastating for the perceptron; although transformations are akin to translations, the focus of pattern recognition is to recognize patterns. If these transformations form a group, the learning perceptron cannot learn to recognize them, necessitating the use of multiple feature units to recognize the transformations of sub-patterns.
Networks without hidden units also have significant limitations in modeling input-output mappings. Adding linear unit layers does not solve the problem, as linear combinations remain linear, and fixed nonlinear outputs cannot establish such mappings. Therefore, it is necessary to establish multilayer adaptive nonlinear hidden units.
Machine learning research has long focused on object detection, but many factors still make it difficult to recognize objects:
1. Object segmentation and occlusion issues;
2. Lighting affects pixel intensity;
3. Objects present in various forms;
4. Objects with the same function have different physical shapes;
5. Variations due to different visual perspectives;
6. Dimensionality jump issues.
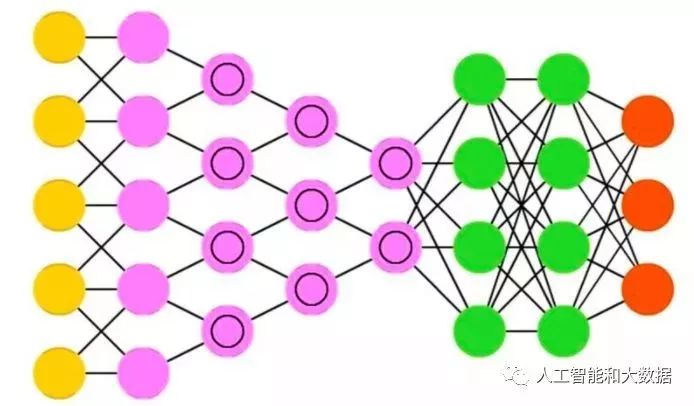
The feature replication method is the primary approach currently used by CNNs for object detection, significantly reducing the number of free parameters to learn by replicating the same feature detection maps at different locations. It uses different types of features, each with its own replicated detection map, allowing for various representations of each image block.
CNNs can be used for tasks ranging from handwritten digit recognition to 3D object recognition; however, recognizing objects from color images is more complex than handwritten digit recognition, as its categories and pixels are 100 times more (1000 vs 100, 256*256 color vs 28*28 grayscale).
The ILSVRC-2012 competition in 2012 provided a dataset containing 1.2 million high-resolution training images. The test images were not labeled, and participants had to identify the types of objects in the images. The winner, Alex Krizhevsky, developed a deep convolutional neural network, which, aside from some max-pooling layers, had seven hidden layers, with convolutional layers at the front and the last two layers fully connected. The activation function in each hidden layer was a linear unit, which is faster than a logic unit, and it also used competitive normalization standards to suppress hidden activity, helping with intensity variations. On the hardware side, an efficient convolutional network was implemented on two Nvidia GTX 580 GPUs (over 1000 fast cores), which is very suitable for matrix multiplication and has high memory bandwidth.
Recurrent Neural Networks (RNNs) have two powerful attributes that allow them to compute anything computable by a computer: (1) they allow for the storage of a large amount of valid information in distributed hidden states, and (2) they allow for complex ways to update hidden states with nonlinear dynamics. The powerful computational capabilities of RNNs, combined with gradient vanishing (or explosion), make them difficult to train. During multilayer backpropagation, if the weights are small, the gradients shrink exponentially; if the weights are large, the gradients grow exponentially. Some hidden layers of a typical feedforward neural network can cope with the exponential effect; however, in long sequence RNNs, gradients easily vanish (or explode), making it difficult to detect the current target output that depends on multiple time inputs, thus making it hard to handle long-range dependencies.
The methods for learning RNNs are as follows:
-
Long Short-Term Memory: Small modules with long-term memory values are used to create RNNs.
-
Hessian Free Optimization: An optimizer is used to address the gradient vanishing problem.
-
Echo State Networks: Initialize input → hidden and hidden → hidden and output → hidden links, allowing the hidden state to have a massive weakly coupled oscillator reserve that can be selectively driven by inputs.
-
Momentum Initialization: Similar to echo state networks, but uses momentum to learn all connections.
Hochreiter & Schmidhuber (1997) constructed long short-term memory networks to solve the problem of acquiring long-term memory in RNNs, using multiplicative logic linear units to design storage units. As long as the “write” gate is kept open, information will be written and retained in the unit, and the “read” gate can also be opened to retrieve data.
RNNs can read cursive handwriting, where the input coordinates of the pen tip are (x,y,p), with p representing whether the pen is up or down, and the output is a sequence of characters, using a series of small images as input instead of pen coordinates. Graves & Schmidhuber (2009) referred to RNNs with LSTM as the best system for reading cursive handwriting.
Nonlinear recurrent networks can exhibit many forms, making them challenging to analyze: they can achieve stable, oscillatory, or chaotic states. Hopfield networks consist of binary threshold units with cyclic connections. In 1982, John Hopfield discovered that if the connections are symmetric, a global energy function exists, where each binary “state” of the entire network has energy, and the binary threshold decision rule sets a minimum energy for the network. The simplest way to use this type of computation is to treat memory as the minimum energy of a neural network. Using minimum energy to represent memory provides a content-addressable memory, accessible by understanding the local content to retrieve the entire item.
Each time a configuration is remembered, it aims to produce a minimum energy. However, if there are two minimums, it will limit the capacity of the Hopfield network. Elizabeth Gardner discovered a better storage rule that uses all weights. Instead of trying to store multiple vectors at once, she trained each unit through multiple cycles using the training set and trained each unit with a perceptron convergence program to ensure that all other units of that vector had the correct state.
A Boltzmann machine is a type of stochastic recurrent neural network that can be seen as a random generation of Hopfield networks, and it is one of the first neural networks to learn internal representations. The algorithm aims to maximize the product of the probabilities assigned to binary vectors in the training set, which is equivalent to maximizing the sum of the logarithmic probabilities assigned to training vectors, as follows:
(1) When the network has no external input, it stabilizes the distribution over time;
(2) Sample from the visible vector each time.
In 2012, Salakhutdinov and Hinton wrote an effective mini-batch learning program for Boltzmann machines. In 2014, the model was updated and referred to as a Restricted Boltzmann Machine; for details, please refer to the original text.
Backpropagation is the standard method for distributing errors across each neuron after processing a batch of data in artificial neural networks, but it also has some issues.
First, training data must be labeled, but almost all data is unlabeled;
Second, insufficient learning time means that networks with many hidden layers are slower;
Third, it may lead to local minima. Therefore, this is far from sufficient for deep networks.
Unsupervised learning methods overcome the limitations of backpropagation, using gradient methods to adjust weights, which helps maintain the efficiency and simplicity of the architecture, and can also be used to model the structure of sensory input. Specifically, it adjusts weights to maximize the probability of generating models that produce sensory inputs. Belief networks consist of directed acyclic graphs composed of random variables, allowing for the inference of unobserved variable states, and can also adjust interactions between variables to make the network more likely to produce training data.
Early graphical models were defined by experts for image structure and conditional probabilities. These graphs were sparsely connected, focusing on making correct inferences rather than learning. However, for neural networks, learning is the focus, and the goal is not interpretability or sparse connectivity to make inference easier.
This architecture provides two mapping methods, resembling a very effective way of nonlinear dimensionality reduction. It is linear (or better) in terms of the number of training examples, while the final encoded model is quite compact and fast. However, optimizing deep autoencoders using backpropagation is challenging, as the gradients may vanish if the initial weights are small. We use unsupervised layer-wise pretraining or serious weight initialization like echo state networks.
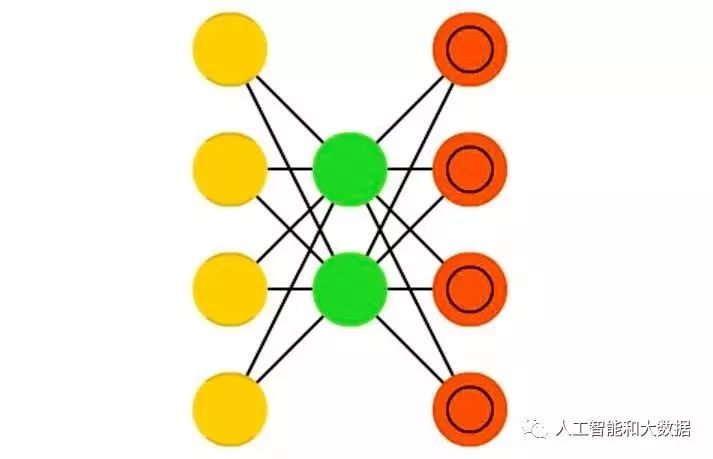
There are three different types of shallow autoencoders for pretraining tasks:
(1) RBM as an autoencoder;
(2) Denoising autoencoder;
(3) Sparse autoencoder.
For datasets without a large amount of labeled data, pretraining helps subsequent discriminative learning. Even for deep neural networks, unsupervised training is not necessary for weight initialization in large labeled datasets; pretraining is a good first method for initializing deep network weights, and there are now other methods as well. However, if the network is expanded, pretraining needs to be done again.
The traditional programming approach is that we tell the computer what to do, breaking down large problems into many small, precise tasks that the computer can easily execute. Neural networks do not require us to tell the computer how to solve the problem; instead, they learn from the observed data, finding ways to solve the problem.
Source: Artificial Intelligence and Big Data
Previous Article Recommendations
