
Introduction
When it comes to the most common AI application scenarios in daily life, speech synthesis and recognition are undoubtedly among the most familiar.
From the announcements in map navigation, WeChat voice-to-text, mobile voice input, to the Baidu smart speaker, all rely on speech technology.
How is speech technology achieved? What ready-made open-source code can be quickly integrated into projects? These are questions of great concern to every developer.
Well, the time for benefits has arrived! Today, we present an open-source project that integrates Chinese and English speech recognition, speech translation, speech synthesis, and sound classification capabilities, and allows you to experiment with just one line of code! You definitely can’t miss it!
Project Introduction
Without further ado, let’s first look at the effect demonstration provided in the project.
Speech Recognition
Input Audio 1
Recognition Result 1
I knocked at the door on the ancient side of the building.
Input Audio 2
Recognition Result 2
I think the most important thing about running is that it brings me good health.
Speech Translation (English to Chinese)
Input Audio
Recognition Result
I knocked at the door on the ancient side of the building.
Speech Synthesis
Input Text 1
Life was like a box of chocolates, you never know what you’re gonna get.
Synthesized Audio 1
Input Text 2
Good morning, today is 2020/10/29, and the lowest temperature is -3°C.
Synthesized Audio 2
As you can see, whether it is recognition or synthesis in Chinese and English, this open-source project performs well. Notably, the project also includes speech translation capabilities, allowing for simultaneous translation of English speech into Chinese subtitles, which is indeed powerful.
Portal:
GitHub Address:
https://github.com/PaddlePaddle/PaddleSpeech
Some readers might wonder, is it complicated to use such powerful speech capabilities?
I must say that this project has indeed considered ease of use very thoughtfully.
Installation and Testing Effects
We followed the guidance on the homepage:
One command to install:
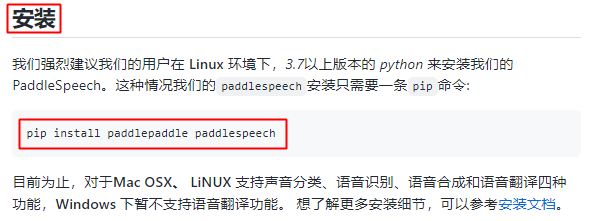
One command to quickly start using:
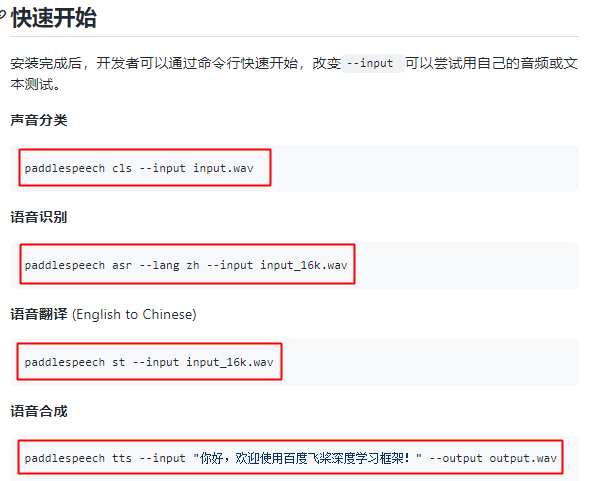
Here, I installed this project on my machine with a try-it-and-see attitude. After installation, I first used speech synthesis to test.

You can listen to the generated effect~
Then, out of curiosity, we sent the synthesized result to speech recognition to see the effect:
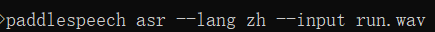
Final output result:

As you can see, the effect is quite good after this loop!
In addition to the excellent effect and easy experience, let’s see what treasures can be dug in this project. Sure enough, we found that the project also contains rich pre-trained models, and both speech recognition and synthesis support custom training.
Rich Pre-trained Models
Speech recognition includes acoustic models and language models, details as follows:
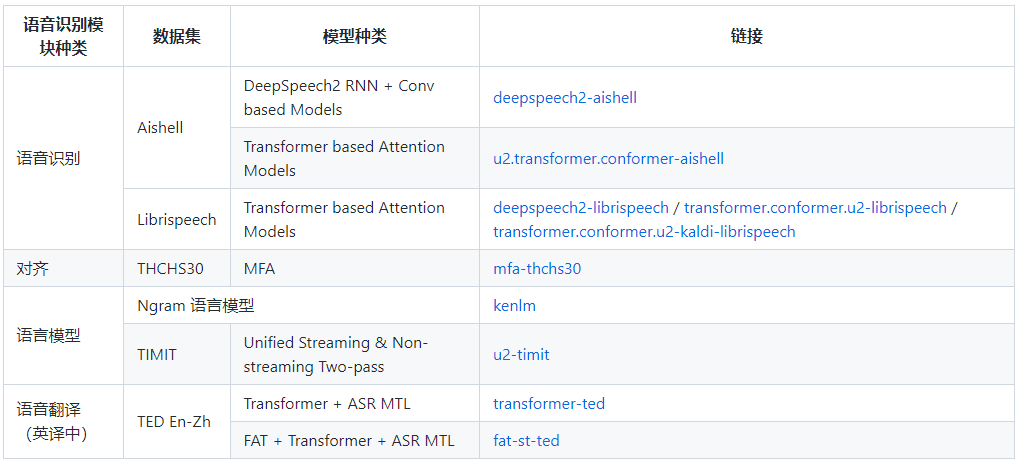
Speech synthesis mainly includes three modules: text frontend, acoustic model, and vocoder. The acoustic model and vocoder models are as follows:
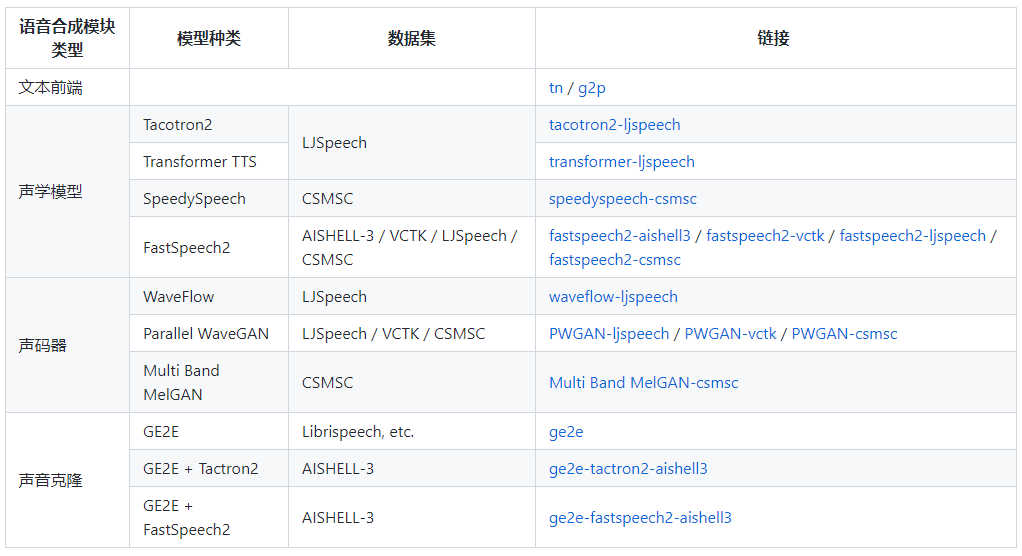
Comprehensive Documentation and Tutorials

Since its open-source release, it has received widespread attention from developers, and many developers have contributed to the project.
Truly full of valuable content!

There’s no need to say much more, please visit GitHub to experience it yourself:
https://github.com/PaddlePaddle/PaddleSpeech
If you are satisfied, feel free to give a star to encourage our engineers!

Live Courses, Learn from Experts
To help everyone understand more about the cutting-edge developments in speech technology and to play with open-source projects, from December 21 to 24, every evening from 20:15 to 21:30, led by Professor Huang Liang, director of Baidu Research Institute’s Deep Learning Lab (US), along with several senior engineers in the field of speech, a premium technical live course will be presented to explain the core technologies in the speech domain.
Scan to Register for the Live Course and Join the Technical Exchange Group

Exciting Content Preview

PaddleSpeech Project Address:
GitHub: https://github.com/PaddlePaddle/PaddleSpeech
Gitee: https://gitee.com/paddlepaddle/PaddleSpeech