

Intelligent speech is a technology that enables human-machine language communication, mainly including speech recognition and speech synthesis. Speech recognition is the technology that converts human speech into text. Speech synthesis is the technology that transforms text information into speech signals.



Overview
01
The research on speech recognition began in 1952 when researchers at Bell Labs developed a speech recognition system for isolated words spoken by a specific speaker in English. After the 1960s, RCA Labs proposed and implemented a normalization scoring mechanism to address the inconsistency in speech duration. Vintsyuk from the former Soviet Union introduced a dynamic programming algorithm for time-aligning speech of different lengths. In the 1970s, the focus of speech recognition research shifted to large vocabulary continuous speech recognition technology. After the 1990s, the overall framework design of HMM became the foundation of research in this field. Currently, deep learning has been widely applied in speech recognition research. Figure 1 summarizes the representative theoretical technologies and open-source software in the development of speech recognition.
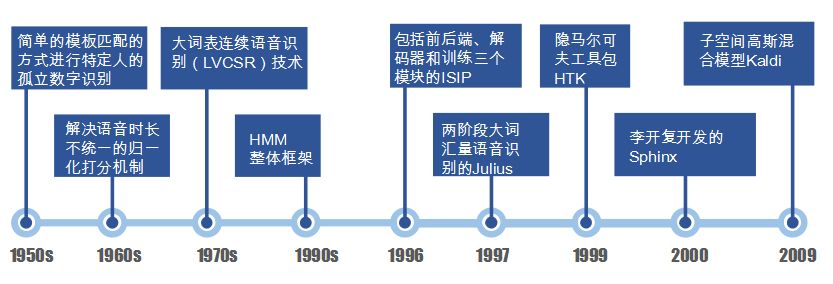
Figure 1 Representative Theoretical Technologies and Open Source Software in Speech Recognition
The research on speech synthesis began in 1939 with the development of the first electronic synthesizer using the formant principle at Bell Labs. In 1980, a hybrid formant synthesizer was proposed. By the late 1980s, the introduction of the fundamental frequency synchronous superposition time-domain waveform modification algorithm better addressed the issue of speech segment splicing. By the end of the 1990s, algorithms for selecting speech units based on large corpora and waveform splicing algorithms were proposed, which could synthesize higher quality speech, and statistical parameter speech synthesis technology based on Hidden Markov Models achieved good results. Today, deep learning algorithms have been widely applied in speech synthesis technology. Figure 2 summarizes the representative theoretical technologies and open-source software in the development of speech synthesis.
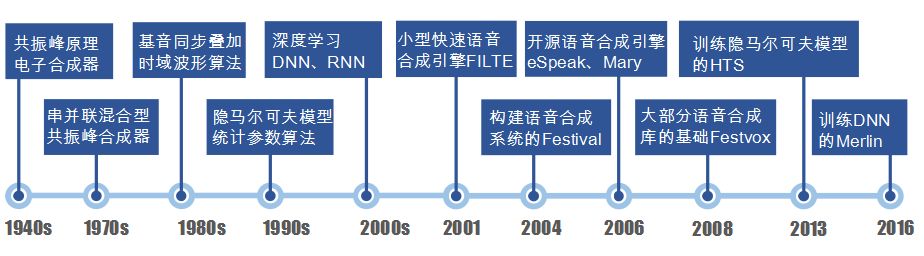
Figure 2 Representative Theoretical Technologies and Open Source Software in Speech Synthesis
The typical tasks of speech recognition mainly include robust speech recognition and speaker adaptation technology. Robust speech recognition is the technology that recognizes speech with high accuracy in complex and variable acoustic environments when the input speech quality is low or speech characteristics change. Speaker adaptation technology can identify non-specific people’s speech by analyzing the differences between different speakers.
The typical tasks of speech synthesis mainly include expressive speech synthesis and multilingual speech synthesis technology. Expressive speech synthesis technology can enhance the expressiveness of synthesized speech, rather than merely outputting speech in a fixed reading manner. Multilingual speech synthesis technology can understand different languages and promote speech synthesis to multilingual platforms based on the different nationalities of listeners and other characteristics.
The typical applications of intelligent speech mainly include intelligent speech interaction, voice control, and biometric information verification. Intelligent speech interaction is an application based on voice input, where the speaker receives feedback results through speech. Intelligent speech interaction has broad applications in voice assistants, smart navigation, smart homes, etc. Voice control technology can recognize and understand speech signals, converting human language commands into corresponding commands. Biometric information verification can utilize the inherent physiological characteristics and behavioral traits of human voice to identify personal identity when combined with speech recognition technology. Table 1 lists some typical applications in the field of intelligent speech.
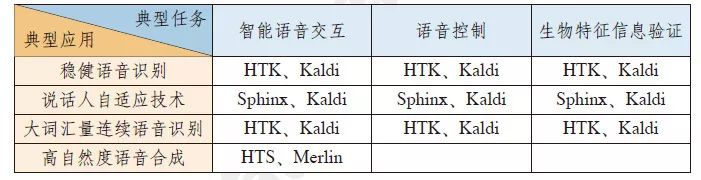
Table 1 Typical Applications in the Field of Intelligent Speech



02
Typical Open Source Software
Intelligent speech, as an important research direction in the field of artificial intelligence, has a large number of open-source software and open-source datasets, providing a solid research foundation for researchers in this field and promoting the rapid development of intelligent speech research. This subsection introduces some typical open-source software.
Speech Recognition
ISIP is an open-source speech recognition toolkit developed by Mississippi State University in 1996, which includes three modules: backend, decoder, and training.
Julius is a high-performance, large vocabulary open-source speech recognition toolkit developed by Nagoya Institute of Technology in 1997 based on the APGL-3.0 license. Julius is used mainly in the field of speech recognition and runs on Linux, Unix, and Windows platforms.
HTK is the Hidden Markov Toolkit developed by the Machine Intelligence Laboratory at Cambridge University, based on the MIT license. HTK is mainly applied in speech recognition, speech synthesis, and DNA sequence analysis through training Hidden Markov models.
CMU Sphinx is an open-source speech recognition toolkit developed by the CMU Sphinx group in 2000, based on the GPL-2.0 license.
Kaldi is a speech recognition toolkit written in C++, developed by Johns Hopkins University in 2009 under the Apache license, focusing on Subspace Gaussian Mixture Model (SGMM) modeling.
Speech Synthesis
MARY is a multilingual speech synthesis platform developed in Java by the German Research Center for Artificial Intelligence in 2014, based on the MIT license, supporting speech synthesis in German, English, Russian, and Turkish.
Festival is a general-purpose open-source framework for building speech synthesis systems, developed by the Speech Technology Research Group at the University of Edinburgh in 2004, based on the BSD license. It supports speech synthesis in multiple languages and can also support Apple’s native operating systems.
eSpeak is an open-source speech synthesis toolkit released by Jonathan Duddington in 1995, designed for English speech synthesis on RISC systems. eSpeak supports SSML (Speech Synthesis Markup Language) and has text processing capabilities.
Filte is a small, fast-running speech synthesis toolkit developed by Carnegie Mellon University in 2001, based on the GPL 3.0 license, mainly used in small embedded machines and large servers.
HTS is a speech synthesis toolkit based on HMM models, developed by Nagoya Institute of Technology in 2002, based on the BSD license. HTS can provide implementations of adaptive training, parameter generation, etc., and can train speech data from corpora to achieve statistical parameter-based speech synthesis.
Merlin is an open-source toolkit for speech synthesis based on neural networks, developed by the University of Edinburgh in 2016 under the Apache 2.0 license, mainly used for training statistical parameter speech synthesis models based on deep neural networks.
Open-source Datasets
Some academic institutions have released speech datasets, while most companies use proprietary speech datasets. Typical open speech recognition datasets include the classic English speech dataset TIMIT, 2000 HUB5 English, Libri Speech containing text and speech from nearly 500 individuals, VoxForge focusing on different accents, and CHIME for use in various noise environments. Typical open speech synthesis datasets include CMU ARCTIC released by the CMU Language Technology Institute.



Summary
03
Currently, there is a rapid growth trend among researchers and enterprises engaged in intelligent speech-related research in China. However, due to the late start of domestic open-source platforms and communities, there is a lack of mature open-source communities and platforms similar to those abroad. With the continuous advancement and development of intelligent speech technology in China, it is hoped that a number of mature open-source software platforms and communities related to intelligent speech will emerge in the near future, contributing to the development of the national intelligent speech field.




04
Serialized Preview
The serialized preview of the current status of open-source software development in artificial intelligence:
Episode 1: Development History of Open Source Software in AI
Episode 2: Open Source Computing Platforms for AI
Episode 3: Open Source Machine Learning Frameworks
Episode 4: Open Source Software for Natural Language Processing
Episode 5: Open Source Software for Computer Vision
Episode 6: Open Source Software for Intelligent Speech
Episode 7: Open Source Software for Unmanned Systems
Episode 8: Open Source Software for Knowledge Graphs
Episode 9: Open Source Software for Virtual Reality and Augmented Reality
Episode 10: Open Source Software for Game Intelligence and Information Security
Episode 11: Analysis of Characteristics of Open Source Software in AI
Episode 12: Typical Solutions for AI Technology Based on Open Source Software
Source: Ministry of Industry and Information Technology Electronic Standards Institute, China Open Source Software Development Alliance
Su Zhou Software Industry Association

Phone: 0512-65215944
Address: 77 Nantiangcheng Road, Xiangcheng District, Suzhou, 403 Gaorong Building