Source: DeepHub IMBA
This article is about 4000 words, and it is recommended to read in 5 minutes.
In this article, I will demonstrate how to create your own Document Assistant from scratch using LLaMA 7b and Langchain.
In the past few months, large language models (LLMs) have gained tremendous attention, creating exciting prospects, especially for developers engaged in chatbots, personal assistants, and content creation.
Large language models (LLMs) refer to machine learning models capable of generating text that is very similar to human language and understanding prompts in a natural way. These models are trained on extensive datasets that include books, articles, websites, and other sources. By analyzing statistical patterns in the data, LLMs can predict the most likely words or phrases that will follow a given input.
The above is a panoramic view of the current LLMs.
Background Knowledge
LangChain is an impressive and free framework that revolutionizes the development process for a wide range of applications, including chatbots, generative question answering (GQA), and summarization. By seamlessly linking components from multiple modules, LangChain can create applications using most LLMs.
LLaMA is a new large language model designed by Meta AI, the parent company of Facebook. LLaMA has a model collection with parameters ranging from 7 billion to 65 billion, making it one of the most comprehensive language models available. On February 24, 2023, Meta publicly released the LLaMA model, showcasing their commitment to open science (although what we are using now is a leaked version).
GGML is a tensor library for machine learning; it is simply a C++ library that allows you to run LLMs on CPU or CPU + GPU. It defines a binary format for distributing large language models (LLMs). GGML uses a technique called quantization, which allows large language models to run on consumer hardware.
As we all know, the weights of models are floating-point numbers. Just as representing large integers (e.g., 1000) requires more space than representing small integers (e.g., 1), representing high-precision floating-point numbers (e.g., 0.0001) requires more space than representing low-precision floating-point numbers (e.g., 0.1). The process of quantizing large language models involves reducing the precision of the weights representation to minimize the resources needed to use the model. GGML supports many different quantization strategies (e.g., 4-bit, 5-bit, and 8-bit quantization), each offering different trade-offs between efficiency and performance.
Below is a comparison of model sizes after quantization:
Streamlit is an open-source Python library for building data science and machine learning applications. It is designed to enable developers to build interactive applications quickly and easily, without the need for cumbersome front-end development. Streamlit provides a simple set of APIs for creating applications with data exploration, visualization, and interactivity. You can create a web application using simple Python scripts and leverage Streamlit’s rich component library to build user interfaces, such as text boxes, sliders, dropdown menus, and buttons, as well as visualization components like charts and maps.
1. Set Up Virtual Environment and Project Structure
Setting up a virtual environment provides a controlled and isolated environment for running the application, ensuring its dependencies are separated from other system-wide packages. This approach simplifies dependency management and helps maintain consistency across different environments.
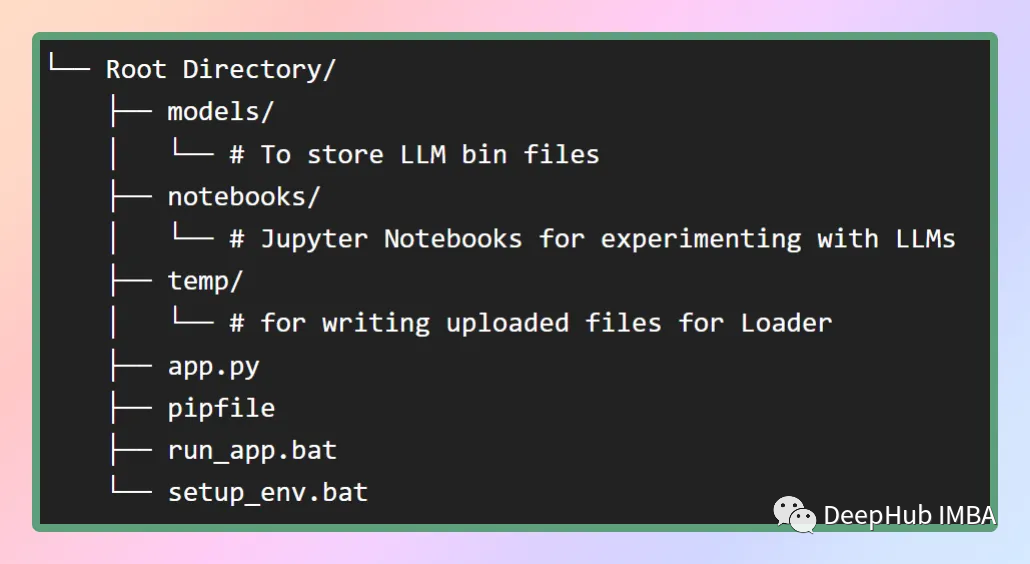
Next, we need to create our project; a good structure will speed up our development, as shown in the figure below:
In the models folder, we will store the downloaded LLMs, and setup_env.bat will install all dependencies from the Pipfile. The run_app.bat will directly run our app. (The above two files are scripts for the Windows environment.)
2. Install LLaMA on Local Machine
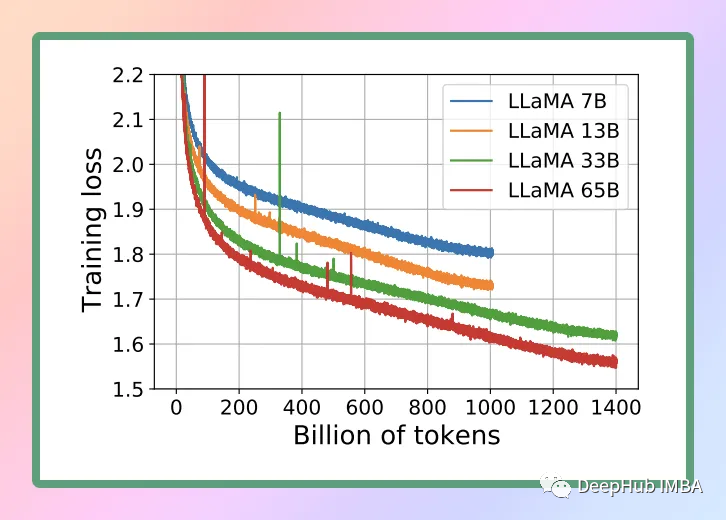
To effectively use the model, we must consider memory and disk space. Since the model needs to be fully loaded into memory, it requires not only sufficient disk space to store them but also enough RAM to load them during execution. For example, the 65B model requires 40GB of RAM even after quantization.
Therefore, to run locally, we will use the minimum version of LLaMA, which is LLaMA 7B. Although it is the smallest version, LLaMA 7B also provides good language processing capabilities, allowing us to efficiently achieve the desired results.
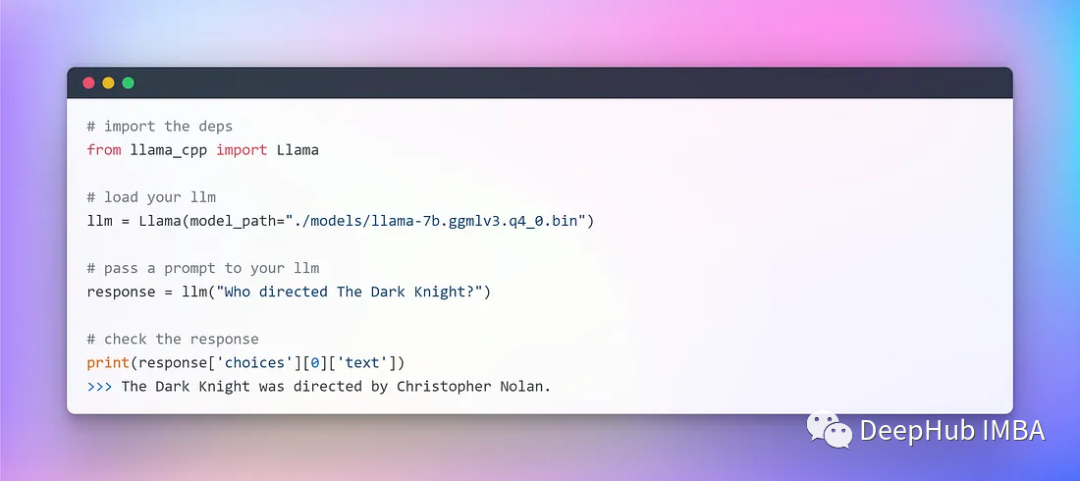
To execute the LLM on the local CPU, we will use the GGML format for the local model. Here, we will directly download the bin file from the Hugging Face Models repository and then move the file to the models directory in the root folder.
As mentioned above, GGML is a C++ library, so we also need to use Python to call the C++ interface. Fortunately, this step is straightforward; we will use llama-cpp-python, which is the Python binding for LLaMA .cpp that serves as the inference for the LLaMA model in pure C/C++. The main goal of .cpp is to run the LLaMA model using 4-bit integer quantization. This allows us to effectively utilize the LLaMA model, taking full advantage of the speed of C/C++ and the benefits of 4-bit integer quantization 🚀.
llama.cpp also supports many other models, as shown in the list below:
Once we have the GGML model and all dependencies ready, we can start integrating with LangChain. However, before we begin, we need to run a test to ensure our LLaMA is available locally:
It seems there are no issues, and the program runs completely offline and in a fully random manner (using temperature hyperparameters).
3. Integrate LLM with LangChain
Now we can use the LangChain framework to develop applications that utilize LLMs.
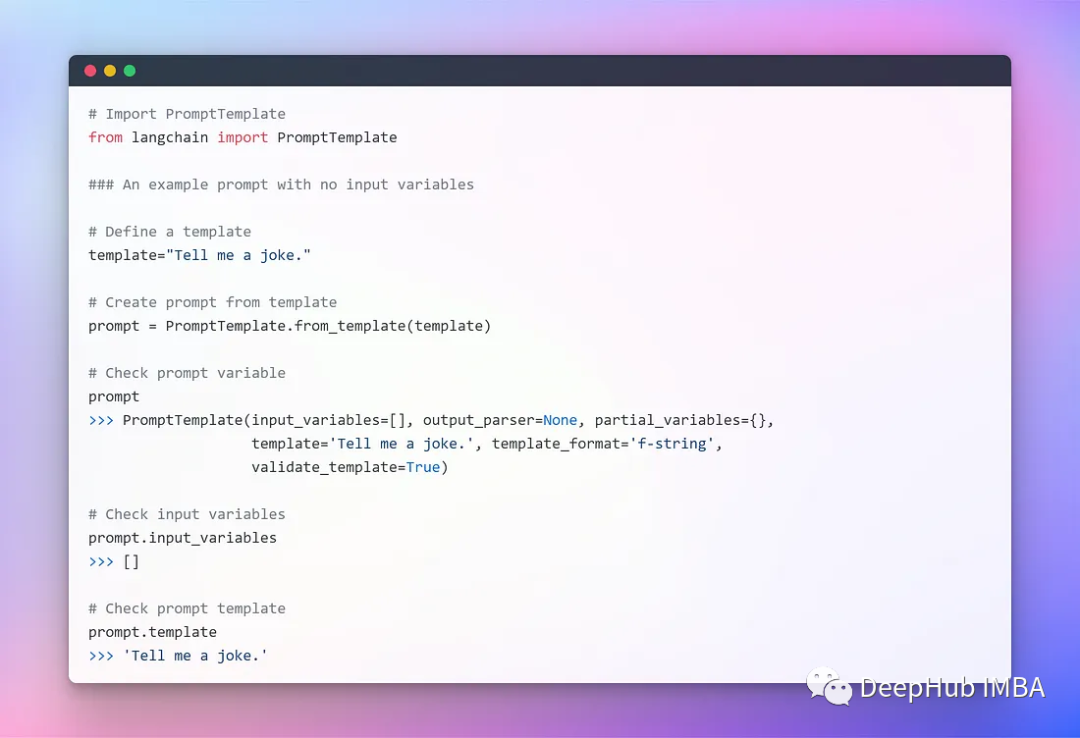
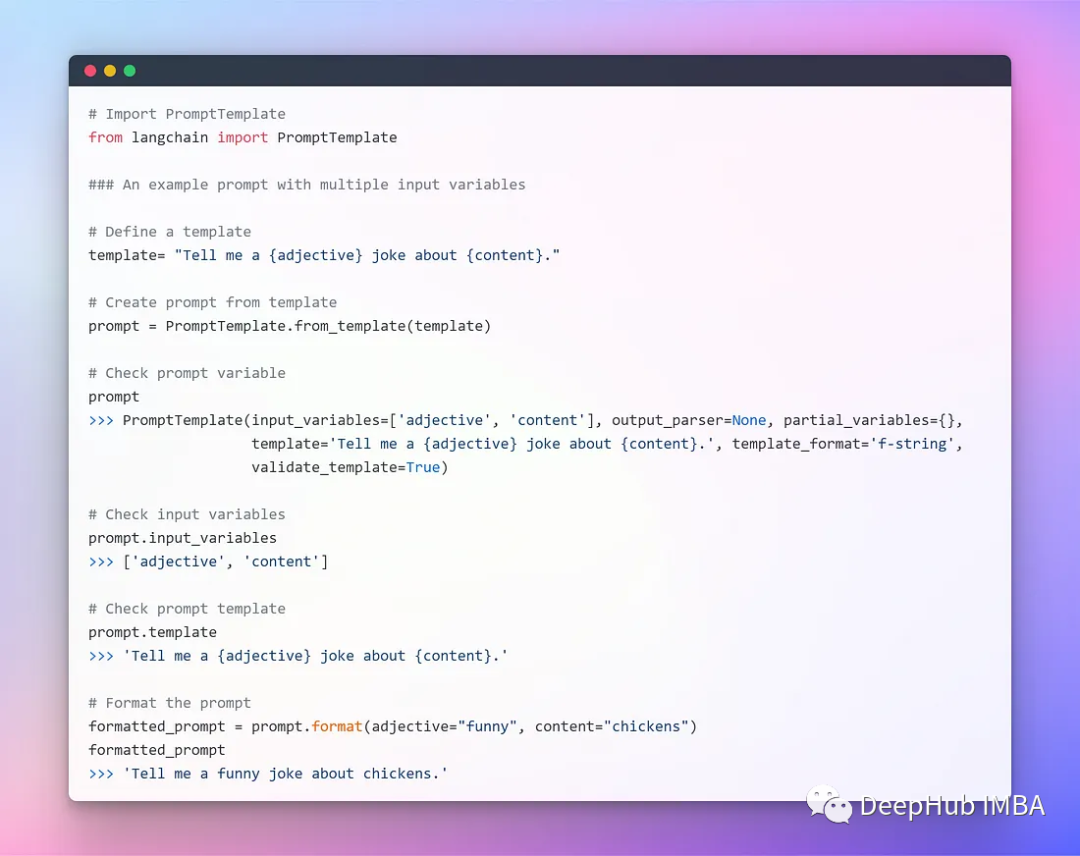
To provide seamless interaction with LLMs, LangChain offers several classes and functions that make it easy to build and use prompts with prompt templates. It includes a text string template that can accept a set of parameters from the end user and generate prompts. Let’s look at a few examples.
Template without Input Parameters
Template with Multiple Parameters
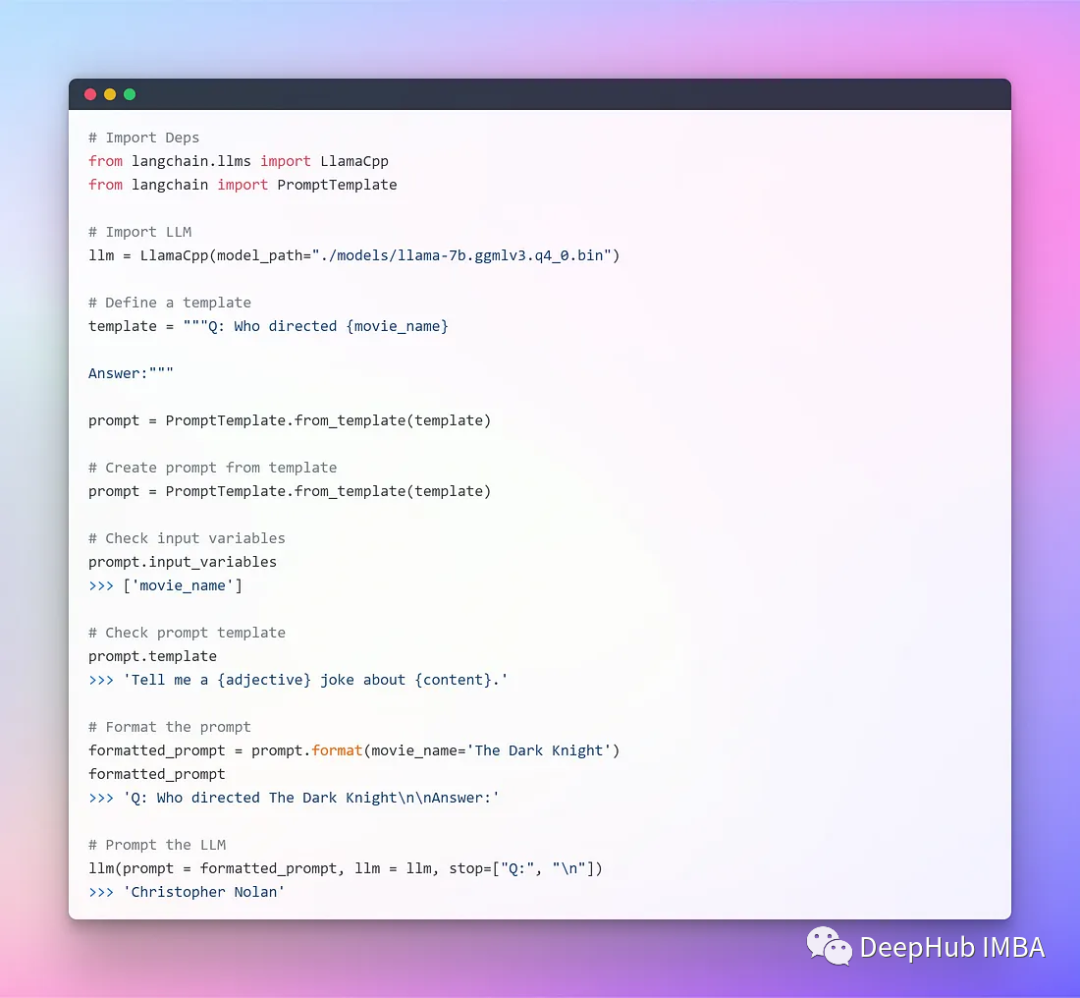
Now we can integrate using LangChain
Currently, we are using separate components, formatting them through prompt templates, and then passing those parameters to the LLM to generate answers. For simple applications, using LLM alone is sufficient, but more complex applications require linking LLMs together—either interlinking them or linking them with other components.
LangChain provides a Chain interface for linking applications 🔗. We can define a Chain as a sequence of calls to components, which may include other Chains. Chains allow us to combine multiple components to create a single, cohesive application. For example, we can create a Chain that takes user input, formats it using a Prompt Template, and then passes the formatted response to the LLM. We can build more complex Chains by combining multiple Chains together or combining them with other components. This is similar to a pipeline in general data processing.
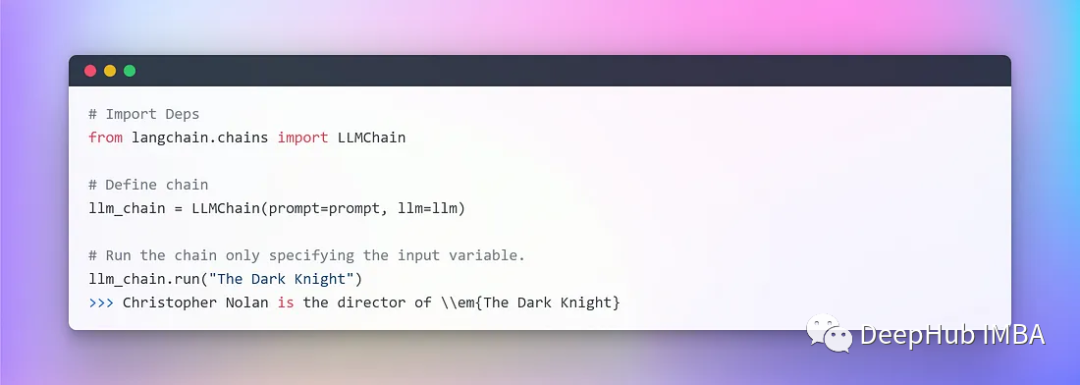
Create a very simple Chain 🔗 that will accept user input, format the prompt using it, and then send it to the LLM using the various components we have created above.
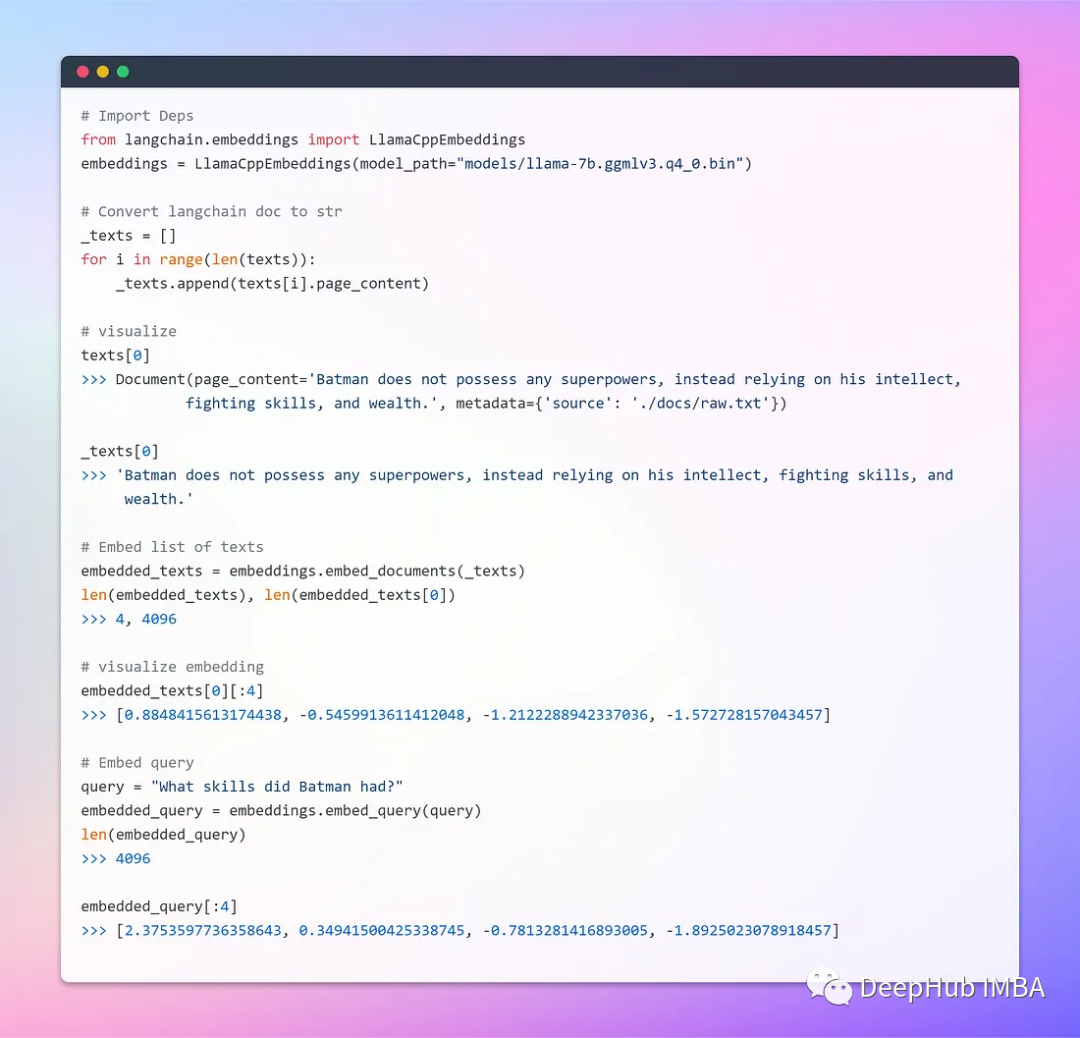
4. Generate Embeddings and Vector Stores
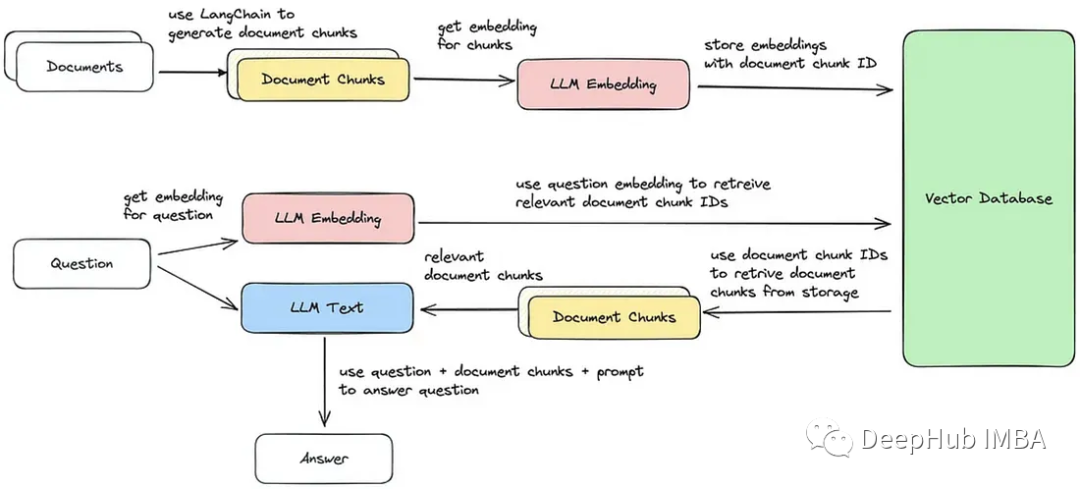
In many LLM applications, user-specific data is needed that is not included in the model’s training set. LangChain provides the essential components for loading, transforming, storing, and querying data, which we can use directly.
The above image contains five components:
-
Document Loader: It is used to load data as documents.
-
Document Converter: It splits documents into smaller chunks.
-
Embedding: It converts chunks into vector representations, i.e., embeddings.
-
Embedding Vector Store: Used to store the aforementioned chunk vectors in a vector database.
-
Retriever: It is used to retrieve a set of vectors that are most similar to the query in the same latent space.
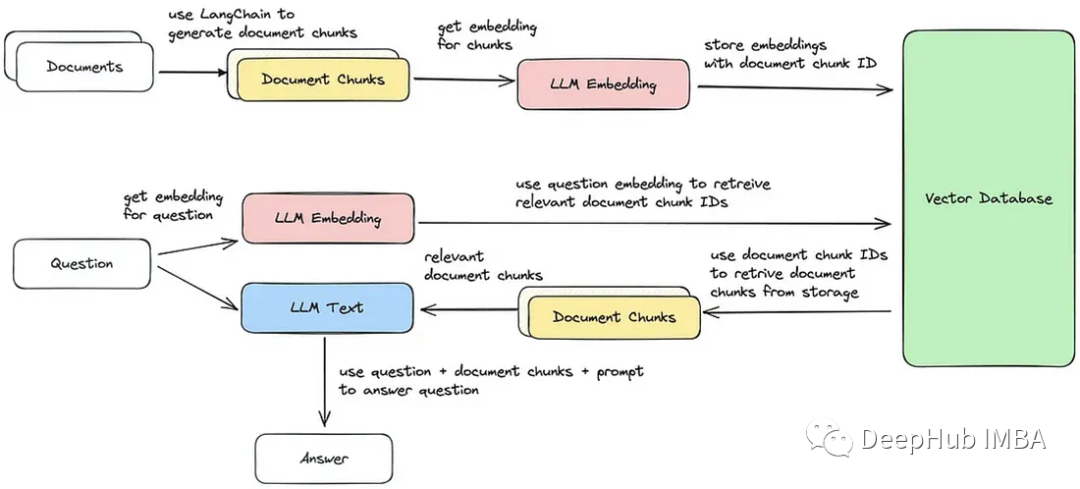
We will implement these five steps, as shown in the flowchart below.
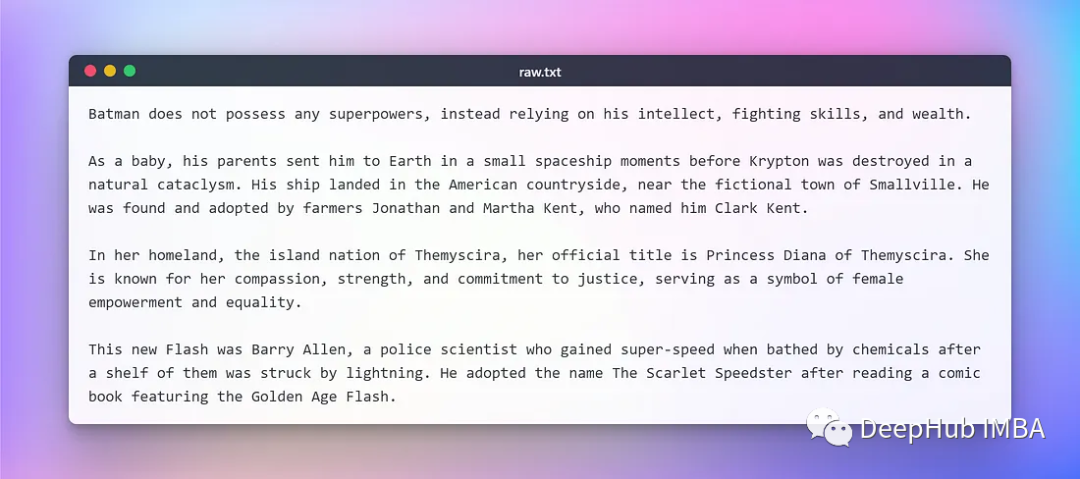
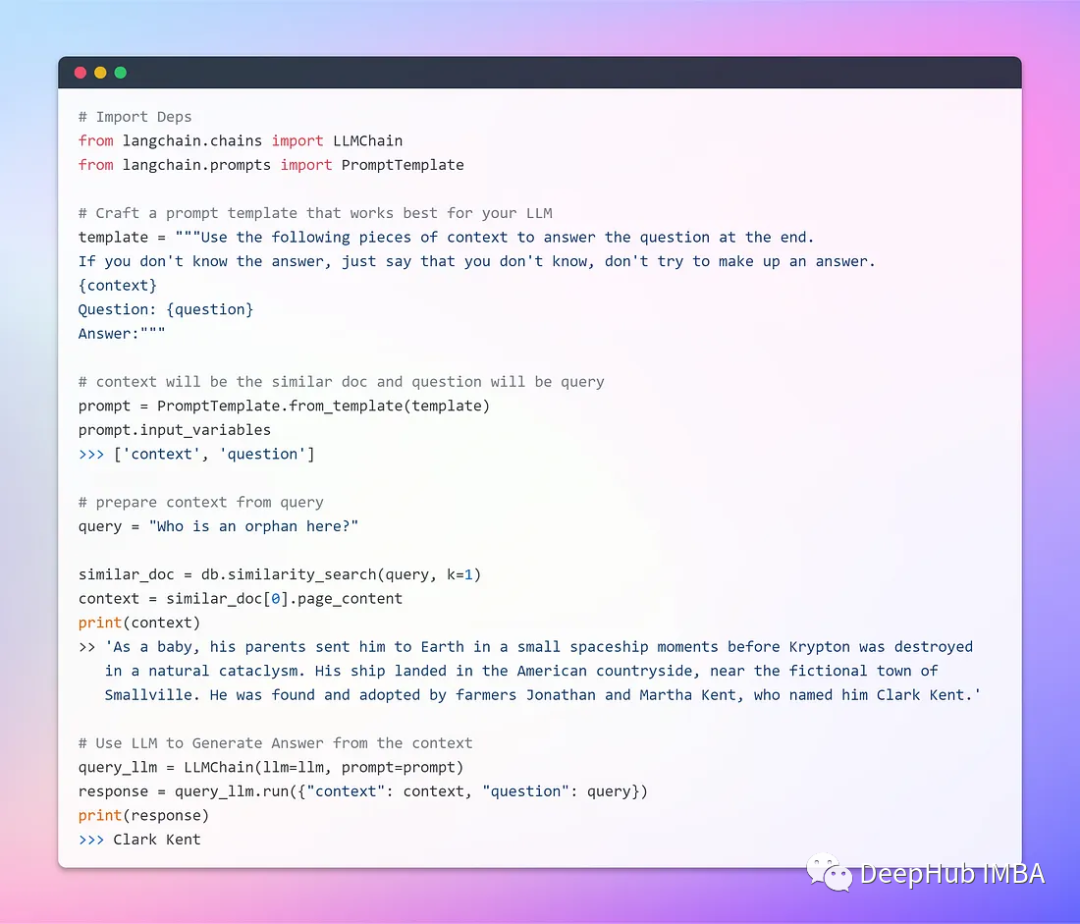
Here we use a segment copied from Wikipedia about some DC superheroes for development testing. The original text is as follows:
a. Load and Transform Document
Create a document object using a text loader (LangChain provides support for multiple documents, allowing different loaders for different documents), retrieve data using the load method, and load it as a document from a pre-configured source.
After loading the document, continue the transformation process by breaking it into smaller chunks using the TextSplitter (by default, the splitter separates documents with the delimiter ‘\n\n’). If the delimiter is set to null and a specific chunk size is defined, each chunk will have the specified length. This results in a list of chunks whose length will equal the document length divided by the chunk size.
Word embeddings are simply a vector representation of a word, where the vector contains real numbers. Word embeddings solve the problem of high dimensionality that simple binary word vectors face by providing a dense representation of words in a low-dimensional vector space.
The base Embeddings class in LangChain exposes two methods: one for embedding documents and another for embedding queries. The former accepts multiple texts as input, while the latter accepts a single text as input.
Since the subsequent retrieval also relies on retrieving the most similar vectors in the same latent space, word vectors must be generated using the same method (model).
c. Create Storage and Retrieval of Documents
Vector storage effectively manages the storage of embedding data and accelerates vector search operations. We will use Chroma, a vector database designed to simplify the development of AI applications containing embeddings. It provides a comprehensive set of built-in tools and functions, and we just need to install it locally using the command pip install chromadb.
Now we can store and retrieve vectors, and the next step is to integrate with the LLM.
At this point, we can already build a Q&A bot using the locally running LLM, and the results are quite good. However, we have a better requirement: a GUI interface.
5. Streamlit
If you prefer running in a command-line manner, this section is completely optional. Here, we will create a web program that allows users to upload any text document. Questions can be posed through text input to analyze the document.
Since file uploads are involved, to prevent potential memory shortage errors, we will simply read the document and write it into a temporary folder, renaming it to raw.txt. This way, regardless of the original name of the document, the TextLoader will handle it seamlessly in the future (assuming: a single user processes only one file at a time).
We will only process txt files, as shown in the code below:
import streamlit as st
from langchain.llms import LlamaCpp
from langchain.embeddings import LlamaCppEmbeddings
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Customize the layout
st.set_page_config(page_title="DOCAI", page_icon="🤖", layout="wide", )
st.markdown(f"""
<style>
.stApp {{background-image: url("https://images.unsplash.com/photo-1509537257950-20f875b03669?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=1469&q=80");
background-attachment: fixed;
background-size: cover}}
</style>
""", unsafe_allow_html=True)
# function for writing uploaded file in temp
def write_text_file(content, file_path):
try:
with open(file_path, 'w') as file:
file.write(content)
return True
except Exception as e:
print(f"Error occurred while writing the file: {e}")
return False
# set prompt template
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer:"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
# initialize hte LLM & Embeddings
llm = LlamaCpp(model_path="./models/llama-7b.ggmlv3.q4_0.bin")
embeddings = LlamaCppEmbeddings(model_path="models/llama-7b.ggmlv3.q4_0.bin")
llm_chain = LLMChain(llm=llm, prompt=prompt)
st.title("📄 Document Conversation 🤖")
uploaded_file = st.file_uploader("Upload an article", type="txt")
if uploaded_file is not None:
content = uploaded_file.read().decode('utf-8')
# st.write(content)
file_path = "temp/file.txt"
write_text_file(content, file_path)
loader = TextLoader(file_path)
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
db = Chroma.from_documents(texts, embeddings)
st.success("File Loaded Successfully!!")
# Query through LLM
question = st.text_input("Ask something from the file", placeholder="Find something similar to: ....this.... in the text?", disabled=not uploaded_file,)
if question:
similar_doc = db.similarity_search(question, k=1)
context = similar_doc[0].page_content
query_llm = LLMChain(llm=llm, prompt=prompt)
response = query_llm.run({"context": context, "question": question})
st.write(response)
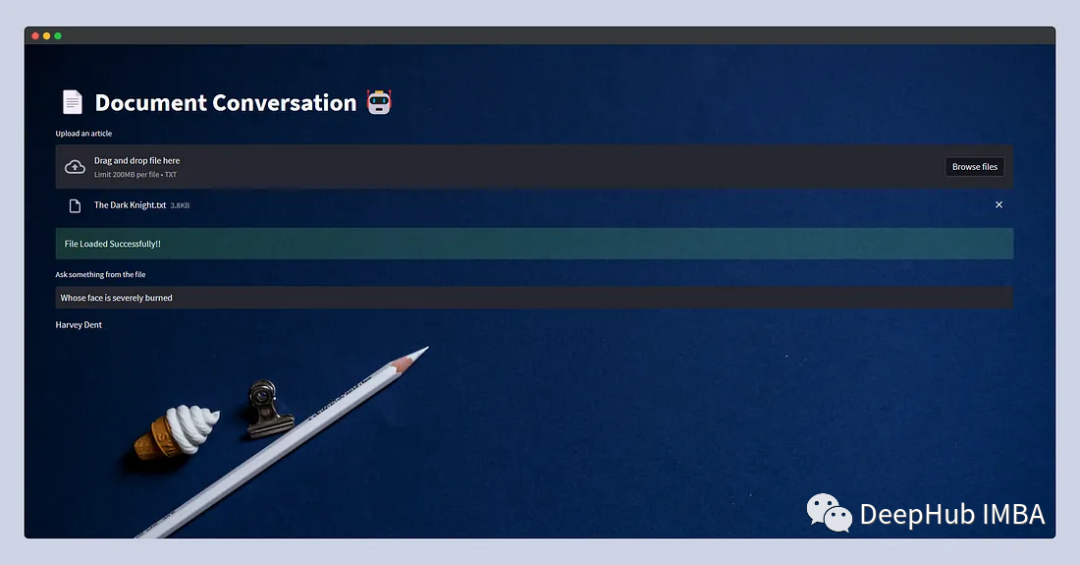
Take a look at our interface:
This simple and functional program is now complete.
Conclusion
With LangChain and Streamlit, we can easily integrate any LLM model, and with GGML, we can run large models on consumer-grade hardware, which is very helpful for our personal research.
If you are interested in this article, here is the complete source code for you to download and use directly:
https://github.com/afaqueumer/DocQA