Source: Biological Large Models
This article is approximately 3000 words long and is suggested to be read in 5 minutes.
This article introduces an innovative biological question reasoning system that combines Retrieval-Augmented Generation (RAG) and Large Language Models (LLM).
In today’s rapidly advancing life sciences field, efficiently processing and answering complex biological questions has always been a significant challenge. As research deepens and interdisciplinary collaboration becomes more frequent, the biological knowledge system has become increasingly vast and complex. To address this challenge, a research team from the Computer Network Information Center of the Chinese Academy of Sciences proposed an innovative framework—BIORAG, which is a biological question reasoning system that combines Retrieval-Augmented Generation (RAG) and Large Language Models (LLM). This article will provide you with a detailed introduction to this groundbreaking research achievement.
Research Background and Challenges
The characteristics of biological research include rapid discoveries, continuously updated insights, and complex interactions between knowledge entities. These characteristics pose unique challenges for maintaining a comprehensive knowledge base and accurate information retrieval. Traditional question-answering systems often struggle with complex queries in the biological field, mainly facing the following three major challenges:
-
Scarcity of high-quality domain-specific corpora. Although the number of biological research papers is vast, there is a lack of extensive, high-quality datasets for building robust information indexing models.
-
The inherent complexity of biological knowledge systems. This complexity is further exacerbated by the interdisciplinary nature of modern biological research. Therefore, automated question-answering systems must be able to understand and handle multifaceted and often ambiguous biological queries.
-
Continuous updates of knowledge. Biology is a dynamic field, with new discoveries emerging constantly, and existing theories frequently revised or replaced. This fluidity requires question-answering systems to flexibly select knowledge sources from databases or contemporary search engines to reflect correct scientific understanding.
Introduction to the BIORAG Framework
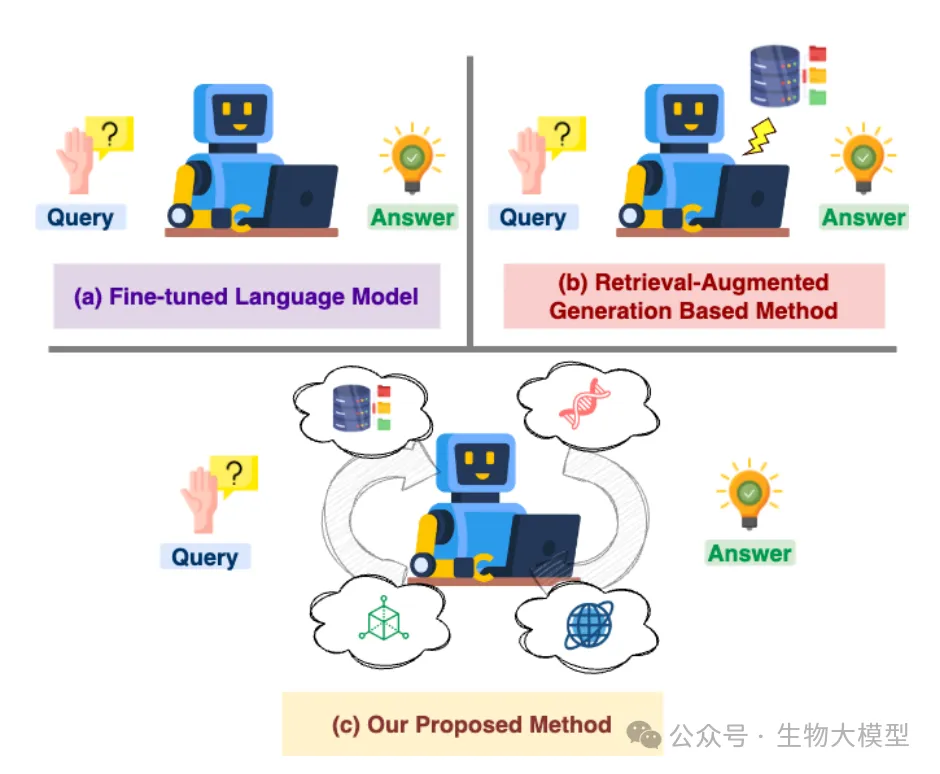
To address the above challenges, the research team proposed the BIORAG framework. This is a novel framework that combines Retrieval-Augmented Generation (RAG) and Large Language Models (LLM). The core idea of BIORAG is to improve the accuracy and efficiency of biological question reasoning by integrating multiple information sources and advanced processing components.
As shown in Figure 1, the BIORAG framework mainly includes the following key components:
-
Internal biological information sources: including pre-processed PubMed paper abstracts and specially trained biological domain embedding models.
-
External information sources: including biological data centers (such as Gene, dbSNP, etc.) and general search engines.
-
Self-assessment information retriever: responsible for selecting the most suitable information sources, preprocessing queries, executing retrieval, and evaluating the sufficiency of retrieval results.
-
Large language model: used for final reasoning and answer generation.
The workflow of the BIORAG framework can be summarized in the following steps:
-
Retriever selection: The system first analyzes the input question and selects the most suitable information source (internal database, external specialized database, or search engine).
-
Query preprocessing: Rewriting the query using a predefined knowledge hierarchy to find relevant topic tags.
-
Retriever execution: Retrieving relevant context from the selected knowledge base.
-
Self-assessment: Evaluating whether the retrieved information is sufficient to answer the question. If not, the system will loop back to use other retrieval tools.
-
Reasoning and generation: Generating the final answer using the collected information.
Innovations and Technical Details
Several key innovations of the BIORAG framework are worth discussing in detail:
-
Building high-quality local information sources
The research team first extracted over 37 million research papers from the globally maintained biomedical article database by NCBI. After strict screening and preprocessing, a total of 22,371,343 high-quality PubMed abstracts were obtained. This vast corpus provides a solid foundation for subsequent information retrieval and reasoning.
-
Specialized biological domain embedding model
To improve retrieval performance, the research team developed a specialized biological embedding model. This model is based on PubMedBERT and fine-tuned using CLIP (Contrastive Language-Image Pretraining) technology. This approach significantly enhances the model’s performance on biological domain texts.
-
MeSH-assisted query preprocessing
BIORAG utilizes the Medical Subject Headings (MeSH) hierarchy to enhance the vector retrieval process. Specifically, the system first trains a model to predict the MeSH terms of the input question, and then constructs MeSH-filtered SQL to generate scalar conditional retrieval. This method effectively simulates the complex relationships between queries and context.
-
BIORAG introduces a self-assessment mechanism that continuously evaluates the sufficiency and relevance of the collected information. If the internal content is insufficient, the model loops back to relevant external knowledge sources. This approach ensures that the system can provide accurate, up-to-date, and comprehensive answers.
-
To maximize the effectiveness of the retrieved corpus and knowledge, BIORAG designs a series of customized prompts. These prompts cover the entire process from retrieval method selection to final answer generation, effectively guiding the reasoning process of the large language model.
Experimental Results and Analysis
The research team conducted extensive experiments on multiple biology-related question-answering datasets to validate the effectiveness of BIORAG. The main experimental results are as follows:
1. Performance on the GeneTuring dataset
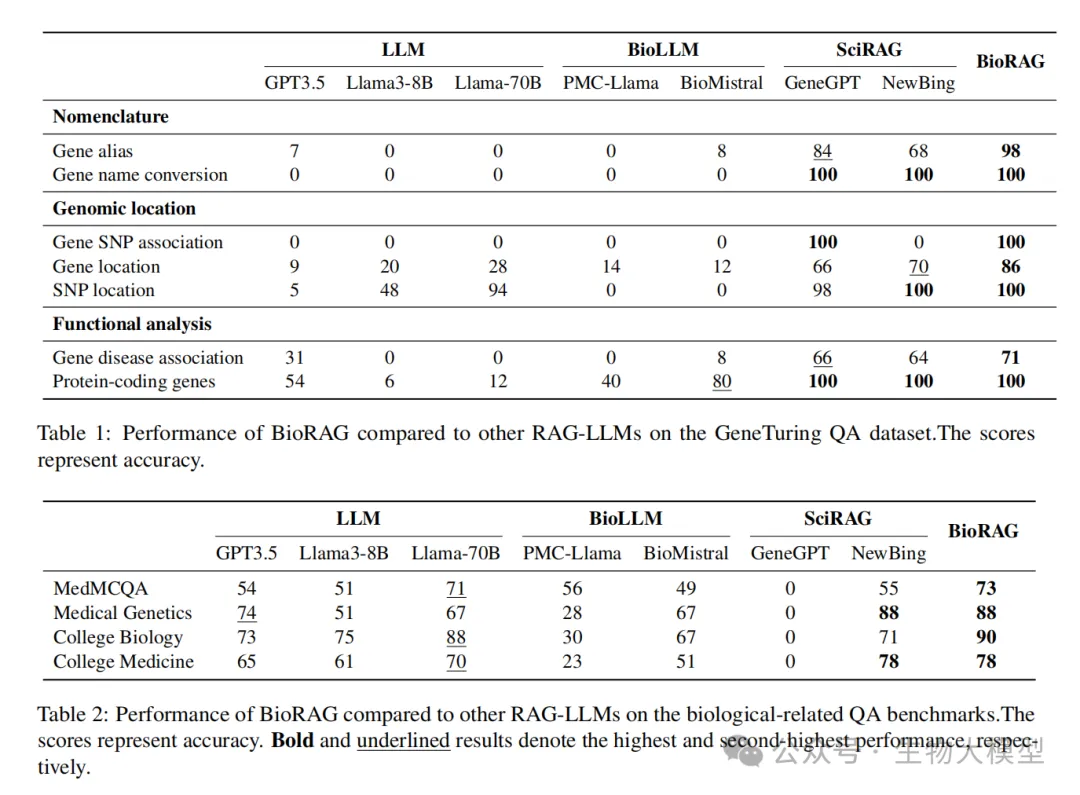
As shown in Table 1, BIORAG achieved the best or second-best performance on most tasks. Especially in naming tasks such as gene aliases and gene name conversions, BIORAG performed excellently. This is mainly due to its access to the Gene database and the integration of search engine results.
In the genomic location task, both BIORAG and GeneGPT achieved 100% accuracy on the gene SNP association subtask, thanks to their access to the dbSNP database. However, in the gene location subtask, BIORAG performed better, as it could handle gene name variants more effectively.
In the functional analysis task, BIORAG combined the Gene database with relevant PubMed papers to achieve optimal performance. This indicates that BIORAG has advantages in handling complex queries that require integrating multiple information sources.
2. Performance on other biology-related question-answering benchmarks
As shown in Table 2, BIORAG performed excellently on datasets such as MedMCQA, Medical Genetics, College Biology, and College Medicine. These results indicate that BIORAG not only excels in specialized biological tasks but also demonstrates strong competitiveness in broader biomedical question-answering tasks.
To evaluate the contributions of each component of BIORAG, the research team conducted detailed ablation studies. The main findings include:
-
The impact of the database: The Gene database plays a crucial role in performance. For example, when this component was removed, the accuracy of the Gene_location task significantly declined.
-
Component contributions: The self-assessment mechanism is vital for maintaining high accuracy in most tasks. The MeSH filter and query rewriting also enhance performance, but their absence does not impact the results as severely as the self-assessment mechanism.
-
The impact of the base language model: Using Llama-3-70B as the base model generally outperformed Llama-3-8B across all tasks, indicating that a larger model size helps better handle complex biological queries.
To visually compare the reasoning differences between BIORAG and other baseline methods, the research team selected three typical cases for analysis:
-
Case from the College Biology dataset
This case demonstrates BIORAG’s self-assessment process. The system first performs a web search to obtain general information but finds the results insufficient to answer the question. Subsequently, BIORAG conducts a second self-assessment, calling upon the more specialized PubMed database. The results of this retrieval are accurate and sufficient, supporting the system in providing the final answer.
-
Case of gene alias tasks from the GeneTuring dataset
This case highlights the challenges of handling gene name variants. BIORAG employs fuzzy queries, generating more relevant responses, each containing detailed gene-related information and descriptions, such as aliases. This enables BIORAG to answer the question accurately, while other methods like NewBing and GeneGPT provide incorrect answers due to insufficient information or improper API usage.
-
Case of gene-disease association tasks from the GeneTuring dataset
This case demonstrates how BIORAG integrates multiple tools (Gene database, local PubMed database, and web search) to collect and mutually confirm gene information related to B-cell immunodeficiency. The reasoning process of BIORAG involves query preprocessing, search execution, and self-assessment at each step to ensure comprehensive and accurate results. In contrast, NewBing and GeneGPT provide inaccurate answers due to reliance on non-specialized sources or selecting incorrect APIs.
The BIORAG framework significantly improves the accuracy and efficiency of biological question reasoning by innovatively integrating Retrieval-Augmented Generation and Large Language Models. It addresses challenges such as the scarcity of high-quality domain-specific corpora, the complexity of biological knowledge systems, and the continuous updating of knowledge. Through extensive validation, including rigorous testing on widely recognized biological QA datasets and numerous case studies, BIORAG demonstrates its exceptional capability in handling complex biological queries.
This research not only provides a new paradigm for biological question-answering systems but also offers insights for knowledge-intensive tasks in other fields. Future research directions may include:
-
Further expanding and optimizing the integration of external knowledge sources to tackle a broader range of biological questions.
-
Exploring how to utilize the reasoning capabilities of large language models more effectively to enhance the system’s interpretability.
-
Researching how to apply the BIORAG framework to other scientific fields, such as chemistry and physics.
-
Developing more efficient self-assessment mechanisms to further improve the system’s accuracy and efficiency.
-
Exploring how to combine BIORAG with other advanced AI technologies (such as image recognition, multimodal learning, etc.) to tackle more complex biological tasks.
Wang C, Long Q, Meng X, et al. BioRAG: A RAG-LLM Framework for Biological Question Reasoning[J]. arXiv preprint arXiv:2408.01107, 2024.
DataPai THU, as a public account focused on data science, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a platform for gathering data talents, creating the strongest group of big data in China.

Sina Weibo: @DataPaiTHU
WeChat Video Account: DataPaiTHU
Today’s Headlines: DataPaiTHU