
Transformers shine in the field of computer vision, and the Detection Transformer (DETR) is a successful application of Transformers in object detection. By utilizing the attention mechanism in Transformers, it effectively models long-range dependencies in images, simplifying the object detection pipeline and constructing an end-to-end object detector.
Object detection can be understood as a set prediction task (predicting a collection of bounding boxes and classification labels). Existing object detection algorithms require defining regression and classification tasks on a large number of proposals/anchors, whereas DETR achieves object detection through set prediction.
Advantages:
- No need for predefined prior anchors
- No need for NMS post-processing strategy
- Increased transformer encoding structure
- Directly predicts the position and category of boxes through a feedforward neural network
Disadvantages:
- DETR performs best on large objects, while it is slightly worse on small objects
- Match-based loss makes learning difficult to converge, making it hard to learn optimal situations
This article analyzes the modules of DETR one by one, which mainly include:
- Backbone module
- Positional encoding module
- Transformer encoding module
- Transformer decoding module
- Feedforward neural network module (FNNs)
- Hungarian algorithm matching module
- Loss function module
Module diagram from the paper:
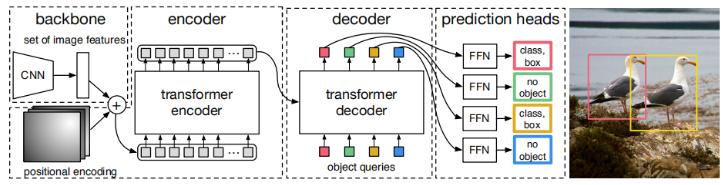
1. Backbone Module
The backbone module is responsible for extracting image features. The basic version of DETR uses a pre-trained ResNet-50 from torchvision, freezing the BN layer parameters during training. Assuming the input image dimensions are (2,3,768,1024), convolution processing is performed to obtain the word embedding dimensions, and finally, through flatten() and permute(), the feature map dimensions are obtained.
To facilitate understanding, assume the input image dimensions are: (2,3,768,1024)
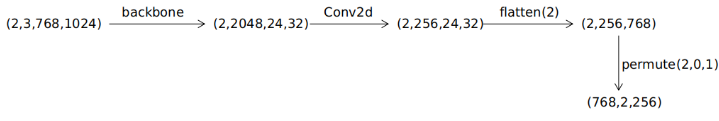
2. Positional Encoding Module
The positional encoding module represents each pixel point of the object with the corresponding embedding vector. The dimension of the embedding vector is d_model, and the embedding vector for each pixel point includes embedding vectors in the y and x directions, each with a dimension of d_model//2. Finally, the dimensions of the y and x directions are concatenated to obtain the embedding vector dimension d_model.
To facilitate understanding, assume the mask dimensions after the backbone processing of the input image are: (2,24,32)

As noted in the previous section, the dimensions of the outputs from the backbone module and the positional encoding module are the same, so the outputs of the two are added together to obtain the Q and K vectors for the transformer encoding module.
3. Transformer Encoding Module
As introduced in the previous section, the Q and K vectors for the transformer encoding module come from the sum of the outputs from the backbone module and the positional encoding module of the image. The green box in the following figure indicates this:
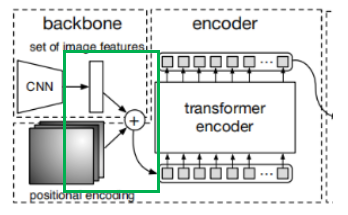
The V vector comes from the output of the backbone module.
Then, through the multi-head attention mechanism, the output vector is obtained. The multi-head attention mechanism refers to the article that analyzes the structure of Transformer module by a big shot.
Finally, through the residual module and layer normalization module, the output vector of the encoding is obtained.
Dimensions are represented as:
Q vector: tensor(768,2,256)
K vector: tensor(768,2,256)
V vector: tensor(768,2,256)
Output vector dimension after the multi-head attention mechanism: tensor(768,2,256)
4. Transformer Decoding Module
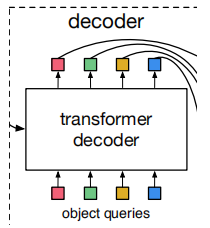
As shown in the figure, object queries are essentially N learnable embedding dimension parameters, initialized to 0 at the start of training, and the corresponding positional encoding module is randomly initialized. The number of object queries is predefined, with the default in the code being 100. Its significance is: based on the features encoded by the Encoder, the Decoder transforms 100 queries into 100 targets, i.e., ultimately predicting the categories and bbox positions of these 100 targets. The final predicted shape should be [N, 100, C], where N is the Batch Num, 100 targets, C is the number of predicted categories for the 100 targets + 1 (background class) and bbox position (4 values).
The decoding module has two self-attention mechanism modules.
The first self-attention mechanism’s Q and K vectors are the object queries vector added to the corresponding positional encoding module’s query_pos vector, while the V vector is the object queries vector. The flow is illustrated in the following figure:
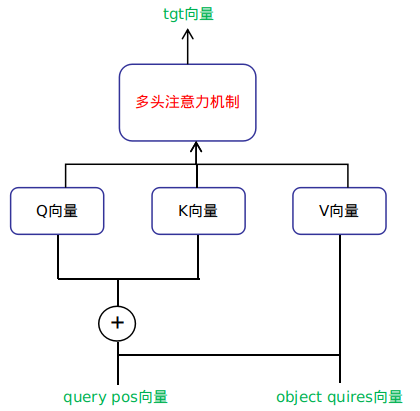
The Q vector of the second self-attention mechanism comes from the output vector tgt of the previous self-attention mechanism module added to the corresponding positional encoding module’s query_pos vector. The K vector comes from the output memory vector of the backbone module added to the corresponding positional encoding module’s pos_embed vector, while the V vector comes from the output memory vector of the backbone module.
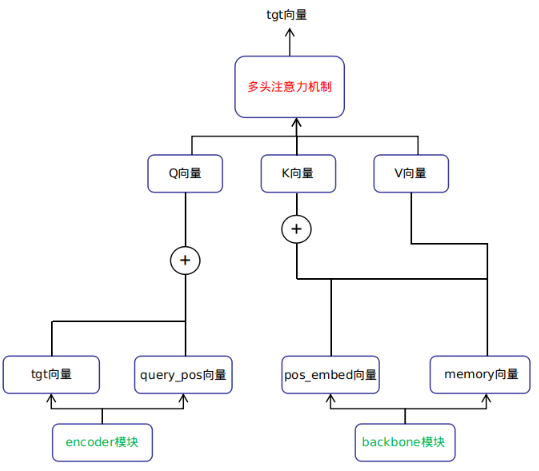
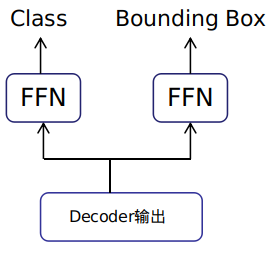
5. Feedforward Neural Network Module (FFNs)
The feedforward neural network module completes the classification + bbox prediction task on the data output from the transformer structure, with two FFNs sharing the output of the transformer.
-
The classification class FNN uses a simple one-layer linear layer, accepting a vector of dimensions (100,C+1), where C+1 is the number of categories in the dataset + the number of backgrounds.
-
The bbox prediction FNN uses a three-layer MLP, accepting an input of dimension (100,256), with dimension changes as (100,256) -> (100,512) -> (100,4). Both of the first two layers are followed by a ReLU activation function, and the last layer is followed by a sigmoid function. The final output dimension is (100,4), representing the four bbox coordinates of the target (x,y,w,h).
As shown in the figure:
Decoder output vector: tensor(6,bs,100,256)
Class output vector: tensor(6,bs,100,C+1), where C is the number of categories
Bounding Box vector: tensor(6,Bs,100,4)
6. Hungarian Algorithm Matching Module
After the feedforward neural network module obtains the predicted classes and predicted boxes, a bipartite matching is performed using the Hungarian algorithm. If there are K real targets, then K of the 100 predicted boxes will match these K real targets, while the others will match with ‘no object’, theoretically ensuring that each object query has a unique matched target without overlap, thus DETR does not require NMS post-processing.
The input vector for Hungarian algorithm matching is the loss matrix. If the number of predicted boxes is N and the number of real boxes is M, then the shape of the loss matrix is (N,M), representing the loss value of each predicted box against all real boxes. As shown in the figure:
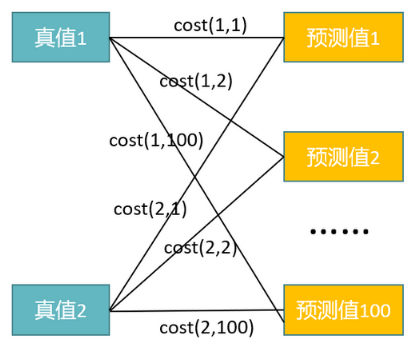
The Hungarian algorithm obtains the matching items of predicted boxes and real boxes based on the principle of minimizing the total matching loss value.
7. Loss Function Module
The loss function module calculates class loss and predicted box loss.
-
The class loss module calculates the loss for all predicted boxes.
-
The predicted box loss calculates the L1 loss and GIoU loss of the matched predicted boxes.
DETR paper link: https://arxiv.org/abs/2005.12872
Official code: https://github.com/facebookresearch/detr
Since the official code does not include an inference module, this article includes the inference code inference.py.
This concludes the content; if you are interested, feel free to scan the code and follow along. Thank you:
import argparse
import random
import time
from pathlib import Path
import numpy as np
import torch
from models import build_model
from PIL import Image
import os
import torchvision
from torchvision.ops.boxes import batched_nms
import cv2
def get_args_parser():
parser = argparse.ArgumentParser('Set transformer detector', add_help=False)
parser.add_argument('--lr', default=1e-4, type=float)
parser.add_argument('--lr_backbone', default=1e-5, type=float)
parser.add_argument('--batch_size', default=2, type=int)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--epochs', default=300, type=int)
parser.add_argument('--lr_drop', default=200, type=int)
parser.add_argument('--clip_max_norm', default=0.1, type=float, help='gradient clipping max norm')
# Model parameters
parser.add_argument('--frozen_weights', type=str, default=None, help="Path to the pretrained model. If set, only the mask head will be trained")
# * Backbone
# If set to resnet101, the subsequent weight file path must also be modified
parser.add_argument('--backbone', default='resnet50', type=str, help="Name of the convolutional backbone to use")
parser.add_argument('--dilation', action='store_true', help="If true, we replace stride with dilation in the last convolutional block (DC5)")
parser.add_argument('--position_embedding', default='sine', type=str, choices=('sine', 'learned'), help="Type of positional embedding to use on top of the image features")
# * Transformer
parser.add_argument('--enc_layers', default=6, type=int, help="Number of encoding layers in the transformer")
parser.add_argument('--dec_layers', default=6, type=int, help="Number of decoding layers in the transformer")
parser.add_argument('--dim_feedforward', default=2048, type=int, help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=256, type=int, help="Size of the embeddings (dimension of the transformer)")
parser.add_argument('--dropout', default=0.1, type=float, help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int, help="Number of attention heads inside the transformer's attentions")
parser.add_argument('--num_queries', default=100, type=int, help="Number of query slots")
parser.add_argument('--pre_norm', action='store_true')
# * Segmentation
parser.add_argument('--masks', action='store_true', help="Train segmentation head if the flag is provided")
# Loss
parser.add_argument('--no_aux_loss', dest='aux_loss', default='False', help="Disables auxiliary decoding losses (loss at each layer)")
# * Matcher
parser.add_argument('--set_cost_class', default=1, type=float, help="Class coefficient in the matching cost")
parser.add_argument('--set_cost_bbox', default=5, type=float, help="L1 box coefficient in the matching cost")
parser.add_argument('--set_cost_giou', default=2, type=float, help="giou box coefficient in the matching cost")
# * Loss coefficients
parser.add_argument('--mask_loss_coef', default=1, type=float)
parser.add_argument('--dice_loss_coef', default=1, type=float)
parser.add_argument('--bbox_loss_coef', default=5, type=float)
parser.add_argument('--giou_loss_coef', default=2, type=float)
parser.add_argument('--eos_coef', default=0.1, type=float, help="Relative classification weight of the no-object class")
# dataset parameters
parser.add_argument('--dataset_file', default='coco')
parser.add_argument('--coco_path', type=str, default="coco")
parser.add_argument('--coco_panoptic_path', type=str)
parser.add_argument('--remove_difficult', action='store_true')
# Detection image path
parser.add_argument('--source_dir', default='demo/images', help='path where to save, empty for no saving')
# Path to save detection results
parser.add_argument('--output_dir', default='demo/outputs', help='path where to save, empty for no saving')
parser.add_argument('--device', default='cuda:0', help='device to use for training / testing')
parser.add_argument('--seed', default=42, type=int)
# Weight file corresponding to resnet50
parser.add_argument('--resume', default='demo/weights/detr-r50-e632da11.pth', help='resume from checkpoint')
parser.add_argument('--start_epoch', default=0, type=int, metavar='N', help='start epoch')
parser.add_argument('--eval', default="True")
parser.add_argument('--num_workers', default=2, type=int)
# Distributed training parameters
parser.add_argument('--world_size', default=1, type=int, help='number of distributed processes')
parser.add_argument('--dist_url', default='env://', help='url used to set up distributed training')
return parser
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox) # out_bbox(100,4),cx,cy,w,h,b(100,4),x1,y1,x2,y2
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)
return b
def filter_boxes(scores, boxes, confidence=0.7, apply_nms=True, iou=0.5):
keep = scores.max(-1).values > confidence # tensor(100)
scores, boxes = scores[keep], boxes[keep] #(27,91),(27,4)
if apply_nms:
top_scores, labels = scores.max(-1)
keep = batched_nms(boxes, top_scores, labels, iou)
scores, boxes = scores[keep], boxes[keep]
return scores, boxes
# COCO classes
CLASSES = [
'N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse',
'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack',
'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis',
'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass',
'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake',
'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A',
'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A',
'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier',
'toothbrush']
def plot_one_box(x, img, color=None, label=None, line_thickness=1):
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
def main(args):
print(args)
device = torch.device(args.device)
model, criterion, postprocessors = build_model(args)
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'], False)
model.to(device)
n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("parameters:", n_parameters)
image_Totensor = torchvision.transforms.ToTensor()
image_file_path = os.listdir(args.source_dir)
for image_item in image_file_path:
print("inference_image:", image_item)
image_path = os.path.join(args.source_dir, image_item)
image = Image.open(image_path)
image_tensor = image_Totensor(image) # tensor(c,h,w)
image_tensor = torch.reshape(image_tensor, [-1, image_tensor.shape[0], image_tensor.shape[1], image_tensor.shape[2]])
image_tensor = image_tensor.to(device)
time1 = time.time()
inference_result = model(image_tensor) # 'pred_logits':(1,100,92),'pred_boxes':(1,100,4),list(5)
time2 = time.time()
print("inference_time:", time2 - time1)
probas = inference_result['pred_logits'].softmax(-1)[0, :, :-1].cpu() # 得到除了背景类的前景,(100,91)
bboxes_scaled = rescale_bboxes(inference_result['pred_boxes'][0,].cpu(), (image_tensor.shape[3], image_tensor.shape[2])) # (100,4)
scores, boxes = filter_boxes(probas, bboxes_scaled) #(100,91),(100,4)
scores = scores.data.numpy()
boxes = boxes.data.numpy()
for i in range(boxes.shape[0]):
class_id = scores[i].argmax()
label = CLASSES[class_id]
confidence = scores[i].max()
text = f"{label} {confidence:.3f}"
print(text)
image = np.array(image)
plot_one_box(boxes[i], image, label=text)
cv2.imshow("images", cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
cv2.waitKey()
image = Image.fromarray(image)
image.save(os.path.join(args.output_dir, image_item))
if __name__ == '__main__':
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)Welcome to scan and follow:
