Click the above “Beginner’s Guide to Vision“, select to add “Starred” or “Pinned“
Important content delivered promptly
Jishi Guide
The author summarizes their experience in the conversion of models from Pytorch to ONNX, mainly introducing the significance of this conversion work, the path for model deployment, and the limitations of Pytorch itself.
In the past few months, I participated in the conversion of models to ONNX in OpenMMlab (github account: drcut), with the main goal of supporting the conversion of some models from Pytorch to ONNX. Although I haven’t achieved much in these months, I’ve encountered many pitfalls, and I’m documenting them here in hopes of helping others.
This is the first part, a theoretical section, mainly discussing some macro issues unrelated to code. Next, I will write a practical section specifically analyzing some specific codes in OpenMMlab, explaining some coding techniques and precautions in the conversion process from Pytorch to ONNX.
(1) Significance of Converting Pytorch to ONNX
Generally speaking, converting to ONNX is merely a means. After obtaining the ONNX model, further conversions may be necessary, such as converting to TensorRT for deployment, or some may add an intermediate step of converting from ONNX to Caffe, and then from Caffe to TensorRT. The reason is that Caffe is more friendly to TensorRT, and I will discuss the definition of friendly later.
Therefore, before starting the ONNX conversion work, it is essential to clarify the target backend. ONNX is just a format, similar to JSON. As long as certain rules are met, it is considered valid. Thus, simply converting from Pytorch to an ONNX file is quite straightforward. However, the ONNX accepted by different backend devices varies, which is the source of many pitfalls.
The ONNX generated by Pytorch’s built-in torch.onnx.export, the ONNX required by ONNXRuntime, and the ONNX needed by TensorRT are all different.
Here’s a simple example of Maxpool:
Maxunpool can be seen as the inverse operation of Maxpool. Let’s first look at an example of Maxpool. Suppose we have a tensor of shape C*H*W (shape [2, 3, 3]), where each channel’s 2D matrix is the same as follows:


In this case, if we call MaxPool (kernel_size=2, stride=1, pad=0) on it in Pytorch,
we will get two outputs. The first output is the value after Maxpool:


The other is the Maxpool Idx, which indicates which output corresponds to which original input, allowing the gradient of the output to be directly passed to the corresponding input during backpropagation:


Careful readers may notice that the Maxpool Idx can actually have another representation:

 ,
,
which places the idx of each channel together, rather than starting from 0 for each channel individually. Both representations are valid as long as they remain consistent during backpropagation.
However, when I was supporting OpenMMEditing, I encountered Maxunpool, which is the inverse operation of Maxpool: given MaxpoolId and the output of Maxpool, we obtain the input of Maxpool.
Pytorch’s MaxUnpool implementation expects each channel’s idx to start from 0, while Onnxruntime requires the opposite. Therefore, if you want to achieve the same results using Onnxruntime, you must perform additional processing on the input Idx (i.e., the input that matches Pytorch). In other words, the neural network graph output by Pytorch and the neural network graph required by ONNXRuntime are different.
(2) ONNX and Caffe
There are two mainstream paths for model deployment, taking TensorRT as an example: one is Pytorch -> ONNX -> TensorRT, and the other is Pytorch -> Caffe -> TensorRT. Personally, I believe the latter is currently more mature, mainly due to the properties of ONNX, Caffe, and TensorRT.
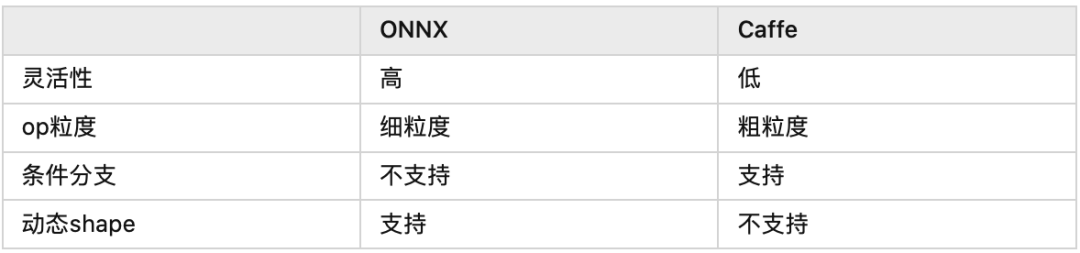
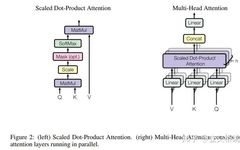
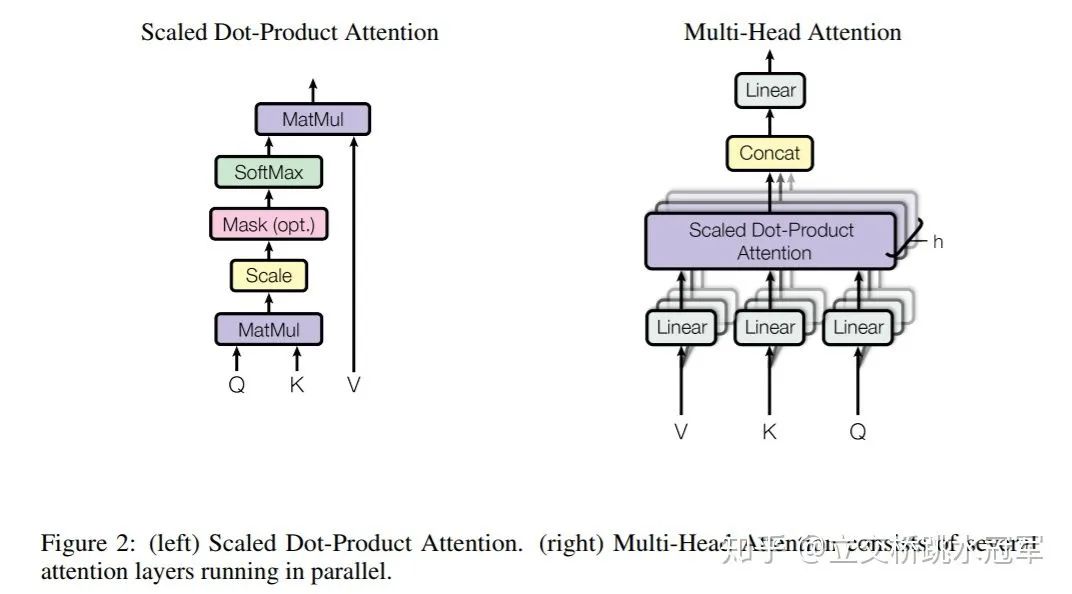
The table above lists some key differences between ONNX and Caffe, with the most important difference being the granularity of ops. For example, if we convert the Attention layer of Bert, ONNX will break it down into a combination of MatMul, Scale, and SoftMax, while Caffe may generate a layer directly called Multi-Head Attention and tell CUDA engineers: “You go write a big kernel” (I suspect that eventually, ResNet50 will be turned into a single layer…).
tensor i = funcA();
if(i==0)
j = funcB(i);
else
j = funcC(i);
funcD(j);
tensor i = funcA();
coarse_func(tensor i) {
if(i==0) return funcB(i);
else return funcC(i);
}
funcD(coarse_func(i))
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of the "Beginner's Guide to Vision" public account to download the first comprehensive OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of the "Beginner's Guide to Vision" public account to download 31 vision practical projects, including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Discussion Group
Welcome to join the reader group of the public account to exchange ideas with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat number below to join the group, and note: "nickname + school/company + research direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, your request will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed. Thank you for your understanding~