Source: “Communications of the China Computer Federation”, Issue 8, “Special Topic”
Author: Wang Xiaogang
History of Deep Learning Development
Deep learning is a significant breakthrough in the field of artificial intelligence over the past decade. It has achieved great success in various fields such as speech recognition, natural language processing, computer vision, image and video analysis, and multimedia. Existing deep learning models belong to neural networks. The origin of neural networks can be traced back to the 1940s, and they were popular in the 1980s and 1990s. Neural networks attempt to solve various machine learning problems by simulating the cognitive mechanisms of the brain. In 1986, Rumelhart, Hinton, and Williams published the famous backpropagation algorithm in the journal Nature for training neural networks[1], which is still widely used today.
Neural networks have a large number of parameters and often suffer from overfitting. Although their recognition accuracy is very high on the training set, their performance on the test set is poor. This is because the training datasets at that time were relatively small, and computing resources were limited, making it time-consuming to train even a small network. Compared to other models, neural networks did not show significant advantages in recognition accuracy.
As a result, more scholars began to adopt classifiers such as support vector machines, boosting, and nearest neighbors. These classifiers can be simulated using a neural network with one or two hidden layers, thus referred to as shallow machine learning models. In these models, different systems are often designed for different tasks, employing various handcrafted features. For instance, object recognition uses Scale Invariant Feature Transform (SIFT), face recognition uses Local Binary Patterns (LBP), and pedestrian detection uses Histogram of Oriented Gradient (HOG) features.
In 2006, Hinton proposed deep learning. Since then, deep learning has achieved great success in many fields and received widespread attention. There are several reasons why neural networks have rejuvenated: first, the emergence of large-scale training data has greatly alleviated the problem of overfitting. For example, the ImageNet[2] training set contains millions of labeled images. Secondly, the rapid development of computer hardware has provided powerful computing capabilities, with a single GPU chip integrating thousands of cores. This has made it possible to train large-scale neural networks. Thirdly, significant progress has been made in the design and training methods of neural network models. For example, to improve the training of neural networks, scholars have proposed unsupervised and layer-wise pre-training, allowing the network parameters to reach a good starting point before performing global optimization using the backpropagation algorithm, which helps achieve a better local minimum at the end of training.
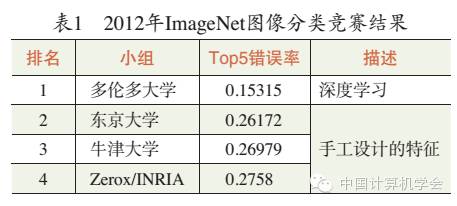
The most influential breakthrough of deep learning in the field of computer vision occurred in 2012 when Hinton’s research group won the ImageNet image classification competition using deep learning[3]. The teams ranked second to fourth used traditional computer vision methods and handcrafted features, with their accuracy differences not exceeding 1%. Hinton’s research group achieved more than 10% higher accuracy than the second place (see Table 1). This result caused a huge stir in the field of computer vision and sparked a deep learning craze.
Another important challenge in the field of computer vision is face recognition. Research has shown[5] that if only the center region of a face excluding hair is shown to people, the recognition rate on the Labeled Faces in the Wild (LFW) database is 97.53%. If the entire image, including the background and hair, is shown, the recognition rate is 99.15%. The classic face recognition algorithm Eigenface[6] has only a 60% recognition rate on the LFW test set. Among non-deep learning algorithms, the highest recognition rate is 96.33%[7]. Currently, deep learning can achieve a recognition rate of 99.47%[8].
Six months after Hinton’s research group won the ImageNet competition, both Google and Baidu released new image content-based search engines. They used deep learning models applied to their respective data, finding that the accuracy of image searches improved significantly. Baidu established a deep learning research institute in 2012 and opened a new deep learning lab in Silicon Valley in May 2014, hiring Stanford University professor Andrew Ng as chief scientist. Facebook established a new artificial intelligence lab in New York in December 2013, hiring renowned deep learning scholar and convolutional network inventor Yann LeCun as chief scientist. In January 2014, Google offered $400 million to acquire the deep learning startup DeepMind. Given the significant impact of deep learning in academia and industry, MIT Technology Review ranked it as the top technology breakthrough in the world in 2013.
What Makes Deep Learning Unique?
What are the key differences between deep learning and other machine learning methods, and why has it succeeded in many fields?
Feature Learning
The biggest difference between deep learning and traditional pattern recognition methods is that the features it uses are automatically learned from big data rather than being designed manually. Good features can improve the performance of pattern recognition systems. For decades, handcrafted features have dominated various applications in pattern recognition. Handcrafted design mainly relies on the designer’s prior knowledge, making it difficult to leverage the advantages of big data. Due to reliance on manual parameter tuning, the number of parameters allowed in feature design is very limited. Deep learning can automatically learn feature representations from big data, which can include thousands of parameters.
It often takes five to ten years to design effective features manually, while deep learning can quickly learn new effective feature representations from training data for new applications.
A pattern recognition system consists of two parts: features and classifiers. In traditional methods, the optimization of features and classifiers is separate. However, within the framework of neural networks, feature representation and classifiers are jointly optimized, maximizing the performance of their collaboration.
The feature representation of the convolutional network model[9] used by Hinton in the ImageNet competition contains 60 million parameters learned from millions of samples. The feature representation learned from ImageNet has strong generalization capabilities and can be successfully applied to other datasets and tasks, such as object detection, tracking, and retrieval. Another well-known competition in the field of computer vision is PSACAL VOC. However, its training set is relatively small and not suitable for training deep learning models. Scholars have used feature representations learned from ImageNet for object detection on PSACAL VOC, improving the detection rate by 20%[10].
Since feature learning is so important, what constitutes a good feature? Various complex factors in an image are often combined non-linearly. For example, a face image contains information about identity, pose, age, expression, and lighting. The key to deep learning is successfully separating these factors through multi-layer non-linear mappings. For instance, in the last hidden layer of a deep model, different neurons represent different factors. If this hidden layer is treated as feature representation, tasks such as face recognition, pose estimation, expression recognition, and age estimation become very simple, as the relationships between the factors become simple linear relationships without mutual interference.
Advantages of Deep Structures
The term “deep” in deep learning models signifies that the neural network structure is deep and consists of many layers. Other commonly used machine learning models, such as support vector machines and boosting, are shallow structures. A three-layer neural network model (including the input layer, output layer, and one hidden layer) can approximate any classification function. If this is the case, why do we need deep models?
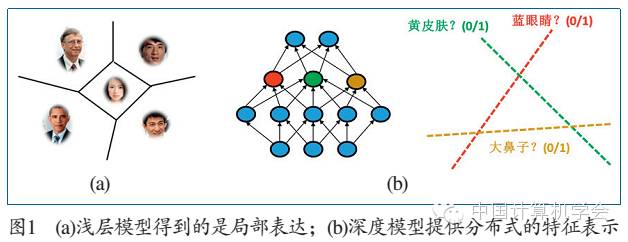
Research shows that for specific tasks, if the model depth is insufficient, the number of required computational units increases exponentially. This means that while shallow models can express the same classification function, they require significantly more parameters and training samples. Shallow models provide local representations. They partition the high-dimensional image space into several local regions, each storing at least one template obtained from the training data, as shown in Figure 1(a). Shallow models match a test sample with these templates one by one and predict its category based on the matching results. For example, in a support vector machine model, the template is the support vector; in a nearest neighbor classifier, the template is all training samples. As the complexity of classification problems increases, the image space must be divided into more and more local regions, requiring more parameters and training samples. Although many deep models currently have a significant number of parameters, if replaced with shallow neural networks, the required number of parameters would increase by several orders of magnitude to achieve the same data fitting effect, making it nearly impossible to realize.
The reason deep models can reduce parameters lies in their ability to reuse intermediate layer computational units. Taking face recognition as an example, deep learning can perform hierarchical feature representation for face images: the lowest layer learns filters from raw pixels to characterize local edges and texture features; the middle layer filters combine various edge filters to describe different types of facial organs; the highest layer describes the global features of the entire face.
Deep learning provides distributed feature representations. In the highest hidden layer, each neuron represents an attribute classifier (as shown in Figure 1(b)), such as gender, ethnicity, and hair color. Each neuron divides the image space in half, and the combination of N neurons can express 2N local regions, while using shallow models to express these region divisions would require at least 2N templates. This demonstrates that deep models have stronger expressive capabilities and higher efficiency.
Ability to Extract Global Features and Contextual Information
Deep models possess strong learning capabilities and efficient feature representation abilities. More importantly, they extract information from pixel-level raw data to abstract semantic concepts layer by layer, giving them outstanding advantages in extracting global features and contextual information from images, providing new ideas for solving traditional computer vision problems (such as image segmentation and keypoint detection).
Taking face image segmentation as an example (as shown in Figure 2), in order to predict which pixel belongs to which facial organ (eyes, nose, mouth), the usual approach is to take a small area around that pixel, extract texture features (such as local binary patterns), and then classify based on that feature using shallow models like support vector machines. Because the information contained in the local area is limited, it often leads to classification errors, thus requiring the introduction of constraints such as smoothing and shape priors for the segmented images.
The human eye can estimate the labels of occluded parts based on information from other regions of the face, even in the presence of local occlusions. This indicates that global and contextual information is crucial for local judgments, and this information is lost at the initial stages of methods based on local features. Ideally, the model should take the entire image as input and directly predict the entire segmentation map. Image segmentation can be viewed as a high-dimensional data transformation problem. This not only utilizes contextual information but also implicitly incorporates shape priors in the high-dimensional data transformation process. However, due to the complexity of the entire image content, shallow models struggle to effectively capture global features. The emergence of deep learning has made this approach possible, achieving success in face segmentation[11], human body segmentation[12], face image registration[13], and human pose estimation[14].
Joint Deep Learning
Some scholars studying computer vision view deep learning models as black boxes, which is an incomplete perspective. Traditional computer vision systems and deep learning models are closely related, and utilizing this relationship can lead to new deep models and training methods. Joint deep learning[15] for pedestrian detection is a successful example. A computer vision system consists of several key components. For instance, a pedestrian detector includes modules for feature extraction, part detection, part geometric deformation modeling, part occlusion reasoning, and classifiers. In joint deep learning[15], various layers of the deep model can establish correspondences with the modules of the vision system. If key modules in the vision system do not have corresponding layers in the existing deep learning model, they can inspire us to propose new deep models. For example, extensive research on object detection has shown that modeling the geometric deformation of object parts can effectively improve detection rates, but there are no corresponding layers in commonly used deep models. Therefore, joint deep learning[15] and its subsequent work[16] have proposed new deformation layers and deformation pooling layers to achieve this functionality.
From a training perspective, the various modules of a computer vision system are trained one by one or designed manually. In the pre-training phase of a deep model, each layer is also trained one by one. If we can establish correspondences between the computer vision system and the deep model, then the experience accumulated in visual research can guide the pre-training of the deep model. As a result, the pre-trained model can achieve results comparable to traditional computer vision systems. On this basis, deep learning will also use backpropagation to jointly optimize all layers, ensuring that their collaboration reaches an optimal state, significantly enhancing the performance of the entire network.
Applications of Deep Learning in Object Recognition
ImageNet Image Classification
The most important progress of deep learning in object recognition is reflected in the image classification task of the ImageNet ILSVRC challenge. The lowest error rate of traditional computer vision methods on this test set is 26.172%. In 2012, Hinton’s research group reduced the error rate to 15.315% using convolutional networks. This network structure is known as AlexNet[3], which differs from traditional convolutional networks in three key ways: first, AlexNet employs a dropout training strategy, randomly setting some neurons in the input and intermediate layers to zero during training. This simulates noise interference on the input data, causing some neurons to miss certain visual patterns. Dropout slows down the convergence of the training process but results in a more robust network model. Secondly, AlexNet uses Rectified Linear Units (ReLU) as the non-linear activation function. This not only significantly reduces computational complexity but also makes the output of neurons sparse, enhancing robustness against various interferences. Thirdly, AlexNet generates more training samples by mapping training samples through mirroring and adding random translation perturbations, reducing overfitting.
In the ImageNet ILSVRC 2013 competition, all top 20 teams used deep learning technology. The winner was Rob Fergus’s research group from New York University, which used a convolutional network and further optimized the network structure, achieving an error rate of 11.197%. Their model is called Clarifai[17].
In the ILSVRC 2014 competition, the winner GooLeNet[18] reduced the error rate to 6.656%. GooLeNet’s outstanding feature is its significantly increased depth, exceeding 20 layers, which was previously unimaginable. Very deep network structures pose challenges for backpropagating prediction errors, as the prediction errors are transmitted from the top layer to the bottom layer, and the errors reaching the bottom layer are minimal, making it difficult to drive updates of the bottom layer parameters. GooLeNet’s strategy was to add supervisory signals directly to multiple intermediate layers, meaning that the feature representations of the intermediate and bottom layers also needed to accurately classify the training data. Effectively training very deep network models remains an important research topic for the future.
Although deep learning has achieved great success on ImageNet, many applications have smaller training sets. In such cases, how can deep learning be applied? Three methods can be considered: (1) Use the model trained on ImageNet as a starting point, continue training it with the target training set and backpropagation to adapt the model to specific applications[10]. Here, ImageNet serves as pre-training. (2) If the target training set is not large enough, the parameters of the lower layers can be fixed, using the results from ImageNet, and only updating the upper layers. This is because the parameters of the lower layers are the hardest to update, and the filters learned from ImageNet often describe various local edges and texture information, which have good universality for general images. (3) Directly use the model trained on ImageNet, taking the output of the highest hidden layer as feature representations, replacing commonly used handcrafted features[19, 20].
Face Recognition
Another important breakthrough of deep learning in object recognition is face recognition. The biggest challenge in face recognition is distinguishing between intra-class variations caused by factors such as lighting, pose, and expression, and inter-class variations arising from different identities. The distributions of these two types of variations are non-linear and extremely complex, making it difficult for traditional linear models to effectively distinguish between them. The goal of deep learning is to obtain new feature representations through multi-layer non-linear transformations. These new features must remove as much intra-class variation as possible while retaining inter-class variation.
Face recognition includes two tasks: face verification and face identification. Face verification determines whether two face photos belong to the same person, which is a binary classification problem with a random guess accuracy of 50%. Face identification classifies a face image into one of N categories, defined by the identity of the face. This is a multi-class classification problem, more challenging, with the difficulty increasing as the number of categories increases, and random guess accuracy is 1/N. Both tasks can learn face feature representations through deep models.
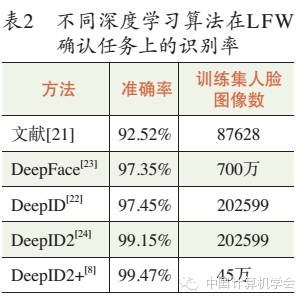
In 2013, literature[21] used the face verification task as a supervisory signal, employing convolutional networks to learn face features, achieving a recognition rate of 92.52% on LFW. Although this result is lower compared to subsequent deep learning methods, it surpasses most non-deep learning algorithms. Since face verification is a binary classification problem, using it to learn face features is less efficient and prone to overfitting on the training set. In contrast, face identification is a more challenging multi-class problem, less prone to overfitting, making it more suitable for learning face features through deep models. Additionally, in face verification, each pair of training samples is manually labeled as one of the two categories, containing less information. In face identification, each training sample is manually labeled as one of N categories, containing more information.
At the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) in 2014, DeepID[22] and DeepFace[23] both used face identification as a supervisory signal, achieving recognition rates of 97.45% and 97.35% on LFW, respectively (see Table 2). They utilized convolutional networks to predict N-dimensional label vectors, using the highest hidden layer as face features. This layer, during training, must distinguish between a large number of face categories (for instance, distinguishing faces from 1000 categories in DeepID), thus containing rich information on inter-class variations and strong generalization capabilities. Although the training used the face identification task, the obtained features can also be applied to face verification tasks and to identify whether there are new individuals in the training set. For example, the task tested on LFW is face verification, different from the face identification task in training; the identities of the individuals in the training sets of DeepID[21] and DeepFace[22] do not overlap with those in the LFW test set.
The face features learned through the face identification task contain significant intra-class variations. DeepID2[24] jointly used face verification and face identification as supervisory signals, achieving face features that minimize intra-class variations while retaining inter-class variations, thus raising the face recognition rate on LFW to 99.15%. DeepID2 utilizes Titan GPUs to extract features from a single face image in just 35 milliseconds and can be done offline. After principal component analysis (PCA) compression, an 80-dimensional feature vector is obtained for rapid online face comparison. In subsequent work, DeepID2[8] achieved a recognition rate of 99.47% on LFW by expanding the network structure, increasing the training data, and adding supervisory information at every layer.
Some believe that the success of deep learning lies in fitting datasets with complex models that have a large number of parameters; however, it is far from that simple. For instance, the success of DeepID2+ also relies on many important and interesting features[8]: the responses of its top-layer neurons are moderately sparse, exhibiting strong selectivity for facial identities and various facial attributes, and demonstrating robustness against local occlusions. In previous research, obtaining these attributes often required adding various explicit constraints to the model. However, DeepID2+ automatically possesses these attributes through large-scale learning, and the theoretical analysis behind this warrants further research in the future.
Applications of Deep Learning in Object Detection
Object detection is a more challenging task than object recognition. An image may contain multiple objects belonging to different categories, and object detection requires determining the location and category of each object. In 2013, the organizers of the ImageNet ILSVRC competition added the task of object detection, requiring the detection of 200 classes of objects in 40,000 internet images. The winner of the competition used manually designed features, achieving an average object detection rate (mean Average Precision, mAP) of only 22.581%. In ILSVRC 2014, deep learning improved the average object detection rate to 43.933%. Influential works include RCNN[10], Overfeat[25], GoogLeNet[18], DeepID-Net[16], network in network[26], VGG[27], and spatial pyramid pooling in deep CNN[28]. RCNN[10] first proposed a widely adopted object detection process based on deep learning, using non-deep learning methods (such as selective search[29]) to propose candidate regions, extracting features from candidate regions using deep convolutional networks, and then classifying the regions into objects and backgrounds using linear classifiers like support vector machines. DeepID-Net[16] further refined this process, significantly improving detection rates and providing detailed experimental analysis of contributions from each step. The design of the deep convolutional network structure is also crucial; if a network structure improves the accuracy of image classification tasks, it usually also significantly enhances the performance of object detectors.
The success of deep learning is also reflected in pedestrian detection. On the largest pedestrian detection test set (Caltech[30]), commonly used Histogram of Oriented Gradient (HOG) features and deformable parts models[31] have an average false detection rate of 68%. Currently, the best result based on deep learning is 20.86%[32]. In recent research advances, many effective object detection methods have utilized deep learning. For example, joint deep learning[15] proposed deformation layers to model geometric deformations between object parts; multi-stage deep learning[33] can simulate commonly used cascade classifiers in object detection; switchable deep networks[34] can express mixed models of various object parts; and literature[35] has adapted a deep learning pedestrian detector to a target scene through transfer learning.
Deep Learning for Video Analysis
The application of deep learning in video classification is still in its infancy, and much work remains to be done. Static image features describing videos can be obtained from deep models learned from ImageNet, but the challenge lies in how to describe dynamic features. Previous visual research methods often relied on optical flow estimation, tracking key points, and dynamic textures to describe dynamic features. How to incorporate this information into deep models is a challenge. The most direct approach is to treat video as a three-dimensional image, directly applying convolutional networks[36] to learn three-dimensional filters at each layer. However, this approach does not consider the differences between the temporal and spatial dimensions. Another simple yet more effective approach is to preprocess and compute the optical flow field or other dynamic feature spatial distributions as an input channel for the convolutional network[37~39]. Some research has also utilized deep autoencoders to non-linearly extract dynamic textures[38]. In recent studies[41], Long Short-Term Memory (LSTM) networks have gained widespread attention for their ability to capture long-term dependencies and model complex dynamics in videos.
Future Development Prospects
The application of deep learning in image recognition is burgeoning, with vast development potential ahead.
In the research of object recognition and detection, a trend is to use larger and deeper network structures. In ILSVRC 2012, AlexNet only contained 5 convolutional layers and two fully connected layers. In ILSVRC 2014, both GooLeNet and VGG used network structures exceeding 20 layers. Deeper network structures make backpropagation more challenging. At the same time, the scale of training data is rapidly increasing. This urgently requires the research of new algorithms and the development of new parallel computing systems to more effectively utilize big data to train larger and deeper models.
Compared to image recognition, the application of deep learning in video classification is still far from mature. Features learned from ImageNet can be directly and effectively applied to various image-related recognition tasks (such as image classification, image retrieval, object detection, and image segmentation) and other different image test sets, exhibiting good generalization performance. However, deep learning has yet to yield similar features applicable to video analysis. Achieving this goal requires not only the establishment of large-scale training datasets (recent literature[42] established a database containing one million YouTube videos) but also the research of new deep models suitable for video analysis. The computational load of training deep models for video analysis will also increase significantly.
In applications related to images and videos, the output predictions of deep models (such as segmentation maps or object detection boxes) often exhibit spatial and temporal correlations. Therefore, researching deep models with structured outputs is also a key focus.
Although the purpose of neural networks is to solve general machine learning problems, domain knowledge plays an important role in the design of deep models. Among image and video-related applications, the most successful are deep convolutional networks, whose design leverages the special structure of images. The two most important operations—convolution and pooling—derive from domain knowledge related to images. How to introduce new effective operations and layers into deep models through research in domain knowledge is crucial for enhancing the performance of image and video recognition. For instance, pooling layers provide local translational invariance, and the deformation pooling layer proposed in literature[16] better describes the geometric deformations of various object parts. In future research, this can be further expanded to achieve rotational invariance, scale invariance, and robustness against occlusion.
By researching the relationship between deep models and traditional computer vision systems, we can not only help understand the reasons for the success of deep learning but also inspire new models and training methods. Joint deep learning[15] and multi-stage deep learning[33] still have much work ahead.
Although deep learning has achieved great success in practice, and the characteristics exhibited by deep models trained on big data (such as sparsity, selectivity, and robustness against occlusion[8]) are remarkable, much work remains to be done in theoretical analysis behind them. For instance, when do they converge? How can we achieve better local minima? What invariances beneficial for recognition are obtained through each layer’s transformations, and what information is lost? Recently, Mallat utilized wavelets for quantitative analysis of deep network structures[43], marking an important exploration in this direction.
Conclusion
Deep models are not black boxes; they are closely related to traditional computer vision systems, with the various layers of neural networks jointly learning and optimizing to significantly enhance performance. Various applications related to image recognition are also driving rapid development in the network structure, layer design, and training methods of deep learning. It is foreseeable that in the coming years, deep learning will enter a period of rapid development in theory, algorithms, and applications.
Images:

Tables:
Author:
 Wang Xiaogang
Wang Xiaogang
Assistant Professor at The Chinese University of Hong Kong. His main research interests include computer vision, deep learning, crowd video surveillance, object detection, and face recognition.