
This summer, Lei Feng Network will host the “Global Artificial Intelligence and Robotics Innovation Conference” (GAIR) in Shenzhen. At this conference, we will release the “Top 25 Innovative Companies in Artificial Intelligence and Robotics” list, and Huiyan Technology is one of the companies we are focusing on. Today, we have invited Li Hanxi, the R&D director of Huiyan Technology, to share insights on deep learning and computer vision.

Guest Introduction: Li Hanxi, R&D Director of Huiyan Technology, PhD from the Australian National University; formerly a senior researcher at the National ICT Australia (NICTA); an expert in face recognition, object detection, object tracking, and deep learning, having published influential papers in authoritative journals such as TPAMI, TIP, TNNLS, and Pattern Recognition, as well as significant conferences like CVPR, ECCV, BMVC, and ACCV; currently a visiting researcher at Griffith University in Australia and a distinguished professor at Jiangxi Normal University.
Artificial intelligence is a beautiful dream for humanity, akin to interstellar travel and immortality. We aim to create a machine that can perceive the external world like humans do, for instance, seeing the world.
In the 1950s, mathematician Alan Turing proposed a standard for judging whether a machine possesses artificial intelligence: the Turing Test. This involves placing a machine in one room and a human tester in another room, where they chat without the tester knowing whether they are communicating with a human or a machine. If the tester cannot determine whether they are chatting with a human or a machine, the Turing Test is passed, meaning the machine has a perception ability comparable to that of humans.
However, from the time the Turing Test was proposed until the early 21st century, countless scientists presented many machine learning algorithms attempting to enable computers to achieve human-like intelligence. It wasn’t until the success of deep learning algorithms in 2006 that a glimmer of hope emerged.
▌The Rise of Deep Learning
In many academic fields, deep learning often achieves a 20-30% improvement over non-deep learning algorithms. Many large companies have gradually begun investing in these algorithms and establishing their own deep learning teams, with Google being the largest investor, revealing the Google Brain project in June 2008. In January 2014, Google acquired DeepMind, and in March 2016, its developed AlphaGo algorithm defeated South Korean nine-dan player Lee Sedol in a Go challenge, proving that algorithms designed using deep learning can beat the strongest players in the world.
In terms of hardware, Nvidia initially focused on display chips but began promoting the use of GPU chips for general computing starting in 2006 and 2007, which are particularly suitable for the large volume of simple repetitive calculations involved in deep learning. Currently, many people choose Nvidia’s CUDA toolkit for developing deep learning software.
Since 2012, Microsoft has utilized deep learning for machine translation and Chinese speech synthesis, with its AI assistant Cortana backed by a set of natural language processing and speech recognition algorithms.
In 2013, Baidu announced the establishment of Baidu Research Institute, with the most important being the Baidu Deep Learning Research Institute, which recruited renowned scientist Dr. Yu Kai. However, later on, Yu Kai left Baidu to establish another company focused on developing deep learning algorithms called Horizon Robotics.
Facebook and Twitter have also conducted deep learning research, with the former collaborating with NYU professor Yann LeCun to establish its own deep learning algorithm laboratory; in October 2015, Facebook announced the open-source release of its deep learning algorithm framework, the Torch framework. Twitter acquired Madbits in July 2014 to provide users with high-precision image retrieval services.
▌Computer Vision Before Deep Learning
Internet giants value deep learning not for academic reasons, but mainly for the enormous market potential it brings. So why did traditional algorithms fail to achieve the accuracy of deep learning before its emergence?
Before the advent of deep learning algorithms, visual algorithms could generally be divided into the following five steps: feature perception, image preprocessing, feature extraction, feature selection, and inference prediction and recognition. In early machine learning, the dominant statistical machine learning community paid little attention to features.
I believe that computer vision can be seen as the application of machine learning in the visual domain, so when adopting these machine learning methods, computer vision had to design the first four parts itself.
However, this is a relatively difficult task for anyone. Traditional computer recognition methods separate feature extraction from classifier design, and then combine them during application. For example, if the input is an image of a motorcycle, there needs to be a feature expression or feature extraction process first, and then the expressed features are input into the learning algorithm for classification learning.
Over the past 20 years, many excellent feature operators have emerged, such as the well-known SIFT operator, which is invariant to scale and rotation. It has been widely used in image matching, especially in applications such as structure from motion, with several successful application examples. Another is the HoG operator, which can extract objects and plays a crucial role in object detection.
These operators include Textons, Spin image, RIFT, and GLOH, which dominated visual algorithms before the birth of deep learning or before deep learning became truly popular.
▌Several (Semi) Successful Examples
These features, combined with specific classifiers, achieved some successful or semi-successful examples, basically meeting commercial requirements but not fully commercialized.
First, there are fingerprint recognition algorithms from the 1980s and 1990s, which are already very mature. They generally look for key points on the fingerprint pattern, searching for points with special geometric features, and then comparing the key points of two fingerprints to determine whether they match.
Next is the Haar-based face detection algorithm from 2001, which was able to achieve real-time face detection under the hardware conditions of the time. All face detection in our mobile phone cameras is based on this or its variants.
The third is object detection based on HoG features, which combined with the corresponding SVM classifier forms the famous DPM algorithm. The DPM algorithm outperformed all other algorithms in object detection, achieving quite good results.
However, there are too few successful examples because manually designed features require a lot of experience and a deep understanding of the domain and data, and the designed features also require extensive debugging work. Simply put, it requires a bit of luck.
Another difficulty is that not only do you need to manually design features, but you also need to have a suitable classifier algorithm based on that. Simultaneously designing features and selecting a classifier to achieve optimal results is nearly impossible.
▌Biomimetic Perspective on Deep Learning
If we don’t manually design features or select classifiers, is there another solution? Can we learn features and classifiers simultaneously? That is, when inputting a certain model, the input is just an image, and the output is its label. For example, inputting a celebrity’s portrait would yield a 50-dimensional vector (if identifying among 50 individuals), where the corresponding celebrity’s vector is 1, and the others are 0.
This setup aligns with findings in human brain science.
In 1981, the Nobel Prize in Physiology or Medicine was awarded to David Hubel, a neurobiologist. His main research achievement was discovering the information processing mechanism of the visual system, demonstrating that the brain’s visual cortex is hierarchical. His contributions mainly include two points: he believed that human visual functions are both abstract and iterative. Abstraction involves extracting very concrete, image-based elements, such as raw light pixel information, to form meaningful concepts. These meaningful concepts then iterate upwards, becoming more abstract concepts that humans can perceive.
Pixels have no abstract meaning, but the human brain can connect these pixels into edges. Edges, relative to pixels, become a more abstract concept; edges then form spheres, and spheres further become balloons, illustrating an abstract process where the brain ultimately recognizes that it sees a balloon.
Simulating how the human brain recognizes faces is also an abstract iterative process, from the initial pixel to the second layer of edges, then to parts of the face, and finally to the entire face, representing an abstract iterative process.
For instance, when we see a motorcycle in an image, we may only take a few microseconds in our minds, but it involves a lot of neurons abstracting iteratively. For computers, the initial input is not a motorcycle, but rather different numbers on the three channels of an RGB image.
The so-called features or visual features are the statistical or non-statistical representations that combine these values, showcasing the components of a motorcycle or the entire motorcycle. Before the rise of deep learning, most designed image features were based on this, i.e., aggregating pixel-level information within a region to facilitate subsequent classification learning.
To fully simulate the human brain, we also need to mimic the processes of abstraction and recursive iteration, abstracting information from the finest pixel level to the concept of “type” that humans can accept.
▌Concept of Convolution
In computer vision, convolutional neural networks, or CNNs, are often used, which are a precise simulation of the human brain.
What is convolution? Convolution is the relationship between two functions that yields a new value, involving integral calculations in continuous space and summation in discrete space. In fact, in computer vision, convolution can be seen as an abstract process, statistically abstracting information from a small region.
For example, with a photo of Einstein, I can learn n different convolutions and functions to statistically analyze this region. Various methods can be used for statistics, such as focusing on the center or the surrounding area, leading to a variety of statistical and functional types to achieve simultaneous learning of multiple statistical accumulations.
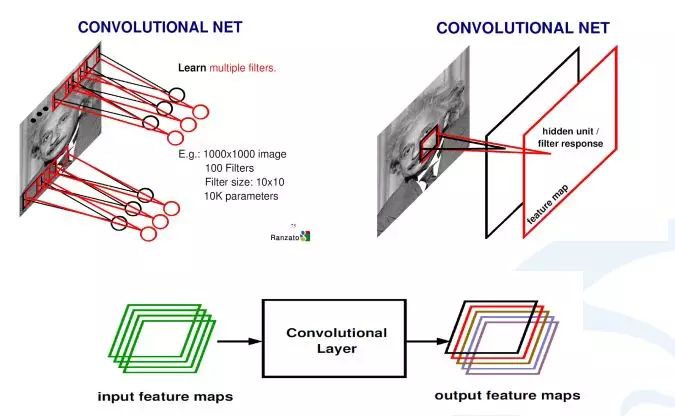
The above image illustrates how to derive the final convolution from the input image to generate the response map. First, the learned convolutions scan the image, and each convolution generates a scanned response map, referred to as a response map or feature map. If there are multiple convolutions, multiple feature maps will be generated. This means that from an initial input image (RGB three channels), one can obtain 256 channels of feature maps, as there are 256 convolutions, each representing a different statistical abstraction method.
In convolutional neural networks, in addition to convolutional layers, there is also an operation called pooling.Pooling is more clearly defined statistically, as a statistical operation that calculates the average or maximum value within a small region.
The result is that if I previously input two channels or 256 channels of convolutional response feature maps, each feature map undergoing a max pooling layer will yield a smaller set of 256 feature maps compared to the original.
In this example, the pooling layer finds the maximum value for each 2X2 region and assigns it to the corresponding position in the generated feature map. If the input image is 100×100, the output image will become 50×50, effectively halving the feature map size while retaining the maximum information from the original 2X2 region.
▌Example Operation: LeNet Network
LeNet, as the name suggests, refers to the renowned figure in artificial intelligence, LeCun. This network is the original prototype of deep learning networks. Previous networks were relatively shallow, while this one is deeper. LeNet was invented in 1998 when LeCun was at AT&T’s laboratory, achieving excellent results in character recognition.
How is it structured? The input image is a 32×32 grayscale image, which first goes through a set of convolutions, generating six 28X28 feature maps, followed by a pooling layer, resulting in six 14X14 feature maps. Then it passes through another convolutional layer, generating 16 tenX10 convolutional layers, followed by a pooling layer resulting in 16 fiveX5 feature maps.
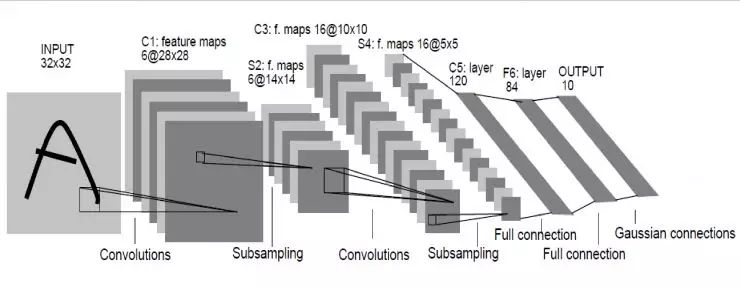
Starting from the last 16 fiveX5 feature maps, it passes through three fully connected layers to reach the final output, which corresponds to the label space output. Since the design only requires recognition of digits from 0 to 9, the output space is 10. If it were to recognize 10 digits plus 26 uppercase and lowercase letters, the output space would be 62. In a 62-dimensional vector, if the value of a certain dimension is the highest, the corresponding letter and digit is the predicted result.
▌The Last Straw on the Camel’s Back
From 1998 until the early 21st century, deep learning flourished over 15 years, but the results were mediocre and it was once marginalized. By 2012, deep learning algorithms achieved good results in some fields, with the last straw on the camel’s back being AlexNet.
AlexNet was developed by several scientists from the University of Toronto, achieving remarkable results in the ImageNet competition. At that time, AlexNet’s recognition performance surpassed all shallow methods. Subsequently, everyone recognized that the era of deep learning had finally arrived, and some began to apply it to other applications, while others started developing new network structures.
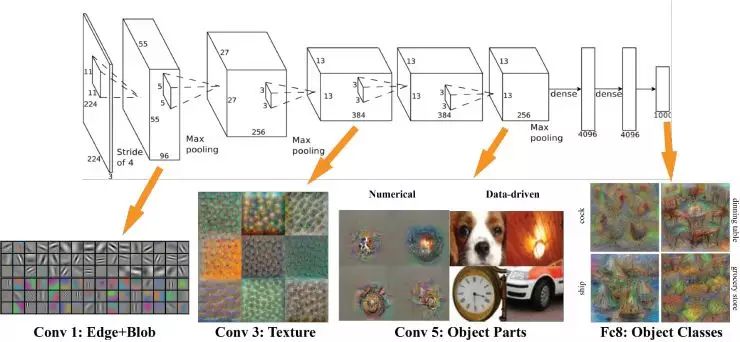
In fact, AlexNet’s structure is simple, just an enlarged version of LeNet. The input is a 224X224 image, which undergoes several convolutional layers, several pooling layers, and finally connects to two fully connected layers, reaching the final label space.
Last year, some researchers discovered how to visualize the features learned by deep learning. So, what do the features learned by AlexNet look like? In the first layer, they are mostly filled blocks and edges; in the middle layers, they begin to learn texture features; in the higher layers closer to the classifier, the features of object shapes become apparent.
In the final layer, the classification layer, the features represent different poses of objects, showcasing different poses based on different objects.
It can be said that whether recognizing faces, vehicles, elephants, or chairs, the initial learned elements are edges, followed by parts of the object, and then at higher levels, the abstraction to the whole object. The entire convolutional neural network simulates the human process of abstraction and iteration.
▌Why Did It Come Back After 20 Years?
We can’t help but ask: The design of convolutional neural networks doesn’t seem very complex, having had a decent prototype since 1998. There hasn’t been much progress in freely exchanging algorithms and theoretical proofs. So why, after 20 years, could convolutional neural networks make a comeback and dominate?
This question is not so much related to the technology of convolutional neural networks; I personally believe it has to do with other objective factors.
First, if the depth of convolutional neural networks is too shallow, their recognition ability often does not surpass that of general shallow models, such as SVM or boosting. However, if made very deep, it requires a large amount of data for training; otherwise, overfitting in machine learning becomes inevitable. Starting in 2006 and 2007, the internet began to generate a vast amount of various image data.
Another condition is computational power. Convolutional neural networks have high computational requirements, needing a large amount of parallelizable calculations. In the past, when CPUs were single-core and had low computational power, it was impossible to train very deep convolutional neural networks. With the growth of GPU computing capabilities, training convolutional neural networks combined with big data became possible.
Lastly, there are the people involved. A group of scientists (like LeCun) persisted in their research, preventing convolutional neural networks from being silenced or drowned out by a flood of shallow methods, ultimately witnessing the dawn of convolutional neural networks dominating the mainstream.
▌Applications of Deep Learning in Vision
Successful applications of deep learning in computer vision include face recognition, image question answering, object detection, and object tracking.
▌Face Recognition
Here, face recognition refers to face matching, i.e., obtaining a face and comparing it with faces in the database; or simultaneously providing two faces to determine if they are of the same person.
This area has been advanced by Professor Tang Xiaowu, whose DeepID algorithm performed well in LFW. They also used convolutional neural networks but extracted different position features from the two faces during comparison, yielding the final comparison result. The latest DeepID-3 algorithm achieved 99.53% accuracy on LFW, nearly matching human recognition results.
▌Image Question Answering
This topic emerged around 2014, where an image is provided along with a question, and the computer must respond. For example, showing an image of an office by the sea and asking, “What is behind the desk?” The neural network should output, “A chair and a window.”
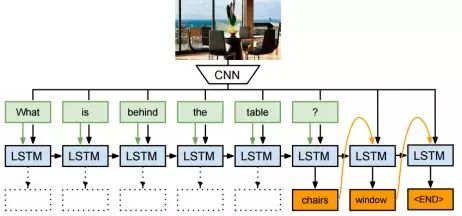
This application introduced LSTM networks, which are specially designed neural units with a certain memory capability. The feature is that the output at a certain moment is treated as the input for the next moment. It can be considered suitable for language and other scenarios with time series relationships, as our understanding of a sentence is based on the memory of the preceding words.
Image question answering is achieved through the combination of convolutional neural networks and LSTM units, where the LSTM output should be the desired answer, and the input includes the previous input, image features, and each word of the question.
Object Detection
▌Region CNN
Deep learning has also achieved excellent results in object detection. The Region CNN algorithm from 2014 is based on the idea of first using a non-deep method to extract potential object image blocks, and then deep learning algorithms determine the properties and specific locations of those objects based on these image blocks.
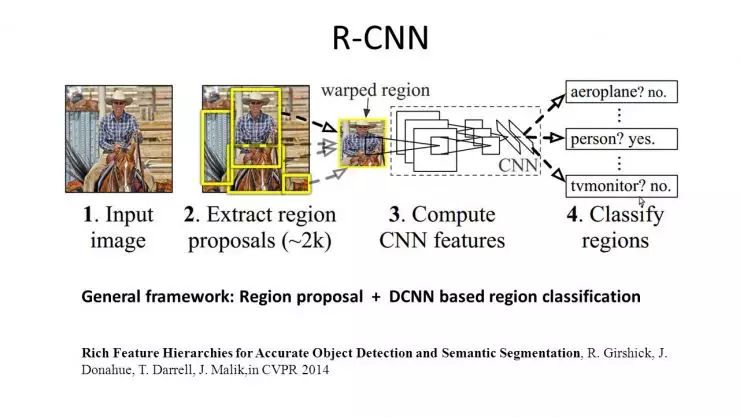
Why use a non-deep method to first extract potential image blocks? Because when monitoring objects using a sliding window method, one must consider the varying sizes, aspect ratios, and positions of the sliding windows. If each image block requires passing through a deep network, the time taken would be unacceptable.
Thus, a compromise method called Selective Search was used, eliminating image blocks that are unlikely to contain objects, leaving around 2000 image blocks for the deep network to assess. The resulting AP score was 58.5, nearly doubling previous achievements. However, one downside is that the speed of region CNN is very slow, requiring 10 to 45 seconds to process a single image.
▌Faster R-CNN Method
At last year’s NIPS, we saw the Faster R-CNN method, a super-speed version of the R-CNN method. Its speed reached seven frames per second, meaning it can process seven images in one second. The trick is that instead of using image blocks to determine whether an object is present, the entire image is fed into the deep network, allowing the deep network to autonomously determine where the objects are, their bounding boxes, and their types.
The number of deep network calculations was reduced from 2000 to just one, greatly enhancing speed.
Faster R-CNN proposed a method where deep learning autonomously generates possible object blocks, then uses the same deep network to determine whether these blocks are backgrounds, while simultaneously classifying and estimating their boundaries.
Faster R-CNN achieves both speed and accuracy, with an AP of 73.2 on VOC2007, improving speed by two to three hundred times.
▌YOLO
The YOLO network proposed by Facebook last year also performs object detection, achieving a speed of 155 frames per second, making it fully real-time. It allows an entire image to enter the neural network, enabling the network to determine where an object might be and what it might be. However, it reduces the number of potential image blocks from over 2000 in Faster R-CNN to just 98.
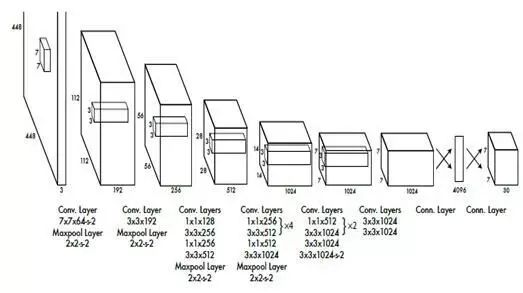
Additionally, it eliminates the RPN structure found in Faster R-CNN, replacing it with a Selective Search structure. YOLO does not include the RPN step, instead directly predicting the type and position of the object.
YOLO’s trade-off is a decrease in accuracy; at 155 frames per second, the accuracy is only 52.7, while at 45 frames per second, the accuracy is 63.4.
▌SSD
The latest algorithm appearing on arXiv is called Single Shot MultiBox Detector (SSD).
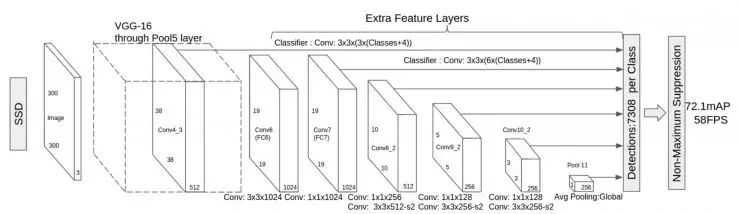
It is a super improved version of YOLO, taking lessons from YOLO’s accuracy decline while retaining its speed advantage. It can achieve 58 frames per second with an accuracy of 72.1. Its speed exceeds that of Faster R-CNN by eight times, while achieving similar accuracy.
▌Object Tracking
Object tracking refers to locking onto an object of interest in the first frame of a video and allowing the computer to follow it, regardless of how it rotates or shakes, even if it hides behind bushes.
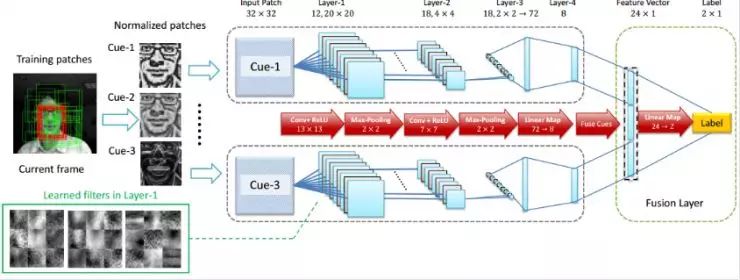
Deep learning has a significant impact on tracking problems. The DeepTrack algorithm was proposed by my colleagues and me during my time at the Australian Institute for Information Technology, being the first online use of deep learning for tracking, surpassing all other shallow algorithms at the time.
This year, more deep learning tracking algorithms have been proposed. In December last year at ICCV 2015, Ma Chao proposed the Hierarchical Convolutional Feature algorithm, achieving the latest record on data. It does not update a deep learning network online but uses a large pre-trained network to recognize what constitutes an object and what does not.
The large network is placed over the tracking video, analyzing the different features generated by the network in the video, using a more mature shallow tracking algorithm for tracking. This approach leverages the advantages of deep learning feature learning while utilizing the speed benefits of shallow methods, achieving 10 frames per second while breaking previous accuracy records.
The latest tracking achievement is based on Hierarchical Convolutional Feature, proposed by a research group from Korea called MDnet. It combines the strengths of the previous two deep learning algorithms, first learning offline, focusing not on general object detection or ImageNet, but on tracking videos. After completing the learning phase, it updates part of the network during real-time usage. This way, it gains extensive training offline while being flexible to adapt its network online.
▌Deep Learning Based on Embedded Systems
Returning to the ADAS issue (the main business of Huiyan Technology), deep learning algorithms can be applied, but they have high hardware platform requirements. It is impractical to place a computer in a car due to power issues, making it hard to be accepted by the market.
Currently, deep learning computations mainly occur in the cloud, where front-end images are transmitted to the back-end cloud platform for processing. However, for ADAS, long data transmission times are unacceptable; for instance, in the event of an accident, the cloud data might not return in time.
Could we consider NVIDIA’s embedded platform? NVIDIA’s embedded platform boasts computational power far exceeding that of all mainstream embedded platforms, nearing that of top-tier CPUs like the i7 desktop model. Therefore, Huiyan Technology’s task is to ensure that deep learning algorithms can achieve real-time effects within the limited resources of an embedded platform while maintaining minimal accuracy reduction.
Specifically, the approach is to first reduce the network, possibly by simplifying its structure; due to different recognition scenarios, functional reductions must also be made. Additionally, the fastest deep detection algorithms must be used, combined with the fastest deep tracking algorithms, while also developing some scene analysis algorithms. The goal is to reduce computational load and the size of the detection space. In this context, deep learning algorithms have been successfully implemented with minimal accuracy loss.
This July, Lei Feng Network will host the “Global Artificial Intelligence and Robotics Innovation Conference” (GAIR) in Shenzhen. We would like to know your views on the future trends of artificial intelligence.
Hanxi: I believe that the future direction of artificial intelligence should be machines serving humans, with machines assisting people. Humans should always be the final decision-makers. This is more reasonable both technically and ethically.
