
AI World 2017 Opening Video
The AI WORLD 2017 World Artificial Intelligence Conference, hosted by the new intelligence source AI news think tank, was held on November 8 at the National Convention Center in Beijing. The conference, themed ‘AI New Dimensions, China Intelligent+’, featured reports and discussions from over a hundred AI leaders covering the cutting edge of technology, academia, and industry, with more than 2,000 industry professionals in attendance. Yang Jing, founder and CEO of the new intelligence source, announced the launch of the world’s first interactive information platform for AI experts, ‘New Intelligence Enjoy Circle’.
Full review of the AI World 2017 World Artificial Intelligence Conference:
Xinhua News Photo Reviewhttp://www.xinhuanet.com/money/jrzb20171108/index.htm
iQIYI Morning: http://www.iqiyi.com/v_19rrdp002w.html
Afternoon: http://www.iqiyi.com/v_19rrdozo4c.html
Aliyun Yunqi Communityhttps://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
New Intelligence Source Compilation
Source: towardsdatascience.com
Compiled by: Ma Wen
[New Intelligence Source Guide]The author of this article recently completed the fourth course of Andrew Ng’s Deep Learning series on Coursera, ‘Convolutional Neural Networks’, which explains many complex methods needed to optimize computer vision tasks in detail. This article introduces the main content of this course.


The image above was created in week 4 of the course, combining Andrew Ng’s face with Leonid Afremov’s Rain Princess style.
I recently completed Andrew Ng’s computer vision course on Coursera. Andrew does an excellent job explaining many complex methods needed to optimize computer vision tasks. My favorite part of this course is Neural Style Transfer (Lesson 11), which allows you to combine the style of Claude Monet with the content of any image. Below is an example:

In this article, I will discuss the 11 main lessons from this course. It is worth noting that this is the fourth course in the Deep Learning series produced by deeplearning.ai, and you can visit the official website to learn about the first three courses.
The development of big data and algorithms will lead to the convergence of intelligent systems’ test errors to the Bayesian optimal error. This will enable AI to surpass human levels in all fields, including natural perception tasks. The open-source software TensorFlow allows you to use transfer learning to implement target detection systems that can quickly detect any target. With transfer learning, you only need about 100-500 samples to make the system work well. The workload of manually labeling 100 examples is not very large, so you can quickly achieve feasible small results.
Andrew explained how to implement the convolution operator and demonstrated how it detects edges in images. He also introduced other filters, such as the Sobel filter, which gives greater weight to the center pixel of edges. According to Andrew’s explanation, the weights of filters should not be manually designed but should be learned using hill climbing algorithms, such as gradient descent.
Andrew presented several philosophical reasons explaining why convolution is so effective in image recognition tasks. He provided two specific reasons. The first is parameter sharing. The idea of parameter sharing is that if a feature detector is effective for a certain part of the image, it may also be effective for another part of the image. For example, an edge detector may be useful for many parts of the image. Sharing parameters allows for a reduced number of parameters and enables strong translational invariance.
The second reason is ‘sparsity of connections’. This means that each output layer is just a function of a small amount of input (especially the size of the filter), which significantly reduces the number of parameters in the network and speeds up training.
Padding is commonly used to preserve the input size (i.e., the dimensions of input and output are the same). Padding is also used to ensure that frames near the edges of the image contribute equally to the output as frames relatively close to the center of the image.
Empirical studies have shown that max pooling is very effective in CNNs. By downsampling the image, you can reduce the number of parameters that keep features invariant to scaling or directional changes.
Andrew explained three classic network architectures, including LeNet-5, AlexNet, and VGG-16. His main idea is that in efficient networks, the channel size of the layers increases while the height and width decrease.
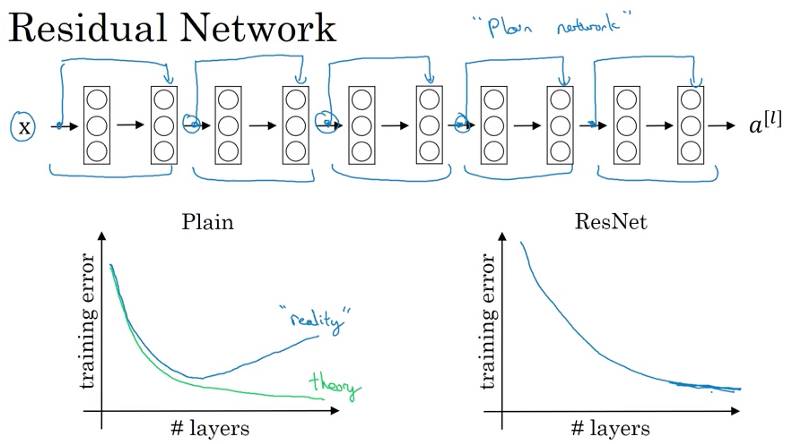
For ordinary networks, due to vanishing and exploding gradients, the training error does not monotonically decrease as the number of layers increases. ResNets have feedforward skip connections, allowing for the training of very large networks without degrading performance.
Training a large network (e.g., inception) from scratch with a GPU may take several weeks. You should download the weights from a pretrained network and only retrain the last softmax layer (or the last few layers). This can significantly shorten training time. The reason this method is effective is that the earlier layers tend to relate to some concepts common to all images, such as edges and curves.
According to Andrew, you should independently train several networks and average their outputs to achieve better performance. Data augmentation techniques, such as randomly cropping images and flipping images along the horizontal and vertical axes, may also help improve performance. Finally, you should start from open-source implementations and pretrained models, then fine-tune parameters for the target application.
Andrew first explained the concept of landmark detection in images. Essentially, these landmarks are part of the examples you train on. Through some clever convolution operations, you can obtain an output that tells you the probability of a target in a certain area and the location of the target. Andrew also explained how to use the intersection over union (IOU) formula to evaluate the effectiveness of object detection algorithms. Finally, Andrew integrated all of this, explaining the famous YOLO algorithm.
Face recognition is a one-shot learning problem because there may only be one sample available to recognize a person. The solution is to learn a similarity function that indicates the degree of difference between two images. Therefore, if the images are of the same person, you want this function to output a small value, and vice versa.
The first solution introduced by Andrew is the Siamese network. The idea is to input images of two people into the same network separately and then compare their outputs. If the outputs are similar, they are likely the same person. The training objective of the network is that if the two input images are of the same person, their encoding distance should be relatively small.
The second solution is to use the triplet loss method. The idea is that the three dimensions of the image (Anchor (A), Positive (P), and Negative (N)) should have the output distance of A and P be much smaller than the output distance of A and N after training.

Andrew explained how to combine content and style to create a painting, as seen in the example below:

The key to neural style transfer is understanding the visual representations learned at each layer of the convolutional network. It turns out that the earlier layers learn simple features like edges, while later layers learn complex objects such as faces, feet, and cars.
To construct a neural style transfer image, you just need to define a cost function, which is a convex combination of content and style similarity. Specifically, the cost function could be:
J(G) = alpha * J_content(C,G) + beta * J_style(S,G)
G is the generated image, C is the content image, and S is the style image. The learning algorithm simply uses gradient descent to minimize the cost function based on the generated image G.
The steps break down as follows:
1. Randomly generate G
2. Use gradient descent to minimize J(G), for example, write G := G – dG(J(G))
3. Repeat step two
By completing this course, you will gain an intuitive understanding of a large amount of computer vision literature. The assigned homework also allows you to practice these ideas yourself. After completing this course, you may not become an expert in computer vision, but this course may inspire your potential ideas/careers in computer vision.
Original article: https://towardsdatascience.com/computer-vision-by-andrew-ng-11-lessons-learned-7d05c18a6999
Readers are welcome to join the New Intelligence Source reader group for discussions. Please add WeChat: aiera2015