Click the “blue words” to follow for more exciting content!


Background: In neurosurgical practice, pain assessment is largely subjective, but the emergence of machine learning offers the possibility of objective pain assessment.
Objective: To predict daily pain levels using smartphone voice recordings from a group of patients diagnosed with neuropathic spine diseases.
Methods: With the approval of the institutional ethics committee, spine disease patients were recruited through a general neurosurgery outpatient clinic. Regular home pain surveys and voice recordings were conducted using the Beiwe smartphone application. Praat audio features were extracted from the voice recordings to serve as input for the KNN machine learning model. Pain was assessed using a score from 0 to 10 to achieve better pain resolution.
Results: A total of 60 patients were included, and 384 observations were used to train and test the predictive model. The KNN predictive model achieved an accuracy of 71% when classifying pain intensity as severe and mild, with a positive predictive value of 0.71. The model predicted severe pain with an accuracy of 0.71, and mild pain with an accuracy of 0.70. The recall for severe pain was 0.74, and for mild pain was 0.67. The overall F1 score was 0.73.
Conclusion: Our study used the KNN model to simulate the relationship between voice features collected from spine disease patients’ smartphones and pain levels. The proposed model serves as a stepping stone for the development of objective pain assessment in neurosurgical clinical practice.
Keywords: Digital phenotyping, voice analysis, patient-reported outcome measures, spinal surgery, machine learning, smartphone
Pain caused by spinal diseases can reduce patients’ mobility and is a major driver for spinal surgery. However, the subjective nature of pain makes its assessment and treatment challenging. Currently, the gold standard for pain assessment in neurosurgical clinical practice includes methods such as numerical rating scales (NRS) and visual analog scales; the NRS is a numerical rating from 0 to 10 that patients use to self-assess their pain level. Although these methods have proven to be simple pain assessment methods, they often require patients to visit the clinic in person and rely on patients’ recollections.
As a complement to clinic visits and patient recollections, recent advancements in remote health monitoring through modern digital devices such as smartphones and tablets provide information for preventive and care management. Smartphone-based patient monitoring allows clinicians to monitor the health of patients at home. The term “digital phenotyping” was coined by Onnela and reported in Onnela et al., referring to a technique that quantifies a patient’s phenotype at every moment by continuously collecting data from mobile devices like smartphones. Recent studies have found a correlation between the activity levels of patients with spinal diseases measured through smartphone GPS data and pain. Therefore, digital phenotyping data seems to have great potential for tracking and evaluating pain, potentially reducing the need for patients to visit the clinic in person. Although pain is a sensation that includes subjective factors, digital phenotyping analysis methods can better control the fluctuations in patients’ perceptions.
Previous studies have shown that pain can alter the language of certain patients. Furthermore, language has been shown to provide evidence of abnormal brain activity for diagnosing depression, schizophrenia, and Alzheimer’s disease. Therefore, voice data may serve as a digital biological marker representing pain, complementing current pain assessment methods.
In neurosurgical research, the applicability of machine learning methods has significantly increased in recent years. Machine learning techniques can create models for various applications based on large datasets, making them particularly suitable for digital phenotyping data analysis. However, implementing applications such as pain prediction in clinical settings still poses significant challenges. The aim of this study is to create a machine learning model that uses digital phenotyping voice data collected through a smartphone application to predict the pain level of patients with spinal diseases on a given day.
Methods
Patient Registration
This study was approved by our hospital’s ethics committee (protocol number 2016P000095), and patients provided consent to participate in this study. Patients were enrolled in our neurosurgery department from June 2017 to July 2019. The inclusion criteria for this study were patients with spinal diseases who visited the neurosurgery department. Patients with a history of opioid abuse or those who had undergone multiple spinal surgeries were excluded from the cohort. Not all patients underwent surgery before or during the study; included patients participated either pre-operatively, post-operatively, or both. Since each data point was processed independently, no inclusion criteria were defined based on the length of follow-up time. Participating patients were asked to download and install the Beiwe smartphone application. Patients who downloaded the Beiwe application but did not record voice samples were excluded from the study.
The two data sources for this study were pain surveys and voice recordings. The timing of voice and pain data collection was predetermined by the smartphone application, requiring no input from the authors. Pain surveys were conducted via smartphone notifications at 5 PM local time each day. The pain survey used the NRS pain scale. The survey text stated: “Please rate your pain over the past 24 hours on a scale from 0 to 10, where 0 means no pain at all and 10 means the worst pain imaginable.” Voice recordings were prompted each Monday at 5 PM local time through the Beiwe application. Patients were asked to read aloud the first paragraph of Charles Dickens’s “A Tale of Two Cities.” This passage was standardized across all patients and each time point of voice recording. This study did not analyze free responses, such as verbal expressions of patients’ feelings. Data collection continued until the application was deleted, and all data were stored in a secure database. The data used in this study are not publicly available.
Data Preprocessing
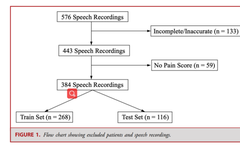
As patients did not always complete the pain surveys and were prompted for voice recordings only once a week, the voice recordings and pain surveys were matched based on completion time. Only voice recordings made within 24 hours before the pain survey was completed were included in the analysis. If multiple pain surveys met the criteria, the one closest to the voice recording time was chosen. Voice recordings were manually screened to exclude all incomplete and accidental recordings. All unmatched pain surveys and voice recordings were excluded.
Feature Extraction
Voice recordings from the Beiwe application were provided in various formats. To ensure compatibility with the software package, voice recordings initially recorded in MP3 format were converted to waveform audio file format. Voice features were extracted using the Parselmouth Python library, which is a software for performing Praat audio analysis. The extracted voice features included meanF0Hz, stdevF0Hz, harmonic to-noise ratio, localJitter, localabsoluteJitter, rapJitter, ppq5Jitter, local Shimmer, localdbShimmer, apq3Shimmer, apq5Shimmer, apq11Shimmer, JitterPCA, and ShimmerPCA. F0 refers to the fundamental frequency, harmonic to-noise ratio is the ratio of periodic to aperiodic components, Jitter describes frequency variation, and Shimmer describes amplitude variation. Praat voice features are derived from the time domain. Additionally, 13 Mel-frequency cepstral coefficients (MFCC) voice features were extracted from the frequency domain using the librosa Python library.
Univariate Analysis
A linear mixed model was created to examine the significant association between voice features and pain scores. For each model, pain was the outcome variable, and each voice feature was treated as its own predictor. A random intercept was added for each patient to control for variability in baseline pain perception.
Model Training
To train the machine learning model, the data were prepared for 5-fold cross-validation and ultimately divided into non-overlapping training set (80%) and test set (20%), ensuring that patients in the test set were not included in the training set data. To prevent the model from being biased towards larger voice features, robust scaling was applied to the training and test data before training. Robust scaling is a statistical method that scales data in a way that reduces the influence of outliers using the interquartile range. Due to sample size limitations, we created a binary classification model. Pain scores between 0 and 4 were classified as mild pain, while pain scores between 5 and 10 were classified as severe pain. The selection of these specific pain score groups was made to provide an equal number of severe and mild pain score samples.
K-Nearest Neighbor Based Predictive Model
A K-nearest neighbor (KNN) classifier was used to classify voice recordings into mild or severe pain categories. We chose this algorithm for its simplicity and interpretability. KNN is one of the commonly used machine learning algorithms in medical research. The algorithm works by plotting the training data in n-dimensional space and classifying each test data point based on the nearest K training data points. We also trained logistic regression and random forest models. The Scikit-learn Python library was used to build and train the machine learning models. All models were trained using the following computational hardware: Intel(R) Core (TM) i5-10210U CPU @ 1.60GHz, Architecture x86_64, Operating system Ubuntu 20.04.1 LTS, CPU(s): 8.
Results
Patient Demographics
After applying exclusion criteria, a total of 384 voice recordings from 60 different patients were used to train and test the KNN model (Figure 1). The average age was 58.5 years, with 26 (43.3%) patients being male. The median follow-up interval was 33 days (range 0-187 days). 53 (88.3%) patients were white. Most patients had lumbar diseases (61.7%), while cervical diseases (21.7%) were the second most common spinal disease locations (Table 1). Diagnoses of spinal diseases included 22 cases (36.7%) of central stenosis, 12 cases (20.0%) of disc herniation, 8 cases (13.3%) of foraminal stenosis, 8 cases (13.3%) of spondylolisthesis, and 4 cases (6.7%) of scoliosis. Conditions such as fractures, epidural masses, sacroiliac joint lesions, and discitis were considered as “other” diagnoses.
Among the 60 patients in the study, 36 (60.0%) underwent surgery. Among the patients who underwent surgery, 27 (75.0%) had at least one voice recording preoperatively, and 26 (72.2%) had at least one voice recording postoperatively. 17 patients (47.2%) had at least one voice recording before and after surgery. Among patients with at least one voice recording postoperatively, the median follow-up time from the date of surgery was 47 days (range 0-273 days).
Table 1. Patient Characteristics

Pain and Voice Data
The median number of audio files per patient was 5 (range 1-28, Figure 2), with an average pain score of 4.6 ± 2.7 (Table 2). Figure 3 provides a histogram of pain scores. The average recording length was 43.3 ± 10.1 seconds. After converting pain scores into mild and severe pain, there were 183 voice samples of mild pain scores and 201 voice samples of severe pain scores.
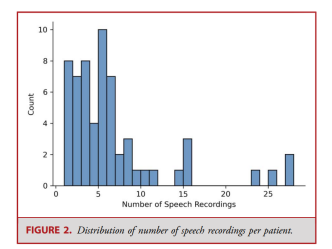
Figure 2. Distribution of the number of voice recordings per patient
Table 2. Voice Recordings and Pain Scores
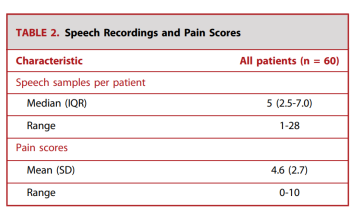
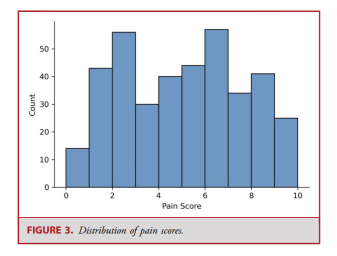
Figure 3. Distribution of Pain Scores
Univariate Analysis
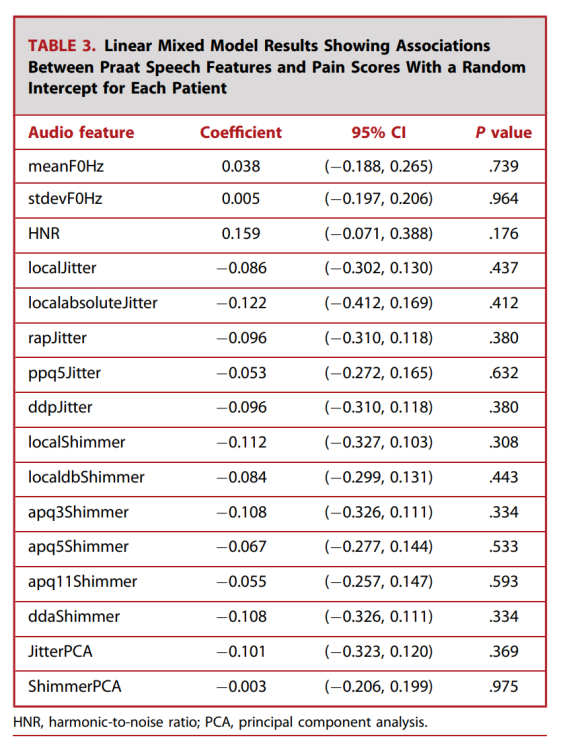
The results of our linear mixed model analysis indicated that all Praat voice features were not significantly associated with pain scores (Table 3). MFCC 2 (Coef: 0.552; 95% CI: [0.254, 0.850]; P< 0.001) and MFCC 12 (Coef: 0.286; 95% CI: [0.538, 0.034]; P= 0.026) were significantly associated with pain scores (http://links.lww.com/NEU/D762).
Table 3. Results of the linear mixed model showing the relationship between Praat voice features and pain scores, with random intercepts for each patient
Model Performance
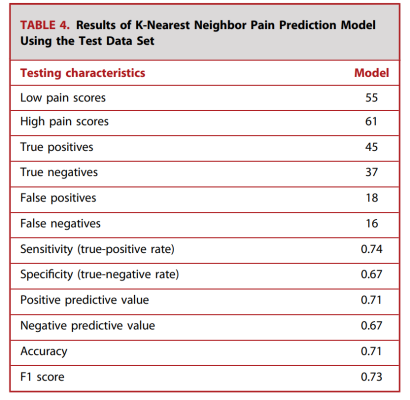
There were 268 voice recordings in the training set and 116 voice recordings in the test set. In the test set, 55 samples (47.4%) were mild pain and 61 samples (52.6%) were severe pain. KNN achieved a prediction accuracy of 71% on the test set. Figure 4 shows a confusion matrix that indicates an accuracy of 0.71 for severe pain and a recall of 0.74. For mild pain, the accuracy was 0.70 and the recall was 0.67. The overall F1 score was 0.73 (Table 4). The results of the logistic regression and random forest models can be seen at http://links.lww.com/NEU/D763 and http://links.lww.com/NEU/D764. The KNN model results using MFCC features as predictors can be seen at http://links.lww.com/NEU/D765.
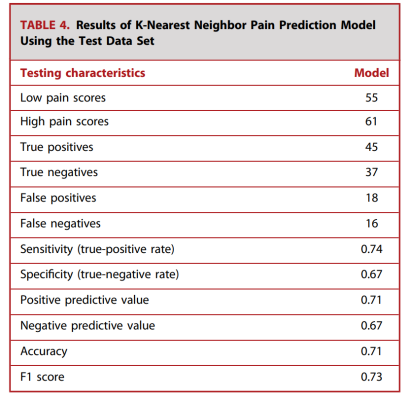
Figure 4. Confusion Matrix of the KNN Pain Prediction Model
Table 4. Results of the K-nearest neighbor pain prediction model using the test dataset
Discussion
Spinal diseases remain common in neurosurgical practice and often lead to severe pain. Although current pain assessment methods have been validated in clinical practice, they are subject to biases from patients’ recollections and require patients to visit the clinic in person. Continuous and remote pain monitoring through smartphones and other mobile devices offers significant value for neurosurgeons in assessing patients. Using digital phenotyping data, timely pain assessments conducted at home can complement current pain assessment tools, allowing better control of patients’ perceptions of their pain. The aim of our study was to establish a data-driven machine learning model that uses voice data collected from patients with spinal diseases’ personal smartphones to predict their pain levels for the day.
Pain recollection is multifaceted, encompassing the severity, duration, and timing of pain. Pain intensity is often considered the most critical factor in pain perception, with severe pain leading to immobility, sleep deprivation, medication dependence, and anxiety. Additionally, chronic pain can be complex and often varies over time. Thus, patients may struggle to communicate their pain experiences to neurosurgeons between follow-ups. Furthermore, self-reported pain outcomes may be biased by pain intensity and the time of day. On the other hand, digital phenotyping analysis helps us understand patients’ daily functioning through two aspects: (1) the ubiquity and familiarity of smartphones and (2) the convenience of data acquisition.
Previous studies have continuously monitored patients using their smartphones in neurosurgical settings. Studies by Cote et al. and Boaro et al. utilized digital phenotyping to explore the relationship between pain and patient-reported outcomes using GPS data from the Beiwe smartphone application. In 2019, Cote et al. used a linear mixed model approach based on GPS summary statistics to find a correlation between pain exacerbation and immobility. More recently in 2021, Boaro et al. demonstrated that GPS summary statistics significantly correlated with visual analog scales, the Oswestry Disability Index, and patient-reported outcome measurement information system 10 physical health scores. These studies collectively demonstrate that digital phenotyping data collected from personal smartphones can reveal patients’ health status at home. Our study enriches these findings by providing a framework for objectively and continuously assessing pain caused by spinal diseases in a home environment.
The human body signals pain through various media, including electrical signals, facial expressions, and language. Previous studies have utilized voice features to detect depression, Alzheimer’s disease, and schizophrenia. In an observational study by Di Matteo et al., ambient voice recorded from patients with depression and anxiety was correlated with clinical symptoms. Additionally, Laguarta et al. proposed a model capable of distinguishing whether a patient had COVID-19 by analyzing a large database of cough recordings from over 5,000 participants. The evidence provided by these studies suggests that language can serve as a physiological marker for diagnosing numerous diseases. Data collected from mobile devices may allow for the creation of linguistic biomarkers representing pain. However, it remains unclear which voice features are most suitable for understanding pain.
In our study, we utilized audio features from Praat software due to their simplicity and widespread use in voice research. We also tested MFCC features with our machine learning model. Although MFCC 2 and 12 were significantly associated with pain scores in the univariate mixed model analysis, they did not improve the accuracy of the KNN model compared to using Praat features for training. MFCCs are commonly used audio features in voice analysis, representing the transformation of audio signals that simulate how the human ear perceives sound. Researchers have also developed other audio features to study human speech. OpenSmile is a common voice analysis software that includes certain aspects of MFCC features, among many other functions. The diversity of voice features should be further explored to discover those that impact the understanding of pain.
Machine learning techniques have recently gained attention for their ability to automatically analyze biological markers and predict real-time pain, including KNN, support vector machines, and tree-based methods (such as random forest algorithms). By learning patterns from massive datasets, machine learning techniques are powerful tools for utilizing clinically relevant features and constructing predictive models. In 2021, Kong et al. published a study in which they established a random forest machine learning model to predict real-time pain using skin electrical activity from calibrated wrist devices. Similarly, Hasan et al. implemented a support vector machine classification model applicable to facial recognition technology to predict pain. However, there has been limited research on training machine learning models to predict pain using audio biological markers.
Inspired by these previous studies, our research explored machine learning techniques to utilize voice features as predictive factors. Given our relatively small dataset, we employed the KNN machine learning model, which we believe is best suited for our voice data. Current deep learning frameworks include convolutional neural networks, long short-term memory networks, and transformers that can learn complex temporal relationships in voice signals. These models can better handle heterogeneous populations and improve discrimination across multiple pain levels. While we explored other models in our experiments, including random forests, support vector machines, and artificial neural networks, these more powerful algorithms typically perform better on larger datasets.
One advantage of digital phenotyping analysis methods for pain assessment is the potential reduction in management costs associated with survey administration. To implement our technology in a clinical setting, we believe that integration with electronic medical records is essential. Furthermore, it is crucial to standardize data collection across institutions and simplify patient participation. The proposed workflow includes an example of how our approach could be implemented in clinical practice. Between two visits, patients will be asked to fill out regular pain surveys and provide sample recordings using their smartphones. These pain surveys and voice recordings will be combined with other digital phenotyping data sources in a comprehensive machine learning model to provide pain estimates while correcting for patients’ perceived differences over time.Next, the model will directly upload pain estimates to electronic medical records and patients’ survey responses for direct comparison. Doctors and patients will use this data during their next visit to discuss appropriate treatment plans. The proposed digital phenotyping workflow is illustrated in Figure 5.
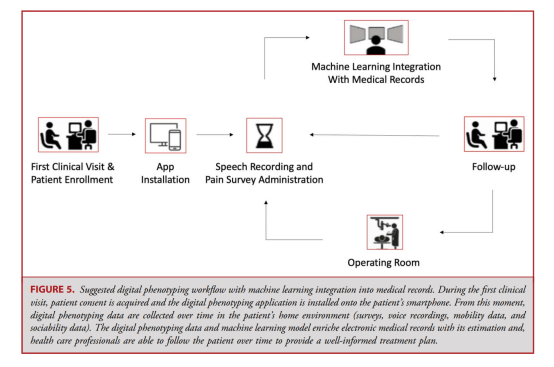
Figure 5. Proposed digital phenotyping workflow for integrating machine learning into medical records. During the first clinical visit, patient consent is obtained and the digital phenotyping application is installed on the patient’s smartphone. From that moment on, digital phenotyping data (surveys, recordings, mobile data, and social data) are collected in the patient’s home environment over time. Digital phenotyping data and machine learning models enrich electronic medical records, allowing healthcare professionals to continuously track patients to provide informed treatment plans.
Limitations
Although we consider this study a valuable addition to previous research, we must acknowledge some limitations. Our study was limited to spinal disease patients from a single institution, which may not be generalizable to other neurosurgical clinics, and our limited sample size of 60 patients is insufficient to establish a generalizable model. Multi-center studies involving patients from different disciplines could yield more universally applicable results. Our pain prediction model is based on self-reported pain scores, and therefore, the predictions are based on patients’ perceptions of pain rather than objective measurements. Due to the time interval of up to 24 hours between pain surveys and voice recordings, voice features may not capture transient pain episodes occurring at the time of the survey, making our study more suitable for assessing chronic pain. Additionally, there are significant variations in follow-up times and participation frequencies among patients. Therefore, our data are not independent of each other, as some patients contributed multiple voice samples. While we chose to use the KNN model for simplicity and interpretability, a model that considers related data may be a better choice in the long run. With a larger dataset, we could optimize predictive accuracy by analyzing more complex voice features using deep learning methods.
Conclusion
This study provides an opportunity for practical objective pain assessment for neurosurgical patients with spinal disease in a home environment. There is limited research exploring the association between smartphone voice data and pain in neurosurgical patients. Here, we propose a machine learning-based approach that quantifies pain using voice data from smartphones and self-reported pain surveys from a group of spinal disease patients. Using our predictive model as a baseline, future models could refine our framework to better assess pain levels in spinal disease patients.
Original Literature



Statement: The Gu Ma Jin Zui public account is under the Shuyi Hui brand, and the intellectual property of the content published by the Gu Ma Jin Zui public account belongs to Shuyi Hui and the organizers, original authors, and other related rights holders. Reprinting, excerpting, copying, cutting, or recording is prohibited without permission. If authorized for use, the source must also be indicated. Sharing and forwarding are welcome.