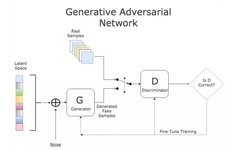

1. Introduction to GAN
-
Through adversarial learning, it learns a generative model of the data distribution. GAN is an unsupervised process that captures the distribution of the dataset so that it can generate data from random noise that follows the same distribution.
-
D Discriminator: learns the boundary between real and fake data -
G Generator: learns the data distribution and generates data
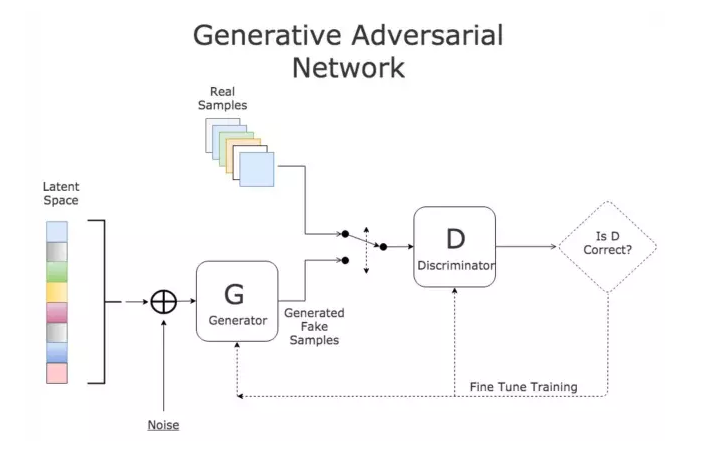
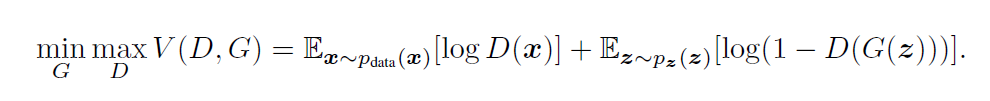
2. Practical CycleGAN Style Transfer

2.1 Introduction to CycleGAN

-
Two-way GAN: two generators [G: X->Y, F: Y->X] and two discriminators [Dx, Dy]. The purpose of G and Dy is to generate objects, while Dy (the positive class is the Y domain) cannot discriminate. Similarly, F and Dx are the same. -
Cycle consistency: G is the generator for generating Y, and F is the generator for generating X. Cycle consistency constrains the range of objects generated by G and F, ensuring that the object generated by G can return to the original domain through the F generator, e.g., x->G(x)->F(G(x))=x.
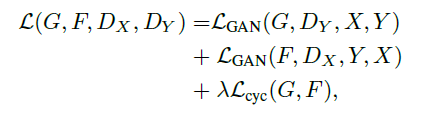

2.2 Implementing CycleGAN
2.2.1 Generator
<span>Perceptual Losses for Real-Time Style Transfer and Super-Resolution: Supplementary Material</span>. It can be roughly divided into: downsampling + residual block + upsampling, as shown in the figure (excerpted from the paper):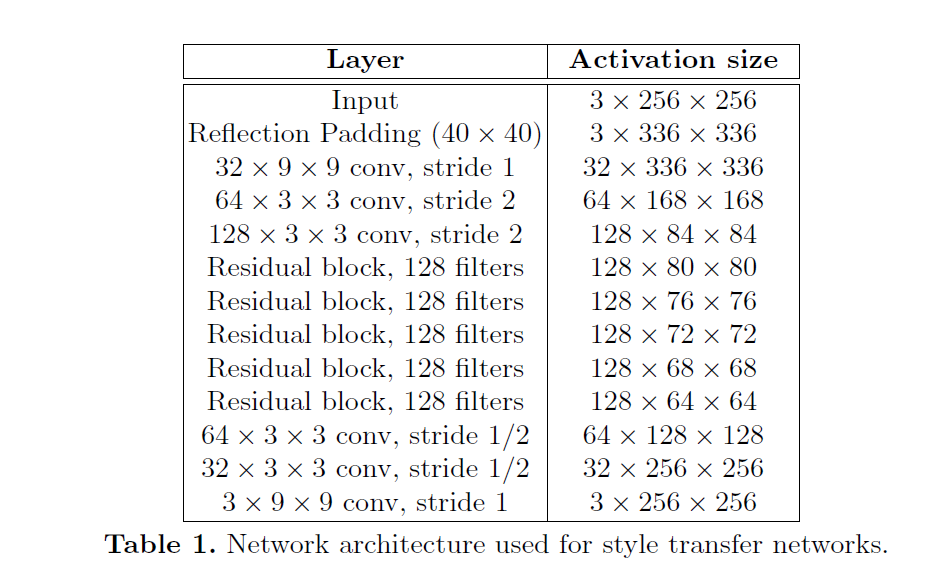
# Residual block
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
)
def forward(self, x):
return x + self.block(x)
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0]
# Initial convolution block
out_features = 64
model = [
nn.ReflectionPad2d(channels),
nn.Conv2d(channels, out_features, 7),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Downsampling
for _ in range(2):
out_features *= 2
model += [
nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Residual blocks
for _ in range(num_residual_blocks):
model += [ResidualBlock(out_features)]
# Upsampling
for _ in range(2):
out_features //= 2
model += [
nn.Upsample(scale_factor=2),
nn.Conv2d(in_features, out_features, 3, stride=1, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Output layer
model += [nn.ReflectionPad2d(channels), nn.Conv2d(out_features, channels, 7), nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)2.2.2 Discriminator
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# Calculate output shape of image discriminator (PatchGAN)
self.output_shape = (1, height // 2 ** 4, width // 2 ** 4)
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1)
)
def forward(self, img):
return self.model(img)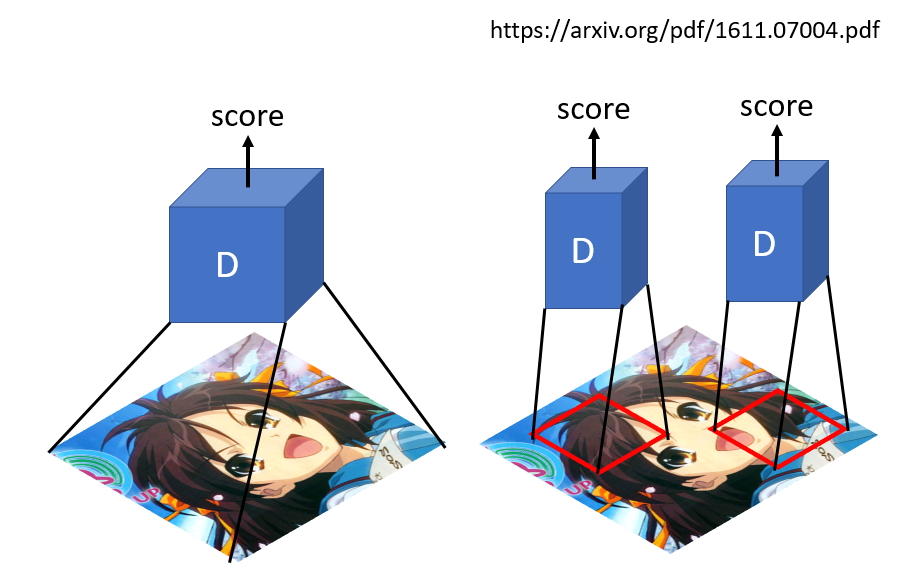
2.2.3 Training
# Losses
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
cuda = torch.cuda.is_available()
input_shape = (opt.channels, opt.img_height, opt.img_width)
# Initialize generator and discriminator
G_AB = GeneratorResNet(input_shape, opt.n_residual_blocks)
G_BA = GeneratorResNet(input_shape, opt.n_residual_blocks)
D_A = Discriminator(input_shape)
D_B = Discriminator(input_shape)# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Learning rate update schedulers
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(
optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(
optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(
optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)-
The training data consists of paired data, but they are unpaired, meaning A and B have no direct connection. A is the original image, and B is the style image. -
Generator Training -
GAN loss: the discriminator judges the loss between the two generated images fake_A and fake_B and the ground truth. -
Cycle loss: the differences between the generated images fake_A and fake_B and the original images A and B. -
Discriminator Training: -
loss_real: MSELoss between the discriminator and the ground truth for A/B. -
loss_fake: MSELoss between the generated fake_A/fake_B and the ground truth.
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# The data consists of paired data, but they are unpaired, meaning A and B have no direct connection
real_A = Variable(batch["A"].type(Tensor))
real_B = Variable(batch["B"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *D_A.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *D_A.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
G_AB.train()
G_BA.train()
optimizer_G.zero_grad()
# Identity loss
loss_id_A = criterion_identity(G_BA(real_A), real_A)
loss_id_B = criterion_identity(G_AB(real_B), real_B)
loss_identity = (loss_id_A + loss_id_B) / 2
# GAN loss
fake_B = G_AB(real_A)
loss_GAN_AB = criterion_GAN(D_B(fake_B), valid)
fake_A = G_BA(real_B)
loss_GAN_BA = criterion_GAN(D_A(fake_A), valid)
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Cycle loss
recov_A = G_BA(fake_B)
loss_cycle_A = criterion_cycle(recov_A, real_A)
recov_B = G_AB(fake_A)
loss_cycle_B = criterion_cycle(recov_B, real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# Total loss
loss_G = loss_GAN + opt.lambda_cyc * loss_cycle + opt.lambda_id * loss_identity
loss_G.backward()
optimizer_G.step()
# -----------------------
# Train Discriminator A
# -----------------------
optimizer_D_A.zero_grad()
# Real loss
loss_real = criterion_GAN(D_A(real_A), valid)
# Fake loss (on batch of previously generated samples)
# fake_A_ = fake_A_buffer.push_and_pop(fake_A)
loss_fake = criterion_GAN(D_A(fake_A_.detach()), fake)
# Total loss
loss_D_A = (loss_real + loss_fake) / 2
loss_D_A.backward()
optimizer_D_A.step()
# -----------------------
# Train Discriminator B
# -----------------------
optimizer_D_B.zero_grad()
# Real loss
loss_real = criterion_GAN(D_B(real_B), valid)
# Fake loss (on batch of previously generated samples)
# fake_B_ = fake_B_buffer.push_and_pop(fake_B)
loss_fake = criterion_GAN(D_B(fake_B_.detach()), fake)
# Total loss
loss_D_B = (loss_real + loss_fake) / 2
loss_D_B.backward()
optimizer_D_B.step()
loss_D = (loss_D_A + loss_D_B) / 2
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Update learning rates
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()2.2.4 Result Presentation


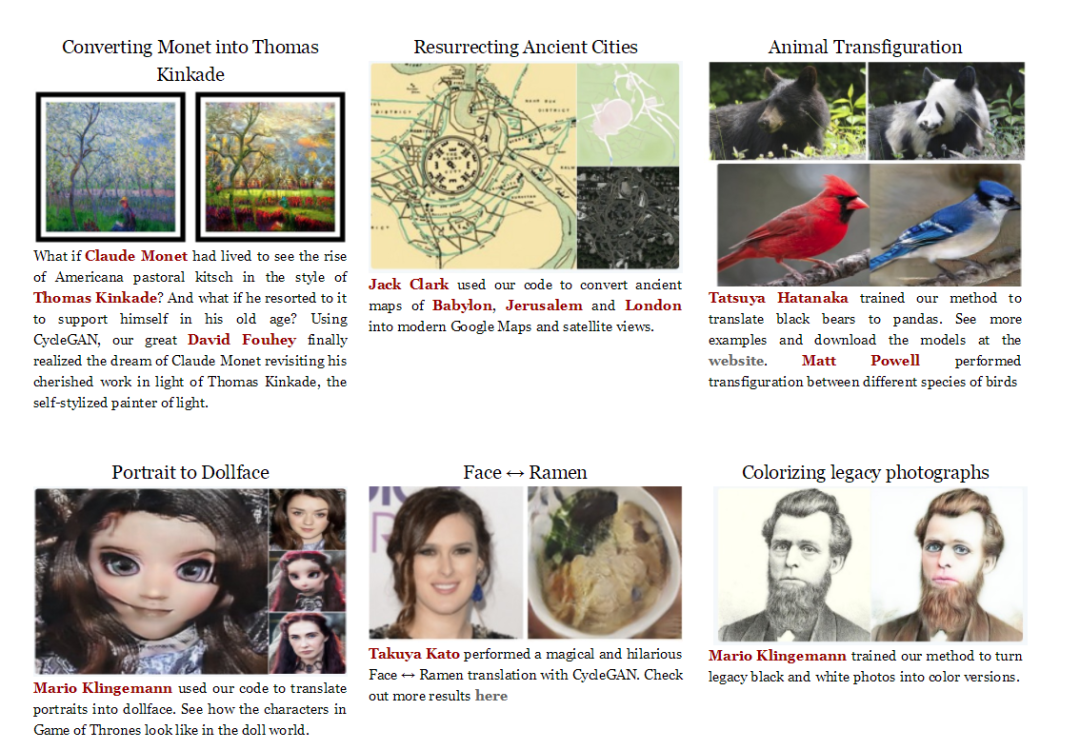
2.2.5 Other Uses of CycleGAN

3. Summary
-
GAN learns the distribution in the data and generates new data that follows the same distribution. -
CycleGAN consists of two-way GANs: two generators and two discriminators; to ensure that the images generated by the generator have a certain relationship with the input images, rather than being randomly produced, cycle consistency is introduced to determine the differences between A->fake_B->recov_A and A. -
Generator: downsampling + residual block + upsampling. -
Discriminator: instead of generating a single judgment value for one image, it uses patchGAN, generating N*N values and then taking the average.
Author Introduction: Wedo Experimenter, Data Analyst; loves life and writing.
Support the Author

More Reading
Google AI Team Uses GAN Model to Synthesize Abnormal Creatures
NVIDIA Research Develops Method to Train GAN with Fewer Datasets
Attention Mechanism Practice in Image Caption Generation in Python
Highly Recommended


Click below to read the original text and join the community membership