

Image source from the internet Written by/GitPython
You must have used those “OCR tools” that can extract text from images, greatly improving work efficiency.
Today, we are going to create a small tool for real-time screenshot recognition. As the name suggests, when the program runs, it can recognize the text in the images you capture in real-time.
Next time, when you want to copy content from “Baidu Wenku,” give this program a try.
Preview of the effect
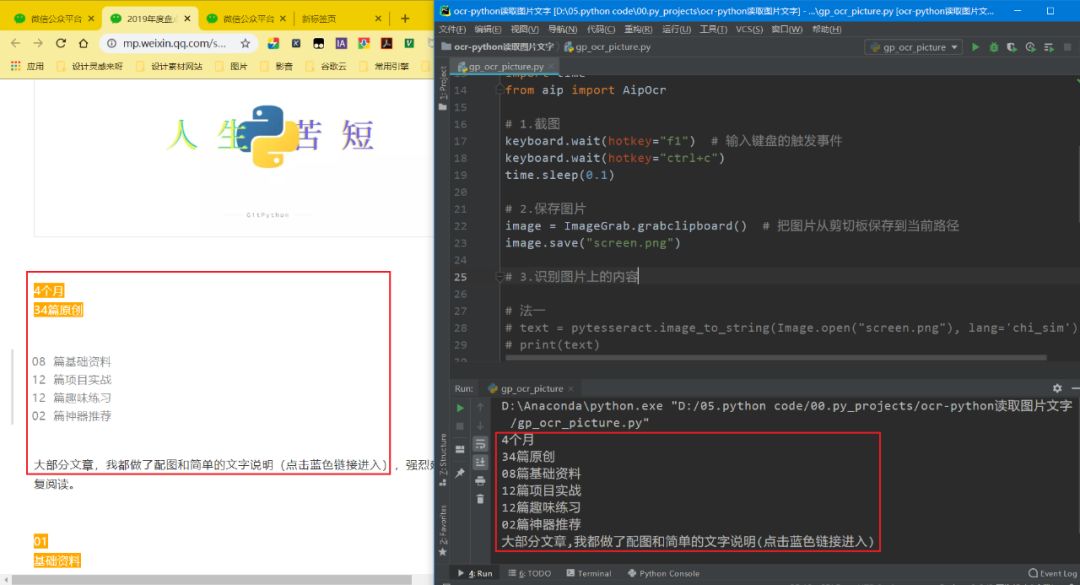
 Source code analysis1) Wait for the user to take a screenshotThis requires the use of the screenshot tool (Snipaste)Where “f1” is the screenshot shortcut, “ctrl+c” is the shortcut to save the screenshot to the clipboard.If you are using QQ screenshot,you need to change the shortcuts to the corresponding “ctrl+alt+c” and “enter”
Source code analysis1) Wait for the user to take a screenshotThis requires the use of the screenshot tool (Snipaste)Where “f1” is the screenshot shortcut, “ctrl+c” is the shortcut to save the screenshot to the clipboard.If you are using QQ screenshot,you need to change the shortcuts to the corresponding “ctrl+alt+c” and “enter”
By the way, I recommend Snipaste,
a must-have efficiency tool
import keyboard
# Use the screenshot software (Snipaste) to capture to clipboard
# Input keyboard trigger events
keyboard.wait(hotkey="f1")
keyboard.wait(hotkey="ctrl+c")
time.sleep(0.1)
After executing the above code, there is now an image waiting in the clipboard.2) Save the screenshotUsing the PIL module’s ImageGrab, you can save the image from the clipboard to the current directory and name it “screen.png”
from PIL import ImageGrab
# Save the image from the clipboard to the current path
image = ImageGrab.grabclipboard()
image.save("screen.png")
3) Recognize the text in the screenshotMethod 1Using the pytesseract moduleAdvantages: free, easy to useDisadvantages: recognition quality is average, accuracy is not highUsage instructions:1) pip install pytesseract2) Install tesseract-ocr.exe and configure the environment variables3) Modify the pytesseract.py file to point tesseract_cmd to the absolute path of Tesseract-OCR’s tesseract.exe.
Reference article
See the first comment
import pytesseract
from PIL import Image
# Method 1: Use the pytesseract module
# Parameter 1: image
# Parameter 2: Simplified Chinese
text = pytesseract.image_to_string(Image.open("screen.png"), lang='chi_sim')
print(text)
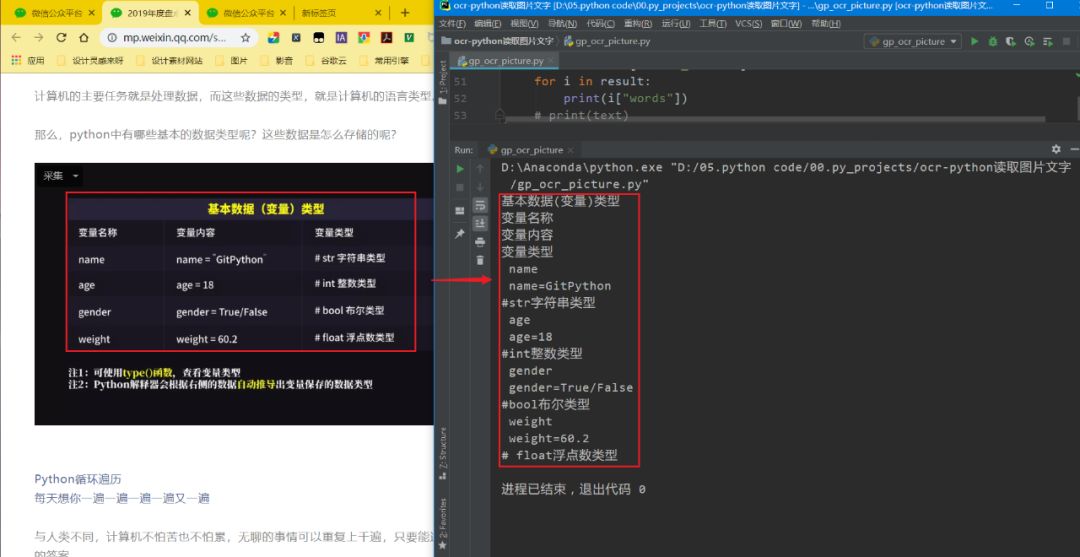
Let’s take a look at the effect: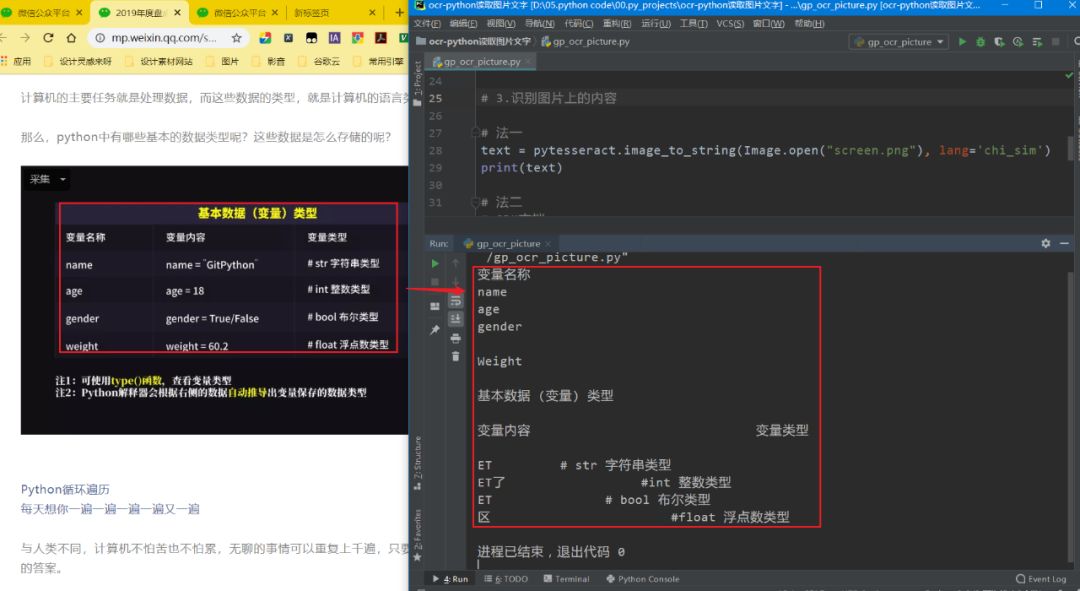 Low qualityIndeed, for high accuracy, using Baidu API is necessaryMethod 2Baidu API interfaceAI Open Platform Documentation Centerhttps://ai.baidu.com/ai-doc
Low qualityIndeed, for high accuracy, using Baidu API is necessaryMethod 2Baidu API interfaceAI Open Platform Documentation Centerhttps://ai.baidu.com/ai-doc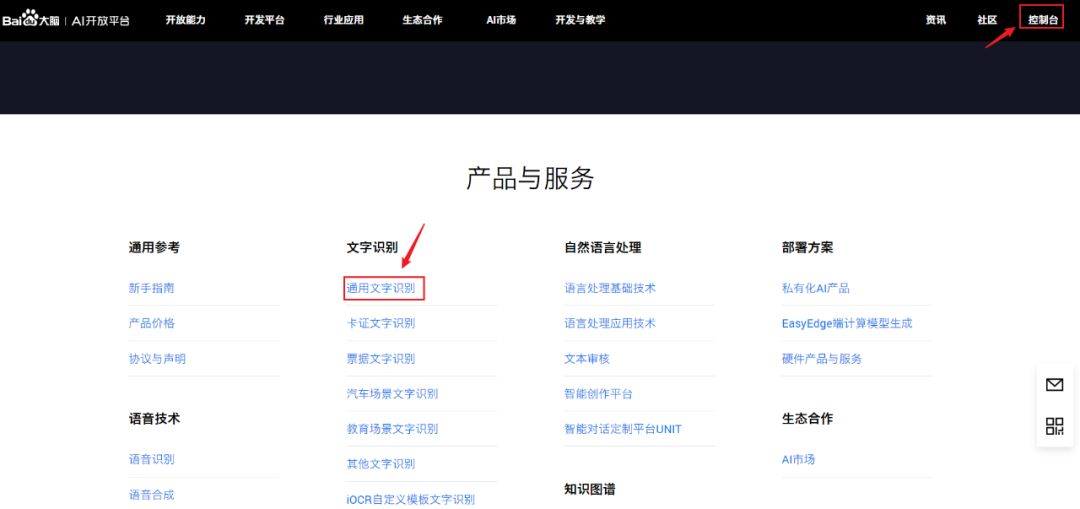 View the SDK documentation for Python
View the SDK documentation for Python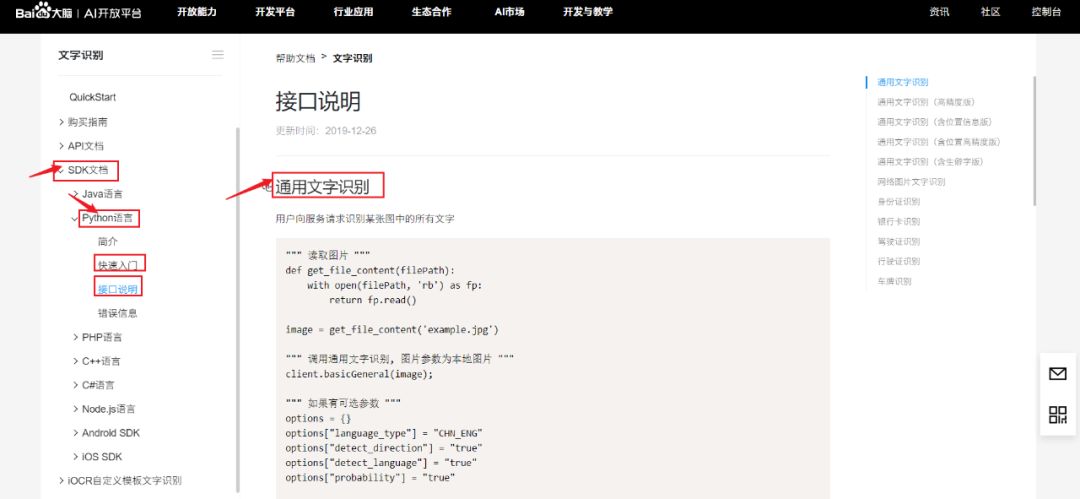 Click the top right corner (console), log into your Baidu account, and create an application for “text recognition”
Click the top right corner (console), log into your Baidu account, and create an application for “text recognition”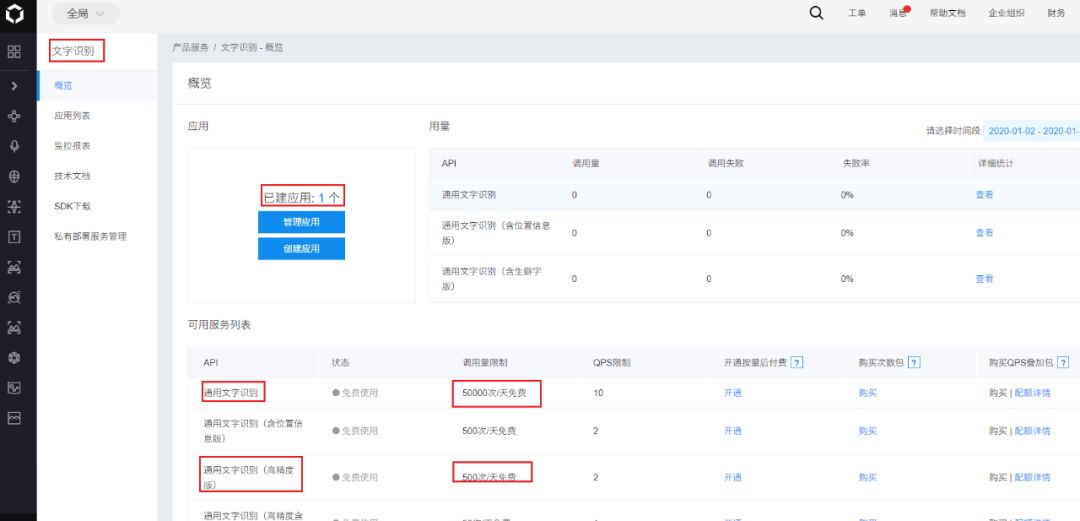
import pytesseract
from aip import AipOcr
from PIL import ImageGrab
# Method 2: Use Baidu API
APP_ID = 'Your App ID'
API_KEY = 'Your Api Key'
SECRET_KEY = 'Your Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# Read the image
with open("screen.png", 'rb') as f:
image = f.read()
# Call Baidu API for general text recognition (high precision version), extract content from the image
text = client.basicAccurate(image)
result = text["words_result"]
for i in result:
print(i["words"])
ResultsAs shown in the first image of the article: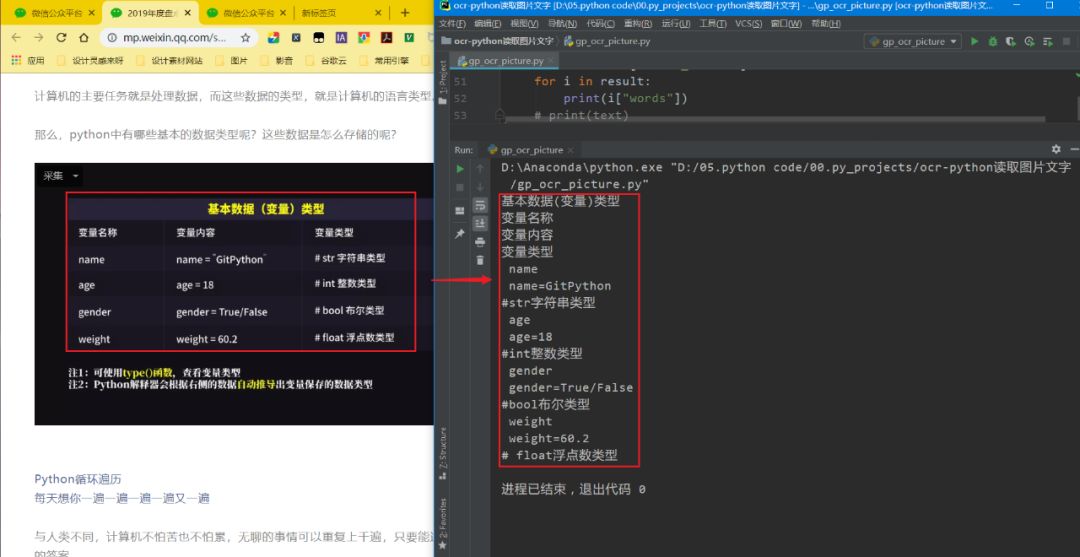
This is my summary
1) Wait for the user to take a screenshot2) Save the screenshot to the current directory3) Recognize the text in the screenshotThere are two methods for recognizing text in the screenshot:
1) Use the pytesseract module
2) Use the Baidu API interface
 ▼Click to become a registered member of the community If you like the article, please give it a thumbs up
▼Click to become a registered member of the community If you like the article, please give it a thumbs up