
This article is sourced from: New Intelligence Yuan
Reprinted from: Machine Translation Observation

On May 30, the 4th session of the Zhiyuan Forum, hosted by the Beijing Zhiyuan Artificial Intelligence Research Institute, titled “Knowledge and Cognitive Graphs,” was successfully held at Tsinghua University. Liu Yang, a tenured associate professor in the Department of Computer Science at Tsinghua University, addressed the three major challenges faced by machine translation based on neural networks and deep learning: knowledge integration, interpretability/visualization, and robustness. He introduced the latest research and breakthroughs of his team regarding these three challenges.
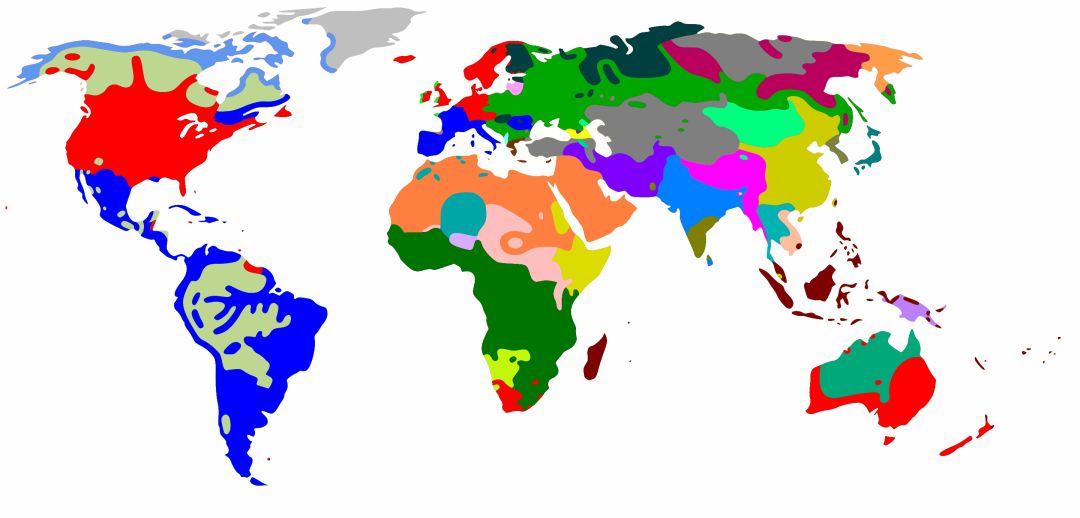
World Language Distribution Map (Source: Wikipedia)
Address:
https://en.wikipedia.org/wiki/Linguistic_map
Currently, there are approximately 6,000 languages in the world, of which over 3,000 have a mathematical system. As shown in the figure above, the languages spoken in different countries and regions vary greatly. There are many issues in communication between different languages, which we commonly refer to as the “language barrier.”
Machine translation is a key technology for solving the language barrier problem.
The concept of machine translation has existed for several centuries, but it only began to become a reality in the early 1950s. Since then, significant progress has been made in machine translation.
The main task of machine translation is to automatically translate one language into another, which appears to be a function mapping problem. However, the difficulty lies in the complexity of language itself and the diversity of language types.
The world’s languages can be classified morphologically into: inflectional languages, agglutinative languages, and isolating languages. How to convert these languages is an important problem that machine translation must solve(detailed content of the three language forms can be found at the end of the article).
After 1990, especially with the advent of the internet, a large amount of readable and machine-readable text became available, leading to a greater reliance on data for machine translation. This period can be divided into two phases:
-
The first phase involved using traditional statistical methods (from 1990 to 2013), which required and depended on manually written features;
-
The second phase adopted deep learning methods (from 2013 to present). This phase does not require manually written features, only writing rules, and later only requires writing frameworks.
As development progresses, human involvement becomes increasingly refined. Currently, the mainstream method is the data-driven approach.
By 2016, machine translation had essentially adopted machine learning in the commercial sector. The core idea is to use a very complex core network to perform nonlinear functions, projecting the source language to the target language. Therefore, how to design such a function has become a critical issue.
On May 30, the 4th session of the Zhiyuan Forum, hosted by the Beijing Zhiyuan Artificial Intelligence Research Institute, titled “Knowledge and Cognitive Graphs,” was successfully held at Tsinghua University.

Liu Yang, a tenured associate professor and doctoral advisor in the Department of Computer Science at Tsinghua University
During the meeting, Professor Liu Yang delivered an excellent report on “Machine Translation Based on Deep Learning.”
Regarding the current state of machine translation, Professor Liu Yang believes that the methods based on neural networks and deep learning face three challenges:
-
The first is knowledge integration (Knowledge incorporation). How can prior knowledge be integrated into Neural Machine Translation (NMT)?
-
The second is interpretability. How to explain and understand NMT?
-
The third is robustness. How to make NMT robust to noise?
In response, Professor Liu Yang introduced his research focus and breakthroughs in the aforementioned three areas.
Three Major Challenges of Machine Translation: Knowledge Integration
How to incorporate knowledge into some application systems is a very hot topic.
Professor Liu Yang stated that data, knowledge, and models are very important for artificial intelligence as a whole. Researchers build a mathematical model to learn parameters from data, which to some extent is merely a representation, using the same model to solve real-world problems.
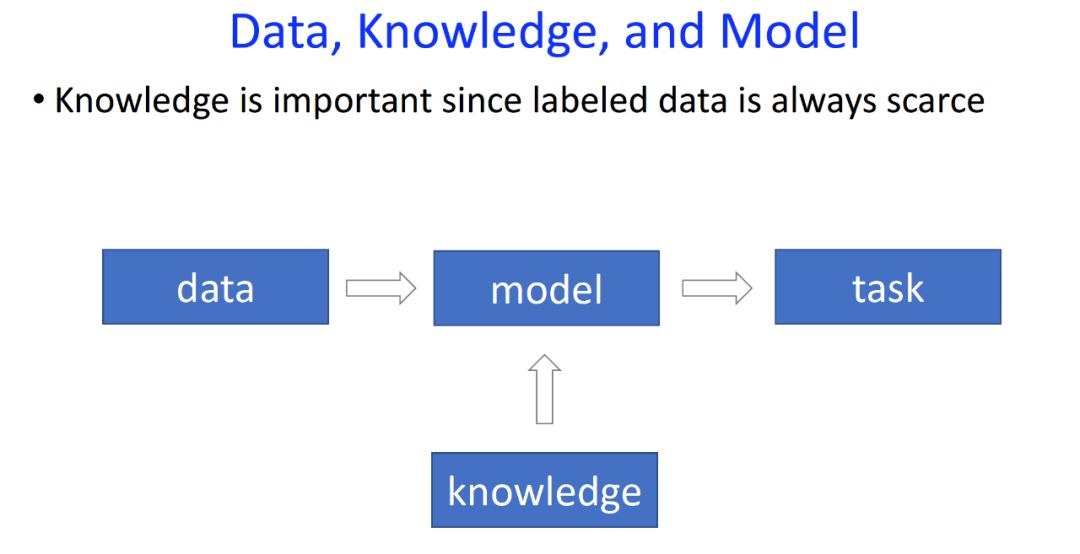
However, sometimes the amount of data is insufficient, for example, for languages like Eskimo and Uyghur, there is almost no data available. The translation of such less common languages becomes very challenging due to the scarcity of data. Therefore, it is worth considering incorporating knowledge.
Although neural machine translation has made significant progress in recent years, how to integrate multiple overlapping, arbitrary prior knowledge resources remains a challenge. In response to this issue, Professor Liu Yang and his team have conducted research.

arXiv address:
https://arxiv.org/pdf/1811.01100.pdf
In this work, it is recommended to use posterior regularization to provide a general framework for integrating prior knowledge into neural machine translation. The sources of prior knowledge are represented as features of a log-linear model, which guides the learning process of the neural translation model. Experiments in Chinese-English translation indicate that this method has achieved significant improvements.
Professor Liu Yang expressed the hope of providing a general framework where all knowledge can be added. Thus, this work represents human knowledge as one space, which is a symbolic space.
Then, deep learning’s numerical representation is another space, attempting to associate these two spaces, and through human knowledge dominating this knowledge, compressing traditional knowledge within, allowing it to understand the deep learning process, thereby providing a better general framework.
In this work, the following features are used to encode knowledge sources.
-
Bilingual Dictionary:
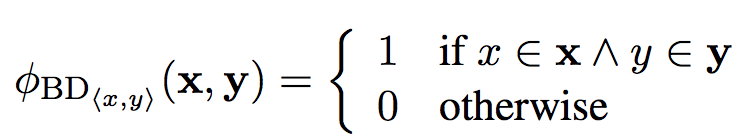
-
Phrase Table:
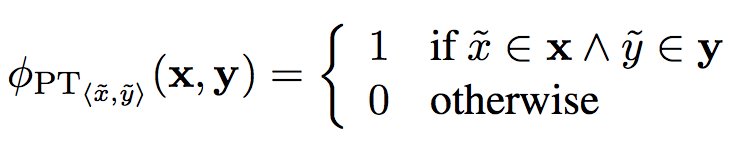
-
Coverage Penalty:

-
Length Ratio:
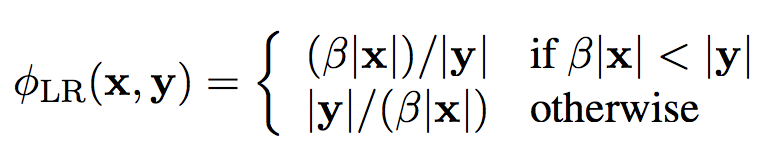
This work compares with RNNsearch, CPR, and PostReg, and the performance comparison results are as follows:
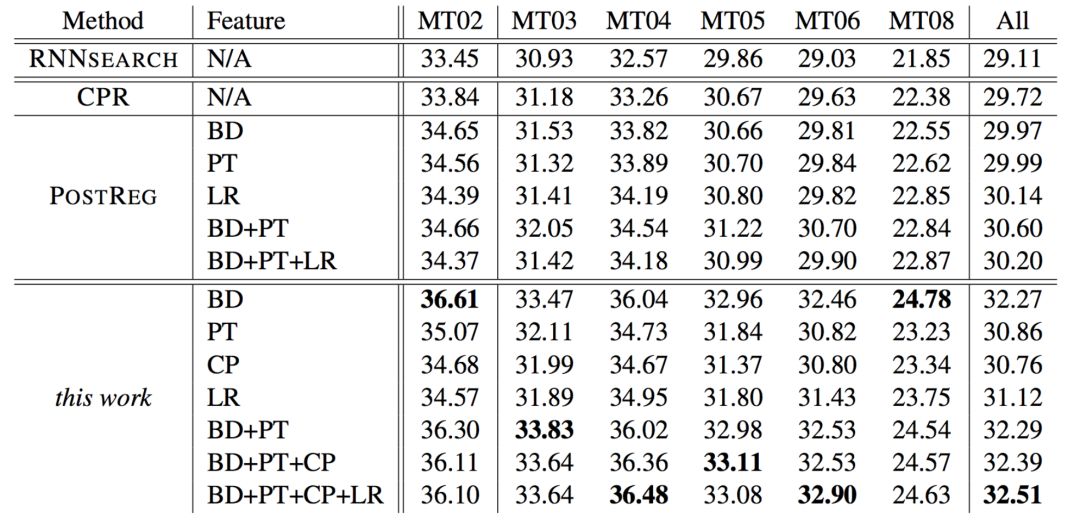
Comparison with RNNsearch, CPR, and PostReg
Three Major Challenges of Machine Translation: Interpretability/Visualization
The second issue is the problem of interpretability or visualization.
Currently, in the field of machine translation, neural machine translation has replaced statistical machine translation due to its better performance, becoming the mainstream method.
Most neural machine translation systems are based on attention mechanism encoder-decoder models. However, this model transmits floating-point numbers internally, making it similar to a “black box,” which is difficult to understand and debug.
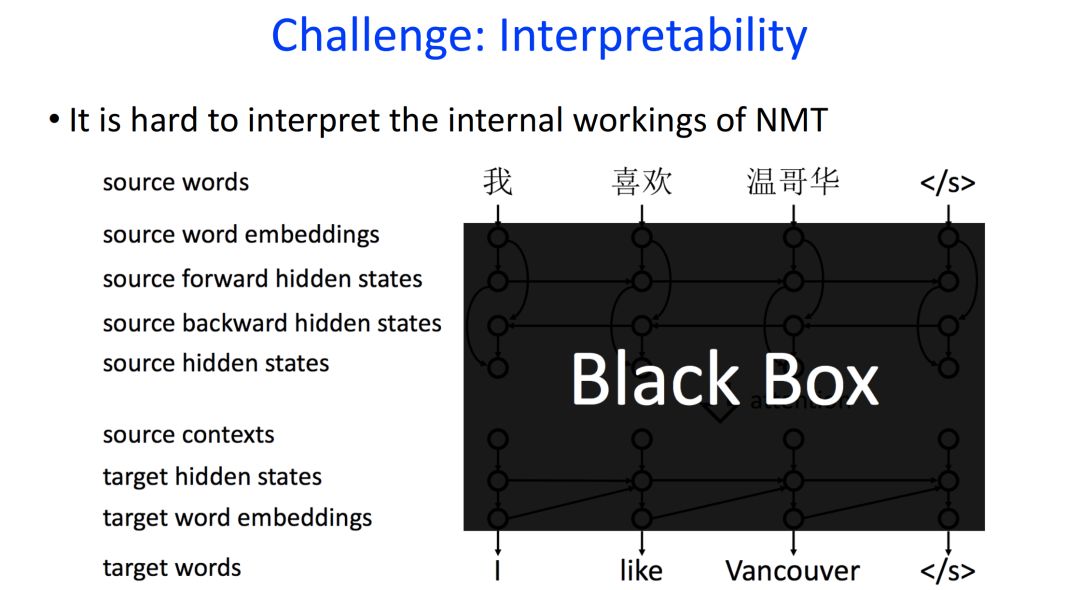
Models are like a “black box,” making it difficult to understand and debug
When inputting a sentence and outputting another, the generation process is unknown; when errors occur, the cause is also unclear.
Thus, researchers urgently hope to open this black box to understand how internal information is transmitted and what causes such errors.
In response to this issue, Professor Liu Yang and his team conducted corresponding work.

Paper address:
https://aclweb.org/anthology/P17-1106
The main contributions of this work include:
-
Using hierarchical relevance propagation algorithms for visual analysis of neural machine translation;
-
Can calculate the relevance of any hidden state and any contextual words without requiring the functions in the neural network to be differentiable, unlike previous methods that only provided corresponding information between encoder and decoder hidden layers;
-
Can analyze examples of errors in machine translation.
Recent work on interpreting and visualizing neural models has focused on calculating the contribution of units in the input layer to the final decision in the output layer. For example, in image classification, understanding the contribution of individual pixels to the classifier’s prediction is important.
In this work, the team is interested in calculating the contribution of source and target words to the internal information in the attention-based encoder-decoder framework.
As shown in the figure below, the generation of the third target word “York” depends on the source context (i.e., the source sentence “zai niuyue </ s>”) and the target context (i.e., the partial translation “in New”).
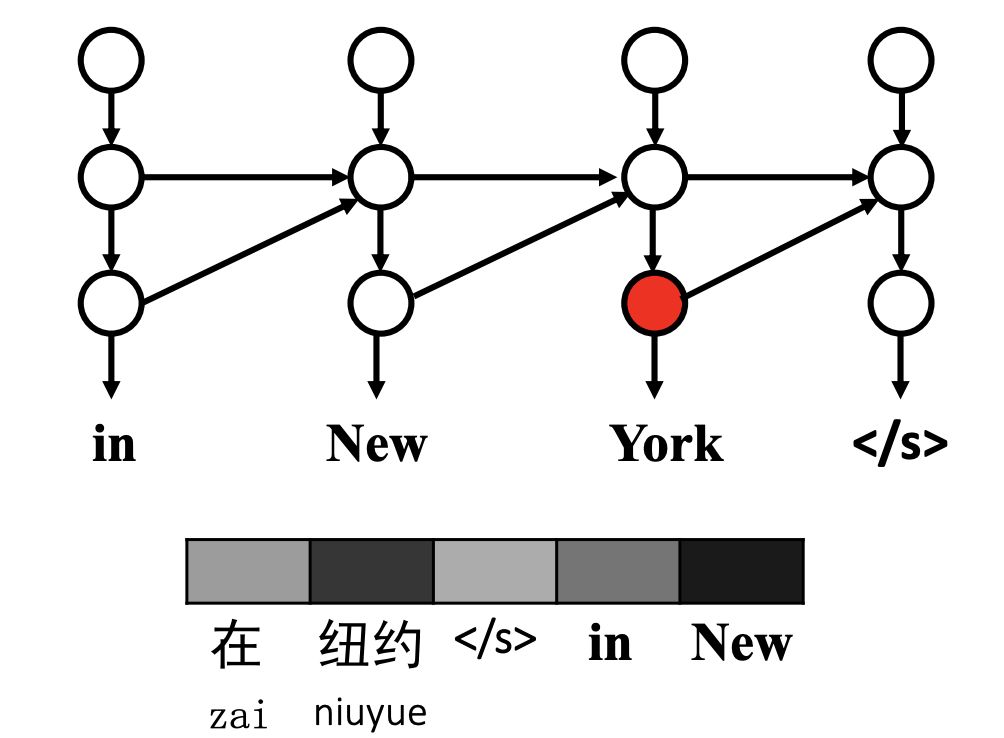
Intuitively, the source word “niuyue” and the target word “New” are more strongly associated with “York” and should receive higher relevance than other words. The question is how to quantify and visualize the correlation between hidden states and contextual word vectors.
Researchers use layer-wise relevance propagation (LRP) to calculate neuron-level relevance. The core idea of LRP is illustrated using a simple feedforward network shown in the figure below.
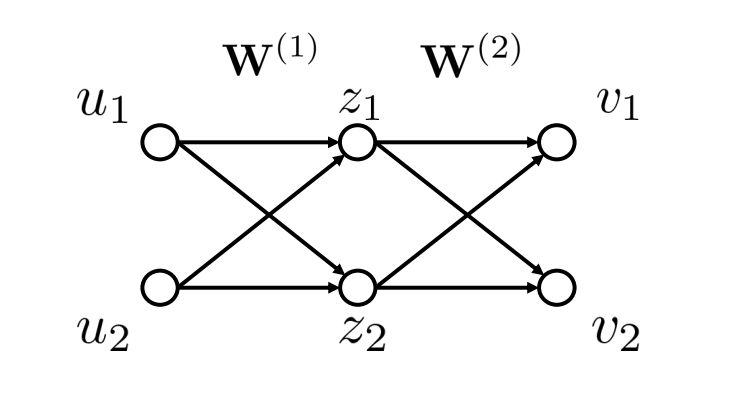
To calculate the relevance between v1 and u1, first calculate the relevance between v1 and z1, z2, and then propagate the relevance of v1 and z1, z2 to u1, thereby determining the relevance between v1 and u1.

LRP Algorithm for Neural Machine Translation
Through this technique, visual analysis can be performed on all models in machine translation.
Professor Liu Yang stated that LRP can generate relevance matrices for Transformers. It cannot be analyzed by itself, but with this technique, the input, output, and internal correlations can be presented visually, allowing for better analysis of the operational mechanism.
The team applied this to error analysis in machine translation, analyzing missed words, repeated translations, irrelevant words, and negation reversals.
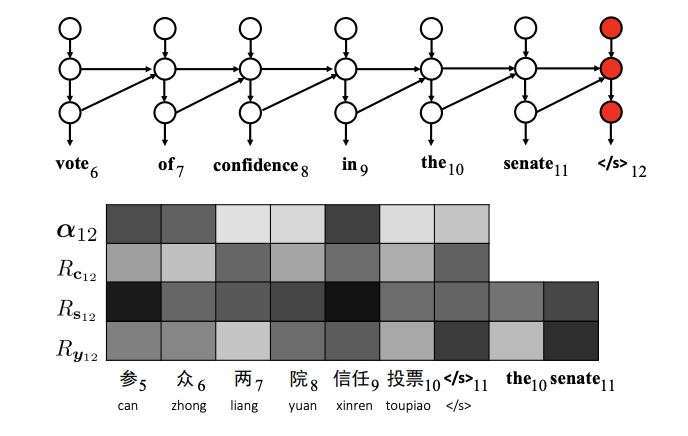
Error Analysis of Translation: Omission of Words. The 6th source word “zhong” was not translated correctly.
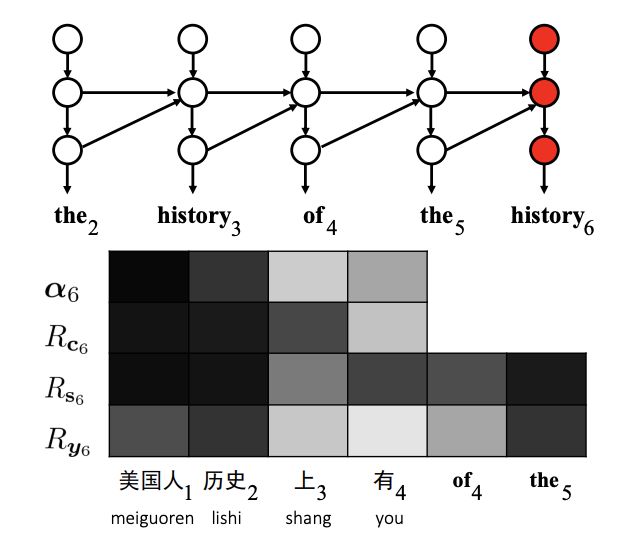
Error Analysis of Translation: Repeated Words. The target word “history” appeared incorrectly twice in the translation.
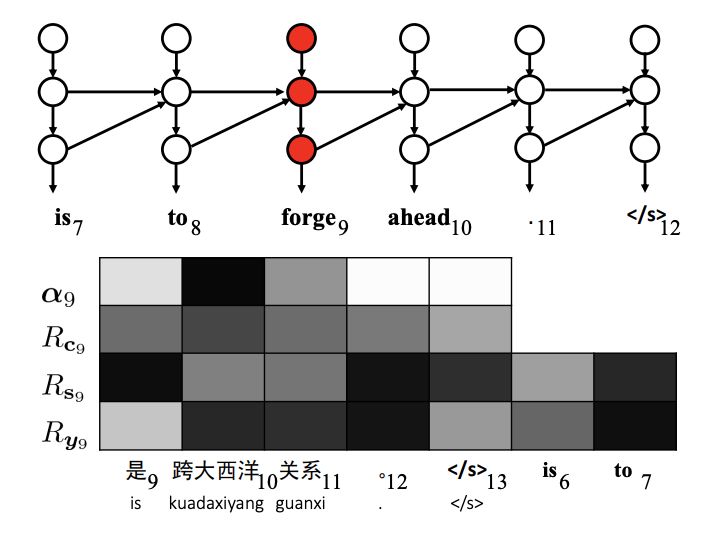
Error Analysis of Translation: Irrelevant Words. The 9th target word “forge” is completely unrelated to the source sentence.
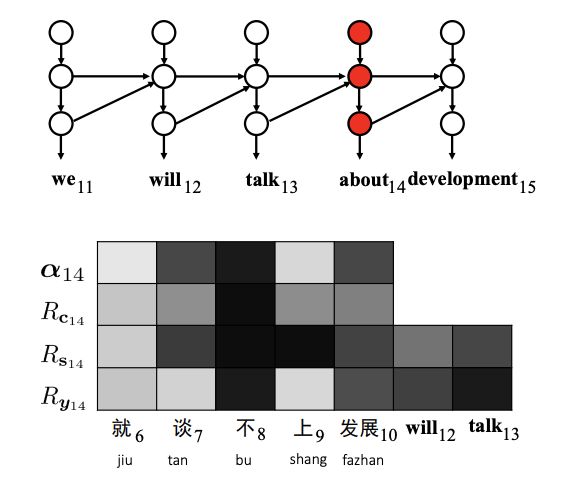
Error Analysis of Translation: Negation. The 8th negation word “bu” (not) was not translated.
Three Major Challenges of Machine Translation: Robustness
The third issue is robustness.
There is an example: suppose there is a translated sentence, “The new regulations for electronic banking in China will take effect from March 1.” If, by mistake, “China” is typed as “Zhongfang,” the subsequent translations will change, which Professor Liu Yang refers to as the butterfly effect.

This represents a more realistic problem: small perturbations in the input can severely distort the intermediate representation, thereby affecting the translation quality of the Neural Machine Translation (NMT) model.
This is because deep learning is a globally associative model; any small change can lead to widespread effects, which is very problematic.
To address this issue, Professor Liu Yang’s team conducted research on this problem.

arXiv address:
https://arxiv.org/pdf/1805.06130.pdf
In this research, the researchers proposed to improve the robustness of NMT models through adversarial stability training.
The basic idea is to make the encoder and decoder in the NMT model robust to input perturbations, so that they behave similarly for the original input and its perturbed counterparts.
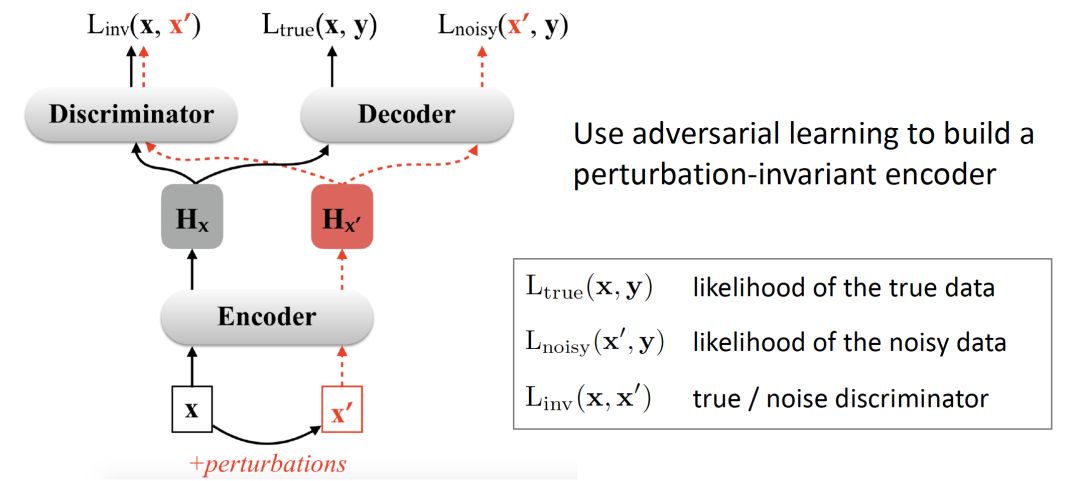
This work proposed two methods for generating synthetic noise.
Lexical Level:
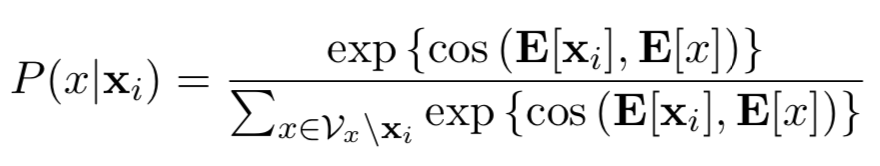
Feature Level:
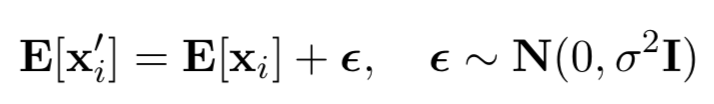
Given a source character, its neighbors in the vector space can be chosen as a noisy character.
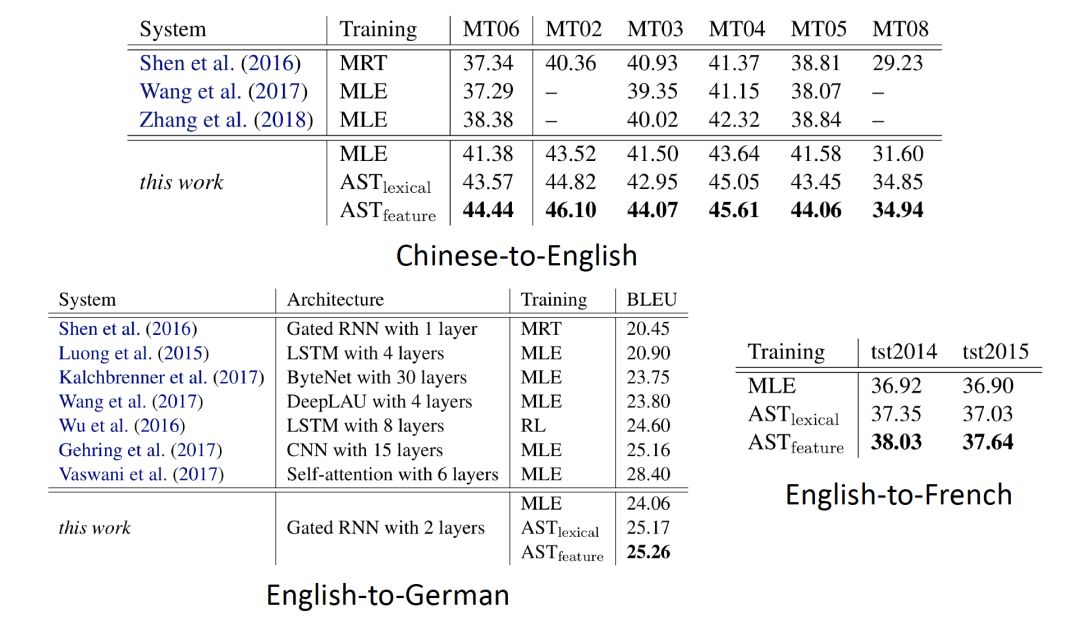
The impact of the loss function and the main experimental results are as follows:
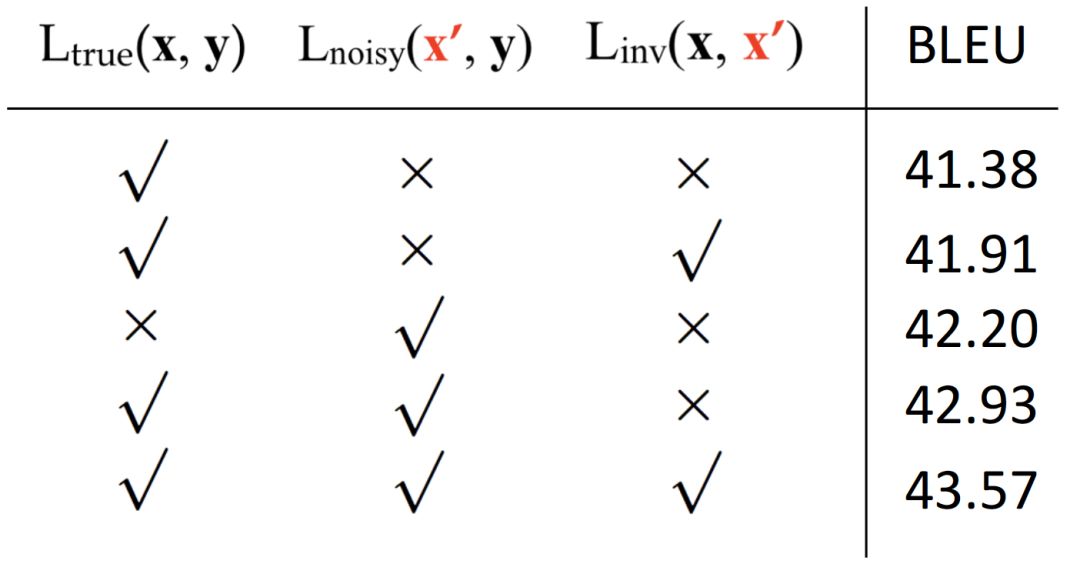
Finally, Professor Liu Yang provided an open-source toolkit for neural machine translation, and interested readers can visit the link below for experiments:

Open-source toolkit address:
http://thumt.thunlp.org/
Appendix: Detailed Content of Three Language Forms
-
Isolating languages, represented by Chinese, consist of independent words with complete meanings, forming sentences through simple addition.
-
Agglutinative languages, centered around the Ural-Altaic language family, connect independent words through particles and auxiliary verbs to complete the statement of the entire article.
-
Inflectional languages refer to the European language family, where words undergo complex morphological changes with respect to person, tense, case, etc.
References:
https://en.wikipedia.org/wiki/Linguistic_map
https://arxiv.org/pdf/1811.01100.pdf
https://aclweb.org/anthology/P17-1106
https://arxiv.org/pdf/1805.06130.pdf
http://thumt.thunlp.org/
