Click on the above “Beginner Learning Vision” to choose to add Star or “Pin”
Important content delivered first
Many articles on convolutional neural networks explain what CNNs are and their uses, while this article will implement a CNN using C++ and a library called mlpack to classify the MNIST dataset.
You may wonder why C++ is used when Python has many libraries that are easy to use; you may have seen some Tesla cars, which require real-time inference from their environment. While Python is great for prototyping, it does not provide real-time updates when deploying such large models.
It is a machine learning library written in C++ that leverages several underlying libraries to provide fast and scalable state-of-the-art machine learning and deep learning methods.
The data we will use is contained in a CSV file consisting of images of digits from 0 to 9, where the columns contain labels and the rows contain features. However, when we load the data into a matrix, the data will be transposed, and the labels indicating which feature will also be loaded, so we need to be aware of this.
#include <mlpack/core.hpp>#include <mlpack/core/data/split_data.hpp>#include <mlpack/methods/ann/layer/layer.hpp>#include <mlpack/methods/ann/ffn.hpp>#include <ensmallen.hpp> /* The numerical optimization library that mlpack uses */ using namespace mlpack;using namespace mlpack::ann; // Namespace for the armadillo library (linear algebra library).using namespace arma;using namespace std; // Namespace for ensmallen.using namespace ens;Next, we will declare a helper function to convert the model output to a row matrix to match the label format we loaded.
arma::Row<size_t> getLabels(arma::mat predOut){ arma::Row<size_t> predLabels(predOut.n_cols); for(arma::uword i = 0; i < predOut.n_cols; ++i) { predLabels(i) = predOut.col(i).index_mat() + 1; } return predLabels;}Below this part, the code will appear in the main function, but it is written not to make the code easy to interpret. Now we will declare some obvious training parameters we need and explain those highlighted parameters.
constexpr double RATIO = 0.1; // ratio to divide the data into train and validation sets.constexpr int MAX_ITERATIONS = 0; // set to zero to allow infinite iterations.constexpr double STEP_SIZE = 1.2e-3; // step size for Adam optimizer.constexpr int BATCH_SIZE = 50; constexpr size_t EPOCH = 2; mat tempDataset; data::Load("train.csv", tempDataset, true); mat tempTest; data::Load("test.csv", test, true);The parameter MAX_ITERATIONS is set to 0 because this allows us to iterate infinitely within one epoch, so we can use early stopping in the later stages of training. As a side note, early stopping can also be used when this parameter is not set to 0.
Let’s process and remove the columns describing the content in each row, as I mentioned in the data section, and create separate matrices for the labels and features of the training, validation, and test sets.
mat dataset = tempDataset.submat(0, 1, tempDataset.n_rows - 1, tempDataset.n_cols - 1); mat test = tempTest.submat(0, 1, tempTest.n_rows - 1, tempTest.n_cols - 1); mat train, valid; data::Split(dataset, train, valid, RATIO); const mat trainX = train.submat(1, 0, train.n_rows - 1, train.n_cols - 1); const mat validX = valid.submat(1, 0, valid.n_rows - 1, valid.n_cols - 1); const mat testX = test.submat(1, 0, test.n_rows - 1, test.n_cols - 1); const mat trainY = train.row(0) + 1; const mat validY = valid.row(0) + 1; const mat testY = test.row(0) + 1;We will use negative log-likelihood loss, and in the mlpack library, its labels start from 1 instead of 0, so we add 1 to the labels.
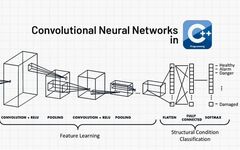
Now let’s look at the simple convolution architecture we will define.

FFN<NegativeLogLikelihood<>, RandomInitialization> model; model.Add<Convolution<>>(1, // Number of input activation maps. 6, // Number of output activation maps. 5, // Filter width. 5, // Filter height. 1, // Stride along width. 1, // Stride along height. 0, // Padding width. 0, // Padding height. 28, // Input width. 28 // Input height.); model.Add<ReLULayer<>>(); model.Add<MaxPooling<>>(2, // Width of field. 2, // Height of field. 2, // Stride along width. 2, // Stride along height. true); model.Add<Convolution<>>(6, // Number of input activation maps. 16, // Number of output activation maps. 5, // Filter width. 5, // Filter height. 1, // Stride along width. 1, // Stride along height. 0, // Padding width. 0, // Padding height. 12, // Input width. 12 // Input height.); model.Add<ReLULayer<>>(); model.Add<MaxPooling<>>(2, 2, 2, 2, true); model.Add<Linear<>>(16 * 4 * 4, 10); model.Add<LogSoftMax<>>();Other details are shown:
ens::Adam optimizer( STEP_SIZE, // Step size of the optimizer. BATCH_SIZE, // Batch size. Number of data points that are used in each iteration. 0.9, // Exponential decay rate for the first moment estimates. 0.999, // Exponential decay rate for the weighted infinity norm estimates. 1e-8, // Value used to initialize the mean squared gradient parameter. MAX_ITERATIONS, // Max number of iterations. 1e-8, // Tolerance. true); model.Train(trainX, trainY, optimizer, ens::PrintLoss(), ens::ProgressBar(), ens::EarlyStopAtMinLoss(EPOCH), ens::EarlyStopAtMinLoss( [&](const arma::mat& /* param */) { double validationLoss = model.Evaluate(validX, validY); std::cout << "Validation loss: " << validationLoss << "." << std::endl; return validationLoss; }));As you can see, early stopping is used on validation accuracy, which is why the MAX_ITERATIONS parameter is set to 0 to allow us to define infinite iterations.
mat predOut;model.Predict(trainX, predOut);arma::Row<size_t> predLabels = getLabels(predOut);double trainAccuracy = arma::accu(predLabels == trainY) / ( double )trainY.n_elem * 100;model.Predict(validX, predOut);predLabels = getLabels(predOut);double validAccuracy = arma::accu(predLabels == validY) / ( double )validY.n_elem * 100;std::cout << "Accuracy: train = " << trainAccuracy << "%," << " valid = " << validAccuracy << "%" << std::endl; mat testPredOut;model.Predict(testX,testPredOut);arma::Row<size_t> testPred = getLabels(testPredOut);double testAccuracy = arma::accu(testPredOut == testY) /( double )trainY.n_elem * 100;std::cout<<"Test Accuracy = "<< testAccuracy;Code link for this article: https://github.com/Aakash-kaushik
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will be gradually subdivided in the future). Please scan the WeChat ID below to join the group, note: “nickname + school/company + research direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format, otherwise, it will not be approved. After successful addition, you will be invited into relevant WeChat groups based on research direction. Please do not send advertisements in the group, otherwise you will be removed from the group, thank you for your understanding~

