

Zhou Bowen, Director and Chief Scientist of Shanghai Artificial Intelligence Laboratory, Tsinghua University Huaiyan Chair Professor, and Tenured Professor of the Department of Electronic Engineering, IEEE/CAAI Fellow, member of the National New Generation Artificial Intelligence Governance Professional Committee, and expert committee member of the New Generation Artificial Intelligence Development Research Center, Chief Scientist of the Science and Technology Innovation 2030-“New Generation Artificial Intelligence” Major Project. Previously served as the head of the Artificial Intelligence Research Institute at IBM Research, Chief Scientist of IBM Watson Group, and IBM Distinguished Engineer; Senior Vice President of JD Group, Chairman of the Group Technical Committee, and President of Cloud and AI.
Introduction
Since 2016, Professor Zhou Bowen and his team have been conducting in-depth research on the implementation path of AGI. In the face of the current technical bottlenecks of large language models regarding Scaling Laws and architecture, they not only proposed a complete path for AGI realization but also innovatively explored scenarios and methods to more efficiently unleash AGI’s potential from the perspective of application value. This article details this original path and its technical research, aiming to provide new in-depth perspectives and practical guidance for the future development of AGI.This content is organized from Professor Zhou Bowen’s invited report at the CNCC2024 conference.
Where do breakthroughs in artificial intelligence come from, and where will the future develop?
Leading scholars have continuously discussed the boundaries of large language models’ capabilities. For example, Turing Award winner Yann LeCun often mentions that machine learning currently has many shortcomings, focusing on how to achieve human-like intelligence. Meanwhile, David Silver, head of DeepMind’s reinforcement learning team, pointed out that to achieve Superhuman Intelligence and discover more new knowledge, large language models still have limitations and much work remains to be done. However, he emphasized implementing Superhuman Intelligence in specific professional fields rather than possessing stronger general capabilities.
Thus, at this point in time, discussing the implementation direction of AGI and its key issues is of great significance.
I first publicly shared my thoughts on the development path of AGI in 2016 when I was the head of the Artificial Intelligence Research Institute at IBM headquarters. At that year’s Town Hall Meeting, I proposed that the development of artificial intelligence would go through three stages: Narrow AI (ANI), Broad AI (ABI), and General AI (AGI).

Professor Zhou Bowen proposed in 2016 that the development of artificial intelligence would go through the three stages of ANI, ABI, and AGI.
At that time, my judgment was that supervised algorithms based on deep learning could only achieve Narrow AI, as their transfer and generalization capabilities between tasks were extremely limited and required a large amount of labeled data. On the other hand, the concept of AGI was still very vague in 2016, with only a few researchers worldwide discussing it. My personal definition of AGI at that time was smarter than humans, capable of independent learning, and requiring better governance and regulation—this was very clear. However, how to transition from Narrow AI to AGI, I judged that there was an inevitable intermediate stage, which I termed ABI, or Broad AI.
This should be the first time the concept of ABI was proposed, and I also defined three necessary elements: self-supervised learning capability, end-to-end capability, and the transition from discriminative to generative. Although Narrow AI made significant progress in 2016, I called on AI researchers to quickly shift from Narrow AI to explore Broad AI due to the predicted limitations of its capabilities.
Looking back at the emergence of ChatGPT at the end of 2022, it possesses all three elements, so we can say that pre-trained large models have effectively realized Broad AI. However, I did not anticipate its powerful emergence and zero-shot learning capabilities, although I had mentioned that ABI should have excellent few-shot learning abilities.
Cognition determines action, and action yields results. With the above judgments, my team shifted to Broad AI research in 2016, starting to think about how to improve model generalization. Subsequently, at the end of 2016, we proposed a prototype of a multi-head self-attention mechanism (A Structured Self-attentive Sentence Embedding, https://arxiv.org/abs/1703.03130), which was first applied in natural language representation pre-training unrelated to downstream tasks.
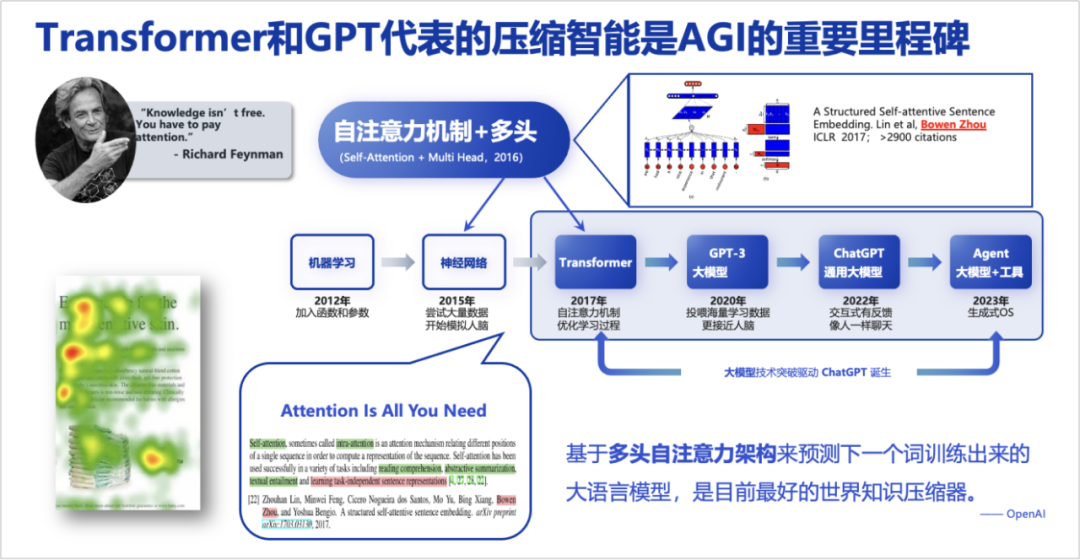
The Transformer improved the multi-head self-attention architecture, but its value amplification came from OpenAI’s judgment. OpenAI discovered and believed that large language models trained based on the multi-head self-attention architecture are currently the best world knowledge compressors. From the perspective of 2019-2022, this recognition was very cutting-edge and laid the foundation for achieving compressed intelligence. We can consider that the compressed intelligence represented by Transformer and GPT is an important milestone in AGI.
However, it is undoubtedly true that relying solely on compressed intelligence is far from achieving AGI. Google DeepMind’s paper published in 2023 (Levels of AGI: Operationalizing Progress on the Path to AGI. 2023) classified AGI into levels. On the one hand, it borrowed the concept we proposed comparing Narrow AI to General AI, while on the other hand, it classified artificial intelligence into six levels, from lacking AI capabilities—pure programming—to Superhuman Level.
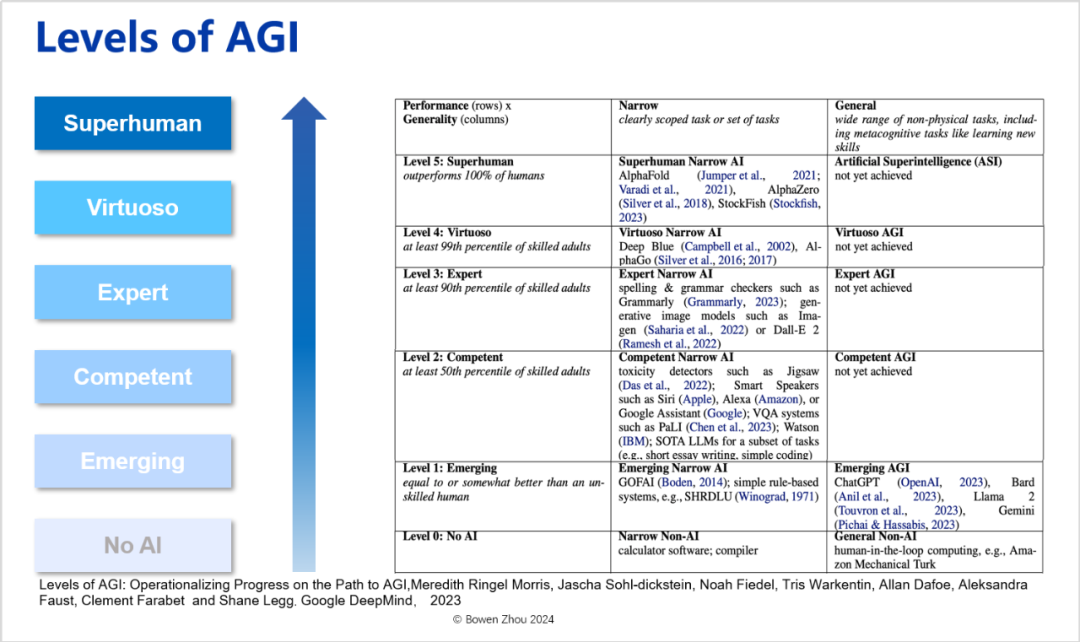
Google DeepMind divides AGI into six levels.
It can be seen that while ChatGPT has good generalization, its intelligence level only belongs to the first level Emerging Level, and it has not yet reached the second level Competent Level—the latter’s definition is exceeding 50% of humans. The next level is Expert, which means exceeding 90% of humans; Virtuoso means exceeding 99% of humans; and the so-called Superhuman refers to surpassing all humans in that field—just like the latest version of AlphaFold, where humans can no longer defeat AI in the field of protein folding.
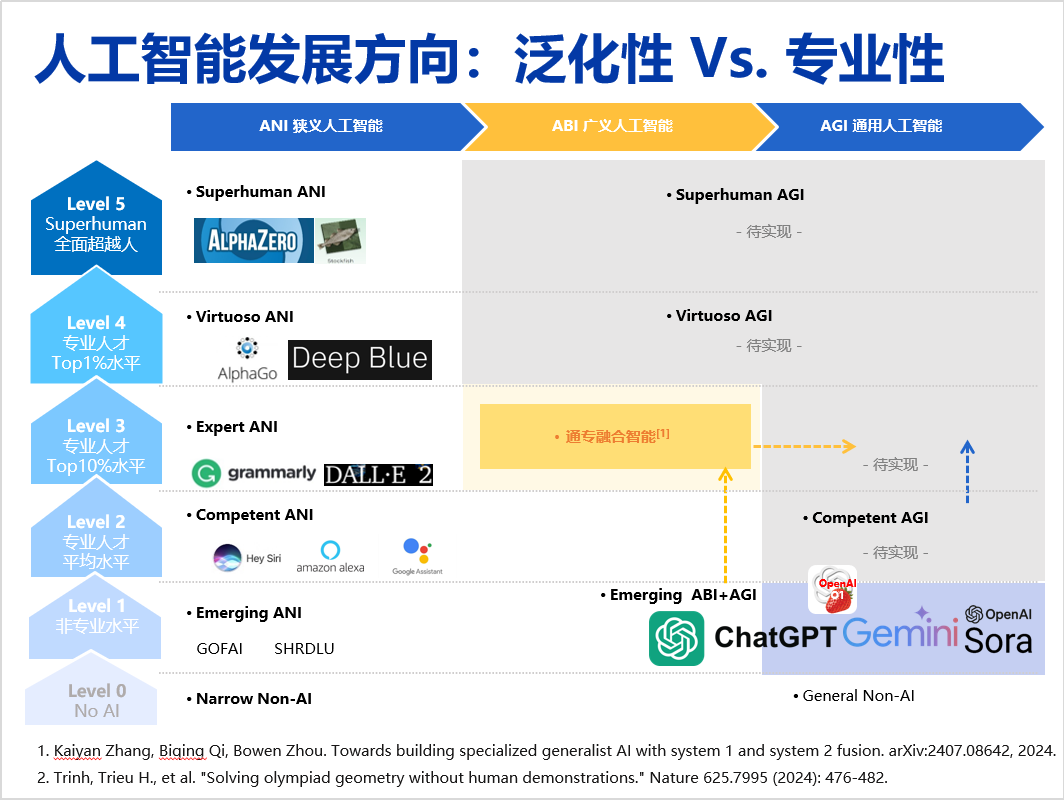
However, specialized AI like AlphaFold often has limited generalization. If we consider generalization and specialization together, we can form a two-dimensional conceptual framework. We note that ChatGPT and Sora have made significant progress in generalization, but their specialization only reaches about 15%-20% of human levels. Even with the application of Scaling Laws to increase model parameters, the improvement in specialization is not significant, while costs rise significantly. Insufficient specialization not only limits innovation but also leads to numerous factual errors.
Reflecting on the development of artificial intelligence over the past seventy years, I believe the path to achieving General Artificial Intelligence can be viewed as a two-dimensional roadmap: the horizontal axis represents specialization, from IBM’s Deep Blue to DeepMind’s AlphaGo, significant progress has been made in the horizontal direction (specialization); however, the generalization of these works has always been relatively weak, limiting the further popularization of AI technology.
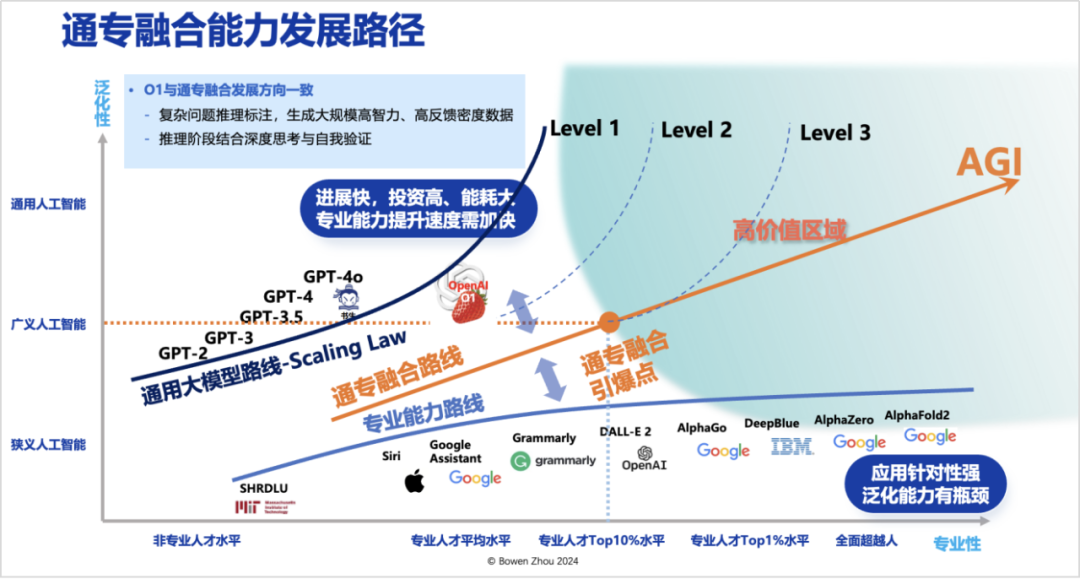
From the multi-head self-attention in 2016 to the emergence of Transformers and ChatGPT, compressed intelligence represents a surge in generalization. However, it can be seen that its level of progress in specialization is extremely slow, and Scaling Laws are clearly insufficient to extend its specialization, with capabilities long stagnating on the left side of level 1.
How should artificial intelligence develop in the future to drive greater value creation? Since the end of 2022, I have mentioned on multiple occasions that there exists a high-value area, where the horizontal axis should reach or exceed the level of over 90% of professionals. At the same time, it must have the generalization capability to achieve above Broad AI levels, enabling low-cost transfer across different tasks. This area is the “high-value area” in the AGI roadmap.
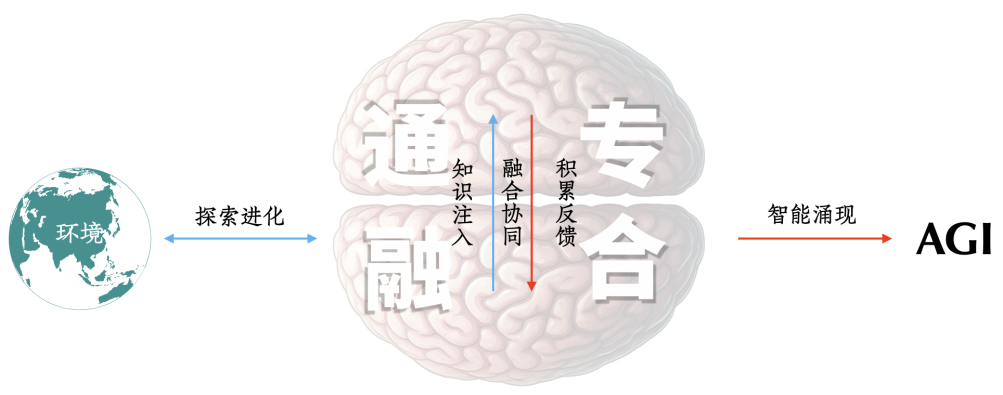
The point on this roadmap closest to the starting point, I call the Integration of General and Specialized Approaches Inflection Point. Is there a route from current technologies that can more quickly approach the Integration of General and Specialized Approaches Inflection Point? I believe such a route exists and I call it the Integration of General and Specialized Approaches Technical Route.
While we have seen that OpenAI has continuously pushed for generalization based on Scaling Laws, this year it has also begun iterating towards specialization. After GPT-4o, OpenAI has invested significant effort into the “Strawberry” system research, beginning to develop along a direction similar to the Integration of General and Specialized Approaches.
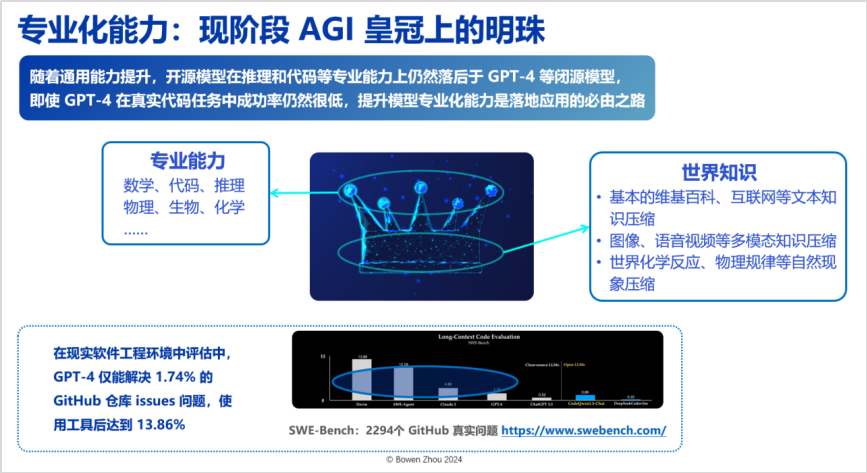
Returning to the goal of the Integration of General and Specialized Approaches: on the one hand, with the acceleration of the synthetic data flywheel effect, the difficulty of acquiring general capabilities for foundational models has significantly decreased over the past year; on the other hand, in terms of the compression capability of world knowledge, the performance of open-source models has come infinitely close to that of closed-source models. However, whether open-source or closed-source models, there are still significant bottlenecks in specialization capability. For example, in actual software engineering environments, GPT-4 can only solve 1.74% of human-posed questions on GitHub. Even with the introduction of numerous tools and the combination of foundational models with tool-based agents, this proportion only increases to 13.85%.
It can be seen that the current development path for compressing world knowledge is naturally evolving, but we believe that the specialization capabilities above this are the crown jewel of AGI at this stage.
Implementation Path for the Integration of General and Specialized Approaches AGI
The Integration of General and Specialized Approaches we propose requires not only the simultaneous possession of specialization and generalization capabilities but also the resolution of task sustainability issues to enable artificial intelligence to develop efficiently and sustainably. These form the three vertices of the technical challenges of the Integration of General and Specialized Approaches.
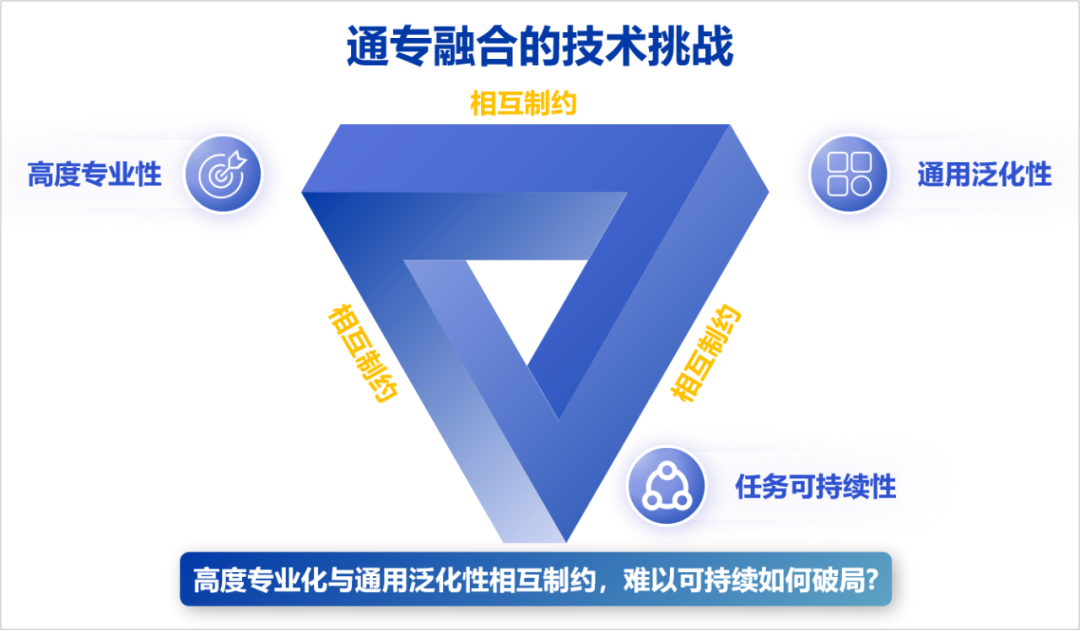
“Integration of General and Specialized Approaches” must achieve “generalization capability,” “high specialization,” and “task sustainability” simultaneously.
Since the beginning of 2023, we have proposed a specific path for the Integration of General and Specialized Approaches (Towards Building Specialized Generalist AI with System 1 and System 2 Fusion, https://arxiv.org/abs/2407.08642), which requires three interdependent levels rather than relying solely on a single model or algorithm. For each level, we have overall planning and specific technical progress, but due to time constraints, I cannot elaborate on each one. Below, I briefly describe the core ideas of each level to complete the disassembly of the technical system for the Integration of General and Specialized Approaches.
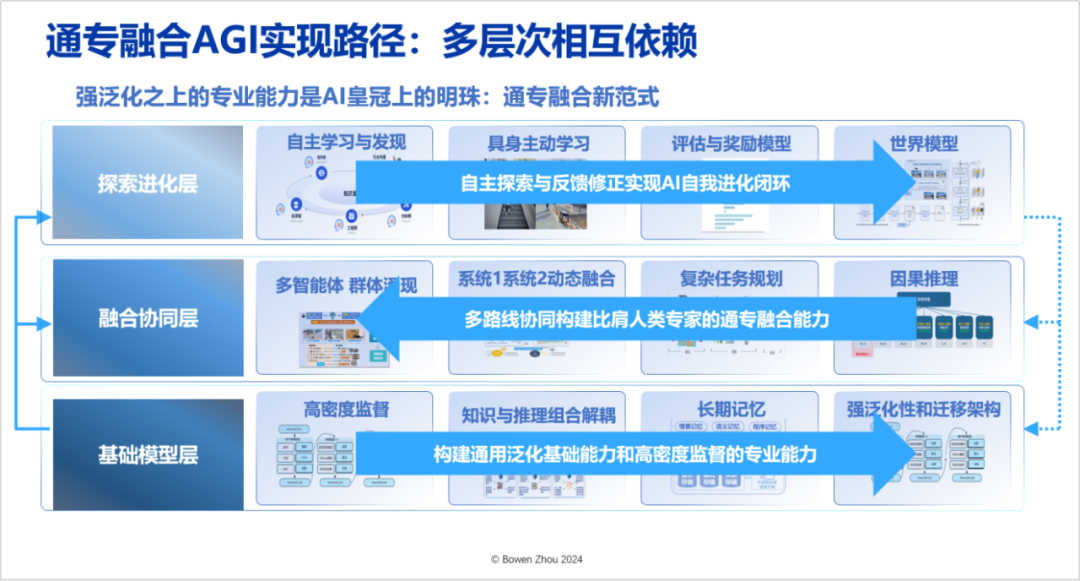
The first layer of the path is the “Foundational Model Layer,” which requires extensive work to change existing architectures. Among these, the most important is how to effectively decouple and combine knowledge and reasoning, while achieving high intelligence density supervision signals, and implementing long-term memory in architecture—currently, Transformers struggle to achieve long-term memory. By changing existing architectures, AI can gain powerful generalization and transfer capabilities.
On top of the foundational model’s capabilities, with general architectures and learning abilities, efficient learning methods are also needed to better realize the Integration of General and Specialized Approaches, leading us to the second layer, the “Fusion and Collaboration Layer.” Since 2017, we have proposed “System 1” and “System 2,” that is, the dynamic fusion of “fast thinking” and “slow thinking” to solve more problems.
The dynamic fusion of these two thinking modes is closest to the way the human brain thinks and is the best method in terms of energy consumption and generalization. This can further extend to multi-agent collaboration, which is not just a single System 1 or System 2; the collaboration of multiple agents produces intelligent emergence at the group level, requiring the ability to plan complex tasks. In the Fusion and Collaboration Layer, we need to move away from current inference based on statistical correlation to causal inference, which is an effective way to avoid the bottlenecks of large model capabilities.
We have recognized that “compressed intelligence” does not represent all intelligence. Just as humans cannot learn to swim by merely reading books and watching videos, to gain intelligence about swimming, one must interact with the physical world, allowing feedback from the physical world to influence muscle memory until it reaches the cerebral cortex. This feedback-driven autonomous learning and discovery is what we refer to as the third layer, the “Exploration and Evolution Layer.” The key here is to efficiently acquire feedback and rewards, that is, to obtain sustainable, high-confidence feedback signals from the real environment. At the same time, we also need cross-media interactive world models to model the physical environment.
Key Technologies for the Integration of General and Specialized Approaches
1. Foundational Model Layer
High-density supervision signals are key to injecting specialized knowledge. In the Foundational Model Layer, high-intelligence density supervision signals must be efficiently introduced. In a compressed intelligence learning approach, it is easy to mistakenly believe that simply providing the next word as supervision enables the model to learn efficiently. However, this learning approach often only teaches the model a “shortcut,” where it knows how to find the best answer but lacks systematic thinking about “why this is the best answer.”
For this reason, during the direct preference optimization phase, we proposed a tree-like preference data construction method with observation, critique, and modification loops. At each reasoning stage, multiple choices are provided to the model with priorities, enabling the model to learn more alternative comparisons through higher-density supervision during the reasoning process (Advancing LLM Reasoning Generalists with Preference Trees, https://arxiv.org/abs/2404.02078). This method was announced before OpenAI’s o1 launch, and detailed research will reveal that it employs a similar high-intelligence density supervision reasoning process. This is key to injecting specialized knowledge into the model.
What is “specialized” and “non-specialized”? The former means always being able to identify the best answer among multiple choices; while the latter can only make a “best guess,” often confused by other options. (Editor’s note: On November 25, the author’s team launched a model called InternThinker, capable of autonomously generating high-intelligence density data and possessing meta-action thinking abilities, enabling it to self-reflect and correct during reasoning processes, achieving better results in mathematics, coding, and various complex reasoning tasks.)
In addition to the current mainstream structures, efficient knowledge reasoning architectures that can be combined and separated are more conducive to building trustworthy, generalizable, and scalable large models. The Brodmann area is a recognized partition architecture in neuroscience where different regions of the brain serve different specialized functions. The architecture we seek should possess three properties: reliable application of knowledge, generalizable reasoning processes, and extensible knowledge content, while being able to combine effectively. One advantage of the Transformer is its ability to achieve a high degree of fusion of reasoning and knowledge, possessing significant potential for enhancement. However, the downside is that once knowledge and reasoning are highly integrated, it becomes difficult to trace back when the model generates hallucinations. Therefore, finding a new architecture is extremely important.
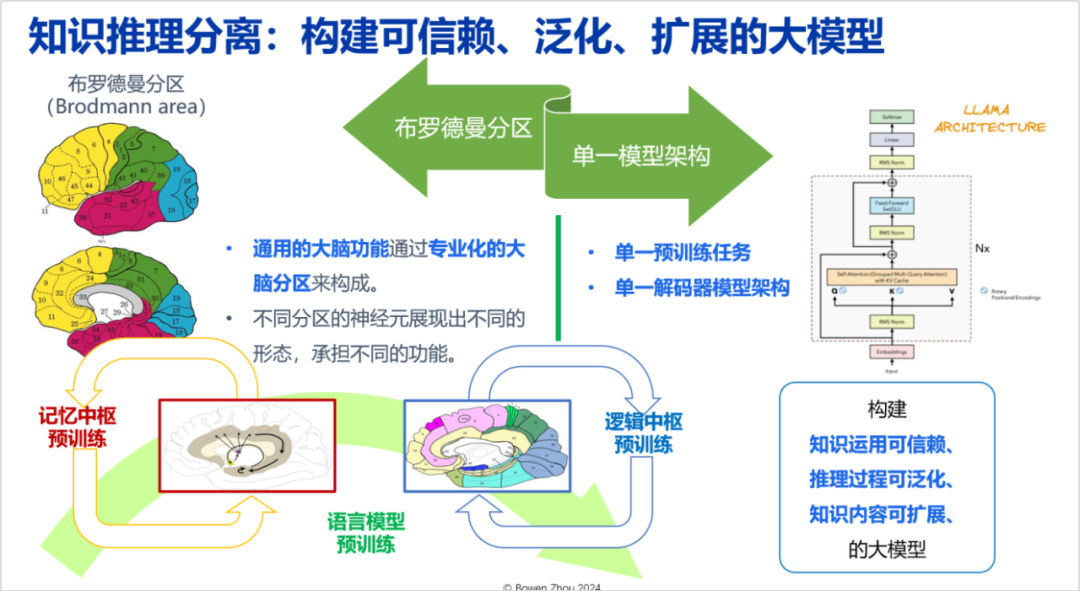
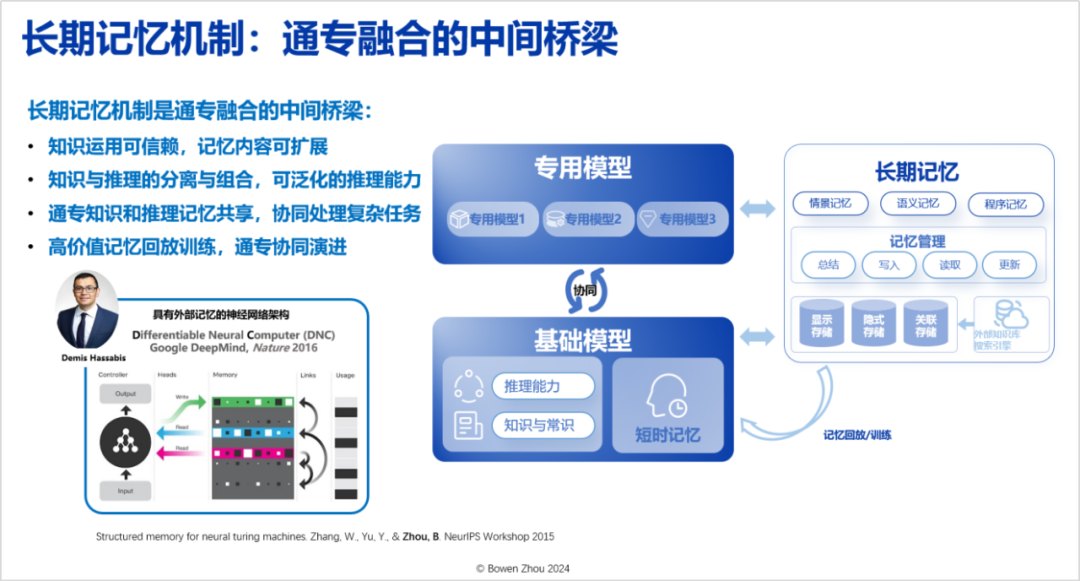
The long-term memory mechanism is the intermediate bridge for the Integration of General and Specialized Approaches, which needs to build a compatible bridge between general and specialized capabilities. Currently, this long-term memory mechanism does not perform sufficiently in Transformer architectures; we have a series of works in this area (such as my 2015 research https://arxiv.org/abs/1510.03931, and recent work https://arxiv.org/html/2408.01970).
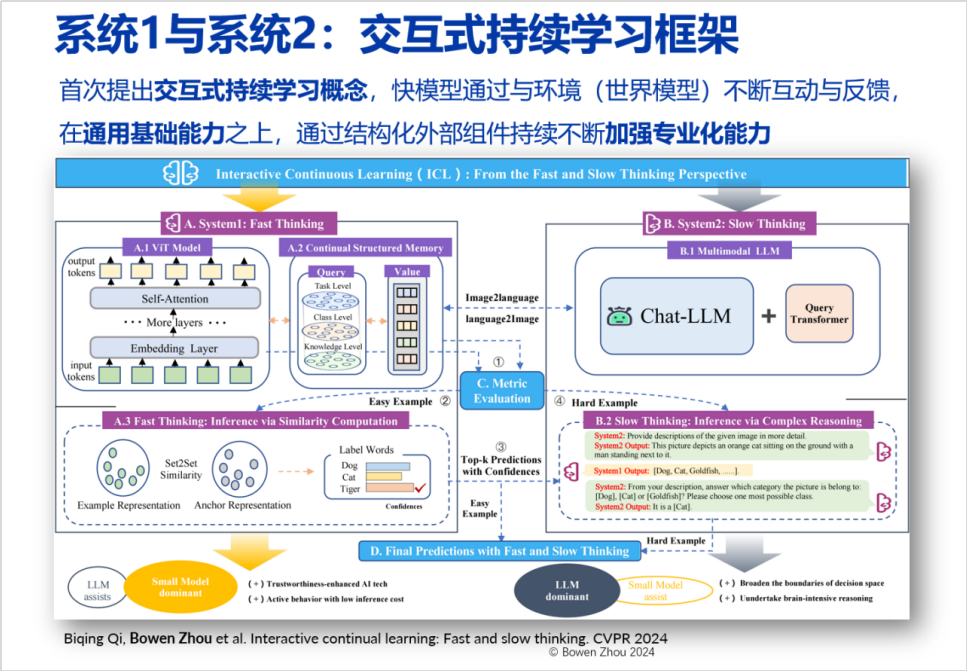
2. Fusion and Collaboration Layer
The second layer of the Integration of General and Specialized Approaches path is the Fusion and Collaboration Layer, which emphasizes the combination of rapid processing and deep reasoning. In a paper accepted at CVPR 2024, we explored this field (Interactive continual learning: Fast and slow thinking). We constructed a fast system for efficiently recognizing images, which, when encountering uncertain situations, would pass information to a more powerful slow system. The slow system conducts deep analysis based on the input information and feeds the results back to the fast system, completing an update of structured long-term storage within the fast system. This combination not only reduces energy consumption but also enhances processing speed and accuracy.
This combination outperforms the use of slow systems alone in terms of processing speed and energy consumption. Many problems can be answered by the fast system independently, without invoking the slow system. Furthermore, we found that the accuracy of this combination is higher than that of using either the fast system or slow system alone, which is quite enlightening. Its potential lies in the fact that the fast system lacks deep thinking and is prone to errors; while the slow system does not judge specific situations as well as the fast system, often lacking in many details. Through the input from the fast system, the slow system can eliminate impossible situations and make better judgments.
The fast system is like a frontline scout providing specific input information; the slow system is akin to a rear commander with better depth of thought and judgment capabilities. The combination of the two can make more accurate and efficient decisions. This combination is not merely a simple addition but a profound interaction and understanding. The fast system learns from the outputs of the slow system and forms long-term memory; the slow system gains specialized judgments and context from the inputs of the fast system.
The above system is not only applicable to image recognition; we have also attempted to apply it to natural language generation, allowing such an Integration of General and Specialized Approaches architecture to generate highly specialized descriptive texts, such as treatment methods for certain diseases or specific marketing strategies for products. In a recent work, the specialized model handled most tasks, with 80% of tasks completed independently by the specialized model, while 20% of slow reasoning significantly enhanced the generalization of the specialized model (CoGenesis: A Framework Collaborating Large and Small Language Models for Secure Context-Aware Instruction Following. 2024).
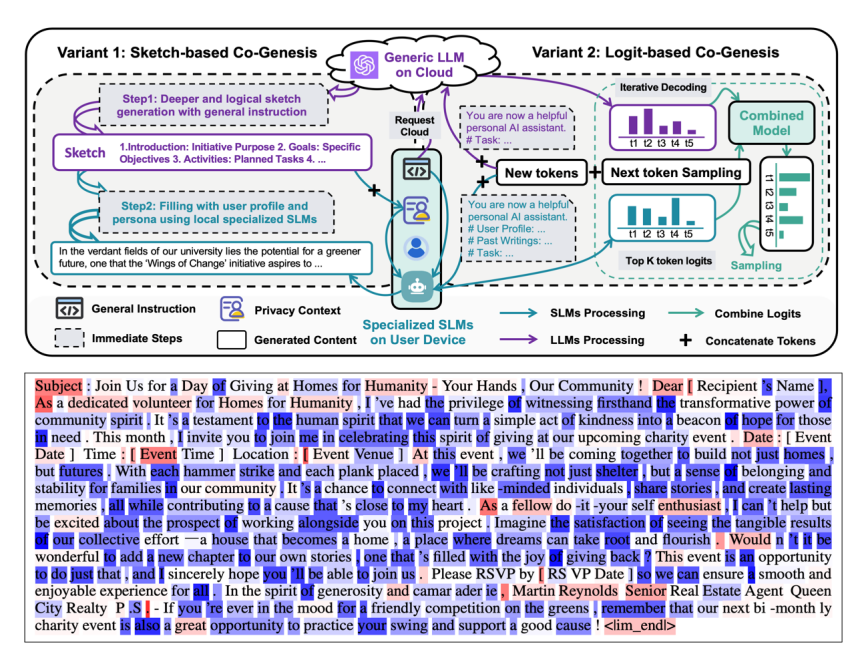
For the task of generating specialized personalized content, the general large model contributes to only about 20% of the content (outline content/reasoning ability, red token), while the remaining 80% is primarily generated by specialized small models (blue token).
3. Exploration and Evolution Layer
As mentioned earlier, humans must interact with the real physical world to learn to swim, and the same goes for AI. In this layer, we attempt to achieve long-term real-time interaction between models and environments, engaging in embodied autonomous exploration and world model construction. For instance, the Shanghai Artificial Intelligence Laboratory proposed an open-source and general automatic driving video prediction model GenAD, similar to SORA in the autonomous driving field, capable of generating high-quality, continuous, diverse future world predictions that comply with the laws of the physical world based on a single photo input, and can generalize to any driving scenario controlled by various driving behaviors.
In the exploration of interaction with the physical world, on one hand, we delve into the physical world, while on the other hand, we further enhance efficiency through simulation in the virtual world. For instance, in embodied intelligent training, we achieved a simulation training efficiency of one hour on a single card, equivalent to training for 380 days in the real physical world. These results have been opened via the first urban-level embodied intelligent simulation training ground, Pu Yuan · Tao Yuan, and everyone is welcome to train their exclusive embodied intelligence on this platform.
(https://github.com/OpenRobotLab/GRUtopia).
Integration of General and Specialized Approaches in Practice: Scientific Discovery
On January 5, 2023, the cover article in Nature titled “Papers and patents are becoming less disruptive over time” mentioned that over the past 70 years, the number of papers and patents has increased, but the influence of individual papers has declined year by year, a phenomenon not only observed in the computer field but also in biology, physics, chemistry, and other fields.
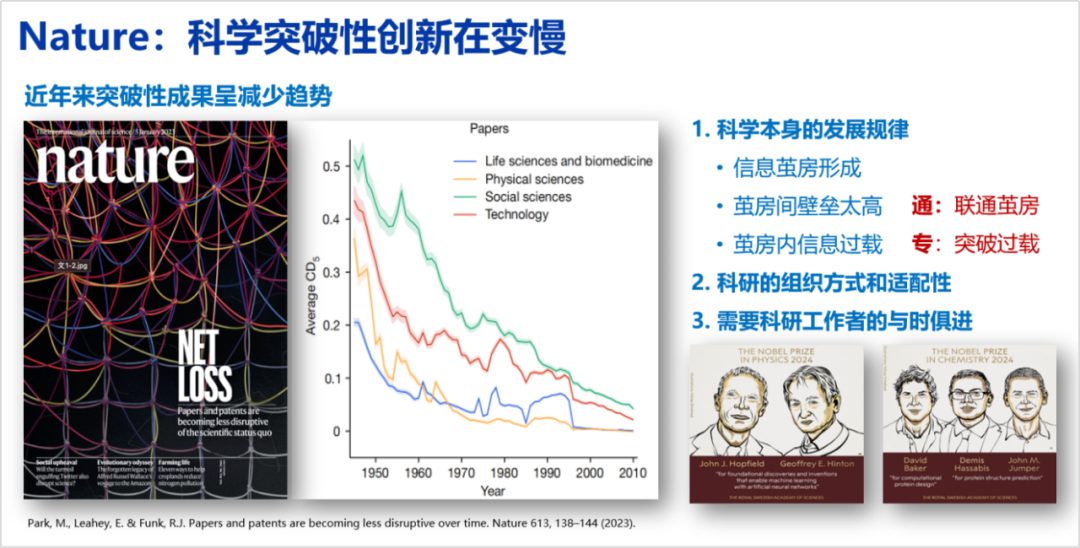
This paper only conducted data analysis without tracing the reasons. My personal thought on this phenomenon is that it is closely related to the laws of scientific development. After over 100 years of construction, science has built a nearly perfect edifice, and within this edifice, each discipline has formed a very powerful information cocoon, with high barriers between cocoons and information overload within, making it difficult for papers to have a broader impact compared to before.
Addressing this issue requires appropriate adjustments to the organization and adaptability of scientific research. At the same time, researchers must keep pace with the times and make good use of new AI tools.
Is it possible for artificial intelligence to help scientists achieve more breakthroughs at a technical level? For example, the general capabilities of AI can help humans solve the problem of excessively high information barriers—because human information capacity has a ceiling. The issue of information overload in cocoons can be broken through through deep thinking by AI systems. Therefore, the Integration of General and Specialized Approaches is the capability necessary to solve scientific innovation and create the next generation of scientific innovation paradigms.
Regarding the use of large models for scientific innovation, there are currently many issues, such as uncertainty and hallucinations. However, former OpenAI co-founder Andrej Karpathy believes that this uncertainty and hallucination can be seen as a characteristic rather than a defect of large models; this hallucination is related to creativity, and the model’s hallucination can be compared to human dreaming.
In the history of science, German organic chemist August Kekulé dreamed of the ouroboros and subsequently discovered the structure of the benzene ring. This discovery process, in some sense, bears a strong resemblance to the hallucinations of large models; the key lies in how to leverage the creativity of hallucinations and utilize this characteristic of large models to generate value.
Based on these ideas, we have carried out a series of works, such as considering large language models as very effective zero-shot proposers of scientific hypotheses. Zero-shot refers to the ability of large models to propose entirely new, original scientific hypotheses. These may not necessarily be as epoch-making as Newton’s three laws of motion, but the models can indeed propose phenomena that scientists have not discovered or observed (such as our 2023 work Large language models are zero shot hypothesis proposers and recent work UltraMedical: Building Specialized Generalists in Biomedicine). For example, our fully automated proteomics knowledge discovery system Proteus has independently discovered 191 scientifically valid, logical, and innovative hypotheses evaluated by experts, based on real proteomics data (https://arxiv.org/abs/2411.03743).
In related work, we verified that large models capable of the Integration of General and Specialized Approaches can propose effective scientific hypotheses. If we extend the Integration of General and Specialized Approaches further to multi-agents, we find that systems with the Integration of General and Specialized Approaches can play different roles throughout the entire lifecycle of scientific research and can collaborate with human scientists.
We further proposed the concept framework of “human-in-the-loop large model multi-agent collaboration with tools” to mimic the human research process. By constructing various roles, such as AI analysts, engineers, scientists, and critics, while integrating tool invocation capabilities to collaboratively propose new hypotheses and further incorporating human experts, we can leverage “human-in-the-loop” to explore the potential of human-machine collaboration. Experimental results show that this framework can significantly enhance the novelty and relevance of hypothesis discovery across multiple dimensions (Large Language Models are Zero Shot Hypothesis Proposers. NeurIPS 2023, https://arxiv.org/abs/2311.05965).
As early as 1900, German mathematician David Hilbert proposed the famous “23 problems,” leading the development of multiple subfields of mathematics for hundreds of years. Whether it was Hilbert or Einstein, they both mentioned that posing scientific questions is far more important than solving them. We hope that AI systems with the Integration of General and Specialized Approaches can help various fields produce more Hilberts.
Outlook: The Central Law of AGI?
In molecular biology, there is a concept known as the “central dogma,” first proposed by Nobel laureate Francis Crick in 1958, which clarifies the process of genetic information transfer from DNA to RNA and then from RNA to protein. This law not only profoundly reveals the essence of life phenomena but also provides directional guidance for subsequent biotechnological development. With the deepening of scientific research, the central dogma has undergone multiple revisions and improvements, gradually becoming one of the core theories of molecular biology.
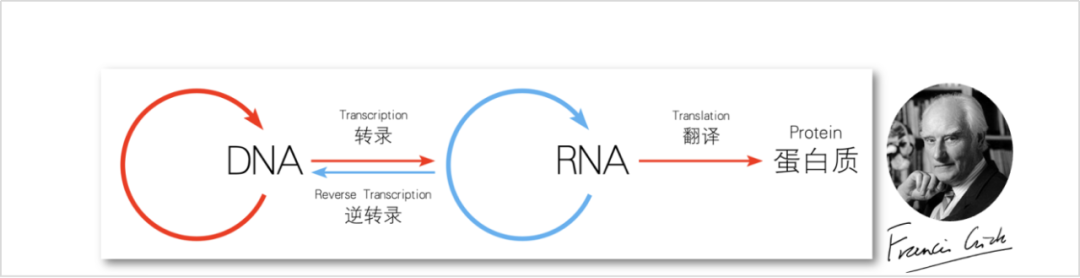
This law impressed me deeply. It insightfully reveals and influences various aspects of the biological field. This further triggered my association: regarding how AGI is achieved, a complete path guiding practice has yet to be formed. Can we find an AGI “central dogma”?
The path of “Integration of General and Specialized Approaches” proposed in my report is an exploration of this question. Just as the central dogma in biology has been iteratively updated through decades of research, with many outstanding scientists contributing, AGI may also require such co-creation from the artificial intelligence research and other interdisciplinary communities. I hope the ideas and related works introduced in this article can inspire readers.
※ Thanks to Professors Yao Qizhi, Chen Chun, E Wei Nan, Gao Wen, and Zhang Yaqin for reviewing and providing suggestions on the initial draft of this article.



Click “Read the Original” to join CCF.