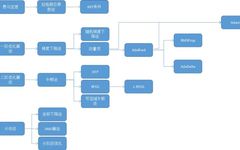
Introduction
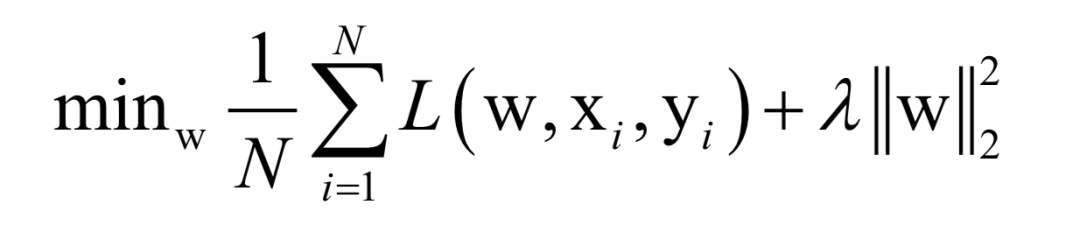
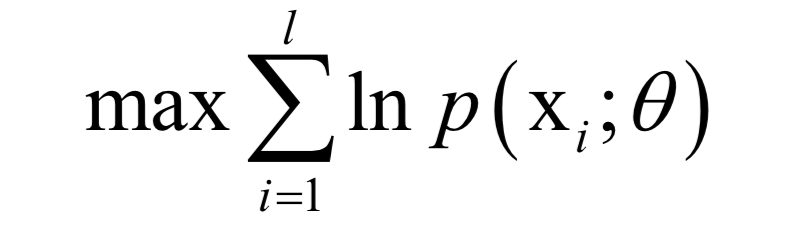
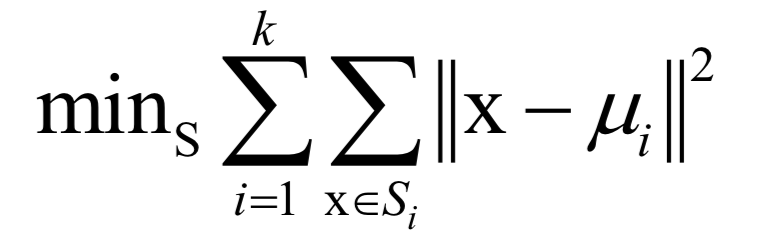
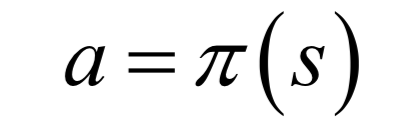
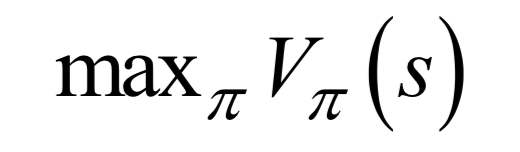
-
Analytical Solution
-
Numerical Optimization
-
Can correctly find extreme points in various situations
-
Fast speed
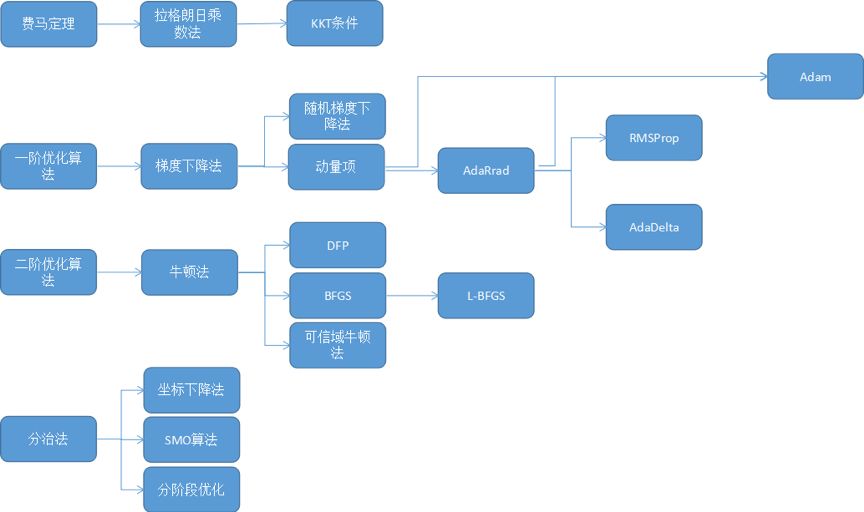
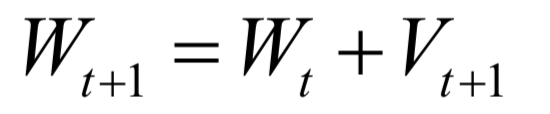
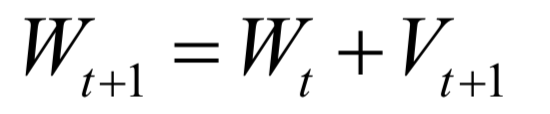
-
If f”(x) > 0, then it is a minimum at that point
-
If f”(x) < 0, then it is a maximum at that point
-
If f”(x) >= 0, further higher-order derivatives need to be checked
-
If the Hessian matrix is positive definite, the function has a minimum at that point
-
If the Hessian matrix is negative definite, the function has a maximum at that point
-
If the Hessian matrix is indefinite, further checks are needed (this part is incorrect)
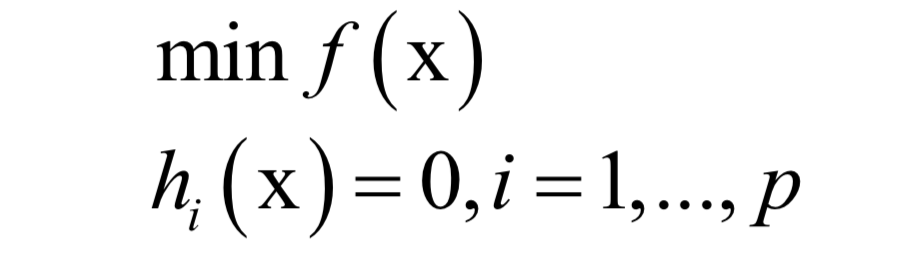
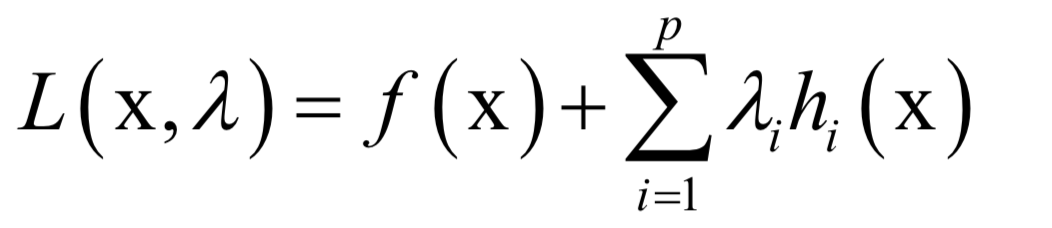

-
Principal Component Analysis
-
Linear Discriminant Analysis
-
Laplacian Eigenmaps in Manifold Learning
-
Hidden Markov Model
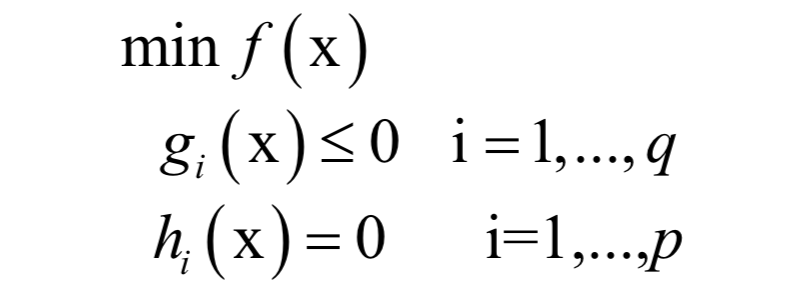
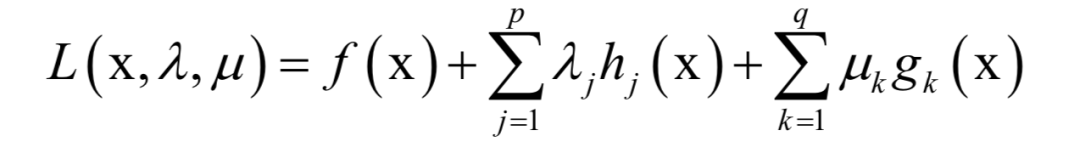
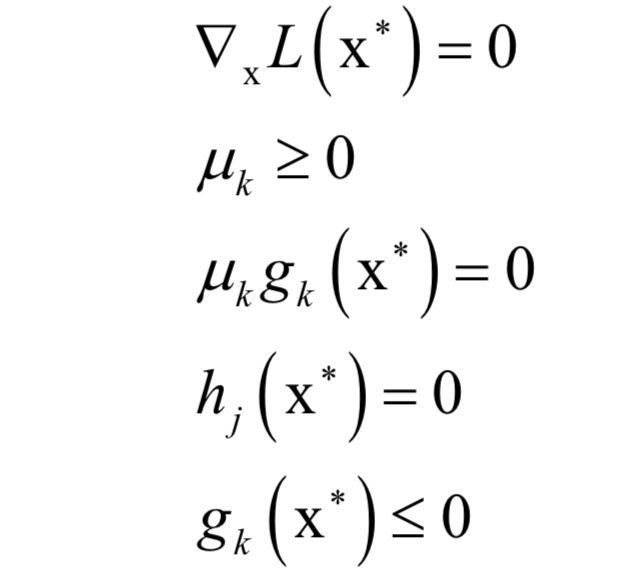
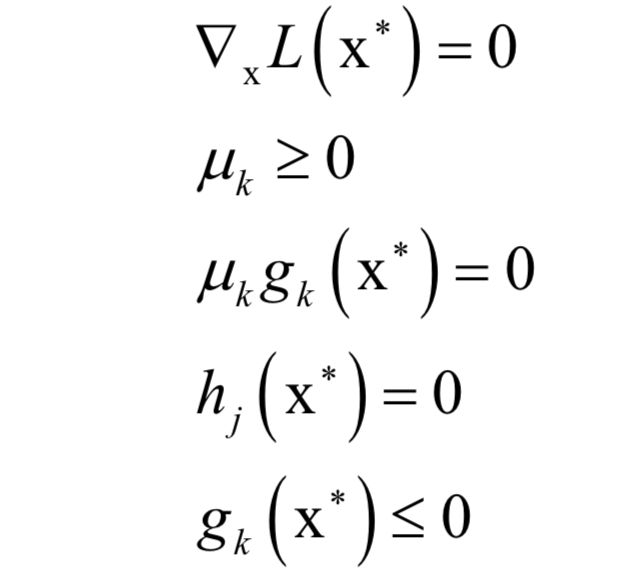
-
Support Vector Machine (SVM)
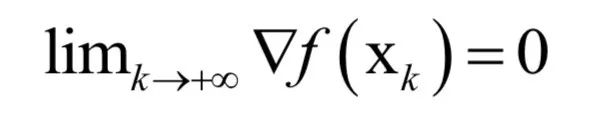
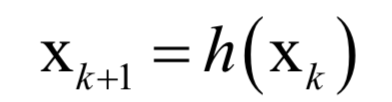
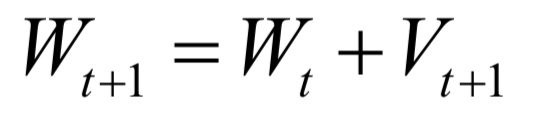
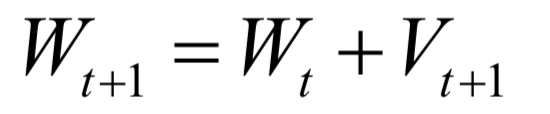
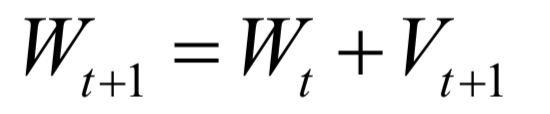
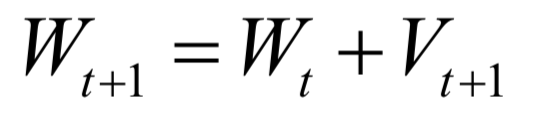
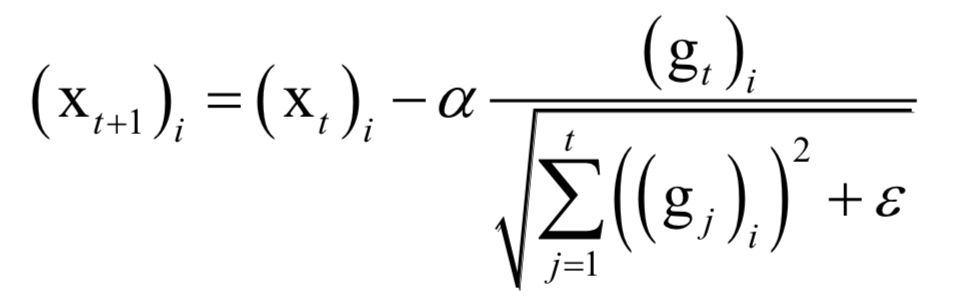
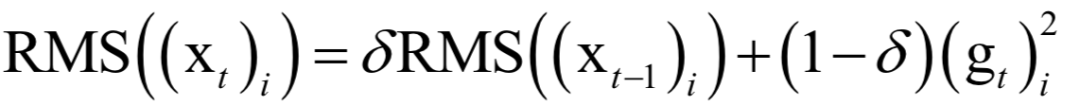
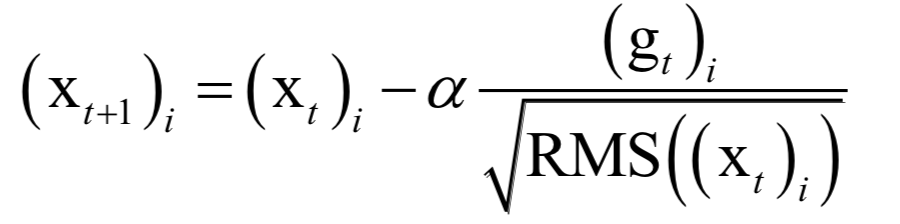
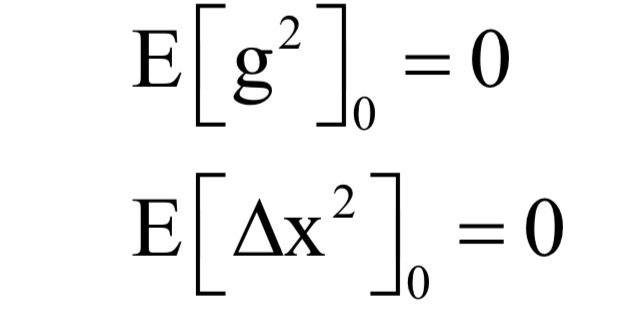
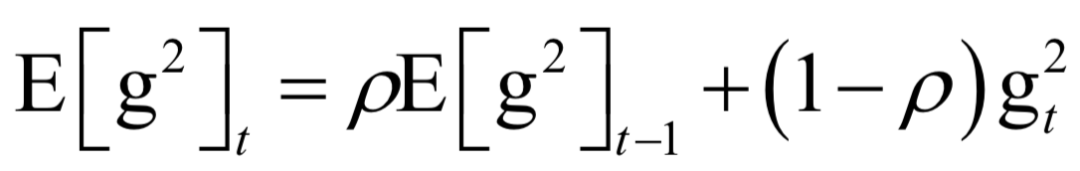
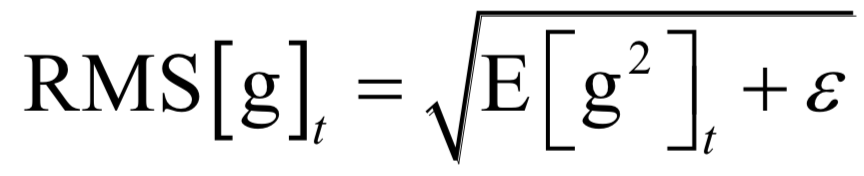
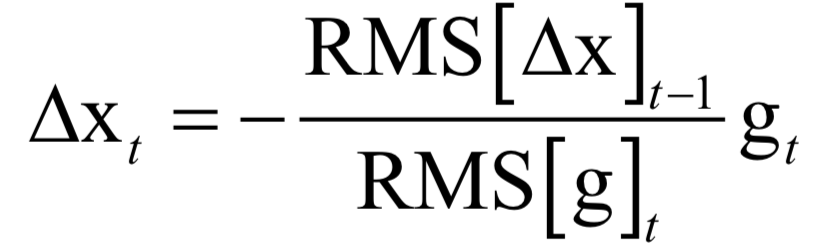
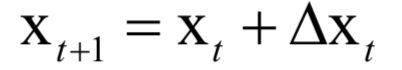
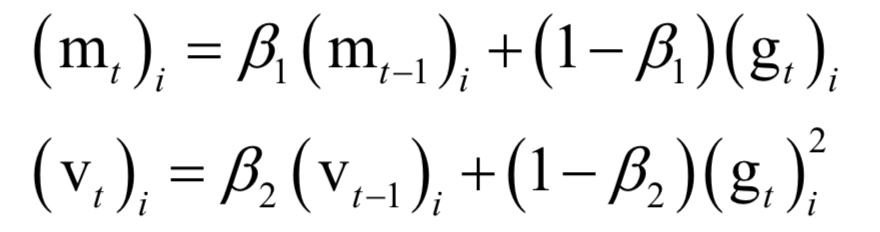
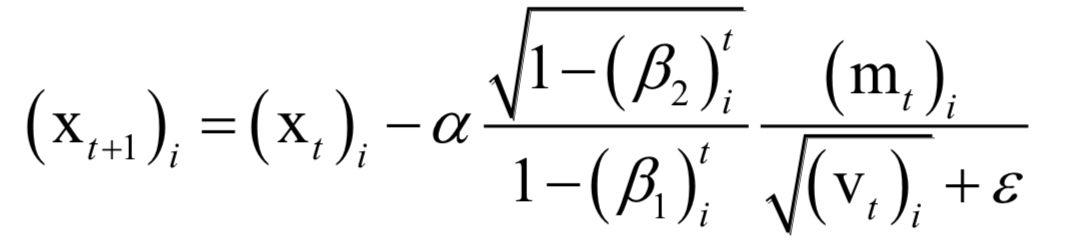
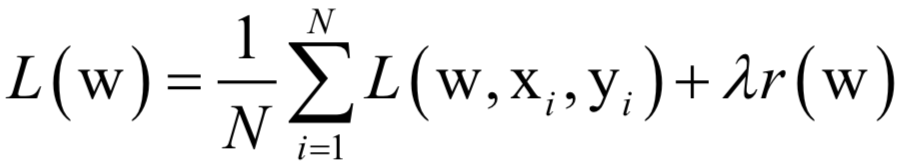
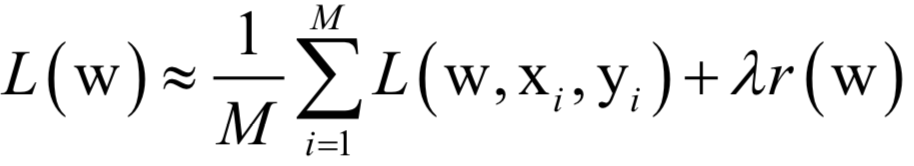
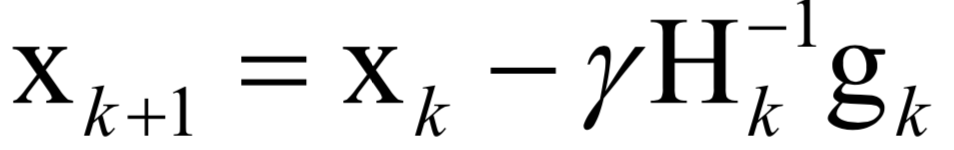
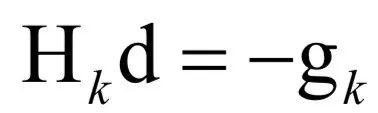
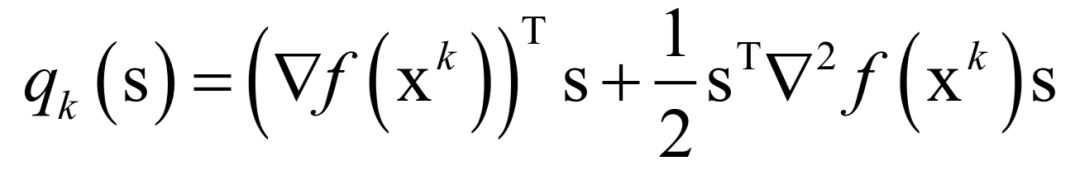
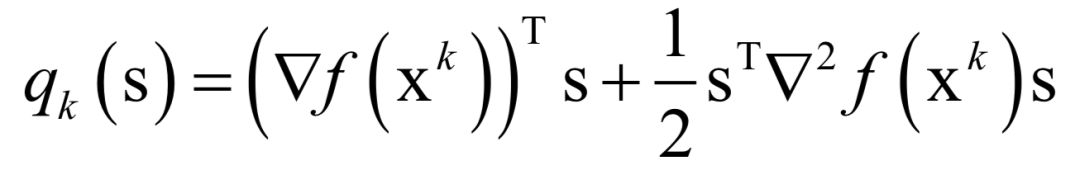
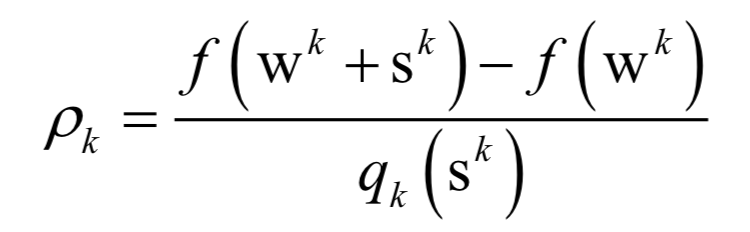
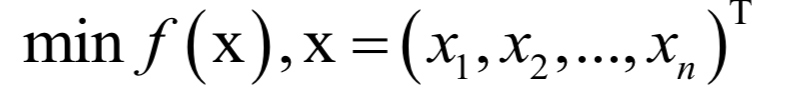
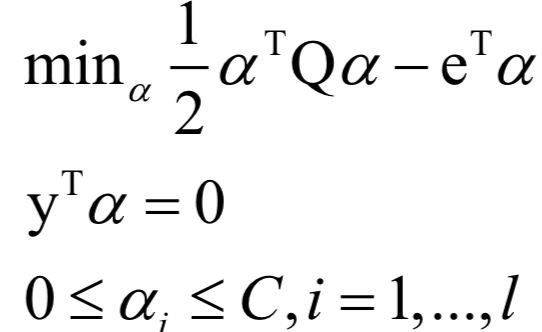
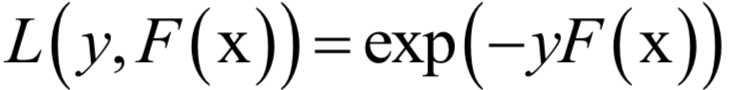
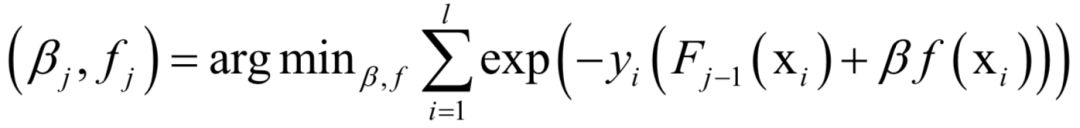
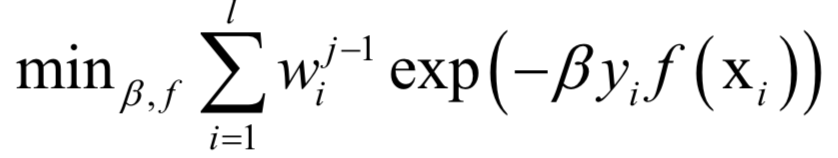
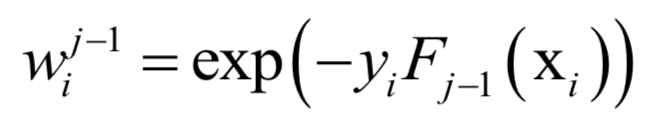
The decoding algorithm of the hidden Markov model (Viterbi algorithm) and the dynamic programming algorithm in reinforcement learning are typical representatives of this method; such algorithms generally optimize discrete variables and are combinatorial optimization problems. The previously discussed derivative-based optimization algorithms cannot be used. Dynamic programming algorithms can efficiently solve such problems, based on Bellman’s optimality principle. Once written in the form of a recursive optimization equation, an algorithm can be constructed for solving.
