Selected from GitHub
Author:Sepehr Sameni
Compiled by Machine Heart
Contributors: Lu
Word and sentence embeddings have become essential components of any deep learning-based natural language processing system. They encode words and sentences into dense fixed-length vectors, significantly enhancing the ability of neural networks to process textual data. Recently, Separius listed a series of recent papers and articles on NLP pre-trained models on GitHub, striving to provide a comprehensive overview of the latest research achievements in various aspects of NLP, including word embeddings, pooling methods, encoders, and OOV handling.
GitHub link: https://github.com/Separius/awesome-sentence-embedding
General Framework
Almost all sentence embedding works operate like this: given a certain word embedding and an optional encoder (e.g., LSTM), sentence embeddings obtain contextualized word embeddings and define some pooling (such as simple last pooling), and then based on this, choose to directly use the pooling method to perform supervised classification tasks (like infersent) or generate target sequences (like skip-thought). This way, we often have many sentence embeddings you have never heard of; you can average pool any word embedding, and that is sentence embedding!
Word Embeddings
In this section, Separius introduced 19 related papers, including pre-trained models like GloVe, word2vec, fastText:

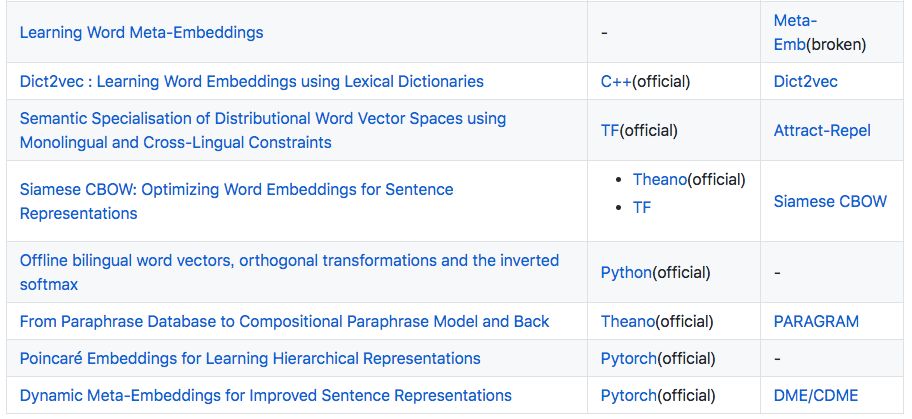
OOV Handling
-
A La Carte Embedding: Cheap but Effective Induction of Semantic Feature Vectors: Constructs OOV representations based on GloVe-like embeddings, relying on pre-trained word vectors and linear transformations that can be efficiently learned using linear regression.
-
Mimicking Word Embeddings using Subword RNNs: Generates OOV word embeddings synthetically by learning a function from spelling to distributed embeddings.
Contextualized Word Embeddings
This section introduces 5 papers on contextualized word embeddings, including the recently popular BERT.
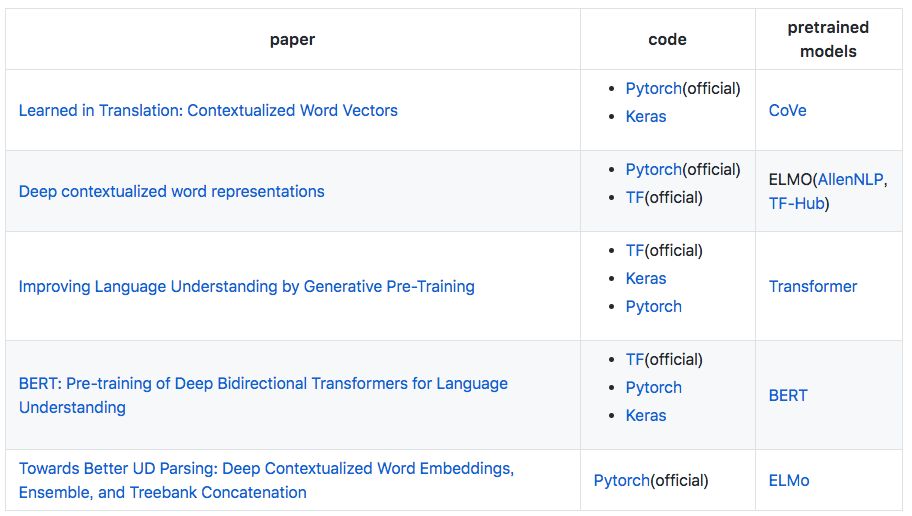
Machine Heart has introduced four of these five papers, see:
-
Deep | Training Universal Contextual Word Vectors through NMT: Are pre-trained models in NLP?
-
NAACL 2018 | Best Paper: A new type of deep contextualized word representation proposed by the Allen Institute for AI
-
Using Transformers and Unsupervised Learning, OpenAI proposes a universal model that can be transferred to various NLP tasks
-
The strongest NLP pre-trained model! Google BERT sweeps 11 NLP task records
Pooling Methods
-
{Last, Mean, Max}-Pooling
-
Special Token Pooling (e.g., BERT and OpenAI’s Transformer)
-
A Simple but Tough-to-Beat Baseline for Sentence Embeddings: Selects a commonly used word embedding computation method on unsupervised corpora, using a weighted average of word vectors to represent sentences, and modifies it using PCA/SVD. This general method has deeper and more powerful theoretical motivation, relying on a generative model that uses random walks on a discourse vector to generate text.
-
Unsupervised Sentence Representations as Word Information Series: Revisiting TF–IDF: Proposes an unsupervised method that models sentences as weighted sequences of word embeddings, learning unsupervised sentence representations from unannotated text.
-
Concatenated Power Mean Word Embeddings as Universal Cross-Lingual Sentence Representations: Generalizes the concept of average word embeddings to power mean word embeddings.
-
A Compressed Sensing View of Unsupervised Text Embeddings, Bag-of-n-Grams, and LSTMs: Looks at representations combining multiple word vectors from the perspective of compressed sensing theory.
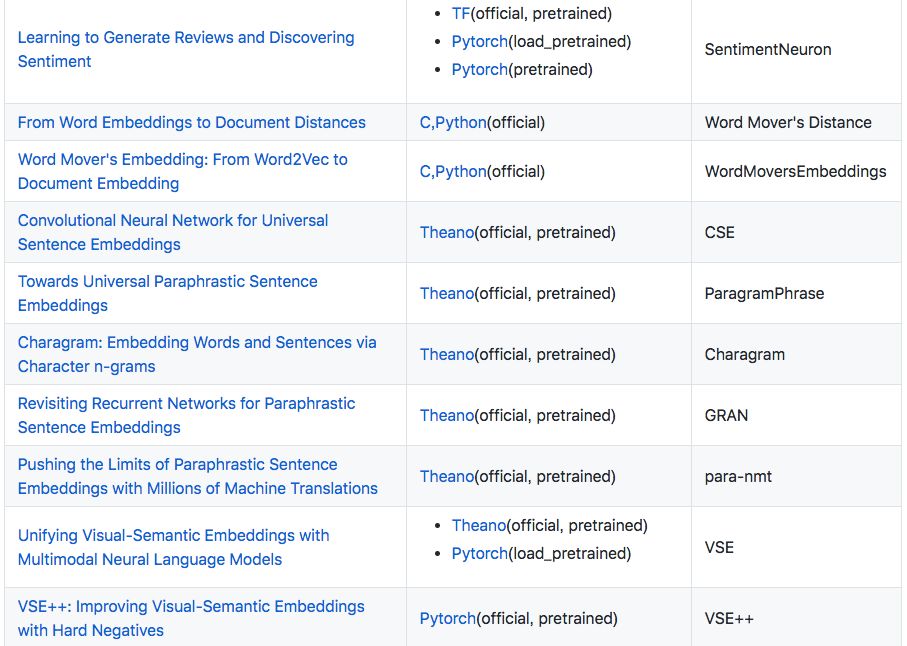
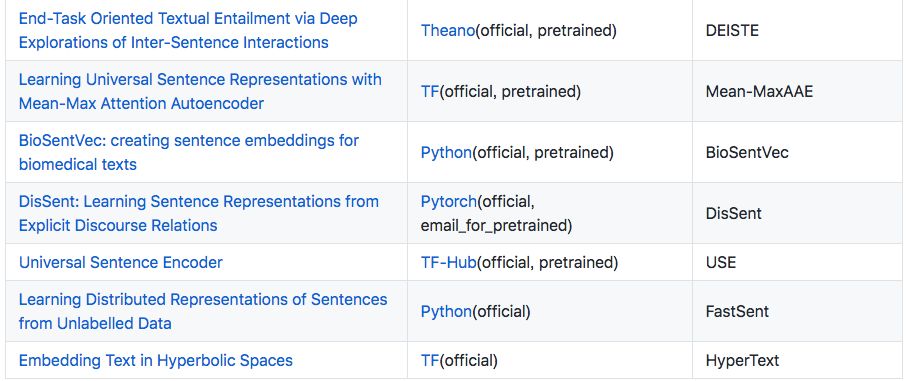
Encoders
This section introduces 25 papers, including pre-trained models like Quick-Thought, InferSent, SkipThought.

Evaluation
This section mainly introduces evaluations and benchmarks for word embeddings and sentence embeddings:
-
The Natural Language Decathlon: Multitask Learning as Question Answering
-
SentEval: An Evaluation Toolkit for Universal Sentence Representations
-
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
-
Exploring Semantic Properties of Sentence Embeddings
-
Fine-grained Analysis of Sentence Embeddings Using Auxiliary Prediction Tasks
-
How to evaluate word embeddings? On the importance of data efficiency and simple supervised tasks
-
A Corpus for Multilingual Document Classification in Eight Languages
-
Olive Oil Is Made of Olives, Baby Oil Is Made for Babies: Interpreting Noun Compounds Using Paraphrases in a Neural Model
-
Community Evaluation and Exchange of Word Vectors at wordvectors.org
-
Evaluation of sentence embeddings in downstream and linguistic probing tasks
Vector Graphs
-
Improving Vector Space Word Representations Using Multilingual Correlation: Proposes a method based on Canonical Correlation Analysis (CCA) that combines multilingual evidence and monolingual generated vectors.
-
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings: Proposes a new unsupervised self-training method that uses better initialization to guide the optimization process, which is particularly powerful for different language pairs.
-
Unsupervised Machine Translation Using Monolingual Corpora Only: Proposes transforming the machine translation task into an unsupervised task. In the machine translation task, the only required data is any corpus in each language, and the authors find how to learn a common latent space between the two languages. See: Unsupervised Machine Translation without Bilingual Corpora
Moreover, Separius also introduced some related articles and papers without published code or pre-trained models.

This article is compiled by Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (Full-time Reporter / Intern): [email protected]
Submissions or seeking coverage: content@jiqizhixin.com
Advertisement & Business Cooperation: [email protected]