
Today is January 18, 2025, Saturday, Beijing, clear weather.
Let’s continue discussing RAG.
Recently, there has been some work on Agentic RAG, which integrates autonomous agents to overcome the limitations of traditional RAG systems that perform well in knowledge retrieval and generation but struggle with dynamic, multi-step reasoning tasks, adaptability, and complex workflow orchestration.
So, let’s look at a well-organized summary for everyone to keep.
Agentic Retrieval-Augmented Generation (Agentic RAG) embeds autonomous agents into RAG. Recently, a survey titled: “Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG” was published, available at https://arxiv.org/pdf/2501.09136, with an associated list at: https://github.com/asinghcsu/AgenticRAG-Survey.
This survey is well-organized and provides detailed classifications of Agentic RAG systems, showcasing frameworks such as single-agent, multi-agent, hierarchical, corrective, adaptive, and graph-based RAG.
It conducts a comparative analysis of traditional RAG, Agentic RAG, and Agentic Document Workflows (ADW), including their advantages, disadvantages, and best-fit scenarios.
On the scenario side, it also examines practical applications in industries such as healthcare, education, finance, and legal analysis.
Specialization and systematization will lead to deeper insights. Let’s all work hard together.
1. Logical Patterns of Agentic Models Combined with RAG
Let’s concretize Agentic RAG and look at some idealized application scenarios across various industries, such as implementing intelligent retrieval, multi-step reasoning, and dynamic adaptation to complex tasks. For example:
In healthcare and personalized medicine, rapidly retrieving and synthesizing medical knowledge for diagnostics, treatment plans, and research. Utilizing clinical decision support systems with multimodal data (e.g., patient records, medical literature); automatically generating medical reports with relevant contextual citations; multi-hop reasoning for analyzing complex relationships (e.g., mapping diseases to symptoms or linking treatments to outcomes).
In education and personalized learning, providing tailored and adaptive learning experiences for different learners. For instance, designing intelligent tutors capable of real-time knowledge retrieval and personalized feedback, generating customized educational content based on student progress and preferences, and using multi-agent systems for collaborative learning simulations.
In legal and contract analysis, analyzing complex legal documents and extracting actionable insights. For example, generating contract summaries and comparing terms while aligning with legal standards and context. Retrieving precedent cases and regulatory guidelines for compliance; identifying inconsistencies or conflicts in contracts through iterative workflows.
In finance and risk analysis, analyzing large-scale financial datasets to identify trends, risks, and opportunities. For instance, automating the generation of financial summaries and investment recommendations; real-time fraud detection through multi-step reasoning and data associations; using graph-based workflows for scenario-based risk analysis modeling.
In customer support and virtual assistants, providing contextually relevant and dynamic responses to customer inquiries. For example, building AI-based virtual assistants for real-time customer support; adaptive systems improving responses through user feedback; multi-agent orchestration handling complex multi-query interactions.
In graph-enhanced applications dealing with multi-modal workflows requiring relational understanding and multi-modal data integration. For example, graph-based retrieval systems connecting structured and unstructured data; enhancing reasoning workflows in scientific research, knowledge management, etc.; synthesizing insights from text, images, and structured data to generate actionable outputs.
In document-centric workflows, automating complex workflows involving document parsing, data extraction, and multi-step reasoning. For example, in invoice payment workflows, parsing invoices to extract key details (e.g., invoice number, vendor information, payment terms), retrieving relevant vendor contracts to verify terms and compliance, and generating payment recommendation reports, including cost-saving suggestions (e.g., early payment discounts). In contract review processes, analyzing key terms and compliance issues in legal contracts, automatically identifying risks, and providing actionable recommendations. In insurance claims analysis processes, automating claims review, extracting policy terms based on predefined rules, and calculating payouts.
From the above scenarios, we can abstract some specific implementation patterns, four patterns categorized into reflective mode, planning mode, tool usage mode, and multi-agent collaboration mode. Let’s look at them one by one.
One is the reflective mode, where agents evaluate their decisions and outputs, identifying errors and areas for improvement, aiming for iterative refinement of results to enhance accuracy in multi-step reasoning tasks. For example, in a medical diagnosis system, agents refine diagnoses based on iterative feedback from retrieved data.
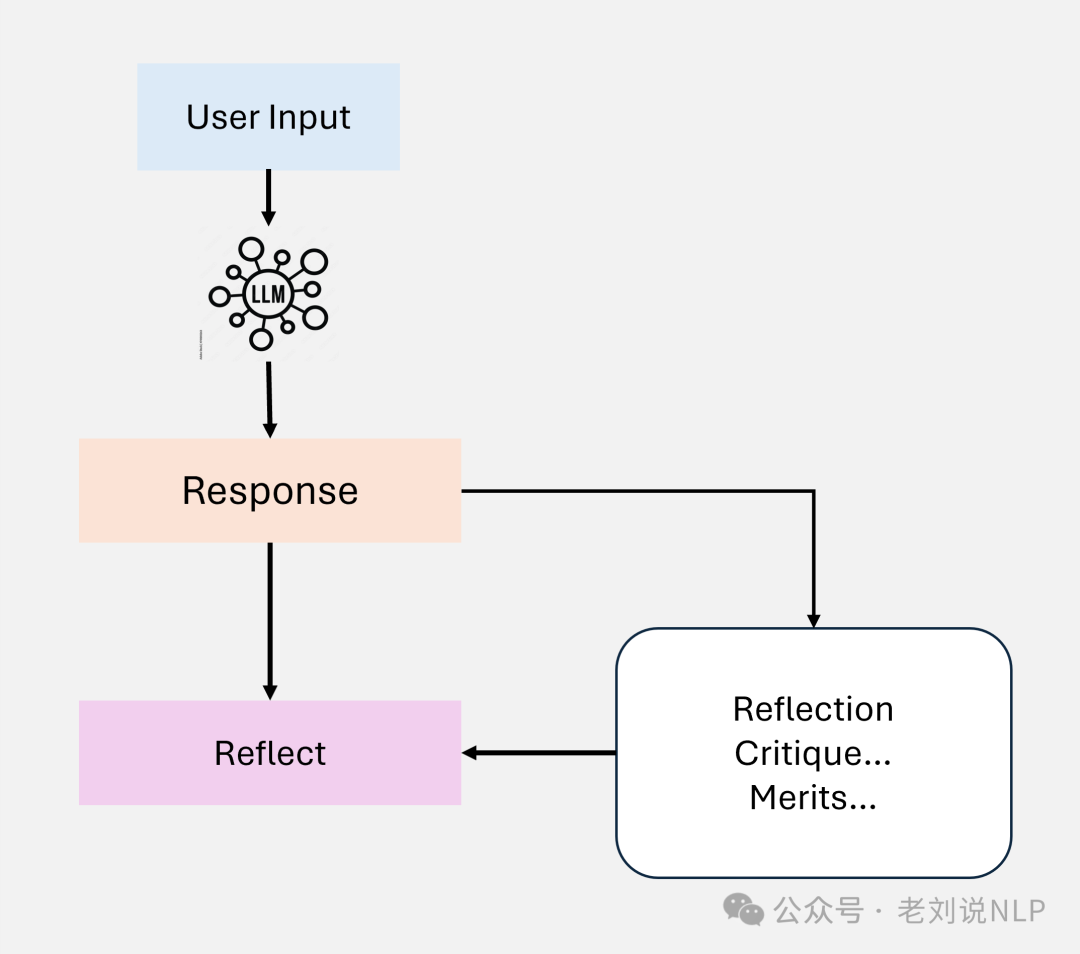
Another is the planning mode, where agents create structured workflows and task sequences to solve problems efficiently. The goal is to facilitate multi-step reasoning by breaking down tasks and reducing computational overhead through task prioritization optimization. For example, a financial analysis system plans data retrieval tasks to assess risks and provide recommendations.
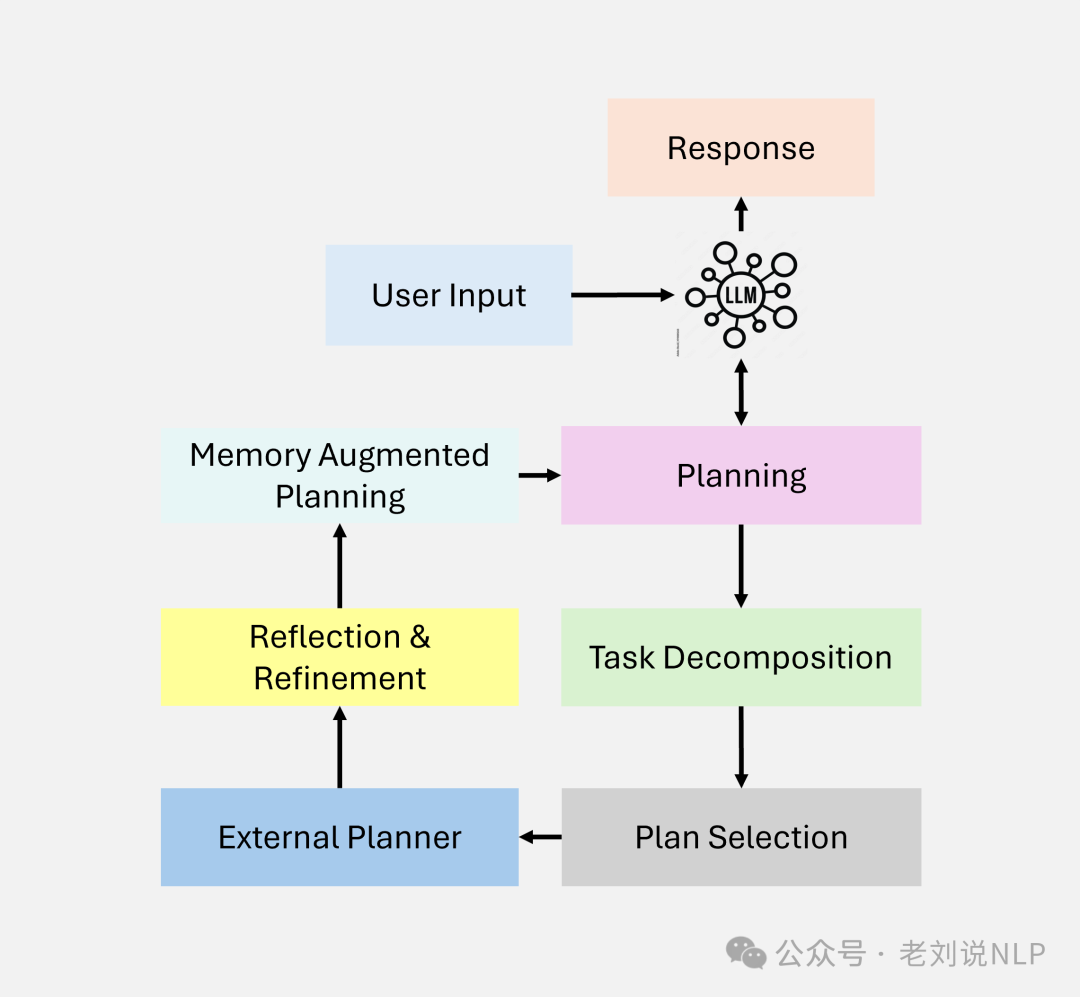
Another is the tool usage mode, where agents interact with external tools, APIs, and knowledge bases to retrieve and process data. The goal is to extend system capabilities beyond pre-trained knowledge by integrating external resources for specific domain applications. For example, legal assistant agents retrieve clauses from a contract database and apply domain-specific rules for compliance analysis.
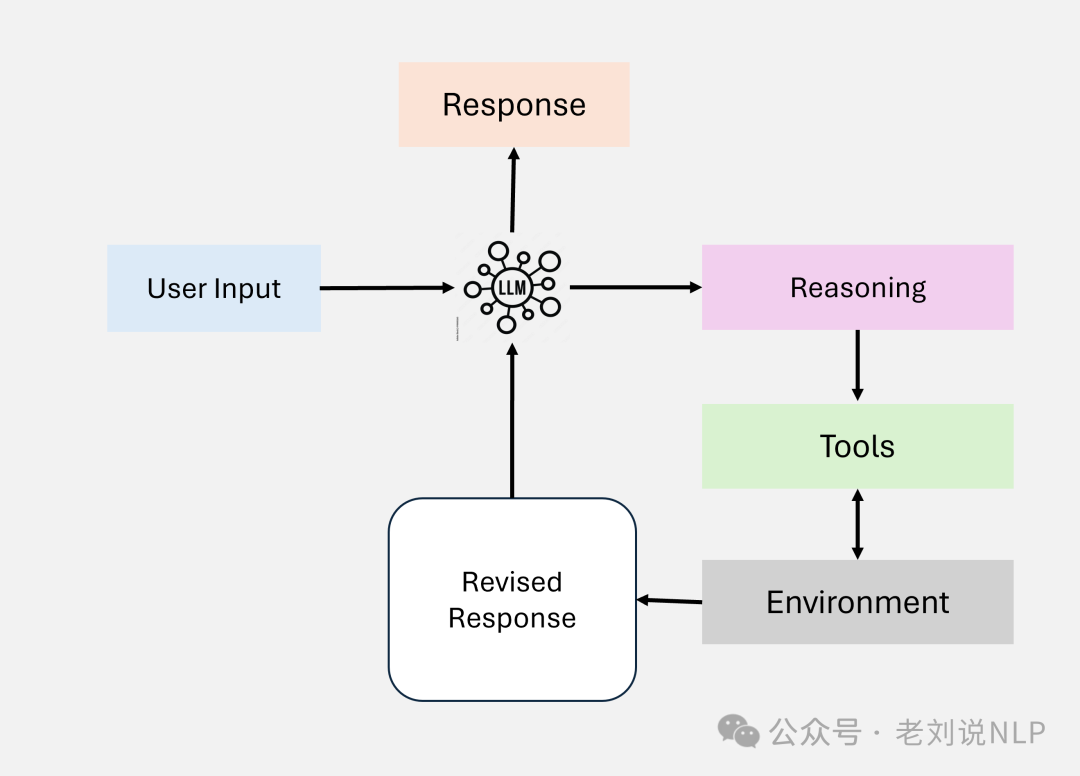
Another is the multi-agent collaboration mode, where multiple agents work together, dividing tasks to solve complex problems, sharing information and results. The goal is to efficiently handle large-scale and distributed problems, combining specialized agent capabilities for better outcomes. For example, in customer support, agents collaborate, retrieving knowledge from FAQs, generating responses, and providing follow-up.
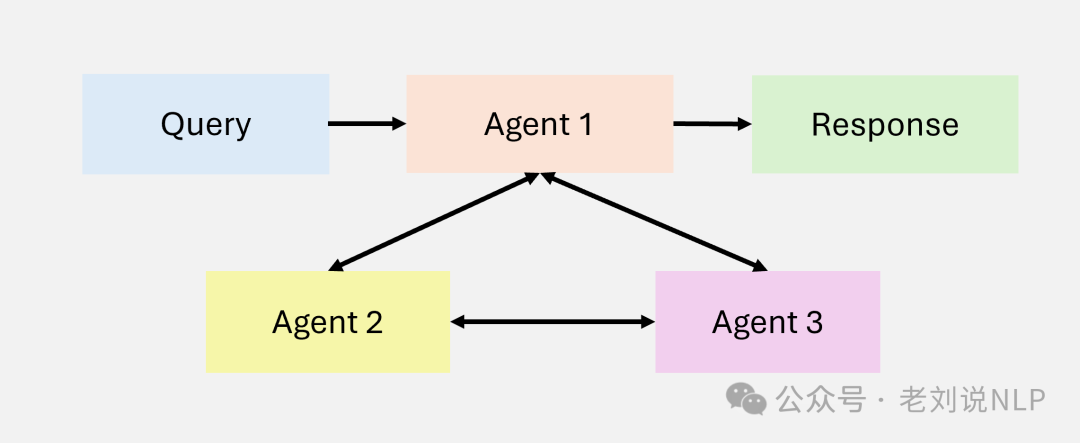
2. Classification and Comparison of Agentic RAG
For classifying Agentic RAG systems, the work is divided into several types, with a good organization covering various architectures and workflows, each customized for specific tasks and complexity levels, allowing comparison between traditional RAG, Agentic RAG, and Agentic Document Workflows (ADW).
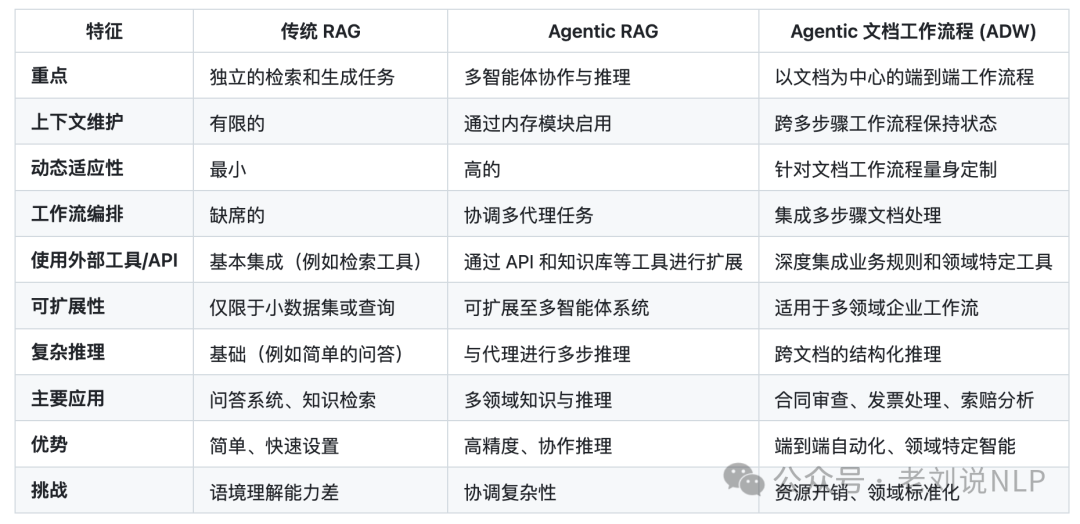
The core is that traditional RAG is best suited for simple tasks requiring basic retrieval and generation functions. Agentic RAG excels in multi-agent collaborative reasoning and is suitable for more complex multi-domain tasks. Agentic Document Workflows (ADW) provide customized document-centric solutions for enterprise applications such as contract analysis and invoice processing.
For Agentic RAG, we can focus on the following:
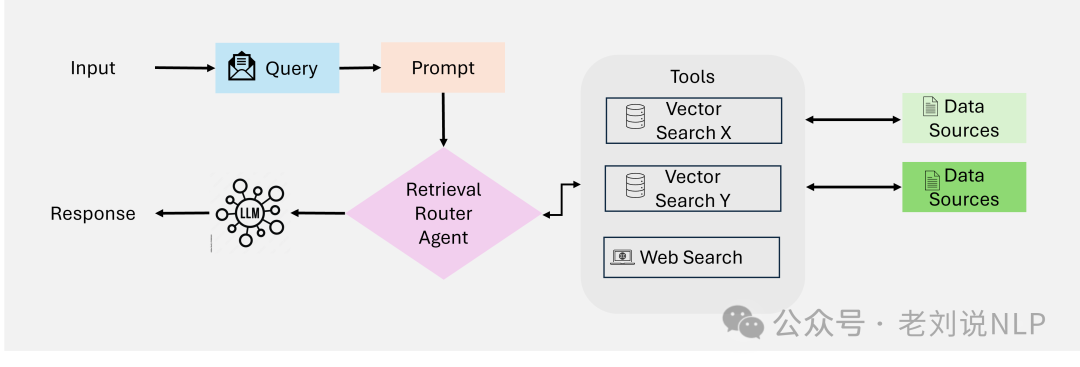
One is Single-Agent RAG (Router-Based), for example, “Search-o1: Agentic Search-Enhanced Large Reasoning Models”: https://arxiv.org/abs/2501.05366, where a single autonomous agent manages the retrieval and generation process. The workflow is as follows: query submitted to the agent -> agent retrieves relevant data from external sources -> data is processed and synthesized into a response. The advantage is that the architecture is simple and easy to implement and maintain for basic use cases, while the disadvantage is limited scalability and poor performance for multi-step reasoning or large datasets.
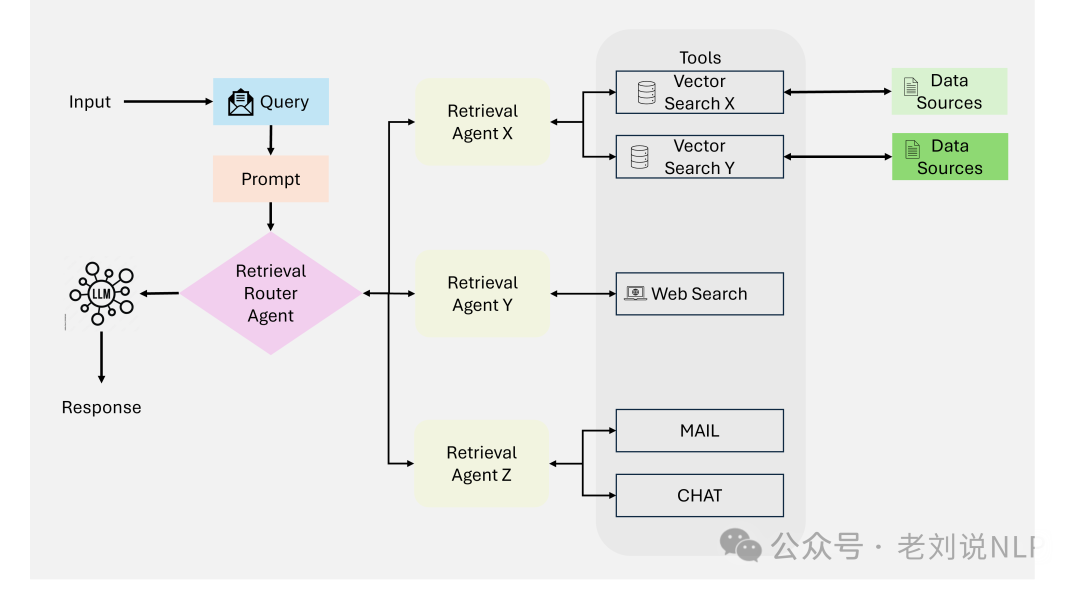
Another is Multi-Agent Agentic RAG, for example, “Agentic Retrieval-Augmented Generation for Time Series Analysis”: https://arxiv.org/abs/2408.14484, where a group of agents collaborates to perform complex retrieval and reasoning tasks. The workflow consists of agents dynamically assigning tasks (e.g., retrieval, reasoning, synthesis) -> each agent is responsible for a specific sub-task -> results are aggregated and synthesized into coherent output. The advantage is better performance for distributed, multi-step tasks, increasing modularity and scalability. The disadvantage is that coordination complexity increases with the number of agents, and there is a risk of redundancy or conflict among agents.
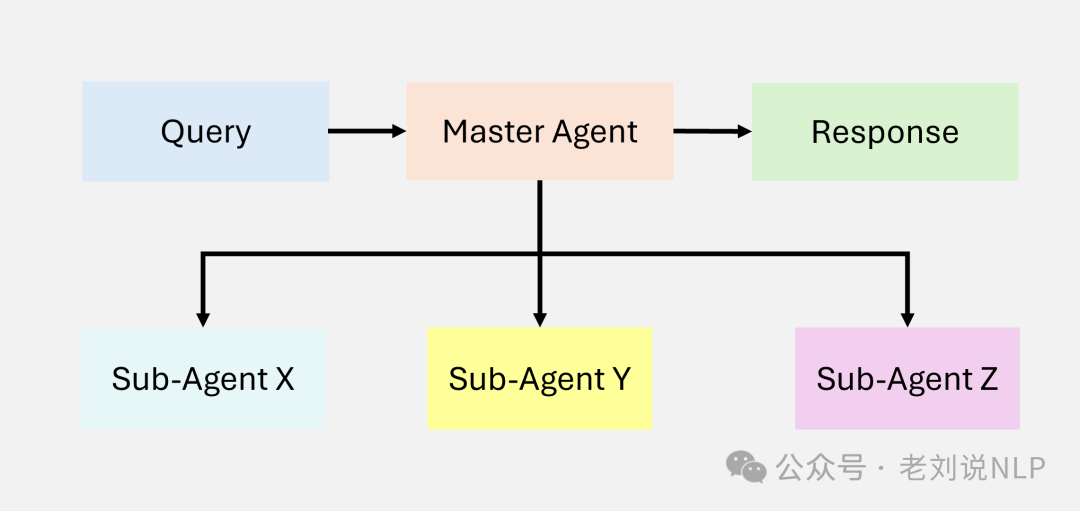
Another is Hierarchical Agentic RAG, which organizes agents through a hierarchy for better task prioritization and delegation. The workflow consists of a top-level agent coordinating sub-tasks among lower-level agents -> each lower-level agent handles a specific part of the process -> results are iteratively improved and integrated at higher levels. The advantage is scalability for large complex tasks, and modular design promotes specialization. The disadvantage is the need for complex orchestration mechanisms and potential bottlenecks at higher levels of hierarchy.
Another is Corrective Agentic RAG, for example, “Agentic AI-Driven Technical Troubleshooting for Enterprise Systems”: https://arxiv.org/abs/2412.12006; “Corrective RAG (CRAG)”: https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_crag/; “Corrective Retrieval Augmented Generation”: https://arxiv.org/abs/2401.15884; “Agentic AI-Driven Technical Troubleshooting for Enterprise Systems”: https://arxiv.org/abs/2412.12006, where the feedback loop enables agents to iteratively evaluate and improve their outputs. The workflow is as follows: agents generate initial responses -> a critique module evaluates errors or inconsistencies in the responses -> agents improve responses based on feedback -> steps 2-3 repeat until the output meets quality standards. The advantage is achieving high precision and reliability through iterative improvements, suitable for error-prone or high-risk tasks. The disadvantage is increased computational overhead, and a well-designed feedback mechanism is necessary to avoid infinite loops.
Another is Adaptive Agentic RAG, for example, “Langgraph Adaptive RAG”: https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_adaptive_rag/; “MBA-RAG: A Bandit Approach for Adaptive Retrieval-Augmented”: https://arxiv.org/abs/2412.01572; “CtrlA: Adaptive Retrieval-Augmented Generation via Inherent Control”: https://arxiv.org/abs/2405.18727; “Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity”: https://arxiv.org/abs/2403.14403; “AT-RAG: An Adaptive RAG Model Enhancing Query Efficiency with Topic Filtering and Iterative Reasoning”: https://arxiv.org/abs/2410.12886. The idea is to dynamically adjust retrieval strategies and workflows based on task requirements. The workflow is: agents evaluate queries and their context -> adjust retrieval strategies in real-time based on available data and user needs -> synthesize responses using dynamic workflows. The advantage is high flexibility for diverse tasks and dynamic environments, improving contextual relevance and user satisfaction. The disadvantage is the challenge of designing robust adaptation mechanisms and additional computational overhead for real-time adjustments.
Another is Self-Reflective Agentic RAG, for example, “Golden-Retriever: High-Fidelity Agentic Retrieval Augmented Generation for Industrial Knowledge Base”: https://arxiv.org/pdf/2408.00798v1; “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection”: https://arxiv.org/abs/2310.11511; “Langchain & Langgraph self-Reflective agentic RAG”: https://blog.langchain.dev/agentic-rag-with-langgraph; “Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models”: https://arxiv.org/abs/2401.15269, which aims to dynamically adjust retrieval strategies and workflows based on task requirements. The workflow is: agents evaluate queries and their context -> adjust retrieval strategies in real-time based on available data and user needs -> synthesize responses using dynamic workflows. The advantage is high flexibility for diverse tasks and dynamic environments, improving contextual relevance and user satisfaction. The disadvantage is the challenge of designing robust adaptation mechanisms and additional computational overhead for real-time adjustments.
Another is Graph-Based Agentic RAG, which extends traditional RAG through the integration of graph data structures for advanced reasoning. It includes two:
First is the agent framework for Graph RAG, such as “Agent-G: An Agentic Framework for Graph Retrieval Augmented Generation”: https://openreview.net/forum?id=g2C947jjjQ, which utilizes graph knowledge bases and feedback loops to dynamically assign tasks to specialized agents. The workflow is: extract relationships from a graph knowledge base (e.g., mapping diseases to symptoms) -> supplement with unstructured data from external sources -> use an evaluation module to validate results and iteratively improve. The advantage is the combination of structured and unstructured data, modular and scalable for complex tasks, and ensuring high precision through iterative refinement.
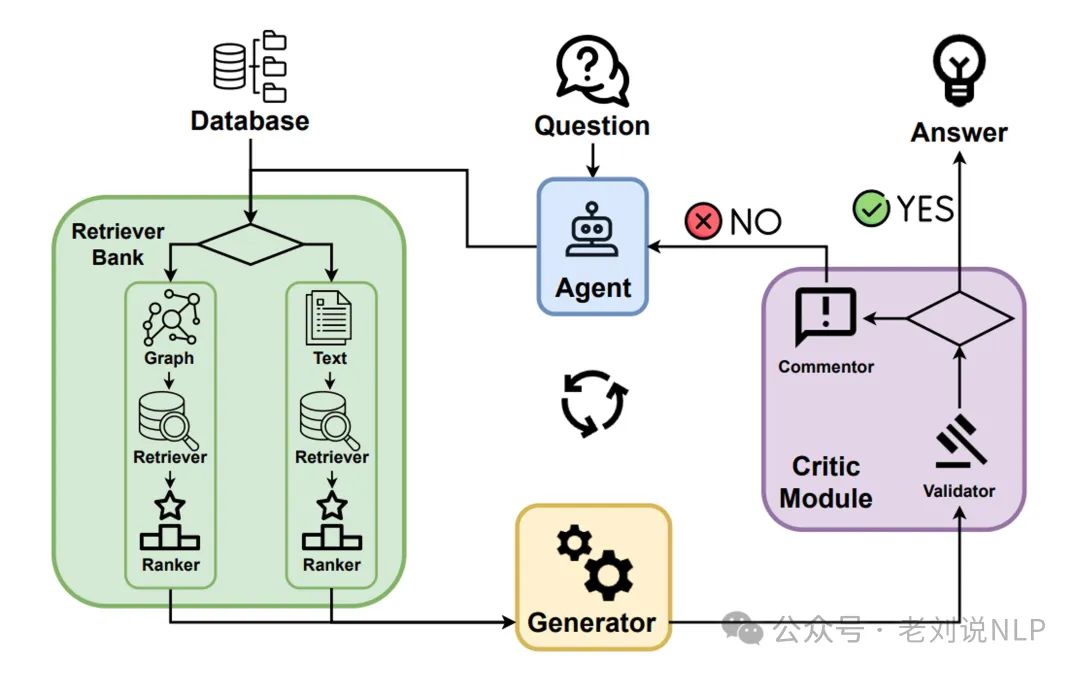
Secondly, the Graph-Enhanced Agent (GeAR), such as “GeAR: Graph-enhanced Agent for Retrieval-augmented Generation”: https://arxiv.org/abs/2412.18431, aims to enhance RAG systems through graph expansion techniques and agent-based architectures. The workflow is: expand the graph related to the query for better relational understanding -> utilize specialized agents for multi-hop reasoning -> synthesize graph structures and unstructured information into responses. The advantage is outstanding performance in multi-hop reasoning scenarios, improving accuracy for deep contextual tasks, and dynamically adapting to complex query environments.
One is Agentic Document Workflows (ADW), which aims to automate document-centric processes through intelligent agents, thus extending traditional RAG systems. The workflow is: document parsing and structuring (extracting structured data from documents like invoices or contracts) -> state maintenance (tracking context in multi-step workflows for consistency) -> knowledge retrieval (retrieving relevant references from external sources or specific domain databases) -> agent orchestration (applying business rules, executing multi-hop reasoning, and orchestrating external APIs) -> generating actionable outputs (producing structured outputs customized for specific use cases, such as reports or summaries).
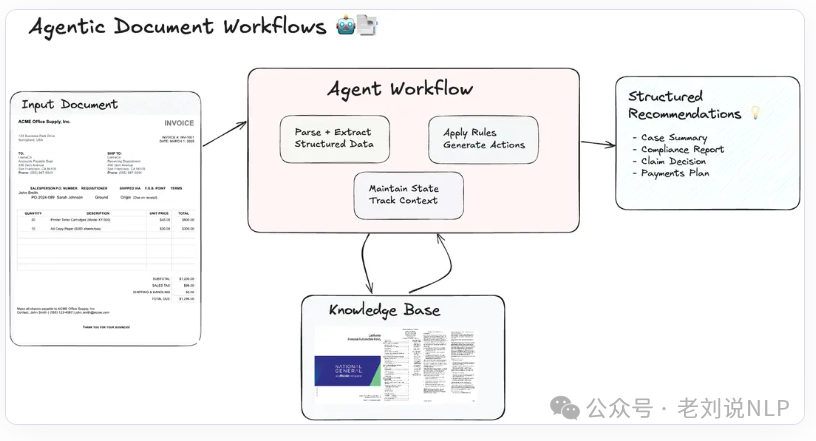
This approach ensures consistency in multi-step workflows and can achieve domain-specific intelligence by adapting to specialized fields through customized rules, efficiently handling large-scale documents and reducing manual labor. For example, https://www.llamaindex.ai/blog/introducing-agentic-document-workflows.
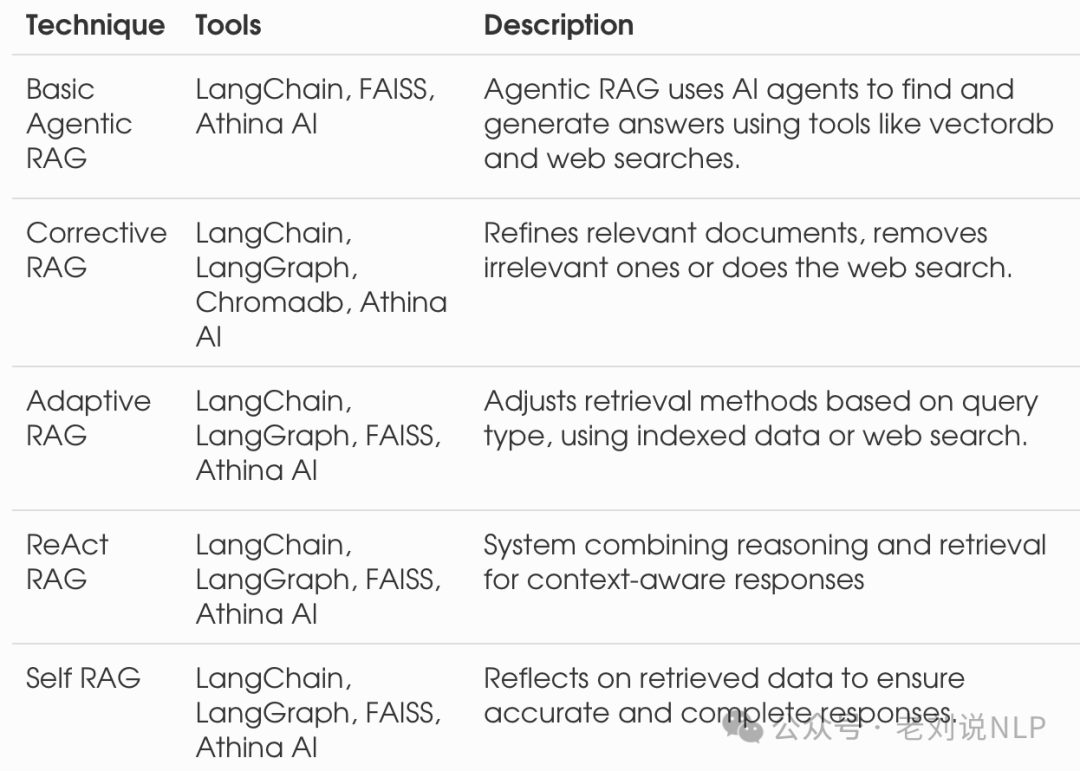
Of course, there are existing tools available to support these works, as shown in the table below:
Conclusion
This article mainly introduces the workings of Agentic RAG, conceptually well, quite comprehensive, with illustrations and examples. However, many of these are conceptual, and practical implementation may encounter various challenges. Everyone can experience more, which will yield greater rewards.
References
1. https://arxiv.org/pdf/2501.09136
2. https://github.com/asinghcsu/AgenticRAG-Survey
About Us
Old Liu, an NLP open-source enthusiast and practitioner, homepage: https://liuhuanyong.github.io.
If you are interested in large models, knowledge graphs, RAG, document understanding, and want to join the community for daily newsletters, Old Liu’s talks on the history of NLP, and sharing insights, you are welcome to join.
How to join as a member: Follow the public account, click on the membership community in the backend menu -> join the group.