Click on the above“Learning Visuals for Beginners” to choose to addStar Mark or “Pin to Top”
Important content delivered immediately
1. Convolutional Layer
Common convolution operations are as follows:
| Convolution Operation | Explanation | Illustration |
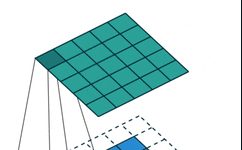
| Standard Convolution | Generally uses 3×3, 5×5, or 7×7 convolution kernels for convolution operations. |
|
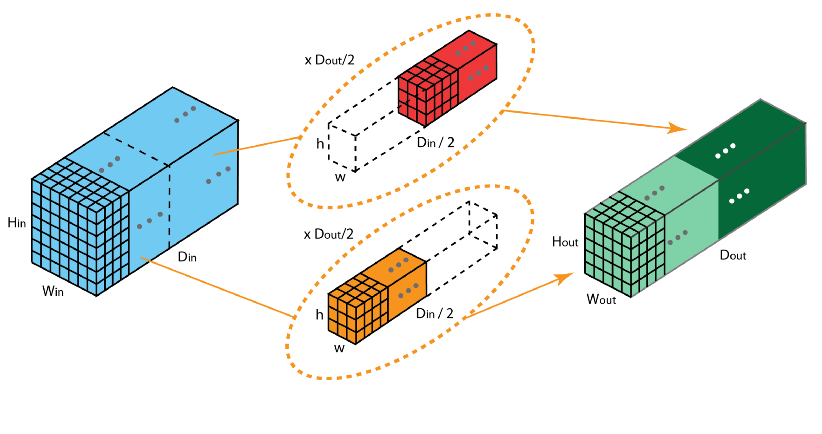
| Grouped Convolution | Divides the input feature map into x groups by channel, then performs standard convolution on each group, and finally merges them. |
|
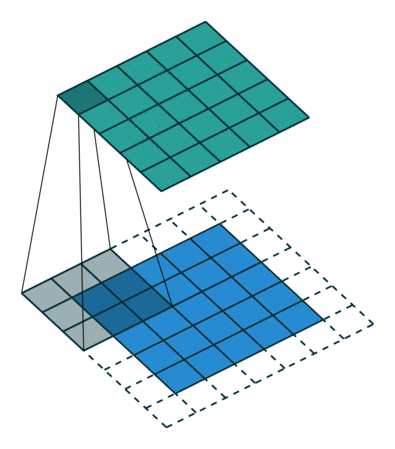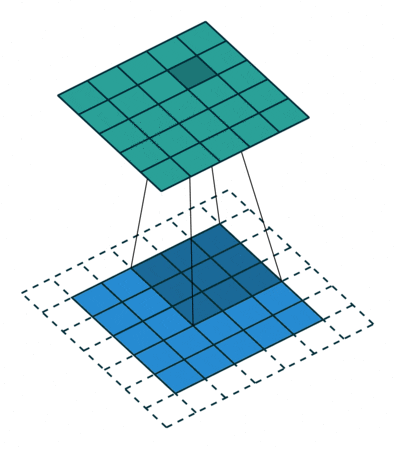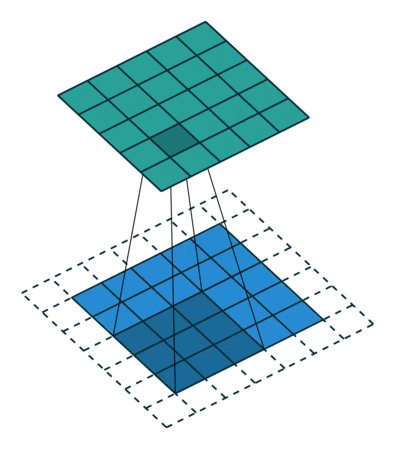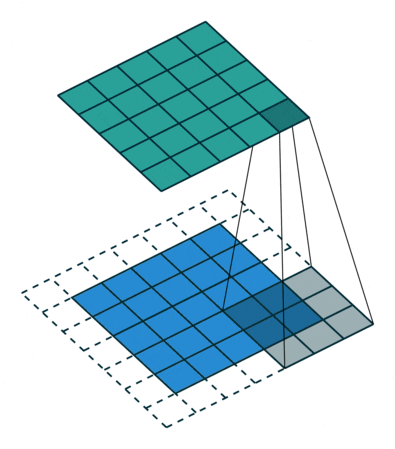
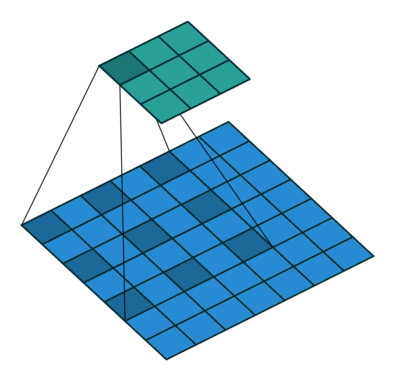
| Dilated Convolution | To expand the receptive field, spaces are inserted between the elements in the convolution kernel to “inflate” the kernel, forming a “dilated convolution” (or called an expanded convolution), and the dilation rate parameter L indicates how much to expand the kernel’s range, i.e., inserting L-1 spaces between kernel elements. When L=1, there are no spaces inserted between kernel elements, becoming standard convolution. |
|
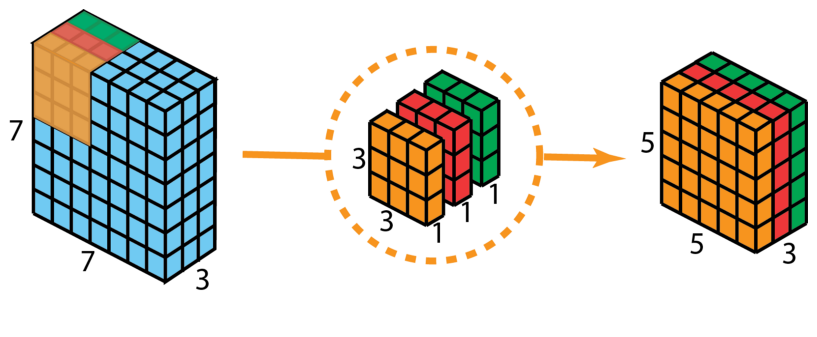
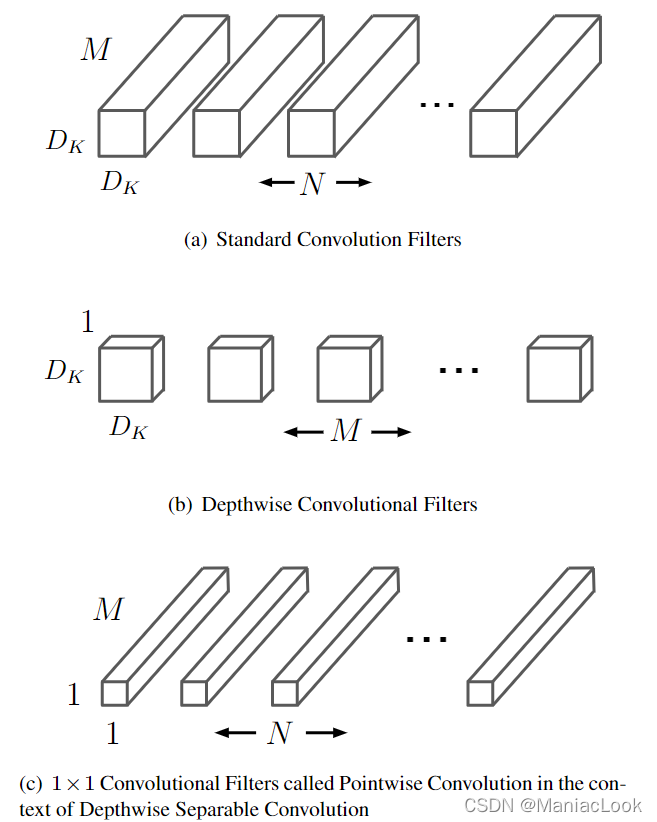
| Depthwise Separable Convolution | Depthwise separable convolution consists of two processes: depthwise convolution and pointwise convolution. |
(Channel convolution, 2D standard convolution)
(Pointwise convolution, 1×1 convolution) |
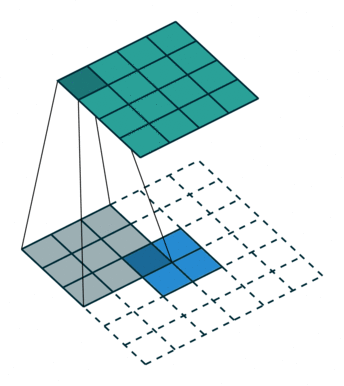
| Transposed Convolution | Part of the upsampling process, “transposed convolution” converts the convolution kernel into a sparse matrix and then performs transposed computation. |
|
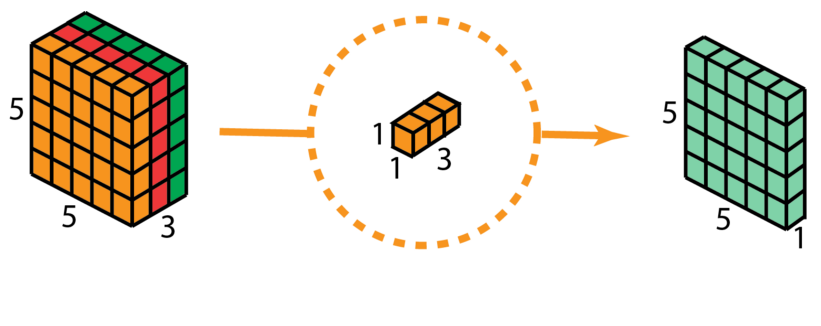
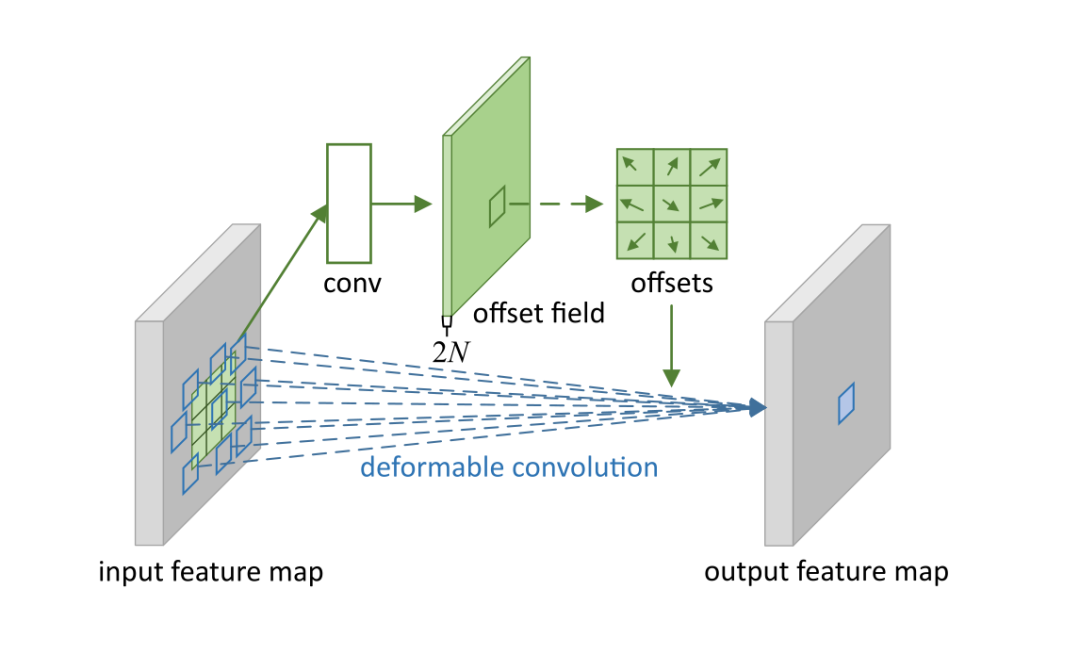
| Deformable Convolution | In standard convolution operations, the sampling position adds an offset, allowing the convolution kernel to expand to a large range during training. |
|
Supplement:
1 x 1 convolution uses a 1 x 1 convolution kernel for convolution operations, which serves to increase and decrease dimensions. The increase in dimensions is commonly used when the channel is 1 (i.e., the number of channels is 1), while the decrease in dimensions is commonly used when the channel is n (i.e., the number of channels is n).
Dimensionality reduction: the number of channels remains unchanged, but the values change.
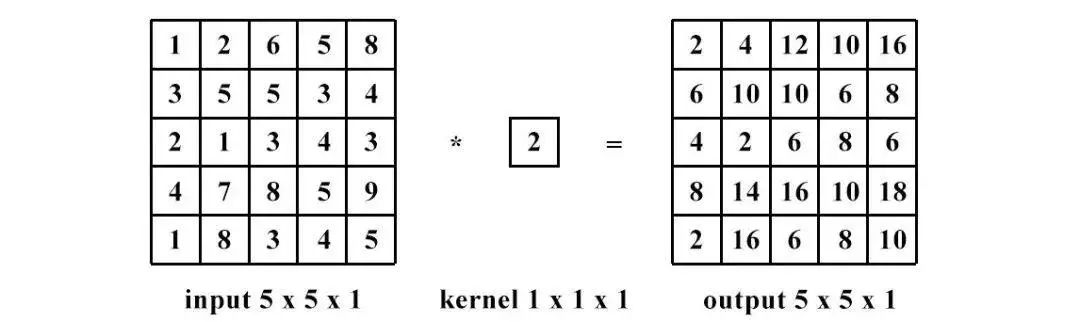
Dimensionality increase: the number of channels changes to the number of kernels (i.e., filters), and the operation can essentially be seen as a fully connected layer.
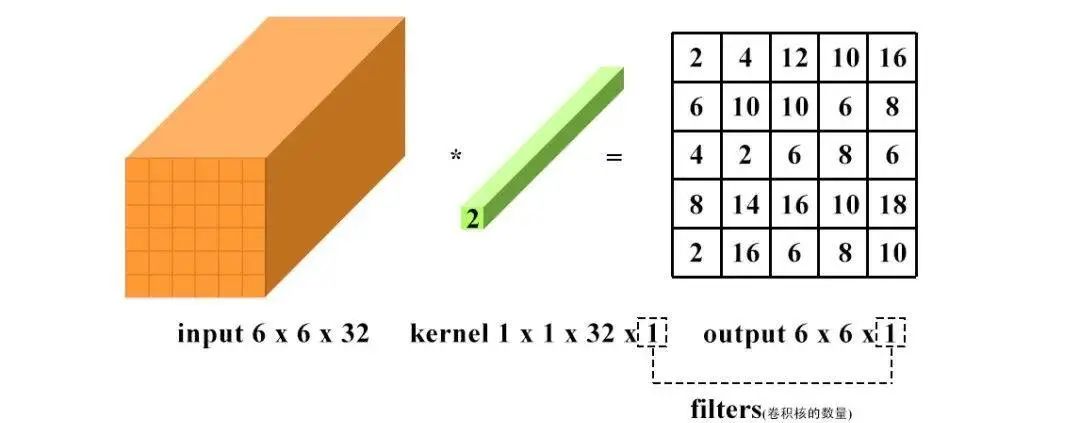
The volume of convolution calculations in deep neural networks is enormous, and the main methods to compress the convolution calculation volume are as follows:
| Serial Number | Method |
| 1 | Use multiple 3×3 convolution kernels to replace large convolution kernels (e.g., use two 3 x 3 convolution kernels to replace a 5 x 5 convolution kernel) |
| 2 | Use depthwise separable convolution (grouped convolution) |
| 3 | Channel Shuffle |
| 4 | Pooling layer |
| 5 | Stride = 2 |
| 6 | Etc. |
2. Activation Layer
Introduction: To enhance the non-linear capability of the network and improve its expressiveness, an activation layer follows each convolutional layer. Activation functions are mainly divided into saturated activation functions (sigmoid, tanh) and non-saturated activation functions (ReLU, Leaky ReLU, ELU, PReLU, RReLU). Non-saturated activation functions can solve the gradient vanishing problem and speed up convergence.
Common functions: ReLU function, Leaky ReLU function, ELU function, etc.
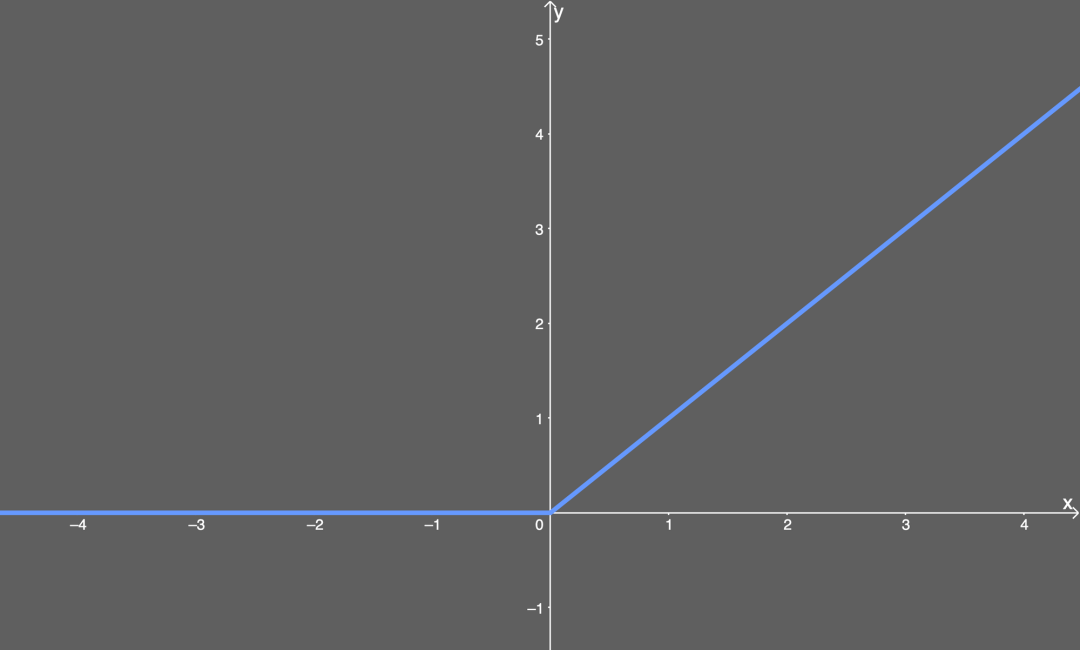
ReLU function
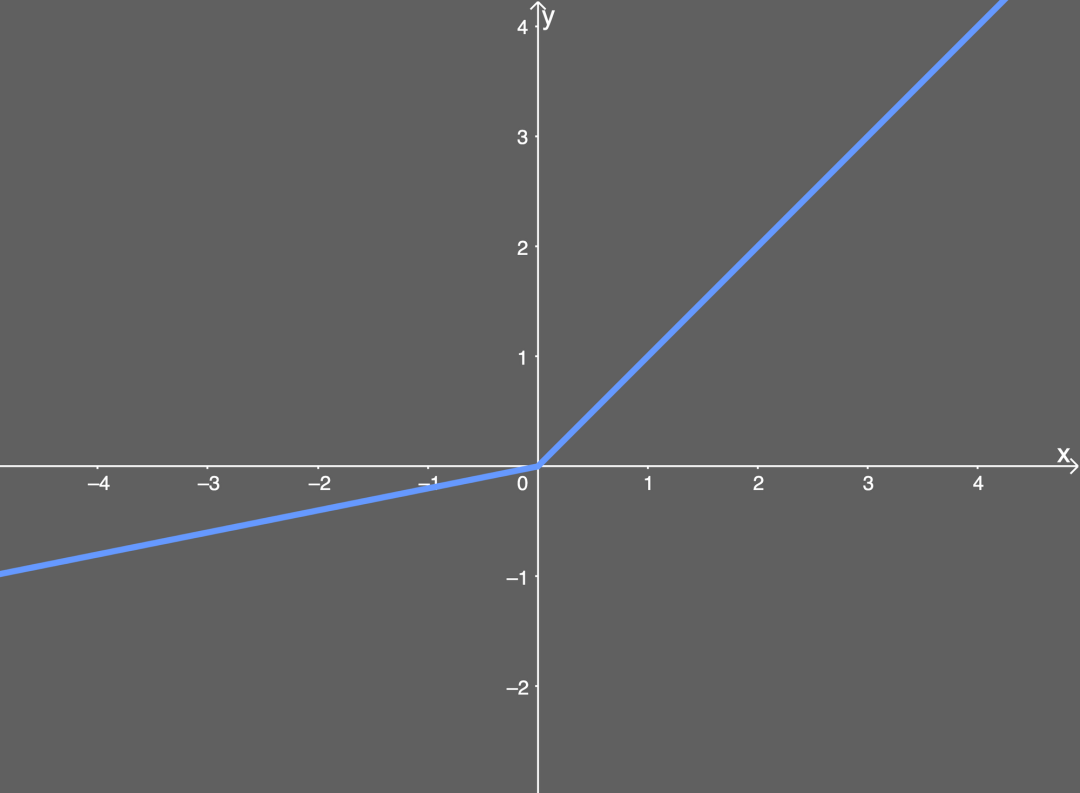
Leaky ReLU function
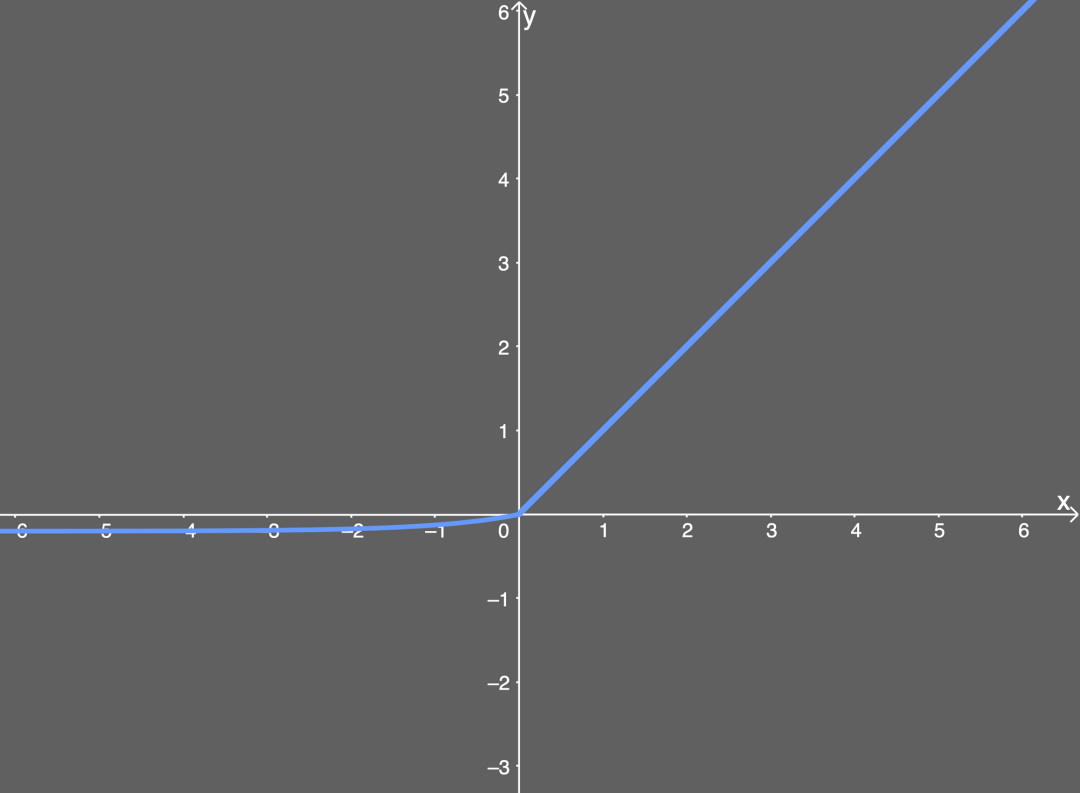
ELU function
3. BN Layer (BatchNorm)
Introduction: By certain normalization methods, the input value distribution of any neuron in each layer of the neural network is forcibly pulled back to a standard normal distribution with a mean of 0 and a variance of 1. BatchNorm is a means of normalization that reduces the absolute differences between images, highlights relative differences, and speeds up training. However, it is not suitable for image-to-image tasks or tasks sensitive to noise.
Common function: BatchNorm2d
Pytorch usage: nn.BatchNorm2d(num_features, eps, momentum, affine)
num_features: Generally, the input parameter is batch_size*num_features*height*width, which is the number of features.
eps: A value added in the denominator for computational stability, default is: 1e-5. momentum: A parameter for estimating the mean and variance during the run (my understanding is a stability coefficient, similar to the momentum coefficient in SGD).
affine: When set to true, it provides learnable coefficient matrices gamma and beta.
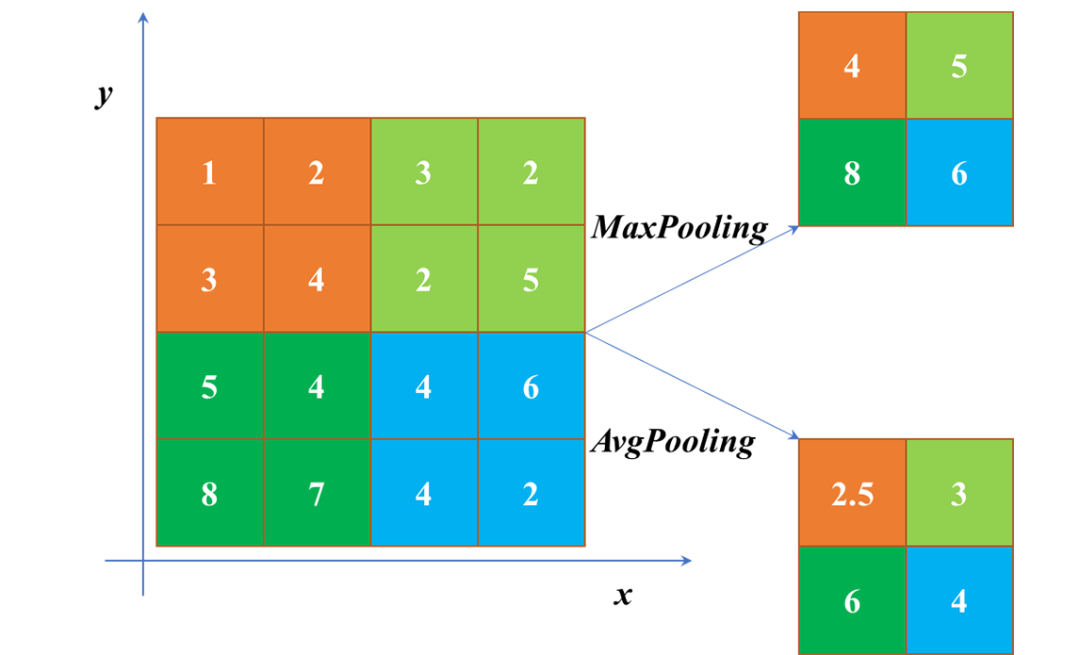
4. Pooling Layer
Introduction: Pooling reduces the feature map size and simplifies the network’s computational complexity. At the same time, it compresses features through multiple pooling operations to extract main features. It is part of the downsampling process.
Common functions: Max Pooling (maximum pooling), Average Pooling (average pooling), etc.
MaxPooling and AvgPooling usage: 1. When comprehensive decisions need to be made based on all information on the feature map, AvgPooling is usually used, for example, in image segmentation, Global AvgPooling is used to obtain global contextual information; in image classification, AvgPooling is used in the last few layers. 2. In the earlier layers of image segmentation/object detection/image classification, due to the presence of noise and irrelevant information, MaxPooling is used to remove invalid information.
Supplement: The upsampling layer resizes the image during the upsampling process, such as Resize, bilinear interpolation directly scales, similar to image scaling, concepts can be seen in nearest neighbor interpolation algorithm and bilinear interpolation algorithm. Implementation functions include nn.functional.interpolate(input, size = None, scale_factor = None, mode = ‘nearest’, align_corners = None) and nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride = 1, padding = 0, output_padding = 0, bias = True)
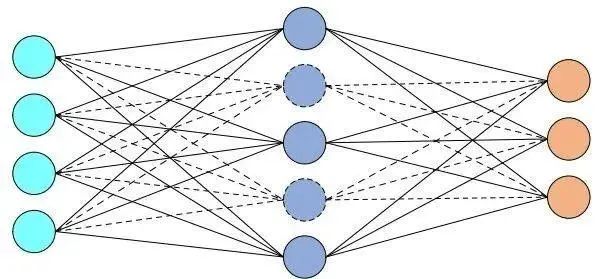
5. FC Layer (Fully Connected Layer)
Introduction: Connects all features and sends the output value to the classifier. It mainly performs a weighted sum of the features from the previous layer (the convolutional layer maps the data input to the hidden feature space), mapping the feature space to the sample label space (label) through linear transformation. The fully connected layer can be replaced by 1 x 1 convolution + global average pooling. The redundancy of fully connected layer parameters is related to the parameters and size of the fully connected layer.
Common function: nn.Linear(in_features, out_features, bias)
Supplement: Classifiers include linear and non-linear classifiers.
| Classifier | Introduction | Common Types | Advantages and Disadvantages |
| Linear Classifier | A linear classifier uses a “hyperplane” to separate positive and negative samples | LR, Softmax,Bayesian classifier, single-layer perceptron, linear regression, SVM (linear kernel), etc. | Linear classifiers are fast, easy to program, and easy to understand, but have low fitting ability |
| Non-linear Classifier | A non-linear classifier uses a “hyper-surface” or a combination of multiple hyper-planes (curved surfaces) to separate positive and negative samples (i.e., not a linear classifier) | Decision trees, RF, GBDT, multi-layer perceptron, SVM (Gaussian kernel), etc. | Non-linear classifiers have strong fitting ability, but programming implementation is more complex and understanding is more difficult |
6. Loss Layer
Introduction: Sets a loss function to compare the network’s output with the target value, driving the network’s training by minimizing the loss. The network’s loss is computed through the forward operation, and the gradient of the network parameters with respect to the loss function is computed through the backward operation.
Common functions: Loss for classification problems (discrete values: classification problems, segmentation problems): nn.BCELoss, nn.CrossEntropyLoss, etc. Loss for regression problems (continuous values: estimation problems, regression classification problems): nn.L1Loss, nn.MSELoss, nn.SmoothL1Loss, etc.
7. Dropout Layer
Introduction: Randomly drops some neurons during different training processes to prevent overfitting, generally used in fully connected layers. During testing, no random deactivation is used, and all neurons are activated.
Common function: nn.dropout
8. Optimizer
Introduction: To optimize the network structure (minimizing the loss function) more efficiently, which is the network’s optimization strategy, the main methods are as follows:
| Explanation | Optimizer Types | Characteristics |
| Based on the gradient descent principle (all use gradient descent algorithms to update network weights, differing in the number of samples used) | GD (Gradient Descent); SGD (Stochastic Gradient Descent, targeting one sample); BGD (Batch Gradient Descent, targeting all samples); MBGD (Mini-Batch Gradient Descent, targeting small batches of samples) | Introduces randomness and noise |
| Based on the momentum principle (smooths the current gradient based on local historical gradients) | Momentum; NAG (Nesterov Accelerated Gradient) | Incorporates the momentum principle, accelerating gradient descent |
| Adaptive learning rate (uses different adaptive learning rates for different parameters; Adagrad uses the sum of squares of gradients, Adadelta and RMSprop use first-order exponential smoothing of gradients; RMSprop is a special form of Adadelta, Adam combines the advantages of Momentum and RMSprop to improve gradient computation and learning rate) | Adagrad; Adadelta; RMSprop; Adam | Adaptive learning |
The commonly used optimizer is Adam, with usage being: torch.optim.Adam.
Supplement:Regularization in convolutional neural networks is to reduce variance and alleviate overfitting, with methods including: L1 regularization (sum of absolute values of parameters); L2 regularization (sum of squares of parameters, weight_decay: weight decay).
9. Learning Rate
Introduction: The learning rate is an important hyperparameter in supervised learning and deep learning, determining whether the objective function can converge to a local minimum and converge appropriately to the minimum. An appropriate learning rate allows the objective function to converge to a local minimum in a suitable timeframe.
Common functions: torch.optim.lr_scheduler; ExponentialLR; ReduceLROnplateau; CyclicLR, etc.
Common Structures of Convolutional Neural Networks
Common structures include: skip connection structure (ResNet), parallel structure (Inception V1-V4 i.e., GoogLeNet), lightweight structure (MobileNetV1), multi-branch structure (SiameseNet; TripletNet; QuadrupletNet; multi-task networks, etc.), Attention structure (ResNet+Attention)
| Structure | Introduction and Characteristics | Illustration |
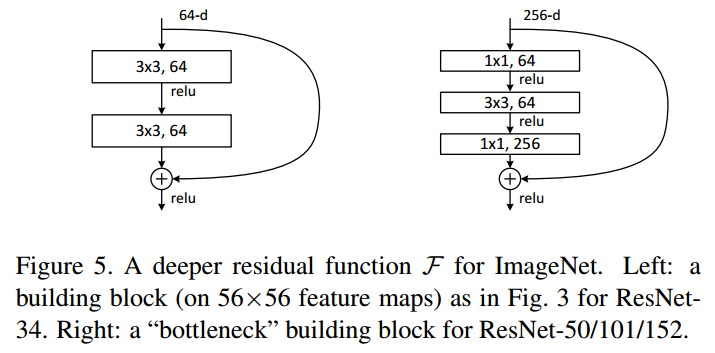
| Skip Connection Structure (Representative: ResNet) | Proposed by He et al. in 2015. Introduces a skip connection structure to prevent the gradient vanishing problem, allowing for further increases in network depth. Extended structures include: ResNeXt, DenseNet, WideResNet, ResNet In ResNet, Inception-ResNet, etc. |
|
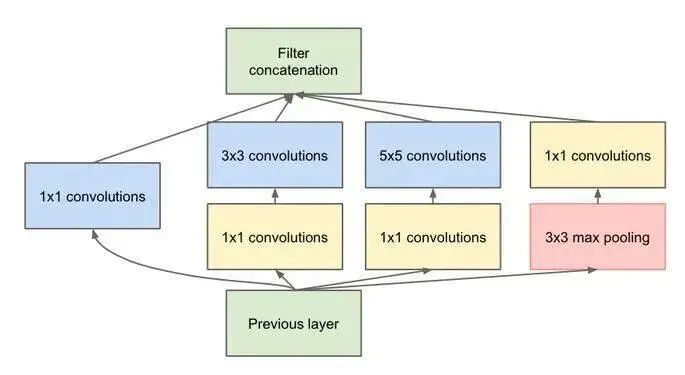
| Parallel Structure (Representative: Inception V1-V4) | Proposed by the Google team in 2014. It emphasizes not only the depth of the network but also its width. It uses 1×1 convolutions for dimension increase and decrease, performing convolutions simultaneously at multiple sizes followed by aggregation. Additionally, it speeds up convergence by decomposing the sparse matrix into dense matrix calculations. |
|
| Lightweight Structure (Representative: MobileNetV1) | Proposed by the Google team in 2017. Designed for mobile-end network structures, it replaces traditional convolution with Depth-wise Separable Convolution to reduce the number of network weight parameters. Extended structures include: MobileNetV2, MobileNetV3, SqueezeNet, ShuffleNet V1, ShuffleNet V2, etc. |
|
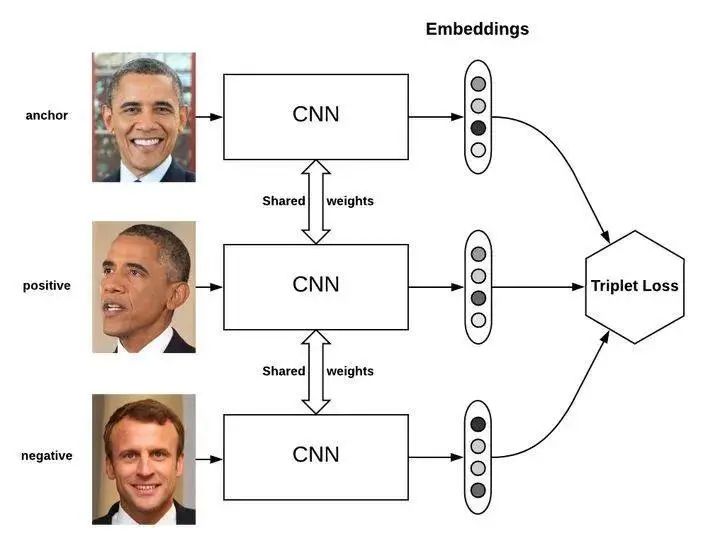
| Multi-branch Structure (Representative: TripletNet) | Proposed based on multiple feature extraction methods, learning useful variables by comparing distances. This network consists of 3 identical feedforward networks (sharing parameters), requiring input of 3 samples, one positive sample and two negative samples, or one negative sample and two positive samples. The training goal is to minimize the distance between samples of the same category while maximizing the distance between samples of different categories. Commonly used in face recognition. |
|
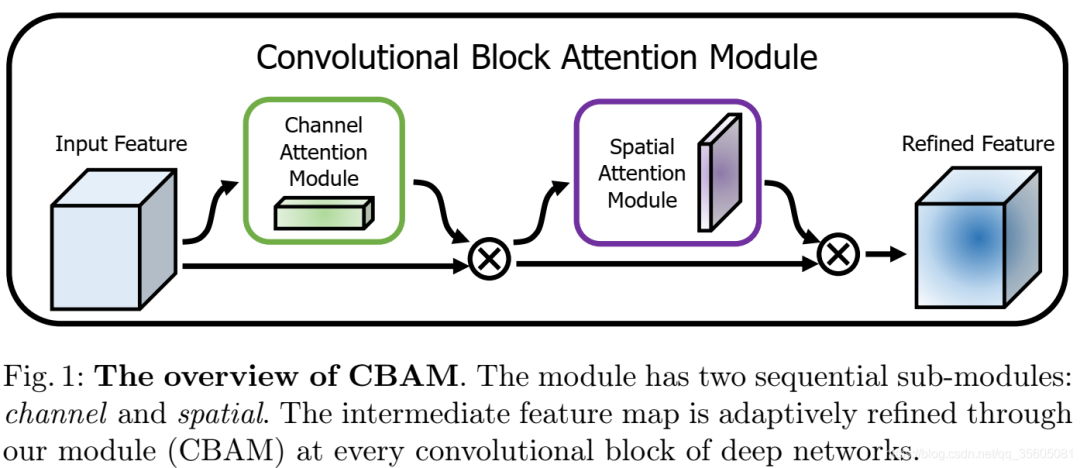
| Attention Structure (Representative: ResNet+Attention) | For global information, the attention mechanism focuses on certain special target areas, which are the focus of attention, thereby using limited attention resources to filter information, improving the accuracy and efficiency of information processing. Attention mechanisms can be categorized into Soft-Attention and Hard-Attention, and can act on feature maps, scale spaces, channel scales, and historical features at different times. |
|
Reference link:
https://www.bilibili.com/video/BV1we4y1X7vy/?spm_id_from=333.880.my_history.page.click&vd_source=8332e741acbb75b438e9c1c91efed022
Download 1: OpenCV-Contrib Extended Module Chinese Version Tutorial
Reply "Extended Module Chinese Tutorial" in the background of the "Learning Visuals for Beginners" public account to download the first OpenCV extended module tutorial in Chinese on the internet, covering installation of extended modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Project 52 Lectures
Reply "Python Visual Practical Project" in the background of the "Learning Visuals for Beginners" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to assist in quickly learning computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the background of the "Learning Visuals for Beginners" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided in the future). Please scan the WeChat number below to join the group, noting: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for notes; otherwise, it will not be approved. After successful addition, invitations to relevant WeChat groups will be sent based on research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~