MLNLP (Machine Learning Algorithms and Natural Language Processing) community is one of the largest natural language processing communities both domestically and internationally, covering NLP master's and doctoral students, university teachers, and corporate researchers.
The vision of the community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, as well as enthusiasts.
Link | https://zhuanlan.zhihu.com/p/353985363
Source | Jishi Platform
Author | Takanashi
01Preface
I have “discovered” the Pytorch-Lightning library twice. The first time I found it, I felt it was heavy and difficult to learn, and it seemed that I couldn’t use it myself. However, as the projects I worked on began to present some slightly advanced requirements, I found myself spending a lot of time on similar engineering code, and debugging took the most time on this code. Gradually, a contradiction arose: if I wanted more and better features, such as TensorBoard support, Early Stop, LR Scheduler, distributed training, fast testing, etc., the code inevitably became longer and looked messier, while the core training logic was gradually overshadowed by these engineering codes. So, is there a better solution that can solve all these problems with one click?
Then I discovered Pytorch-Lightning for the second time.
It was great.
But the problem still arose. This framework did not become easier to learn just because it was great. The official tutorials are rich, and it is clear that the developers are making efforts. However, many interconnected knowledge points are scattered across different sections, and some core understanding points are not emphasized but are briefly mentioned in small print. This made me want to create an inclusive tutorial that includes all the important concepts, useful parameters, some notes, pitfalls, a large number of example code snippets, and a concentrated explanation of some core issues that I found important during my learning process.
Finally, the third part provides a template that I summarized, which is easy to use for large projects, easy to migrate, and easy to reuse. Interested parties can try it on GitHub— https://github.com/miracleyoo/pytorch-lightning-template .
02Core
- A major feature of Pytorch-Lightning is to separate the model and the system. The model is a pure model like Resnet18, RNN, while the system defines a set of models and how they interact with each other, such as GAN (Generator Network and Discriminator Network), Seq2Seq (Encoder and Decoder Network), and Bert. Sometimes, the problem only involves one model, so this system can be a general system used to describe how the model is used and can be reused in many other projects.
- The core design philosophy of Pytorch-Lightning is “self-sufficient”. Each network also contains how to train, how to test, optimizer definitions, and other content.

03Recommended Usage Method
This section is placed at the beginning because the content is too long, and if placed at the end, this essence may be overlooked.
Pytorch-Lightning is a great library, or rather, an abstraction and packaging of pytorch. Its advantages include strong reusability, easy maintenance, and clear logic. However, the disadvantages are also obvious, as there is still quite a lot to learn and understand about this package, or in other words, it is quite heavy. If you write code directly according to the official template, it is fine for small projects, but for large projects with multiple models and datasets that need debugging and validation, it becomes quite troublesome. After a few days of exploration and debugging, I summarized the following useful template, which can also be seen as a further abstraction of Pytorch-Lightning.
Everyone is welcome to try this coding style. If you get used to it, it is quite convenient for reuse and not easy to give up halfway.
root-
|-data
|-__init__.py
|-data_interface.py
|-xxxdataset1.py
|-xxxdataset2.py
|-...
|-model
|-__init__.py
|-model_interface.py
|-xxxmodel1.py
|-xxxmodel2.py
|-...
|-main.py
If you directly apply plmodule to each model, the conversion for existing projects, others’ code, etc., will be quite time-consuming. In addition, this way, you need to add similar code to each model, such as <span>training_step</span>, <span>validation_step</span>. Obviously, this is not what we want. If you really do this, it will not only be difficult to maintain but may also become messier. Similarly, if you convert each dataset class directly into pl’s DataModule, you will face similar problems. Based on this consideration, I recommend using the above architecture:
- Only place one
<span>main.py</span>file under the main directory. <span>data</span>and<span>modle</span>folders should contain<span>__init__.py</span>files to make them packages. This makes imports easier. The two<span>init</span>files are:<span>from .data_interface import DInterface</span>and<span>from .model_interface import MInterface</span>- In
<span>data_interface</span>, create a<span>class DInterface(pl.LightningDataModule):</span>as an interface for all dataset files. In the<span>__init__()</span>function, import the corresponding Dataset class, instantiate it in the<span>setup()</span>function, and honestly add the required<span>train_dataloader</span>,<span>val_dataloader</span>,<span>test_dataloader</span>functions. These functions are often similar and can be controlled with a few input args. - Similarly, in
<span>model_interface</span>, create a<span>class MInterface(pl.LightningModule):</span>class as the intermediate interface for the model. In the<span>__init__()</span>function, import the corresponding model class, and then honestly add<span>configure_optimizers</span>,<span>training_step</span>,<span>validation_step</span>, etc., to control all models with one interface class. Different parts are controlled using input parameters. <span>main.py</span>function is only responsible for: defining the parser, adding parse items; selecting the required<span>callback</span>functions; instantiating<span>MInterface</span>,<span>DInterface</span>, and<span>Trainer</span>.
That’s it.
The complete template can be found on GitHub: https://github.com/miracleyoo/pytorch-lightning-template .
04Lightning Module
Introduction
Homepage: https://pytorch-lightning.readthedocs.io/en/latest/common/lightning_module.html
Three core components:
- Model
- Optimizer
- Train/Val/Test Steps
Pseudocode for data flow:
outs = []
for batch in data:
out = training_step(batch)
outs.append(out)
training_epoch_end(outs)
Equivalent Lightning code:
def training_step(self, batch, batch_idx):
prediction = ...
return prediction
def training_epoch_end(self, training_step_outputs):
for prediction in predictions:
# do something with these
What we need to do is to fill in these functions like filling in blanks.
Components and Functions
API page: https://pytorch-lightning.readthedocs.io/en/latest/common/lightning_module.html%23lightningmodule-api
A Pytorch-Lightning model must contain the following components:
<span>__init__</span>: Initialization, including model and system definition.<span>training_step(self, batch, batch_idx)</span>: The processing function for each batch.
Parameters:
batch (
Tensor| (Tensor, …) | [Tensor, …]) – The output of yourDataLoader. A tensor, tuple or list.batch_idx (
int) – Integer displaying index of this batchoptimizer_idx (
int) – When using multiple optimizers, this argument will also be present.hiddens (
Tensor) – Passed in if truncated_bptt_steps > 0.
Return value: Any of.
<span>Tensor</span>– The loss tensor<span>dict</span>– A dictionary. Can include any keys, but must include the key<span>'loss'</span><span>None</span>– Training will skip to the next batch
Regardless of the return value, there must be a loss quantity. If it is a dictionary, it must have this key. If there is no loss, this batch will be skipped. For example:
def training_step(self, batch, batch_idx):
x, y, z = batch
out = self.encoder(x)
loss = self.loss(out, x)
return loss
# Multiple optimizers (e.g.: GANs)
def training_step(self, batch, batch_idx, optimizer_idx):
if optimizer_idx == 0:
# do training_step with encoder
if optimizer_idx == 1:
# do training_step with decoder
# Truncated back-propagation through time
def training_step(self, batch, batch_idx, hiddens):
# hiddens are the hidden states from the previous truncated backprop step
...
out, hiddens = self.lstm(data, hiddens)
...
return {'loss': loss, 'hiddens': hiddens}
<span>configure_optimizers</span>: Optimizer definition, returns one optimizer, or multiple optimizers, or two lists (optimizers, Scheduler). For example:
# most cases
def configure_optimizers(self):
opt = Adam(self.parameters(), lr=1e-3)
return opt
# multiple optimizer case (e.g.: GAN)
def configure_optimizers(self):
generator_opt = Adam(self.model_gen.parameters(), lr=0.01)
disriminator_opt = Adam(self.model_disc.parameters(), lr=0.02)
return generator_opt, disriminator_opt
# example with learning rate schedulers
def configure_optimizers(self):
generator_opt = Adam(self.model_gen.parameters(), lr=0.01)
disriminator_opt = Adam(self.model_disc.parameters(), lr=0.02)
discriminator_sched = CosineAnnealing(discriminator_opt, T_max=10)
return [generator_opt, disriminator_opt], [discriminator_sched]
# example with step-based learning rate schedulers
def configure_optimizers(self):
gen_opt = Adam(self.model_gen.parameters(), lr=0.01)
dis_opt = Adam(self.model_disc.parameters(), lr=0.02)
gen_sched = {'scheduler': ExponentialLR(gen_opt, 0.99),
'interval': 'step'} # called after each training step
dis_sched = CosineAnnealing(discriminator_opt, T_max=10) # called every epoch
return [gen_opt, dis_opt], [gen_sched, dis_sched]
# example with optimizer frequencies
# see training procedure in `Improved Training of Wasserstein GANs`, Algorithm 1
# https://arxiv.org/abs/1704.00028
def configure_optimizers(self):
gen_opt = Adam(self.model_gen.parameters(), lr=0.01)
dis_opt = Adam(self.model_disc.parameters(), lr=0.02)
n_critic = 5
return (
{'optimizer': dis_opt, 'frequency': n_critic},
{'optimizer': gen_opt, 'frequency': 1}
)
Components that can be specified include:
<span>forward</span>: Same as normal<span>nn.Module</span>, used for inference. When called internally:<span>y=self(batch)</span><span>training_step_end</span>: Only used when training with multiple nodes and the results involve steps that require all outputs for joint operations like softmax. Similarly,<span>validation_step_end</span>/<span>test_step_end</span>.<span>training_epoch_end</span>: Called at the end of a training epoch; input parameter: a list, the contents of the list are the returns from the previous<span>training_step()</span>; return: None<span>validation_step(self, batch, batch_idx)</span>/<span>test_step(self, batch, batch_idx)</span>: No return value restrictions, it does not necessarily have to output a<span>val_loss</span>.<span>validation_epoch_end</span>/<span>test_epoch_end</span>
Utility functions include:
<span>freeze</span>: Freeze all weights for use during prediction. Only use this when training is complete and only testing is required.<span>print</span>: Although the built-in<span>print</span>function can also be used, if the program runs on a distributed system, it will print multiple times. Using<span>self.print()</span>will only print once.<span>log</span>: Like loggers such as TensorBoard, for each log scalar, there will be a corresponding x-coordinate, which may be the batch number or epoch number.<span>on_step</span>indicates that the x-coordinate for the logged quantity is the current batch, while<span>on_epoch</span>indicates that the logged quantity is accumulated over the entire epoch, with the x-coordinate being the current epoch.
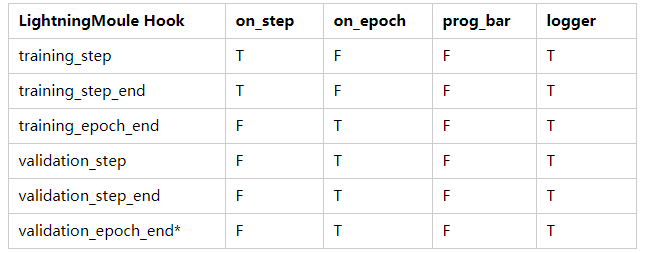
<span>*</span> also applies to the test loop
Parameters:
name (
str) – key namevalue (
Any) – value nameprog_bar (
bool) – if True logs to the progress barlogger (
bool) – if True logs to the loggeron_step (
Optional[bool]) – if True logs at this step. None auto-logs at the training_step but not validation/test_stepon_epoch (
Optional[bool]) – if True logs epoch accumulated metrics. None auto-logs at the val/test step but not training_stepreduce_fx (
Callable) – reduction function over step values for end of epoch. Torch.mean by defaulttbptt_reduce_fx (
Callable) – function to reduce on truncated back proptbptt_pad_token (
int) – token to use for paddingenable_graph (
bool) – if True, will not auto detach the graphsync_dist (
bool) – if True, reduces the metric across GPUs/TPUssync_dist_op (
Union[Any,str]) – the op to sync across GPUs/TPUssync_dist_group (
Optional[Any) – the ddp group
<span>log_dict</span>: The only difference between this and the<span>log</span>function is that the<span>name</span>and<span>value</span>variables are replaced by a dictionary. This allows logging multiple values at once. For example:<span>python values = {'loss': loss, 'acc': acc, ..., 'metric_n': metric_n} self.log_dict(values)</span><span>save_hyperparameters</span>: Store all hyperparameters input in<span>init</span>. Subsequent access can be done via<span>self.hparams.argX</span>. At the same time, the hyperparameter table will also be stored in a file.
Built-in variables in functions:
<span>device</span>: You can use<span>self.device</span>to construct device-independent tensors. For example:<span>z = torch.rand(2, 3, device=self.device)</span>.<span>hparams</span>: Contains all previously stored input hyperparameters.<span>precision</span>: Precision. Commonly 32 and 16.
Key Points
If you are preparing to use DataParallel, when writing the <span>training_step</span>, you need to call the forward function, <span>z=self(x)</span>
Template
class LitModel(pl.LightningModule):
def __init__(...):
def forward(...):
def training_step(...)
def training_step_end(...)
def training_epoch_end(...)
def validation_step(...)
def validation_step_end(...)
def validation_epoch_end(...)
def test_step(...)
def test_step_end(...)
def test_epoch_end(...)
def configure_optimizers(...)
def any_extra_hook(...)
05Trainer
Basic Usage
model = MyLightningModule()
trainer = Trainer()
trainer.fit(model, train_dataloader, val_dataloader)
If there is no validation_step, then the val_dataloader can be skipped.
Pseudocode and Hooks
Hooks page: https://pytorch-lightning.readthedocs.io/en/latest/common/lightning_module.html%23hooks
def fit(...):
on_fit_start()
if global_rank == 0:
# prepare data is called on GLOBAL_ZERO only
prepare_data()
for gpu/tpu in gpu/tpus:
train_on_device(model.copy())
on_fit_end()
def train_on_device(model):
# setup is called PER DEVICE
setup()
configure_optimizers()
on_pretrain_routine_start()
for epoch in epochs:
train_loop()
teardown()
def train_loop():
on_train_epoch_start()
train_outs = []
for train_batch in train_dataloader():
on_train_batch_start()
# ----- train_step methods -------
out = training_step(batch)
train_outs.append(out)
loss = out.loss
backward()
on_after_backward()
optimizer_step()
on_before_zero_grad()
optimizer_zero_grad()
on_train_batch_end(out)
if should_check_val:
val_loop()
# end training epoch
logs = training_epoch_end(outs)
def val_loop():
model.eval()
torch.set_grad_enabled(False)
on_validation_epoch_start()
val_outs = []
for val_batch in val_dataloader():
on_validation_batch_start()
# -------- val step methods -------
out = validation_step(val_batch)
val_outs.append(out)
on_validation_batch_end(out)
validation_epoch_end(val_outs)
on_validation_epoch_end()
# set up for train
model.train()
torch.set_grad_enabled(True)
Recommended Parameters
Parameter introduction (with video) — https://pytorch-lightning.readthedocs.io/en/latest/common/trainer.html%23trainer-flags
Class definition and default parameters— https://pytorch-lightning.readthedocs.io/en/latest/common/trainer.html%23trainer-class-api
<span>default_root_dir</span>: Default storage address. All experimental variables and weights will be stored in this folder. It is recommended that each model have its own independent folder. Each time you retrain, a new <span>version_x</span> subfolder will be created.
<span>max_epochs</span>: Maximum number of training epochs.<span>trainer = Trainer(max_epochs=1000)</span>
<span>min_epochs</span>: Minimum number of training epochs. Used when there is Early Stop.
<span>auto_scale_batch_size</span>: Automatically select an appropriate batch size before any training.
# default used by the Trainer (no scaling of batch size)
trainer = Trainer(auto_scale_batch_size=None)
# run batch size scaling, result overrides hparams.batch_size
trainer = Trainer(auto_scale_batch_size='binsearch')
# call tune to find the batch size
trainer.tune(model)
<span>auto_select_gpus</span>: Automatically select appropriate GPUs. Especially useful when some GPUs are in exclusive mode.
<span>auto_lr_find</span>: Automatically find an appropriate initial learning rate. Utilizes techniques from the paper https://arxiv.org/abs/1506.01186. Works only when executing <span>trainer.tune(model)</span>.
# run learning rate finder, results override hparams.learning_rate
trainer = Trainer(auto_lr_find=True)
# run learning rate finder, results override hparams.my_lr_arg
trainer = Trainer(auto_lr_find='my_lr_arg')
# call tune to find the lr
trainer.tune(model)
<span>precision</span>: Precision. Normally 32, using 16 can reduce memory consumption and increase batch size.
# default used by the Trainer
trainer = Trainer(precision=32)
# 16-bit precision
trainer = Trainer(precision=16, gpus=1)
<span>val_check_interval</span>: The interval for performing validation tests. Generally 1, testing 4 times during training for 1 epoch is 0.25, testing once every 1000 batches is 1000.
use (float) to check within a training epoch: at this point, this value is a percentage of an epoch. How often to test at every percentage. use (int) to check every n steps (batches): how many batches to test every time.
# default used by the Trainer
trainer = Trainer(val_check_interval=1.0)
# check validation set 4 times during a training epoch
trainer = Trainer(val_check_interval=0.25)
# check validation set every 1000 training batches
# use this when using iterableDataset and your dataset has no length
# (i.e., production cases with streaming data)
trainer = Trainer(val_check_interval=1000)
<span>gpus</span>: Control the number of GPUs to use. When set to None, use CPU.
# default used by the Trainer (i.e., train on CPU)
trainer = Trainer(gpus=None)
# equivalent
trainer = Trainer(gpus=0)
# int: train on 2 gpus
trainer = Trainer(gpus=2)
# list: train on GPUs 1, 4 (by bus ordering)
trainer = Trainer(gpus=[1, 4])
trainer = Trainer(gpus='1, 4') # equivalent
# -1: train on all gpus
trainer = Trainer(gpus=-1)
trainer = Trainer(gpus='-1') # equivalent
# combine with num_nodes to train on multiple GPUs across nodes
# uses 8 gpus in total
trainer = Trainer(gpus=2, num_nodes=4)
# train only on GPUs 1 and 4 across nodes
trainer = Trainer(gpus=[1, 4], num_nodes=4)
<span>limit_train_batches</span>: The percentage of training data to use. If the data is too large or in debugging, this can be used. The value range is 0~1. Similarly, there are <span>limit_test_batches</span>, <span>limit_val_batches</span>.
# default used by the Trainer
trainer = Trainer(limit_train_batches=1.0)
# run through only 25% of the training set each epoch
trainer = Trainer(limit_train_batches=0.25)
# run through only 10 batches of the training set each epoch
trainer = Trainer(limit_train_batches=10)
<span>fast_dev_run</span>: A bool value. If set to true, it will only execute one batch of train, val, and test, and then end. Only for debugging.
Setting this argument will disable tuner, checkpoint callbacks, early stopping callbacks, loggers, and logger callbacks like
<span>LearningRateLogger</span>and runs for only 1 epoch
# default used by the Trainer
trainer = Trainer(fast_dev_run=False)
# runs 1 train, val, test batch and program ends
trainer = Trainer(fast_dev_run=True)
# runs 7 train, val, test batches and program ends
trainer = Trainer(fast_dev_run=7)
.fit() Function
<span>Trainer.fit(model, train_dataloader=None, val_dataloaders=None, datamodule=None)</span>: The first argument must be the model, followed by a LightningDataModule or a regular Train DataLoader. If a Val step is defined, a Val DataLoader is also required.
Parameters:
datamodule ([Optional] [LightningDataModule]) – An instance of LightningDataModule.
model [LightningModule] – Model to fit.
train_dataloader ([Optional] [DataLoader]) – A Pytorch DataLoader with training samples. If the model has a predefined train_dataloader method this will be skipped.
val_dataloaders (Union [DataLoader], List [DataLoader], None) – Either a single Pytorch Dataloader or a list of them, specifying validation samples. If the model has a predefined val_dataloaders method this will be skipped
Other Key Points
<span>.test()</span>will not run unless directly called.<span>trainer.test()</span><span>.test()</span>will automatically load the best model.<span>model.eval()</span>and<span>torch.no_grad()</span>will be automatically called during testing.- By default,
<span>Trainer()</span>runs on CPU.
Usage Examples
1. Manually add command line parameters:
from argparse import ArgumentParser
def main(hparams):
model = LightningModule()
trainer = Trainer(gpus=hparams.gpus)
trainer.fit(model)
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--gpus', default=None)
args = parser.parse_args()
main(args)
2. Automatically add all parameters that <span>Trainer</span> will use:
from argparse import ArgumentParser
if __name__ == '__main__':
parser = ArgumentParser()
parser = Trainer.add_argparse_args(
# group the Trainer arguments together
parser.add_argument_group(title="pl.Trainer args")
)
args = parser.parse_args()
main(args)
3. Mixed, using both <span>Trainer</span> related parameters and some custom parameters, such as various model hyperparameters:
from argparse import ArgumentParser
import pytorch_lightning as pl
from pytorch_lightning import LightningModule, Trainer
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--batch_size', default=32, type=int)
parser.add_argument('--hidden_dim', type=int, default=128)
parser = Trainer.add_argparse_args(
# group the Trainer arguments together
parser.add_argument_group(title="pl.Trainer args")
)
args = parser.parse_args()
main(args)
All Parameters
Trainer.__init__(logger=True, checkpoint_callback=True, callbacks=None, default_root_dir=None, gradient_clip_val=0, process_position=0, num_nodes=1, num_processes=1, gpus=None, auto_select_gpus=False, tpu_cores=None, log_gpu_memory=None, progress_bar_refresh_rate=None, overfit_batches=0.0, track_grad_norm=- 1, check_val_every_n_epoch=1, fast_dev_run=False, accumulate_grad_batches=1, max_epochs=None, min_epochs=None, max_steps=None, min_steps=None, limit_train_batches=1.0, limit_val_batches=1.0, limit_test_batches=1.0, limit_predict_batches=1.0, val_check_interval=1.0, flush_logs_every_n_steps=100, log_every_n_steps=50, accelerator=None, sync_batchnorm=False, precision=32, weights_summary=’top’, weights_save_path=None, num_sanity_val_steps=2, truncated_bptt_steps=None, resume_from_checkpoint=None, profiler=None, benchmark=False, deterministic=False, reload_dataloaders_every_epoch=False, auto_lr_find=False, replace_sampler_ddp=True, terminate_on_nan=False, auto_scale_batch_size=False, prepare_data_per_node=True, plugins=None, amp_backend=’native’, amp_level=’O2′, distributed_backend=None, move_metrics_to_cpu=False, multiple_trainloader_mode=’max_size_cycle’, stochastic_weight_avg=False)
What Log and Return Loss Actually Do
To add a training loop use the training_step method.
class LitClassifier(pl.LightningModule):
def __init__(self, model):
super().__init__()
self.model = model
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = F.cross_entropy(y_hat, y)
return loss
Whether it’s <span>training_step</span>, <span>validation_step</span>, or <span>test_step</span>, the return value is always <span>loss</span>. The returned loss will be collected in a list.
Under the hood, Lightning does the following (pseudocode):
# put model in train mode
model.train()
torch.set_grad_enabled(True)
losses = []
for batch in train_dataloader:
# forward
loss = training_step(batch)
losses.append(loss.detach())
# backward
loss.backward()
# apply and clear grads
optimizer.step()
optimizer.zero_grad()
Training Epoch-Level Metrics
If you want to calculate epoch-level metrics and log them, use the <span>.log</span> method.
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = F.cross_entropy(y_hat, y)
# logs metrics for each training_step,
# and the average across the epoch, to the progress bar and logger
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
return loss
If you use the <span>.log()</span> function in the <span>x_step</span> function, then this quantity will be logged step by step. Each logged variable will be recorded, and each step will generate a dictionary dict, while each epoch will collect these dictionaries into a list of dictionaries.
The .log object automatically reduces the requested metrics across the full epoch. Here’s the pseudocode of what it does under the hood:
outs = []
for batch in train_dataloader:
# forward
out = training_step(val_batch)
# backward
loss.backward()
# apply and clear grads
optimizer.step()
optimizer.zero_grad()
epoch_metric = torch.mean(torch.stack([x['train_loss'] for x in outs]))
Train Epoch-Level Operations
If you need to do something with all the outputs of each training_step, override training_epoch_end yourself.
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = F.cross_entropy(y_hat, y)
preds = ...
return {'loss': loss, 'other_stuff': preds}
def training_epoch_end(self, training_step_outputs):
for pred in training_step_outputs:
# do something
The matching pseudocode is:
outs = []
for batch in train_dataloader:
# forward
out = training_step(val_batch)
# backward
loss.backward()
# apply and clear grads
optimizer.step()
optimizer.zero_grad()
training_epoch_end(outs)
06DataModule
Homepage: https://pytorch-lightning.readthedocs.io/en/latest/extensions/datamodules.html
Introduction
First, this <span>DataModule</span> does not conflict with the previously written Dataset. The former is a wrapper for the latter, and this wrapper can be used for multiple torch Datasets. In my opinion, its greatest function is to simplify the reuse of repetitive code such as various train/val/test divisions and DataLoader initialization through a wrapper class.
Specific functional items:
- Download instructions: Download
- Processing instructions: Process
- Split instructions: Split
- Train dataloader: Training set Dataloader
- Val dataloader(s): Validation set Dataloader
- Test dataloader(s): Test set Dataloader
Secondly, <span>pl.LightningDataModule</span><span> is like a feature-enhanced version of torch Dataset, with enhanced functionalities including:</span>
<span>prepare_data(self)</span>:
- At the very beginning, perform some operations that need to be executed only once regardless of the number of GPUs, such as disk writing downloads, tokenization, etc.
- This is a one-time preparation function for the data.
- Since it is called in a single thread, do not perform assignments like
<span>self.x=y</span>in this function. - However, if it is for personal use and not for public distribution, this function may not need to be called, as the data is already processed.
<span>setup(self, stage=None)</span>:
- Instantiate the dataset (Dataset) and perform related operations, such as counting class numbers, dividing train/val/test sets, etc.
- The parameter
<span>stage</span>is used to indicate whether it is in the training phase (<span>fit</span>) or testing phase (<span>test</span>), where the<span>fit</span>phase needs to build datasets for both train and val. - The setup function does not need to return a value. The initialized train/val/test set can be directly assigned to self.
<span>train_dataloader/val_dataloader/test_dataloader</span>:
- Initialize
<span>DataLoader</span>. - Return a DataLoader quantity.
Example
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir: str = './', batch_size: int = 64, num_workers: int = 8):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.num_workers = num_workers
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# self.dims is returned when you call dm.size()
# Setting default dims here because we know them.
# Could optionally be assigned dynamically in dm.setup()
self.dims = (1, 28, 28)
self.num_classes = 10
def prepare_data(self):
# download
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage=None):
# Assign train/val datasets for use in dataloaders
if stage == 'fit' or stage is None:
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
# Assign test dataset for use in dataloader(s)
if stage == 'test' or stage is None:
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size, num_workers=self.num_workers)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.batch_size, num_workers=self.num_workers)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size, num_workers=self.num_workers)
Key Points
If a <span>self.dims</span> variable is defined in the DataModule, it can be called later using <span>dm.size()</span>.
07Saving and Loading
Homepage: https://pytorch-lightning.readthedocs.io/en/latest/common/weights_loading.html
Saving
ModelCheckpoint address: https://pytorch-lightning.readthedocs.io/en/latest/extensions/generated/pytorch_lightning.callbacks.ModelCheckpoint.html%23pytorch_lightning.callbacks.ModelCheckpoint
ModelCheckpoint: An automatically saved callback module. By default, during training, it will only automatically save the latest model and related parameters, but users can customize this module. For example, monitor a <span>val_loss</span> quantity and save the top 3 best models, as well as the model from the last epoch, etc. For example:
from pytorch_lightning.callbacks import ModelCheckpoint
# saves a file like: my/path/sample-mnist-epoch=02-val_loss=0.32.ckpt
checkpoint_callback = ModelCheckpoint(
monitor='val_loss',
filename='sample-mnist-{epoch:02d}-{val_loss:.2f}',
save_top_k=3,
mode='min',
save_last=True
)
trainer = pl.Trainer(gpus=1, max_epochs=3, progress_bar_refresh_rate=20, callbacks=[checkpoint_callback])
- Additionally, you can manually store a checkpoint:
<span>trainer.save_checkpoint("example.ckpt")</span> <span>ModelCheckpoint</span>Callback, if<span>save_weights_only =True</span>, will only store the model’s weights (equivalent to<span>model.save_weights(filepath)</span>), otherwise it will store the entire model (equivalent to<span>model.save(filepath)</span>).
Loading
Load a model, including its weights, biases, and hyperparameters:
model = MyLightingModule.load_from_checkpoint(PATH)
print(model.learning_rate)
# prints the learning_rate you used in this checkpoint
model.eval()
y_hat = model(x)
When loading a model, replace some hyperparameters:
class LitModel(LightningModule):
def __init__(self, in_dim, out_dim):
super().__init__()
self.save_hyperparameters()
self.l1 = nn.Linear(self.hparams.in_dim, self.hparams.out_dim)
# if you train and save the model like this it will use these values when loading
# the weights. But you can overwrite this
LitModel(in_dim=32, out_dim=10)
# uses in_dim=32, out_dim=10
model = LitModel.load_from_checkpoint(PATH)
# uses in_dim=128, out_dim=10
model = LitModel.load_from_checkpoint(PATH, in_dim=128, out_dim=10)
Fully load the training state: load includes everything about the model, as well as all parameters related to training, such as <span>model, epoch, step, LR schedulers, apex</span>, etc.
model = LitModel()
trainer = Trainer(resume_from_checkpoint='some/path/to/my_checkpoint.ckpt')
# automatically restores model, epoch, step, LR schedulers, apex, etc...
trainer.fit(model)
08Callbacks
Callbacks are self-contained programs that can interweave with the training process without polluting the main research logic.
Callbacks are not only called at the end of each epoch. Pytorch-Lightning provides dozens of hooks (interfaces, call locations) to choose from and allows for custom callbacks to implement any desired module.
The recommended approach is to write these functions into the Lightning module as operations that change with the problem and project, while relatively independent and auxiliary content that needs to be reused can be defined as separate modules for easy plug-and-play in the future.
Recommended Callbacks
Built-in Callbacks: https://pytorch-lightning.readthedocs.io/en/latest/extensions/callbacks.html%23built-in-callbacks
<span>EarlyStopping(monitor='early_stop_on', min_delta=0.0, patience=3, verbose=False, mode='min', strict=True)</span>: Stop training early based on a certain value if there is no improvement for several epochs.
Parameters:
monitor (str) – quantity to be monitored. Default: ‘early_stop_on’.
min_delta (float) – minimum change in the monitored quantity to qualify as an improvement, i.e. an absolute change of less than min_delta will count as no improvement. Default: 0.0.
patience (int) – number of validation epochs with no improvement after which training will be stopped. Default: 3.
verbose (bool) – verbosity mode. Default: False.
mode (str) – one of ‘min’, ‘max’. In ‘min’ mode, training will stop when the quantity monitored has stopped decreasing and in ‘max’ mode it will stop when the quantity monitored has stopped increasing.
strict (bool) – whether to crash the training if monitor is not found in the validation metrics. Default: True.
Example:
from pytorch_lightning import Trainer
from pytorch_lightning.callbacks import EarlyStopping
early_stopping = EarlyStopping('val_loss')
trainer = Trainer(callbacks=[early_stopping])
<span>ModelCheckpoint</span>: See the previous section Saving and Loading.<span>PrintTableMetricsCallback</span>: Print a summary table of results at the end of each epoch.
from pl_bolts.callbacks import PrintTableMetricsCallback
callback = PrintTableMetricsCallback()
trainer = pl.Trainer(callbacks=[callback])
trainer.fit(...)
# ------------------------------
# at the end of every epoch it will print
# ------------------------------
# loss│train_loss│val_loss│epoch
# ──────────────────────────────
# 2.2541470527648926│2.2541470527648926│2.2158432006835938│0
09Logging
Logging: The default logger is TensorBoard, but various mainstream logger frameworks such as Comet.ml, MLflow, Netpune, or direct CSV files can be specified. Multiple loggers can be used simultaneously.
from pytorch_lightning import loggers as pl_loggers
# Default
tb_logger = pl_loggers.TensorBoardLogger(
save_dir=os.getcwd(),
version=None,
name='lightning_logs'
)
trainer = Trainer(logger=tb_logger)
# Or use the same format as others
tb_logger = pl_loggers.TensorBoardLogger('logs/')
# One Logger
comet_logger = pl_loggers.CometLogger(save_dir='logs/')
trainer = Trainer(logger=comet_logger)
# Save code snapshot
logger = pl_loggers.TestTubeLogger('logs/', create_git_tag=True)
# Multiple Logger
tb_logger = pl_loggers.TensorBoardLogger('logs/')
comet_logger = pl_loggers.CometLogger(save_dir='logs/')
trainer = Trainer(logger=[tb_logger, comet_logger])
By default, logs every 50 batches, which can be adjusted through parameters.
If you want to log non-scalar outputs, such as images, text, histograms, etc., you can directly call <span>self.logger.experiment.add_xxx()</span><span> to achieve the desired operation.</span>
def training_step(...):
...
# the logger you used (in this case tensorboard)
tensorboard = self.logger.experiment
tensorboard.add_image()
tensorboard.add_histogram(...)
tensorboard.add_figure(...)
To use log: If it is TensorBoard, then:<span>tensorboard --logdir ./lightning_logs</span>. In Jupyter Notebook, you can use:
# Start tensorboard.
%load_ext tensorboard
%tensorboard --logdir lightning_logs/
Open TensorBoard inline.
- Tip: If you start TensorBoard on the local area network, add the flag
<span>--bind_all</span>to access it via the hostname:
tensorboard --logdir lightning_logs --bind_all` -> `http://SERVER-NAME:6006/
10Transfer Learning
Homepage: https://pytorch-lightning.readthedocs.io/en/latest/starter/introduction_guide.html%23transfer-learning
import torchvision.models as models
class ImagenetTransferLearning(LightningModule):
def __init__(self):
super().__init__()
# init a pretrained resnet
backbone = models.resnet50(pretrained=True)
num_filters = backbone.fc.in_features
layers = list(backbone.children())[:-1]
self.feature_extractor = nn.Sequential(*layers)
# use the pretrained model to classify cifar-10 (10 image classes)
num_target_classes = 10
self.classifier = nn.Linear(num_filters, num_target_classes)
def forward(self, x):
self.feature_extractor.eval()
with torch.no_grad():
representations = self.feature_extractor(x).flatten(1)
x = self.classifier(representations)
...
11About Device Operations
LightningModules know what device they are on! Construct tensors on the device directly to avoid CPU->Device transfer.
# bad
t = torch.rand(2, 2).cuda()
# good (self is LightningModule)
t = torch.rand(2, 2, device=self.device)
For tensors that need to be model attributes, it is best practice to register them as buffers in the modules’ <span>__init__</span> method:
# bad
self.t = torch.rand(2, 2, device=self.device)
# good
self.register_buffer("t", torch.rand(2, 2))
The first two paragraphs are the text in the tutorial. However, there is actually a hidden pit:
If you use a relay <span>pl.LightningModule</span>, and this module instantiates a normal <span>nn.Module</span>, and this model needs to generate some tensors internally, such as the mean and std of each channel of the image, then if you pass a <span>self.device</span> from <span>pl.LightningModule</span>, actually at the beginning, this <span>self.device</span> is always <span>cpu</span>. So if you initialize it in the called <span>nn.Module</span>’s <span>__init__()</span>, using <span>to(device)</span> or doing nothing, the result is that it will always be on <span>cpu</span>.
However, experiments show that although <span>pl.LightningModule</span> in the <span>__init__()</span> phase has <span>self.device</span> still as <span>cpu</span>, once entering the <span>training_step()</span>, it quickly turns into <span>cuda</span>. Therefore, for submodules, the best solution is to use a variable passed in the <span>forward</span> as a reference variable, such as <span>x</span>, and use the <span>type_as</span> function to ensure that all tensors generated in the model are placed on the same device as this reference variable.
class RDNFuse(nn.Module):
...
def init_norm_func(self, ref):
self.mean = torch.tensor(np.array(self.mean_sen), dtype=torch.float32).type_as(ref)
def forward(self, x):
if not hasattr(self, 'mean'):
self.init_norm_func(x)
12Points
<span>pl.seed_everything(1234)</span>: Fix the seed for all related random quantities.
When using LR Scheduler, do not call <span>.step()</span> yourself. It is also handled automatically by the Trainer.
Related interface: https://pytorch-lightning.readthedocs.io/en/latest/common/optimizers.html%3Fhighlight%3Dscheduler%23
# Single optimizer
for epoch in epochs:
for batch in data:
loss = model.training_step(batch, batch_idx, ...)
loss.backward()
optimizer.step()
optimizer.zero_grad()
for scheduler in schedulers:
scheduler.step()
# Multiple optimizers
for epoch in epochs:
for batch in data:
for opt in optimizers:
disable_grads_for_other_optimizers()
train_step(opt)
opt.step()
for scheduler in schedulers:
scheduler.step()
Regarding the method of dividing train and val sets, it is unrelated to PL but very common. Two examples:<span>random_split(range(10), [3, 7], generator=torch.Generator().manual_seed(42))</span>
As follows:
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import MNIST
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
Parameters:
dataset (https://pytorch.org/docs/stable/data.html%23torch.utils.data.Dataset) – Dataset to be split
lengths – lengths of splits to be produced
generator (https://pytorch.org/docs/stable/generated/torch.Generator.html%23torch.Generator) – Generator used for the random permutation.
Technical Communication Group Invitation

△ Long press to add the assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiaozhang-Harbin Institute of Technology-Dialogue System) to apply to join the Natural Language Processing/Pytorch technical communication group
About Us
MLNLP(Machine Learning Algorithms and Natural Language Processing) community is a grassroots academic community jointly built by scholars in natural language processing both domestically and internationally, and has now developed into one of the largest natural language processing communities, including well-known brands such as Ten Thousand People Top Conference Communication Group, AI Selection Exchange, AI Talent Exchange and AI Academic Exchange, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing and the general public.The community can provide an open communication platform for related practitioners’ further studies, employment, and research. Everyone is welcome to follow and join us.