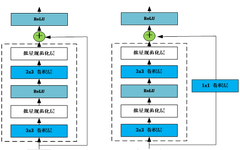
The following uses various methods to construct the network structure shown in the figure below:
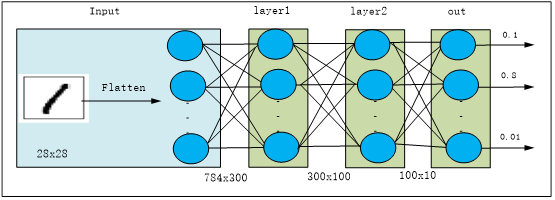
1.1 Inheriting nn.Module Base Class to Build Model
import torch
from torch import nn
import torch.nn.functional as F
class Model_Seq(nn.Module):
"""
Build model by inheriting the base class nn.Module
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Model_Seq, self).__init__()
self.flatten = nn.Flatten()
self.linear1= nn.Linear(in_dim, n_hidden_1)
self.bn1=nn.BatchNorm1d(n_hidden_1)
self.linear2= nn.Linear(n_hidden_1, n_hidden_2)
self.bn2 = nn.BatchNorm1d(n_hidden_2)
self.out = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x=self.flatten(x)
x=self.linear1(x)
x=self.bn1(x)
x = F.relu(x)
x=self.linear2(x)
x=self.bn2(x)
x = F.relu(x)
x=self.out(x)
x = F.softmax(x,dim=1)
return x
## Assign values to some hyperparameters
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
model_seq= Model_Seq(in_dim, n_hidden_1, n_hidden_2, out_dim)
print(model_seq)Model_Seq(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=784, out_features=300, bias=True)
(bn1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(linear2): Linear(in_features=300, out_features=100, bias=True)
(bn2): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(out): Linear(in_features=100, out_features=10, bias=True))
1.2 Using nn.Sequential to Build Model in Layer Order
import torch
from torch import nn
import torch.nn.functional as FUsing Variable-Length Parameters
Seq_arg = nn.Sequential(
nn.Flatten(),
nn.Linear(in_dim,n_hidden_1),
nn.BatchNorm1d(n_hidden_1),
nn.ReLU(),
nn.Linear(n_hidden_1, n_hidden_2),
nn.BatchNorm1d(n_hidden_2),
nn.ReLU(),
nn.Linear(n_hidden_2, out_dim),
nn.Softmax(dim=1)
)
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
print(Seq_arg)Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=300, bias=True)
(2): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
(4): Linear(in_features=300, out_features=100, bias=True)
(5): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU()
(7): Linear(in_features=100, out_features=10, bias=True)
(8): Softmax(dim=1))
input = torch.randn(10,1,28, 28)
Seq_arg(input).shapetorch.Size([10, 10])
Using add_module Method
Seq_module = nn.Sequential()
Seq_module.add_module("flatten",nn.Flatten())
Seq_module.add_module("linear1",nn.Linear(in_dim,n_hidden_1))
Seq_module.add_module("bn1",nn.BatchNorm1d(n_hidden_1))
Seq_module.add_module("relu1",nn.ReLU())
Seq_module.add_module("linear2",nn.Linear(n_hidden_1, n_hidden_2))
Seq_module.add_module("bn2",nn.BatchNorm1d(n_hidden_2))
Seq_module.add_module("relu2",nn.ReLU())
Seq_module.add_module("out",nn.Linear(n_hidden_2, out_dim))
Seq_module.add_module("softmax",nn.Softmax(dim=1))
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
print(Seq_module)Sequential( (flatten): Flatten(start_dim=1, end_dim=-1) (linear1): Linear(in_features=784, out_features=300, bias=True) (bn1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu1): ReLU() (linear2): Linear(in_features=300, out_features=100, bias=True) (bn2): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu2): ReLU() (out): Linear(in_features=100, out_features=10, bias=True) (softmax): Softmax(dim=1))
Using OrderedDict
import torch
from torch import nn
from collections import OrderedDict
Seq_dict = nn.Sequential(OrderedDict([
("flatten",nn.Flatten()),
("linear1",nn.Linear(in_dim,n_hidden_1)),
("bn1",nn.BatchNorm1d(n_hidden_1)),
("relu1",nn.ReLU()),
("linear2",nn.Linear(n_hidden_1, n_hidden_2)),
("bn2",nn.BatchNorm1d(n_hidden_2)),
("relu2",nn.ReLU()),
("out",nn.Linear(n_hidden_2, out_dim)),
("softmax",nn.Softmax(dim=1))
]))
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
print(Seq_dict)Sequential(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=784, out_features=300, bias=True)
(bn1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU()
(linear2): Linear(in_features=300, out_features=100, bias=True)
(bn2): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU()
(out): Linear(in_features=100, out_features=10, bias=True)
(softmax): Softmax(dim=1))
## Display parameter values
for param in Seq_dict.parameters(): print(param,param.size()) breakParameter containing:tensor([[ 0.0097, 0.0145, -0.0071, …, -0.0117, -0.0209, 0.0319],
[ 0.0147, -0.0258, -0.0163, …, -0.0091, -0.0040, -0.0036],
[ 0.0248, 0.0330, -0.0015, …, 0.0020, -0.0339, -0.0135],
…,
[-0.0304, -0.0112, -0.0268, …, 0.0127, -0.0064, -0.0327],
[ 0.0080, -0.0248, 0.0106, …, 0.0339, 0.0251, 0.0021],
[-0.0097, 0.0226, 0.0251, …, 0.0079, -0.0026, -0.0013]],
requires_grad=True) torch.Size([300, 784])
## Display parameter values
params=list(Seq_dict.named_parameters())
for i in range(len(params)):
print(i)
print(params[i])
break
0(‘linear1.weight’, Parameter containing:tensor([[ 0.0097, 0.0145, -0.0071, …, -0.0117, -0.0209, 0.0319],
[ 0.0147, -0.0258, -0.0163, …, -0.0091, -0.0040, -0.0036],
[ 0.0248, 0.0330, -0.0015, …, 0.0020, -0.0339, -0.0135],
…, [-0.0304, -0.0112, -0.0268, …, 0.0127, -0.0064, -0.0327],
[ 0.0080, -0.0248, 0.0106, …, 0.0339, 0.0251, 0.0021],
[-0.0097, 0.0226, 0.0251, …, 0.0079, -0.0026, -0.0013]],
requires_grad=True))
1.3 Inheriting nn.Module Base Class and Using Model Containers to Build Model
Using nn.Sequential Model Container
class Model_lay(nn.Module):
"""
Build network using sequential, the function of Sequential() is to combine the layers of the network together
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Model_lay, self).__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1),nn.BatchNorm1d(n_hidden_1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2),nn.BatchNorm1d(n_hidden_2))
self.out = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x=self.flatten(x)
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = F.softmax(self.out(x),dim=1)
return x
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
model_lay= Model_lay(in_dim, n_hidden_1, n_hidden_2, out_dim)
print(model_lay)Model_lay( (flatten): Flatten(start_dim=1, end_dim=-1) (layer1): Sequential(
(0): Linear(in_features=784, out_features=300, bias=True)
(1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
) (layer2): Sequential(
(0): Linear(in_features=300, out_features=100, bias=True)(1): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (out): Sequential( (0): Linear(in_features=100, out_features=10, bias=True) ))
Using nn.ModuleList Model Container
class Model_lst(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Model_lst, self).__init__()
self.layers = nn.ModuleList([
nn.Flatten(),
nn.Linear(in_dim,n_hidden_1),
nn.BatchNorm1d(n_hidden_1),
nn.ReLU(),
nn.Linear(n_hidden_1, n_hidden_2),
nn.BatchNorm1d(n_hidden_2),
nn.ReLU(),
nn.Linear(n_hidden_2, out_dim),
nn.Softmax(dim=1)
])
def forward(self,x):
for layer in self.layers:
x = layer(x)
return x
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
model_lst = Model_lst(in_dim, n_hidden_1, n_hidden_2, out_dim)
print(model_lst)Model_lst( (layers): ModuleList((0): Flatten(start_dim=1, end_dim=-1)(1): Linear(in_features=784, out_features=300, bias=True)(2): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU()(4): Linear(in_features=300, out_features=100, bias=True)(5): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(6): ReLU()(7): Linear(in_features=100, out_features=10, bias=True)(8): Softmax(dim=1) ))
Using nn.ModuleDict Model Container
import torch
from torch import nn
class Model_dict(nn.Module):
def __init__(self,in_dim, n_hidden_1,n_hidden_2,out_dim):
super(Model_dict, self).__init__()
self.layers_dict = nn.ModuleDict({"flatten":nn.Flatten(),
"linear1":nn.Linear(in_dim,n_hidden_1),
"bn1":nn.BatchNorm1d(n_hidden_1),
"relu":nn.ReLU(),
"linear2":nn.Linear(n_hidden_1, n_hidden_2),
"bn2":nn.BatchNorm1d(n_hidden_2),
"out":nn.Linear(n_hidden_2, out_dim),
"softmax":nn.Softmax(dim=1)
})
def forward(self,x):
layers = ["flatten","linear1","bn1","relu","linear2","bn2","relu","out","softmax"]
for layer in layers:
x = self.layers_dict[layer](x)
return x
ing_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
model_dict = Model_dict(in_dim, n_hidden_1, n_hidden_2, out_dim)
print(model_dict)Model_dict( (layers_dict): ModuleDict(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=784, out_features=300, bias=True) (bn1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(linear2): Linear(in_features=300, out_features=100, bias=True) (bn2): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(out): Linear(in_features=100, out_features=10, bias=True) (softmax): Softmax(dim=1) ))
params_count=len(list(model_dict.parameters()))
print(params_count)
for param in model_dict.parameters(): print(param) break10Parameter containing:tensor([[ 0.0146, -0.0231, -0.0304, …, 0.0130, 0.0266, 0.0106],
[-0.0075, -0.0254, 0.0325, …, -0.0149, -0.0328, -0.0299],
[ 0.0062, 0.0156, 0.0334, …, -0.0136, 0.0124, 0.0254],
…,
[-0.0332, 0.0173, 0.0256, …, 0.0269, 0.0179, -0.0159],
[ 0.0162, -0.0137, 0.0344, …, 0.0233, 0.0147, 0.0169],
[ 0.0103, -0.0302, 0.0308, …, -0.0034, -0.0178, -0.0325]],
requires_grad=True)
1.4 Custom Network Module
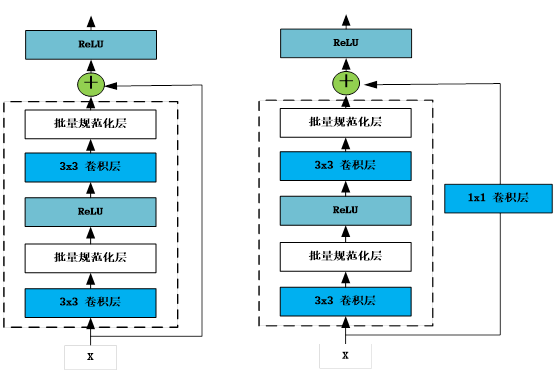
import torch
import torch.nn as nn
from torch.nn import functional as F
class RestNetBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetBasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
output = self.conv1(x)
output = F.relu(self.bn1(output))
output = self.conv2(output)
output = self.bn2(output)
return F.relu(x + output)
class RestNetDownBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetDownBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride[0], padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.extra = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=0),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
extra_x = self.extra(x)
output = self.conv1(x)
out = F.relu(self.bn1(output))
out = self.conv2(out)
out = self.bn2(out)
return F.relu(extra_x + out)
class RestNet18(nn.Module):
def __init__(self):
super(RestNet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = nn.Sequential(RestNetBasicBlock(64, 64, 1),
RestNetBasicBlock(64, 64, 1))
self.layer2 = nn.Sequential(RestNetDownBlock(64, 128, [2, 1]),
RestNetBasicBlock(128, 128, 1))
self.layer3 = nn.Sequential(RestNetDownBlock(128, 256, [2, 1]),
RestNetBasicBlock(256, 256, 1))
self.layer4 = nn.Sequential(RestNetDownBlock(256, 512, [2, 1]),
RestNetBasicBlock(512, 512, 1))
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Linear(512, 10)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out

Want to know more
Quickly scan the code to follow