Originally published on the frontier of deep learning technology
Author: I want to encourage Nazha @ ZhihuSource: https://zhuanlan.zhihu.com/p/89587997Editor: Jishi Platform
Introduction
As the autumn recruitment season is underway, this article collects relevant interview questions in the field of deep learning & computer vision, covering various aspects such as deconvolution, neural networks, object detection, etc., making the content very comprehensive.
1. What is deconvolution?
Deconvolution, also known as transposed convolution, if convolution operation is implemented using matrix multiplication, where the convolution kernel is laid out as a matrix, then during forward computation of deconvolution, the transpose of this matrix WT is left-multiplied, and during backpropagation, W is left-multiplied, which is exactly the opposite of the convolution operation. It should be noted that deconvolution is not the inverse operation of convolution.
The general convolution operation can be viewed as a sparse matrix C with non-zero elements as weights multiplied by the input image, and the operation during backpropagation is essentially the multiplication of C’s transpose with the derivative matrix of the loss with respect to the output y.
The operation process of inverse convolution is exactly the opposite of convolution, forming C’s transpose during forward propagation and left-multiplying C during backpropagation.
2. What are the uses of deconvolution?
To achieve upsampling; approximate reconstruction of input images, and visualization of convolutional layers.
3. Explain the universal approximation theorem of neural networks.
As long as the activation function is appropriately chosen and the number of neurons is sufficient, a neural network with at least one hidden layer can approximate any continuous function on a closed interval to any specified degree of accuracy.
4. Is a neural network a generative model or a discriminative model?
It is a discriminative model, directly outputting class labels or outputting class posterior probabilities p(y|x).
5. What are the differences between Batch Normalization and Group Normalization?
BN normalizes over the batch dimension, while GN computes the mean and variance for each group in the channel direction.
6. What are the main methods of model compression?
Optimizing from the model structure: model pruning, model distillation, and automl directly learning simpler structures.
Model parameter quantization reduces the numerical precision of FP32 to FP16, INT8, binary networks, ternary networks, etc.
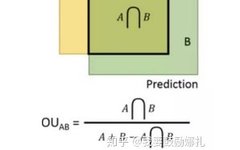
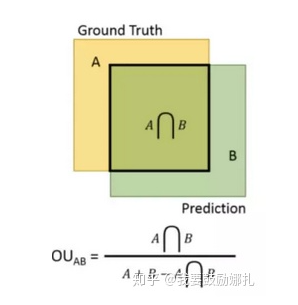
7. How is IoU calculated in object detection?
IoU is the intersection of the detection result and the Ground Truth divided by their union, which is the accuracy of detection.
8. What problems might arise when training a model with 10 million classes using deep convolutional networks for image classification?
Hint: Memory/VRAM usage; model convergence speed, etc.
9. Why don’t we use second-order derivatives for optimization in deep learning?
The Hessian matrix is n*n, which becomes very large in high-dimensional cases, making computation and storage problematic.
10. How does the size of mini-batch affect learning outcomes in deep learning?
A mini-batch that is too small may slow down convergence, while one that is too large may lead to sharp minima and poor generalization.
11. The principle of dropout.
Dropout can be viewed as an ensemble method; each time dropout is applied, it is equivalent to finding a slimmer network from the original network.
-
It forces neurons and other randomly selected neurons to work together, reducing the joint adaptability between neuron nodes and enhancing generalization ability.
-
Using dropout results in more local clusters, which increases discrimination and sparsity under the same amount of data.
12. Why does SSD perform poorly in detecting small objects?
-
Small objects correspond to fewer anchors, and the pixels on the corresponding feature map are difficult to train, which is why SSD’s accuracy increases after augmentation (because cropping makes small objects larger).
-
Detecting small objects requires sufficiently large feature maps to provide precise features, as well as enough semantic information to distinguish from the background.
13. Dilated convolution and its advantages and disadvantages.
Pooling operations can increase the receptive field but may lose some information. Dilated convolution inserts zero-weight values into the convolution kernel, thus skipping some pixels during each convolution.
Dilated convolution increases the receptive field of each output point of the convolution and does not lose information like pooling, making it widely applicable in problems requiring global information or long sequence dependencies in speech sequences.
14. Why does Fast RCNN use Smooth L1 for location loss?
The expression is:
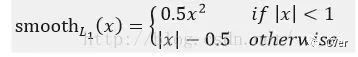
-
The author’s goal in this setting is to make the loss more robust to outliers; compared to the L2 loss function, it is less sensitive to outliers and abnormal values, controlling the magnitude of the gradients to prevent divergence during training.
15. Batch Normalization.
-
The reason for using BN is that the continuously changing parameters of each layer during network training cause the input distribution of each subsequent layer to change, and the learning process requires each layer to adapt to the input distribution, thus necessitating a reduction in the network’s learning rate and careful initialization (internal covariant shift).
-
If normalization is only performed to ensure that data has zero mean and unit variance, it can reduce the expressive capability of the layer (for example, when using the Sigmoid function, only the linear region is utilized).
-
The specific process of BN (note that epsilon should be added to the denominator in the third formula).

Note: The mean and variance used during testing are no longer from a single batch, but rather for the entire dataset. Therefore, in addition to normal forward propagation and backpropagation during training, we also need to record the mean and variance of each batch to calculate the overall mean and variance after training.
Another note: In a preprint paper on arxiv from June, there is an article titled “How Does Batch Normalization Help Optimization?” which mentions that the real reason BN works and changes the input distribution to produce stability is almost unrelated; the real reason is that BN makes the landscape of the corresponding optimization problem smoother, ensuring more predictive gradients and allowing the use of larger learning rates, thus speeding up convergence of the network. Moreover, not only BN can produce such effects, but many regularization techniques have similar impacts.
16. Hyperparameter search methods.
-
Grid search: Among all candidate parameter selections, try every possibility through looping, and the best-performing parameters are the final results.
-
Bayesian optimization: Bayesian optimization is an algorithm that estimates the maximum of a function based on existing sampling points when the function equation is unknown. This algorithm assumes that the function follows a Gaussian process (GP).
-
Random search: It has been found that simply performing a fixed number of random searches on parameter settings is more effective than exhaustive searches in high-dimensional spaces. This is because it has been shown that some hyperparameters do not transform the low-dimensional space into a high-dimensional space through feature transformation, and data that is not separable in low-dimensional space is more likely to be linearly separable in high-dimensional space. Specific methods include kernel functions, such as Gaussian kernel, polynomial kernel, etc.
-
Gradient-based: Calculate the gradient concerning hyperparameters and then use gradient descent to optimize hyperparameters.
17. How to understand operations such as convolution, pooling, and fully connected layers?
-
The role of convolution: to capture the dependencies of adjacent pixels in an image; it acts like a filter to obtain different forms of feature maps.
-
The role of activation functions: to introduce non-linear factors.
-
The role of pooling: to reduce the size of feature dimensions, making features more controllable; reduce the number of parameters, thus controlling overfitting; increase the robustness of the network to slightly transformed images; achieve a scale-invariance, meaning objects can be detected regardless of their orientation in the image.
18. The role of a 1×1 convolution kernel.
-
To achieve dimensionality increase or decrease by controlling the number of convolution kernels, thus reducing model parameters.
-
To perform normalization operations on different features.
-
To fuse features across different channels.
19. Characteristics of common activation functions.
-
Sigmoid: When the input value is large, the corresponding function value approaches 1 or 0, leading to saturation of the function and resulting in the vanishing gradient problem.
-
Relu: Solves the vanishing gradient problem but may exhibit the dying relu phenomenon, where some neurons effectively become